本文最后更新于:1 年前
MemorySearch 忆搜阁 前端代码仓库:memory-search-frontend
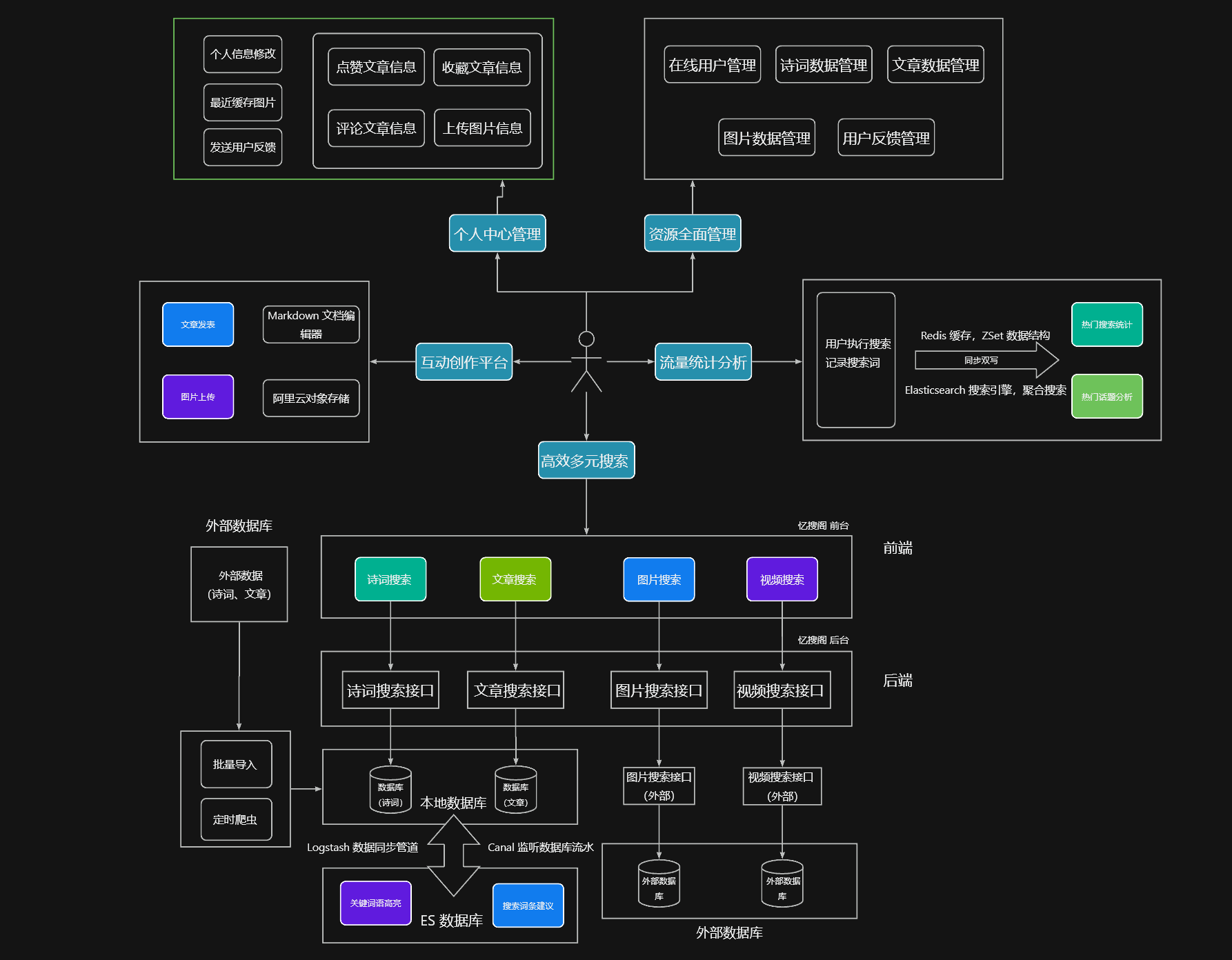
☕ 项目概述 这个项目是一个基于 Spring Boot + Elastic Stack 技术栈 + Vue.js 的聚合搜索中台。它不仅是一个强大的搜索引擎,更是一个内容丰富的社区平台。
这个项目的目标是提供一个一站式的搜索、管理和互动体验 ,满足各种用户需求。
🥘 效果展示 用户登录
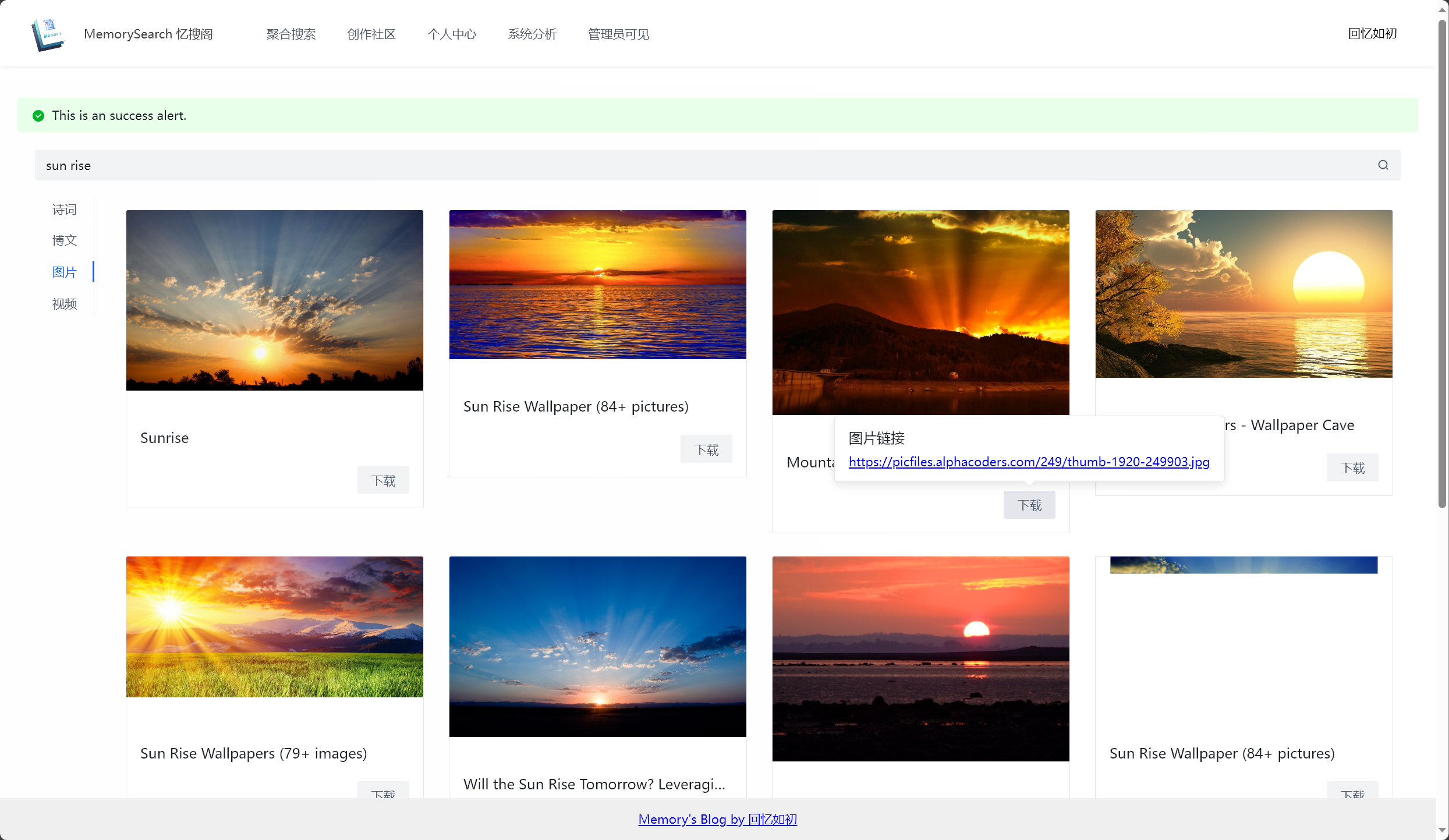
图片搜索
文章上传
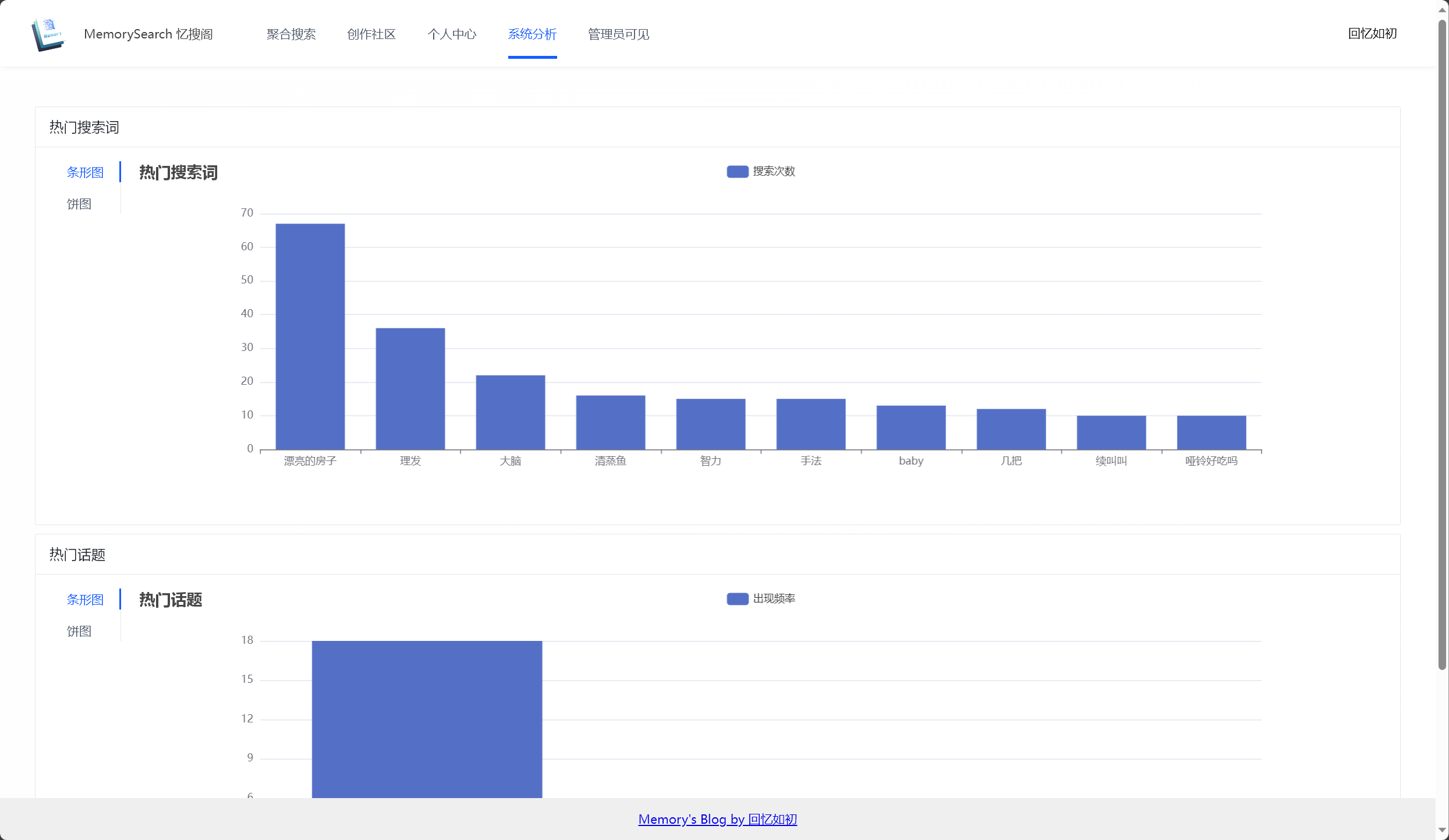
统计分析
🍚 使用场景
企业内部多项目数据搜索:该平台能够满足企业内部多个项目的数据搜索需求,避免每个项目都单独开发搜索功能,提升开发效率并降低系统维护成本。
多源内容聚合搜索:当需要聚合不同来源、不同类型的内容时,该平台可以提供一站式的搜索页面,便于用户快速查找所需信息,提高工作效率。
企业级搜索需求:对于有大规模搜索需求的企业,该平台提供了稳定的、高效的搜索功能,满足企业的搜索需求,并支持数据源接入和管理。
🥣 核心功能与特点
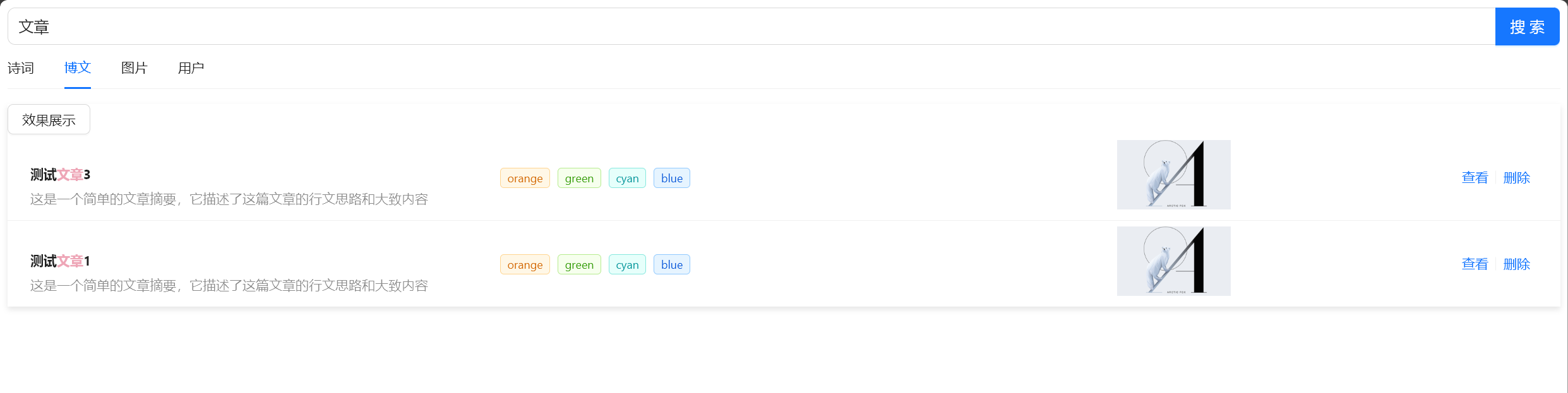
高效多元搜索 :用户可以在搜索框中输入关键词,系统会提供快速、准确的搜索结果。搜索结果会根据内容类型(文本、图片、视频)进行分类展示,并提供关键词高亮和搜索建议,使用户能快速找到所需内容。
互动创作平台 :用户可以在这个模块中发布文章、上传图片,与其他用户互动。系统会自动推荐热门内容,引导用户发现更多优质内容。用户还可以对文章、图片进行点赞、评论和收藏,形成一个活跃的内容创作社区。
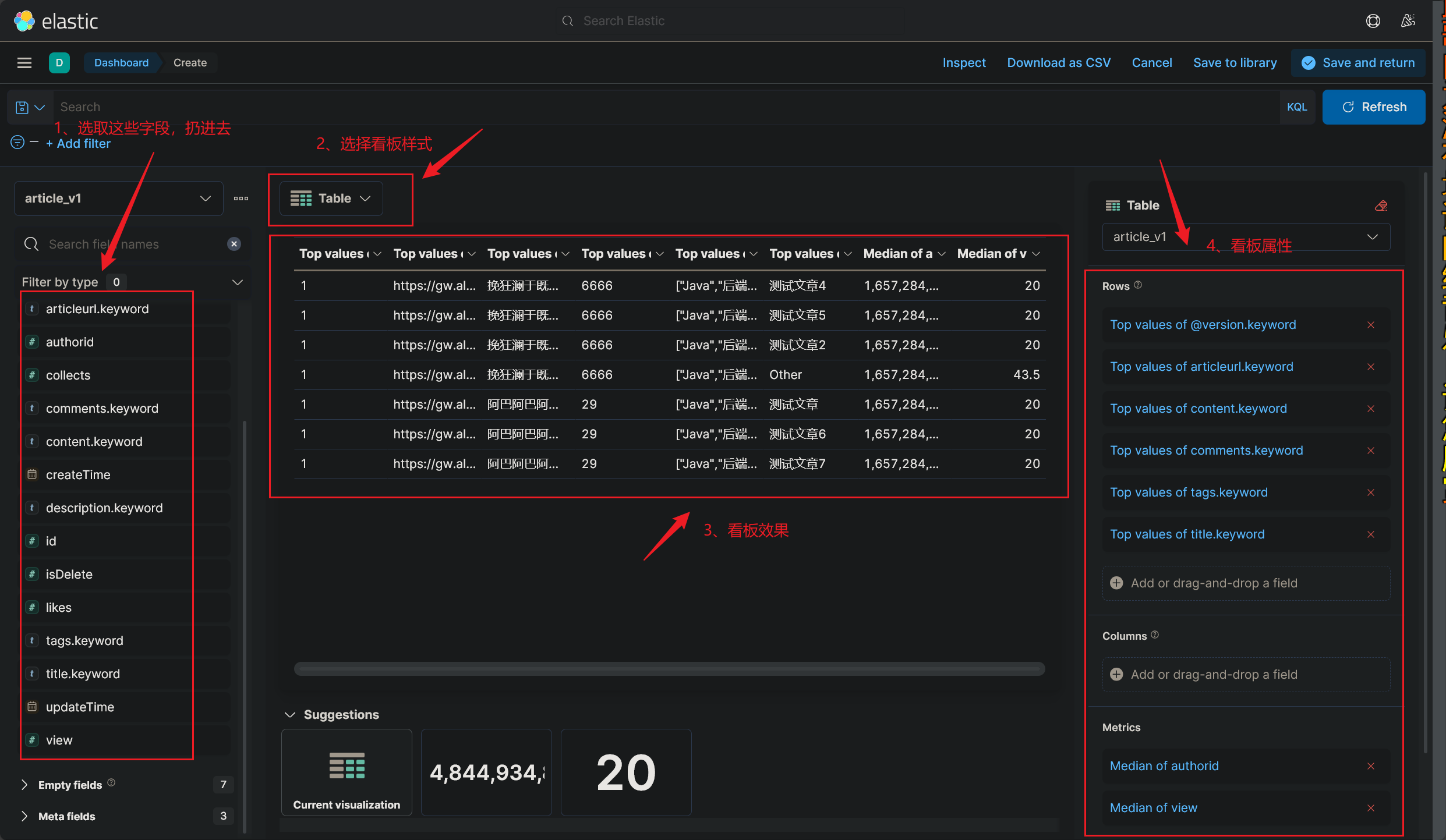
流量统计分析 :系统会自动统计每个关键词的搜索流量,并按照时间、关键词类型等维度进行分析。用户可以查看热搜词类别和搜索流量高峰,了解内容趋势和用户行为。
个人中心管理 :用户可以在个人中心查看和编辑个人信息,包括头像、昵称、简介等。用户还可以查看自己的点赞、评论和收藏的内容,以及自己创作的文章和下载的图片、视频等。
资源全面管理 :这个模块仅对管理员可见,管理员可以对全站资源(文章、图片、视频、用户等)进行全面管理。管理员可以对资源进行添加、删除、修改等操作,保证资源的准确性和完整性。
图片预览分享 :通过集成的图片预览功能,用户可以像浏览相册一样查看页面中的图片,并支持缩放和分享到社交媒体平台。
🍜 访问地址 暂未部署上线,点击跳转至:个人博客 MemorySearch 开发文档
🍝 架构设计 原图链接:项目架构图
🍺 技术选型 后端
Spring Boot:作为项目的核心框架,提供快速构建 RESTful API 的能力。
Elasticsearch:作为搜索引擎的核心,提供全文搜索、结构化搜索和推荐等功能。
Elasticsearch JDBC:用于将关系型数据库中的数据同步到 Elasticsearch 中。
Spring Data Elasticsearch:提供与 Elasticsearch 的集成,简化 Elasticsearch 操作。
Logstash:用于日志收集、解析和传输,便于监控和调试。
Kibana:用于可视化展示 Elasticsearch 中的数据,提供强大的数据分析和可视化功能。
Mybatis:作为持久层框架,用于操作关系型数据库。
Redis:作为缓存数据库,提高系统性能。
Swagger:用于 API 文档的管理和展示。
前端
Vue.js:作为前端框架,提供响应式设计和组件化开发的能力。
Element UI:作为 Vue.js 的 UI 组件库,提供丰富的界面元素和样式。
Axios:用于发送 HTTP 请求,与后端 API 进行交互。
Vue Router:用于实现前端路由,管理页面跳转。
Vuex:用于管理前端状态,实现组件之间的数据共享和通信。
ECharts:用于数据可视化,展示统计图表。
🍰 快速启动 拉取代码后, 如何快速运行该项目?
后端
配置 MySQL、Redis、Elasticsearch 为本机地址:
1 2 3 4 5 6 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/xxx username: xxx password: xxx
1 2 3 4 5 6 7 redis: database: 0 host: localhost port: 6379 timeout: 5000 password: Dw990831
1 2 3 4 5 elasticsearch: uris: http://localhost:9200 username: root password: 123456
额外安装
在本地安装 Elasticsearch、Kibana、Logstash
在 ES 的 bin 目录下执行以下命令,启动 ES:
在 Kibana 的 bin 目录下执行以下命令,启动 Kibana:
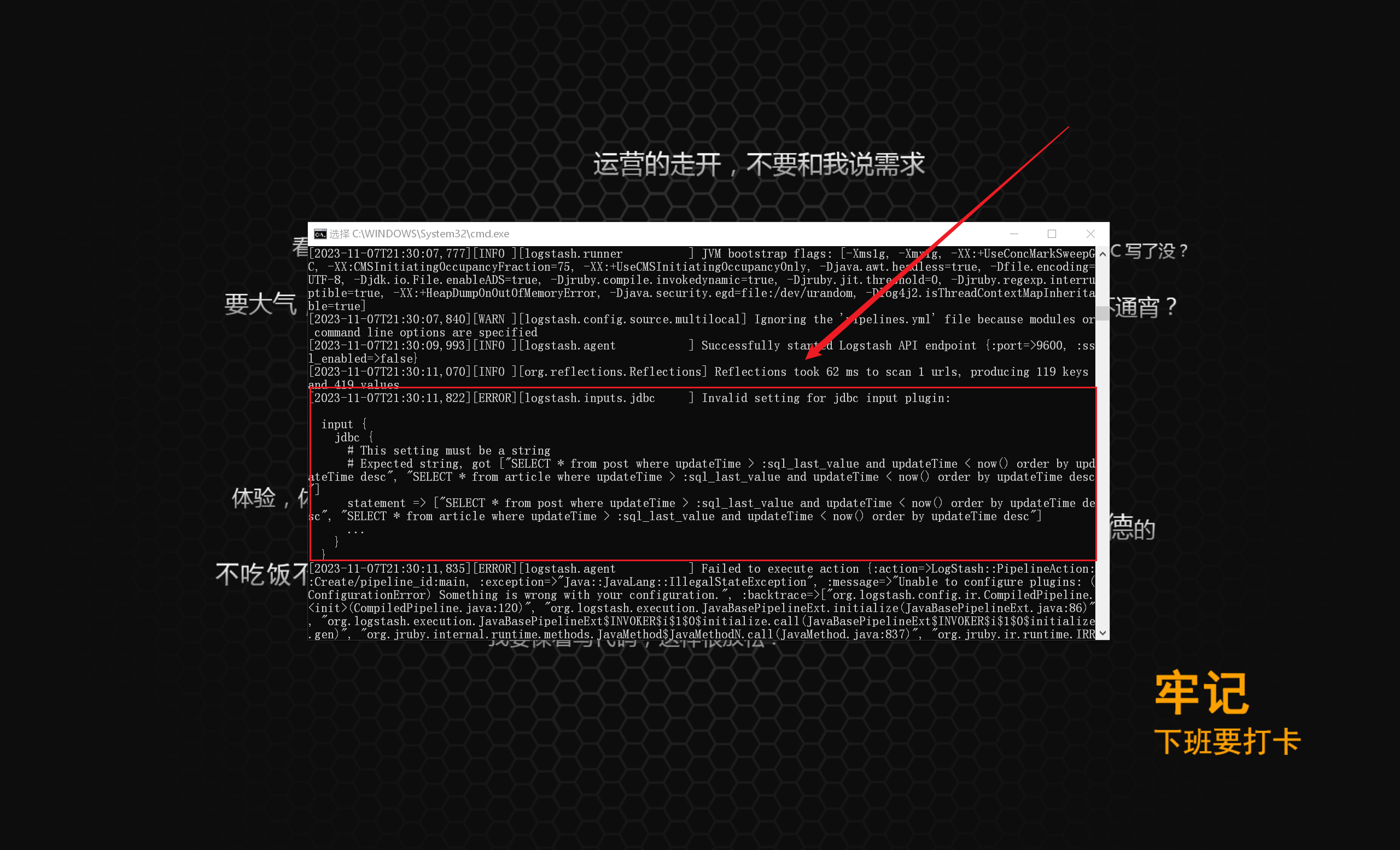
在 Logstash 的 config 目录下新增 .conf 文件,编写配置文件,做好数据映射(以下配置信息可作为参考)
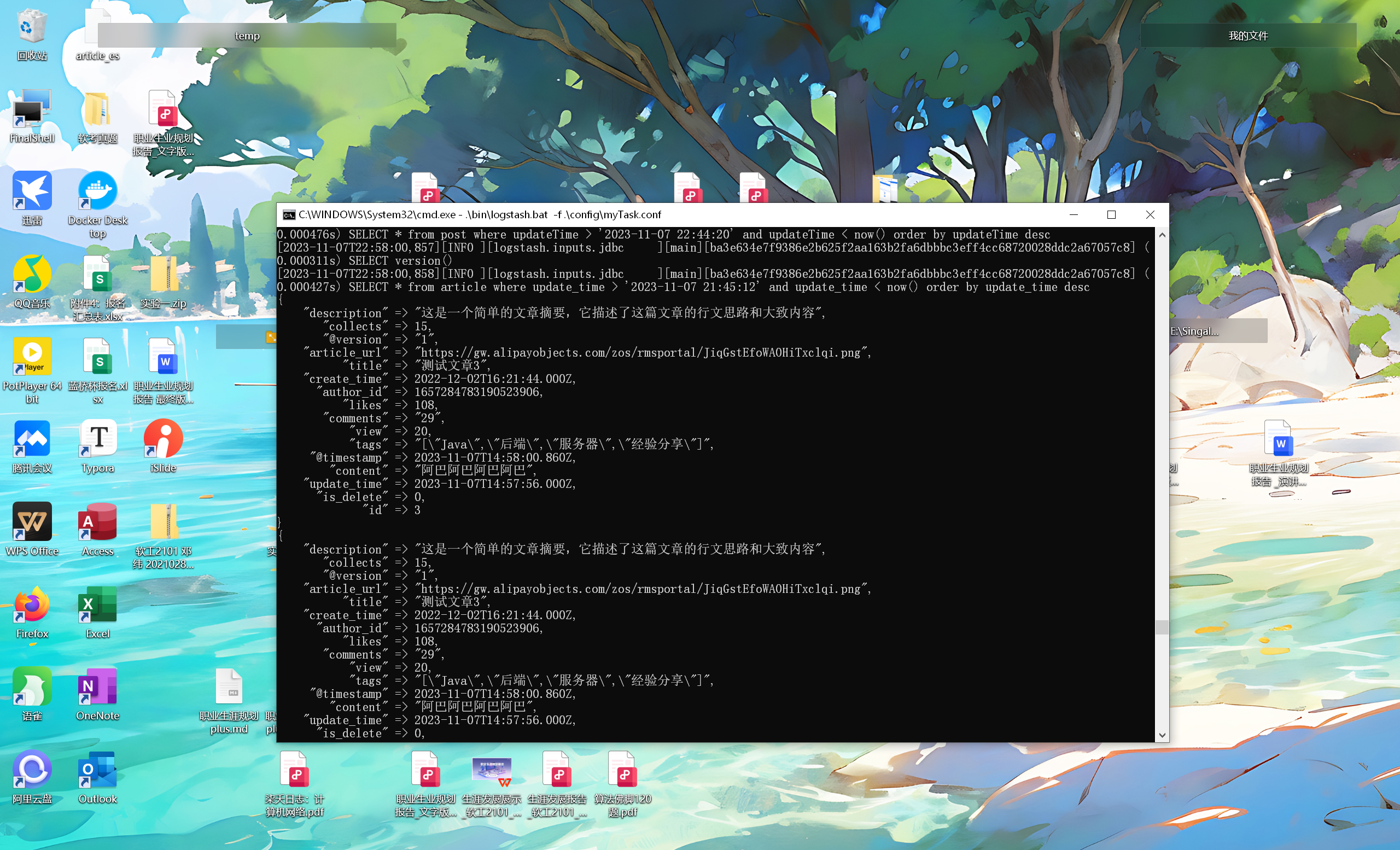
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" "com.mysql.jdbc.Driver" "jdbc:mysql://localhost:3306/******" "******" "******" "SELECT * from post where updateTime > :sql_last_value and updateTime < now() order by updateTime desc" true "timestamp" "updatetime" "*/5 * * * * *" "Asia/Shanghai" "updatetime" => "updateTime" "userid" => "userId" "createtime" => "createTime" "isdelete" => "isDelete" "thumbnum" , "favournum" ]"127.0.0.1:9200" "******" "%{id}"
在 Logstash 的根目录下执行以下命令,加载配置文件并启动 Logstash :
1 .\bin\logstash.bat -f .\config\myTask.conf
前端 ::: warning 注意Node.js 环境配置完成,版本为 v18.x.x及以上
根据后端接口文档,一键生成前端 HTTP 请求接口:
🍖 官方文档:ferdikoomen/openapi-typescript-codegen (github.com)
安装:
1 npm install openapi-typescript-codegen --save-dev
执行命令生成代码:
1 openapi --input http://localhost:8104/api/v2/api-docs?group=memory-search --output ./generated --client axios
执行成功后,在 OpenAPI.ts 文件下,修改请求的后端地址:
1 2 3 4 5 6 7 8 9 10 11 export const OpenAPI : OpenAPIConfig = {BASE : "http://localhost:8104" ,VERSION : "1.0" ,WITH_CREDENTIALS : true ,CREDENTIALS : "include" ,TOKEN : undefined ,USERNAME : undefined ,PASSWORD : undefined ,HEADERS : undefined ,ENCODE_PATH : undefined ,
🥩 持续优化 随着项目的发展和用户需求的增加,我们将持续优化系统性能,提升用户体验。
加强系统的安全性措施,定期进行安全审计和漏洞扫描,确保用户数据的安全。引入微服务架构将项目向容器化部署发展,确保系统的可扩展性和灵活性。
同时将引入持续集成与部署的流程,实现自动化测试和部署上线,降低运维成本。
正文 Day1
前端项目初始化 ✔
后端项目初始化 ✔
前端封装全局 Axios、Index 页面设计 ✔
实现用户改变页面,URL 同步改变
前后端联调成功 ✔
记录
使用 Ant Design Vue 快速构建了前端项目,快捷方便,项目构建的实现流程全部记录在《》一文
我使用了一套模板,快速实现了后端项目初始化
前端封装全局 Axios、router 路由、嵌套路由等基础操作,同样记录在了《》一文中
后端造了几条 post 评论假数据,前端使用列表组件,简单展示
URL 同步页面状态改变,可难死我了:
使用 url 记录页面搜索状态,当用户刷新页面时,能够从 url 中还原之前的搜索状态
实现:用户操作页面,能够改变 url 地址(搜索内容同步填充在 url,切换 tab 页时,也要填充)
url 改变,去改变对应页面状态
Day2
后端获取到文章、用户、图片信息 了解数据抓取的几种方式
数据抓取流程
分析数据,怎么抓取
拿到数据后,怎么处理
写入数据库,持久化存储
数据抓取的几种方式
直接请求数据接口(最方便),可使用 HttpClient、Hutool 等客户端发送请求
解析HTML 文档/JSON 字符串 中的网页内容,获取数据
jsoup 解析库,支持发送请求获取 HTML 文档,解析数据
文章获取
去其他网站抓取,持久化存储到数据库中
从互联网上获取数据 -> 爬虫
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 String json = "{\"current\":1,\"pageSize\":8,\"sortField\":\"createTime\",\"sortOrder\":\"descend\",\"category\":\"文章\",\"reviewStatus\":1}" ;String url = "https://www.code-nav.cn/api/post/search/page/vo" ;String result = HttpRequestJSONObject data = (JSONObject) map.get("data" );JSONArray records = (JSONArray) data.get("records" );new ArrayList <>();for (Object record : records) {JSONObject tempRecord = (JSONObject) record;Post post = new Post ();"title" ));"content" ));JSONArray tags = (JSONArray) tempRecord.get("tags" );1L );boolean b = postService.saveBatch(articleList);
用户获取
本地数据,每个网站的用户基本都是自己的,无需从外站获取
图片获取
实时抓取,这部分数据不存放在本地数据库,直接从别人的接口(网站/数据库)中获取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 long current = currentPage - 1 ;if (StringUtils.isNotBlank(searchText)) {"UTF-8" );String url = String.format("https://cn.bing.com/images/search?q=%s&first=%s" , searchText, current);Document doc = Jsoup.connect(url).get();Elements elements = doc.select(".iuscp.isv" );new ArrayList <>();for (Element element : elements) {String m = element.select(".iusc" ).get(0 ).attr("m" );String murl = (String) map.get("murl" );String title = element.select(".inflnk" ).get(0 ).attr("aria-label" );Picture picture = new Picture ();new Page <>(pageSize, currentPage);return picturePage;
Day3 现有业务场景分析 实现了在页面获取文章、用户和图片数据
几种不同的业务场景分析:
可以根据不同的 Tab 页,发送不同的请求 ,当用户点击切换标签页,发送不同的请求
如果是聚合内容 的网页,可以考虑设计后端统一请求接口,设计一个请求搞定所有搜索查询请求
考虑到业务的扩展性:更多的搜索条件,搜索更多的信息。比如不直接返回数据,但返回数据总数,给予用户反馈
聚合搜索
浏览器可能会限制请求数量,可以考虑后端统一接口,一个接口搞定所有查询请求数据(后端可以并发)
设计多个特定的接口,分别接收不同的查询请求 :不同的接口接收的参数不一致 ,增加了前后端沟通的负担,可以考虑用一个接口将请求参数统一,前端只需传入固定的参数,后端负责转换和处理参数,减轻前端压力 -> 比如编程导航的分类请求
Java 并发
适配器模式
注册器模式 1 2 3 4 5 6 7 8 9 @PostConstruct public void doInit () {1 );new HashMap () {{
使用适配器模式,干掉了冗长复杂的 switch Day4 根据页面,选择性查询对应页面的数据 我们实现前端切换文章、用户和图片的 Tab 页面时,传入 type(页面类型)参数,用来指定搜索哪个页面的数据 ,而非全部搜索
前端传入 type(类型)参数,通知后端,根据类型 搜索对应页面 的数据
默认 type 为空,则搜索所有页面数据
Day5
再成功地将 ES 和 MySQL 数据同步后,终于可以进行下一步了
搜索高亮
官方文档:[Highlighting | Elasticsearch Guide 7.17] | Elastic 如何使搜索词高亮?ES 文档里有现成的 demo:
1 2 3 4 5 6 7 8 9 10 11 GET / _search
后端
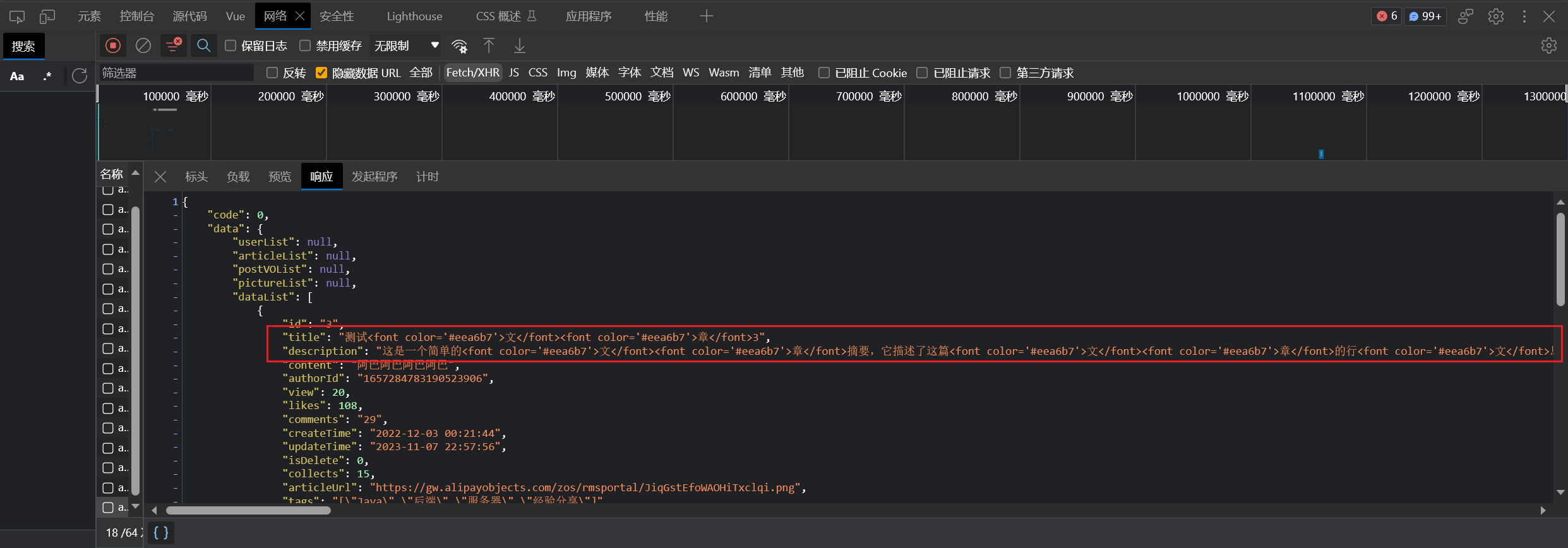
我们使用 Java 客户端,这样编写: 使所有字段内匹配的关键字高亮: (2023/10/01 晚)
1 2 3 4 5 6 HighlightBuilder highlightBuilder = new HighlightBuilder ();"*" )"<font color='#eea6b7'>" )"</font>" ); false );
1 2 3 4 5 6 7 8 HighlightBuilder highlightBuilder = new HighlightBuilder ()"content" )false )"<font color='#eea6b7'>" )"</font>" );"title" )
1 2 3 4 5 6 NativeSearchQuery searchQuery = new NativeSearchQueryBuilder ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 List<SearchHit<PostEsDTO>> searchHitList = searchHits.getSearchHits();new HashMap <>();for (SearchHit hit : searchHits.getSearchHits()) {PostEsHighlightData data = new PostEsHighlightData ();if (hit.getHighlightFields().get("title" ) != null ) {String highlightTitle = String.valueOf(hit.getHighlightFields().get("title" ));1 , highlightTitle.length() - 1 ));if (hit.getHighlightFields().get("content" ) != null ) {String highlightContent = String.valueOf(hit.getHighlightFields().get("content" ));1 , highlightContent.length() - 1 ));
根据 id 拿到每一个 Post 对象,使用高亮关键词替换原文本,返回结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 if (postList != null ) {if (idPostMap.containsKey(postId)) {Post post = idPostMap.get(postId).get(0 );String hl_title = highlightDataMap.get(postId).getTitle();String hl_content = highlightDataMap.get(postId).getContent();if (hl_title != null && hl_title.trim() != "" ) {if (hl_content != null && hl_content.trim() != "" ) {else {String delete = elasticsearchRestTemplate.delete(String.valueOf(postId), PostEsDTO.class);"delete post {}" , delete);
前端
后端已经将关键词高亮特殊处理了,前端应该做什么呢?
将后端响应的文本信息,放入 v-html 属性 中,即可解析出文本的 CSS 样式 :
1 2 3 4 5 6 7 8 9 10 11 12 13 <!--标题-->
这让我想起了前两天刚实现过的前端解析 Markdown 格式文件 的方法: (2023/10/01 晚)
1 2 3 4 5 6 7 import MarkdownIt from "markdown-it" ;const parsedContent = ref ();const md = new MarkdownIt ();value = md.render (articleInfo.value .content );
1 2 3 4 5 <div
搜索高亮语法
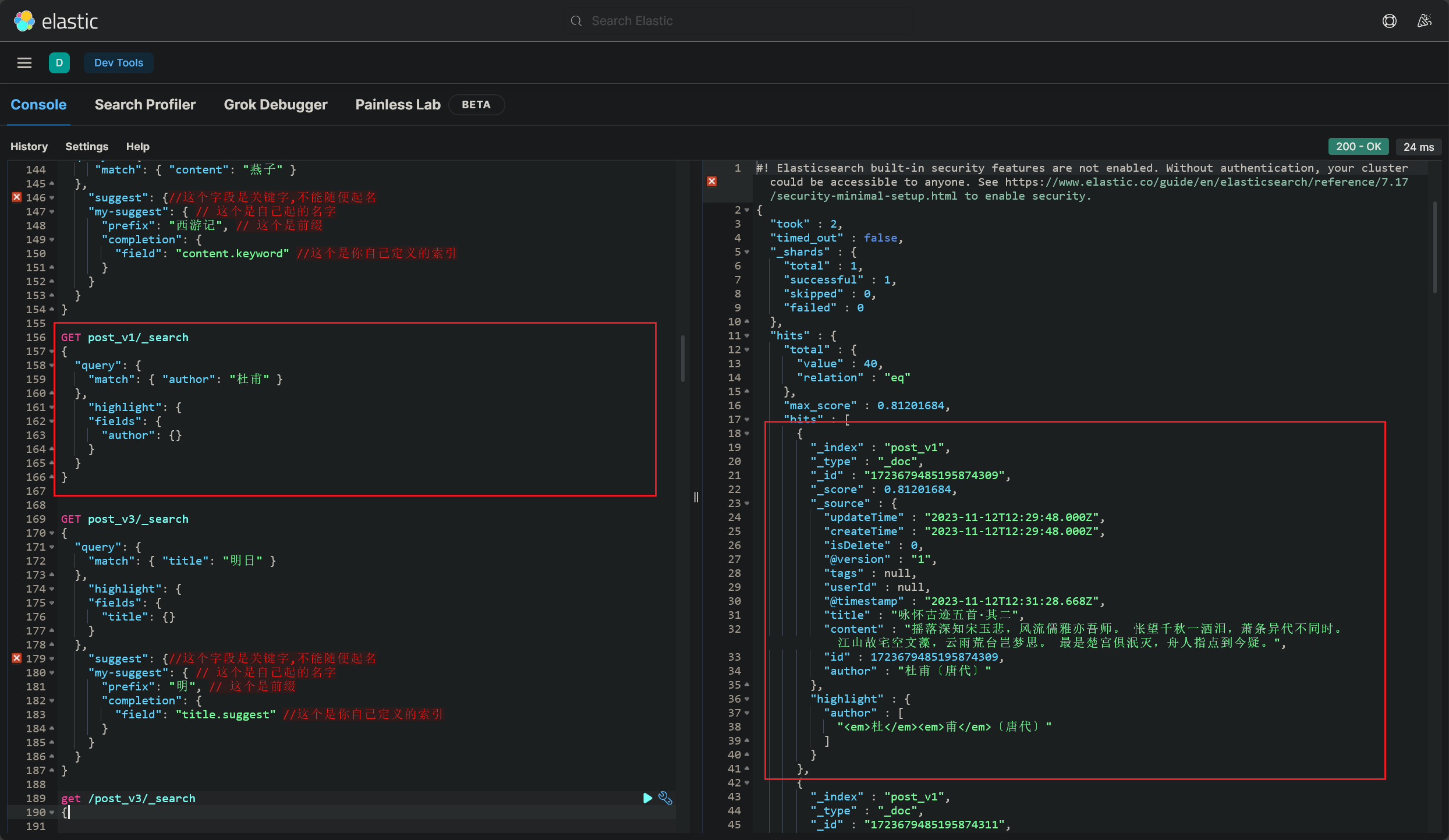
搜索高亮语法,就是查询词和指示高亮字段相配合的结果:
1 2 3 4 5 6 7 8 9 10 11 GET post_v1/ _search
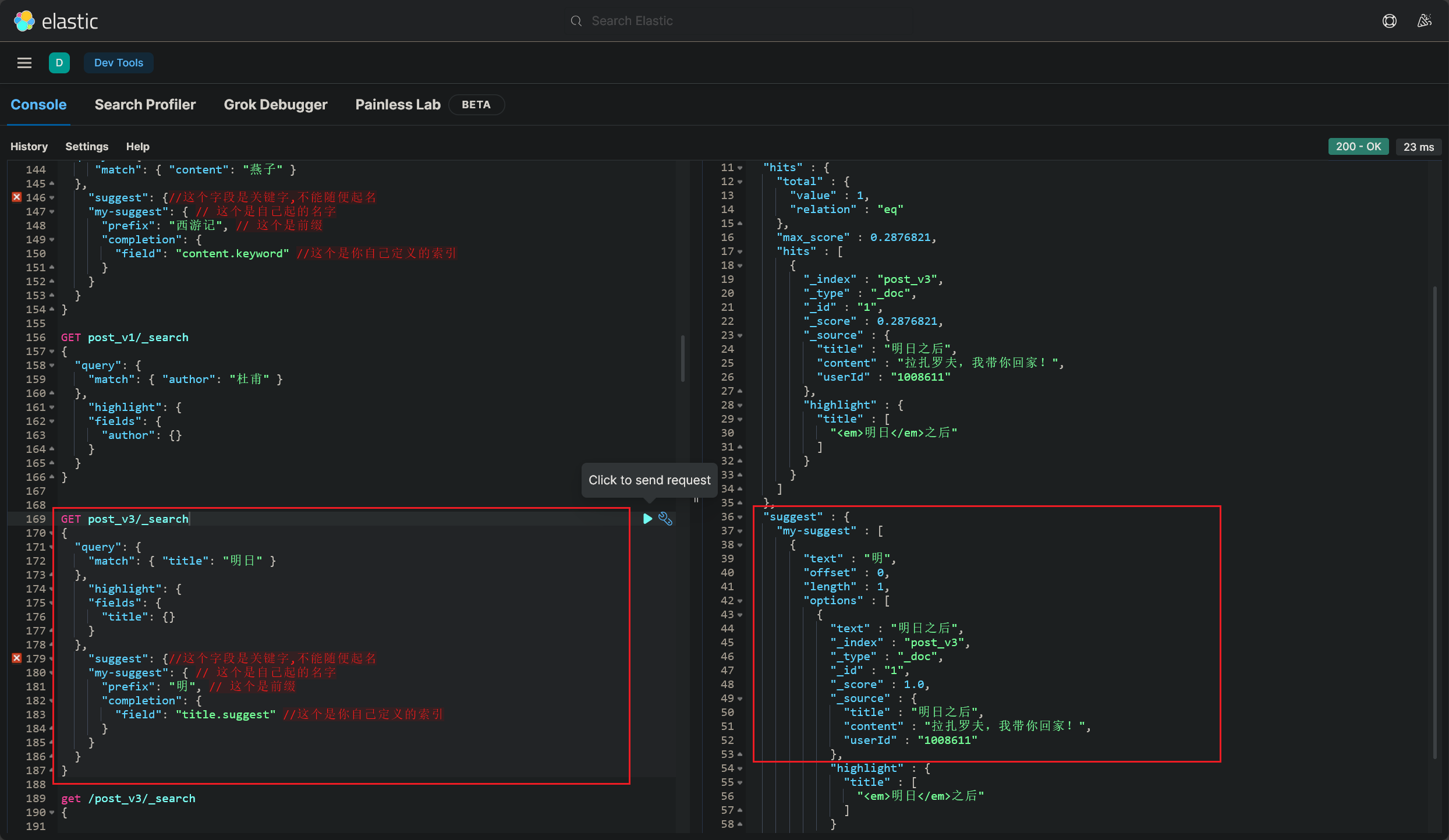
搜索词建议
距离上次搞搜索建议,已经过去半个多月了 (2023/12/03 晚)
🍖 推荐阅读:[ElasticSearch 的搜索建议功能 suggest search(completion suggest)_es suggest-CSDN 博客](https://blog.csdn.net/qq_41489540/article/details/121865225?ops_request_misc={"request_id"%3A"170159810516800211543981"%2C"scm"%3A"20140713.130102334.pc_all."}&request_id=170159810516800211543981&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-121865225-null-null.142^v96^pc_search_result_base5&utm_term=es suggest 搜索建议&spm=1018.2226.3001.4187)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 GET post_v3/ _search/ / 这个字段是关键字,不能随便起名/ / 这个是自己起的名字/ / 这个是前缀/ / 这个是你自己定义的索引
什么是搜索建议?就是根据索引中的某个字段,使用前缀匹配来预先返回该索引字段中的部分文档,就能实现搜索建议
需要注意的是,要想使某个字段支持搜索建议,该字段的值的类型一定要是 completion 的,这里给些代码示例 ,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 PUT / post_v3/ _mapping256 / / 类型是completion,就是自动补全256 / / 类型是completion,就是自动补全
1 2 3 4 5 6 PUT / post_v3/ _doc/ 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 GET post_v3/ _search/ / 这个是前缀/ / 这个是你自己定义的索引
是的,只有配置为 completion 字段的字段才支持搜索建议功能。Completion 字段是 Elasticsearch 中专门用于实现搜索建议功能的字段类型。它可以将输入的前缀映射到某个完整的词,并存储在索引中,以便在搜索时提供建议。
当你在字段上配置了 completion 类型时,Elasticsearch 会为该字段创建一个自动完成的字典,并将输入的前缀映射到字典中的完整词。然后,在搜索时,Elasticsearch 会根据用户输入的前缀来查找匹配的建议,并将它们返回给用户。
因此,如果你希望在 Elasticsearch 索引中使用搜索建议功能,你需要确保相关字段被配置为 completion 类型,以便支持该功能。
在 Elasticsearch 中,为字段创建子字段主要是为了实现多字段索引和搜索需求。在您的示例中,通过在”title”字段下创建一个名为”suggest”的子字段,并将其类型设置为”completion”,您可以实现以下实际应用场景:
搜索建议:当用户在搜索时输入”title”字段中的某个前缀时,Elasticsearch 可以基于”suggest”子字段中的自动完成字典提供搜索建议。这些建议可以帮助用户更快地找到他们想要的结果,提高搜索效率。
不同的索引方式:在”title”字段下创建”suggest”子字段,可以让您在同一字段上使用不同的索引方式。例如,您可以将”title”字段的主要部分作为文本进行索引,以支持全文搜索,同时将相同字段的另一个部分作为 completion 字段进行索引,以支持搜索建议功能。
总之,通过在字段下创建子字段,您可以实现更灵活和特定的索引和搜索需求。这在处理多语言数据、进行特定领域的搜索优化或提高用户体验等方面非常有用。
自动创建索引结构
如果不创建索引结构,而直接插入文档数据,Elasticsearch 底层是会自动创建索引结构的对吧?
是的,Elasticsearch 底层会自动创建索引结构。当你向 Elasticsearch 插入文档数据时,Elasticsearch 会根据文档中的字段和类型自动创建相应的索引映射和类型定义。
在 Elasticsearch 中,自动创建的索引结构的字段类型取决于文档中的字段和数据。Elasticsearch 支持多种字段类型,包括文本、数字、日期、布尔类型等。
在默认情况下,如果文档中包含一个字段,且该字段的值是字符串类型,那么 Elasticsearch 会将该字段的类型设置为”text”类型。此外,如果一个字段的值是一个数字或日期类型,那么 Elasticsearch 会将该字段的类型设置为相应的数字或日期类型。
需要注意的是,在某些情况下,如果文档中包含未在映射中定义的字段,Elasticsearch 可能会自动创建额外的索引映射和类型定义。这可能会导致额外的开销和资源消耗,因此建议在创建索引之前明确定义映射。
总之,虽然 Elasticsearch 底层会自动创建索引结构,但在生产环境中,为了更好的性能和可维护性,建议在创建索引之前明确定义映射。
12 月份的优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 PUT / article_v2256
1 2 3 4 5 PUT / article_v2/ _doc/ 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 GET article_v2/ _search/ / 这个字段是关键字,不能随便起名/ / 这个是自己起的名字/ / 这个是前缀/ / 这个是你自己定义的索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 PUT / article_v3/ _mapping256
持续优化
Memory 聚合搜索平台优化:
新增博文搜索:后端提供博文搜索接口 、前端提供博文列表展示
完善 Gitee 仓库项目介绍
博文搜索实现:新增博文数据库表 Article、ArticleEsDTO、博文 ES 包装类 ArticleEsDTO、博文高亮字段 ArticleEsHighlightData、博文搜索接口 ArticleDataSource (2023/11/06 晚)
待完成:ES 博文数据同步 、ES 博文搜索测试 (ES 博文记录)
分词器
分词器是干啥用的?指定了分词的规则(2023/09/20 午)
内置分词器
空格分词器
1 2 3 4 5 POST _analyze "analyzer" : "whitespace" ,"text" : "The quick brown fox."
关键词分词器
标准分词规则 1 2 3 4 5 6 POST _analyze "tokenizer" : "standard" ,"filter" : [ "lowercase" , "asciifolding" ],"text" : "Is this déja vu?"
分词器 analyze 和分词规则 tokenizer 有什么区别呢?
1 2 3 4 5 6 7 在搜索引擎和文本分析领域中,分词器(Analyzer)和分词规则器(Tokenizer)是两个不同的概念。Term )序列的工具。它通常包含多个处理步骤,例如词法分析、去除停用词、小写转换、词干提取等。分词器的作用是将原始的文本输入转换为可供索引和搜索的标记流。例如,在Elasticsearch中,分词器被用于预处理文本数据并将其存储在倒排索引中,以支持全文搜索。
IK 分词器(ES 内置插件) 下载安装
下载完成,将压缩包解压在 Elasticsearch 的 plugins / ik 目录下即可
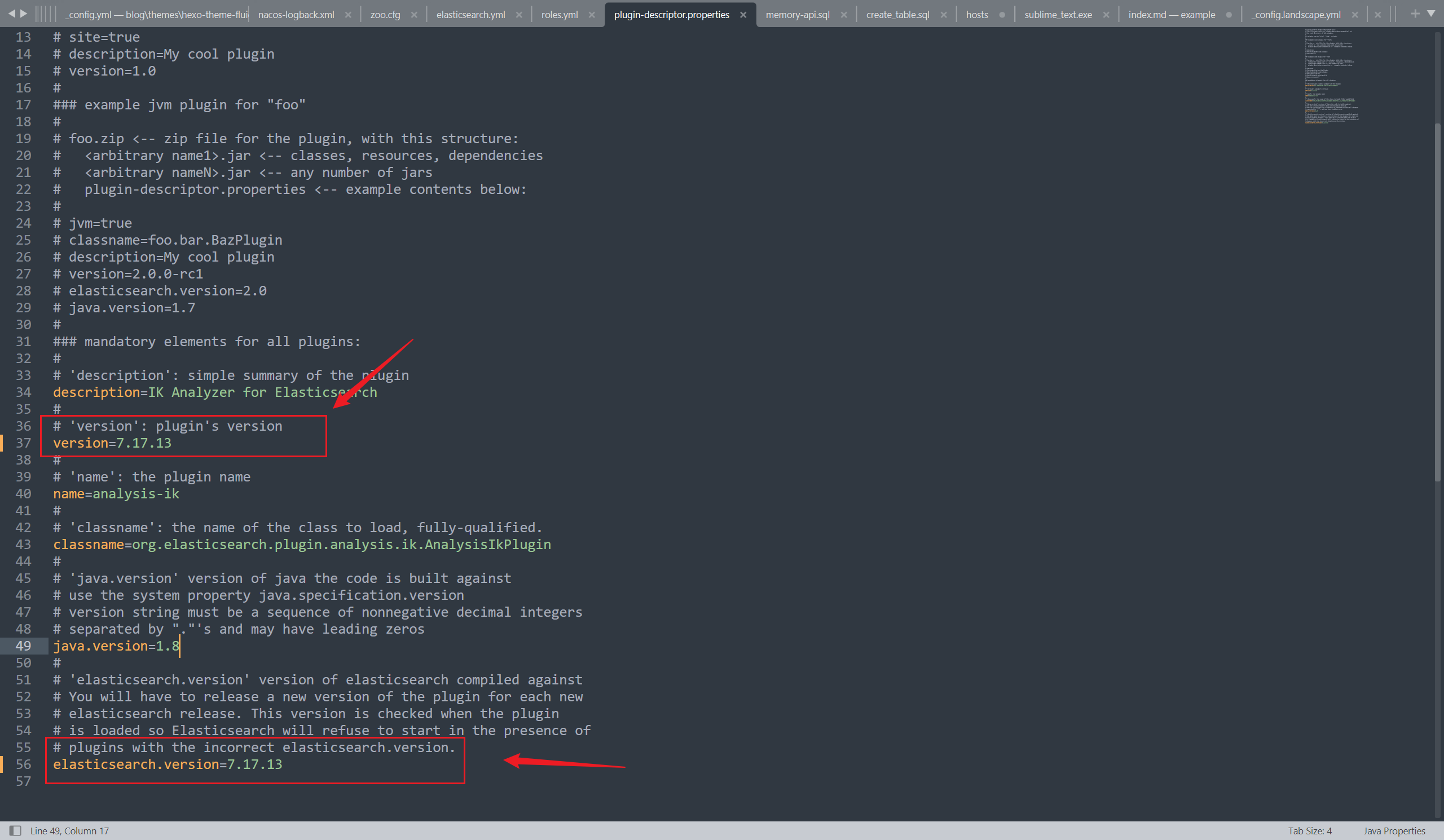
修改版本一致
启动 ES、Kibana
测试分词效果
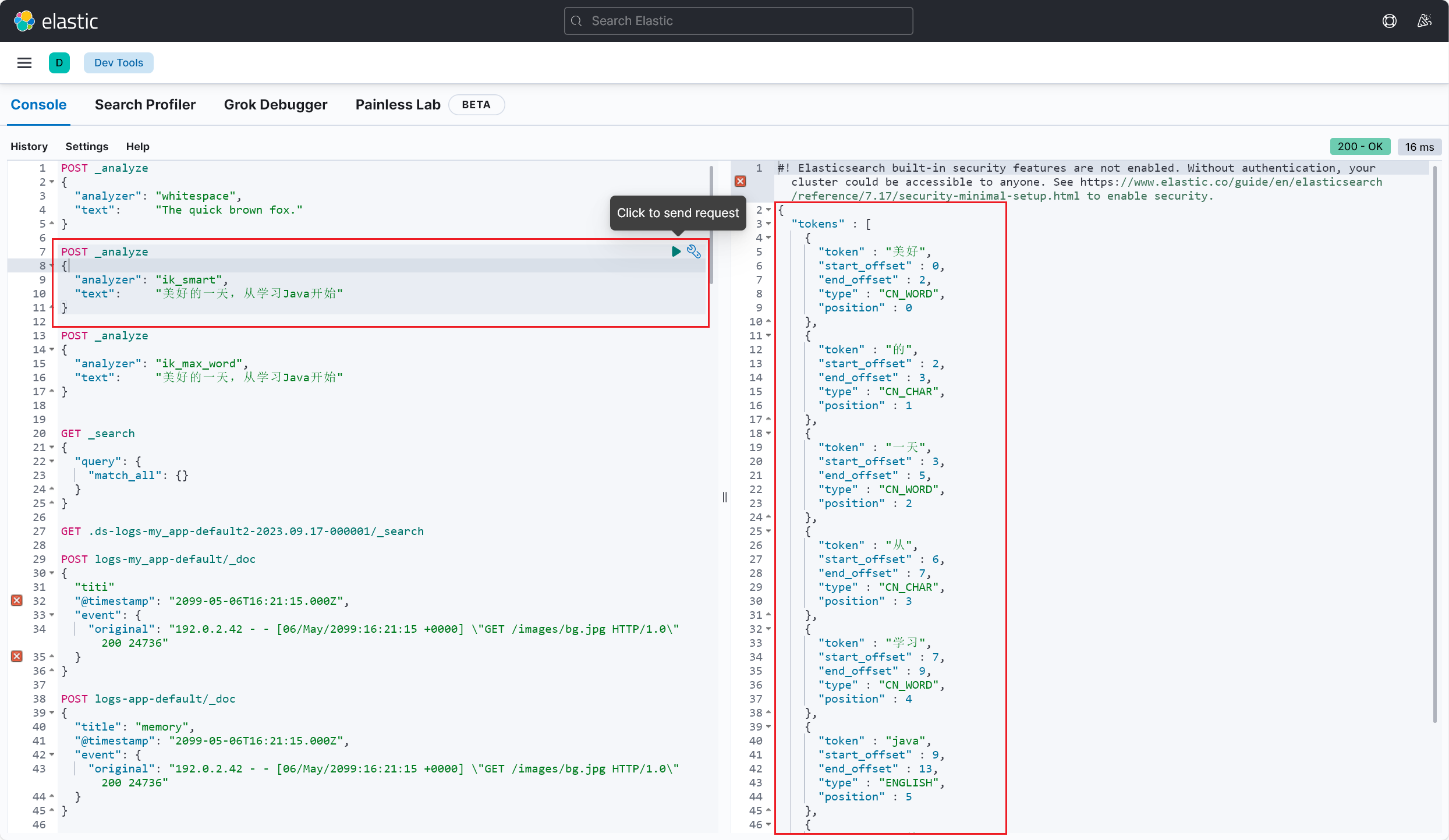
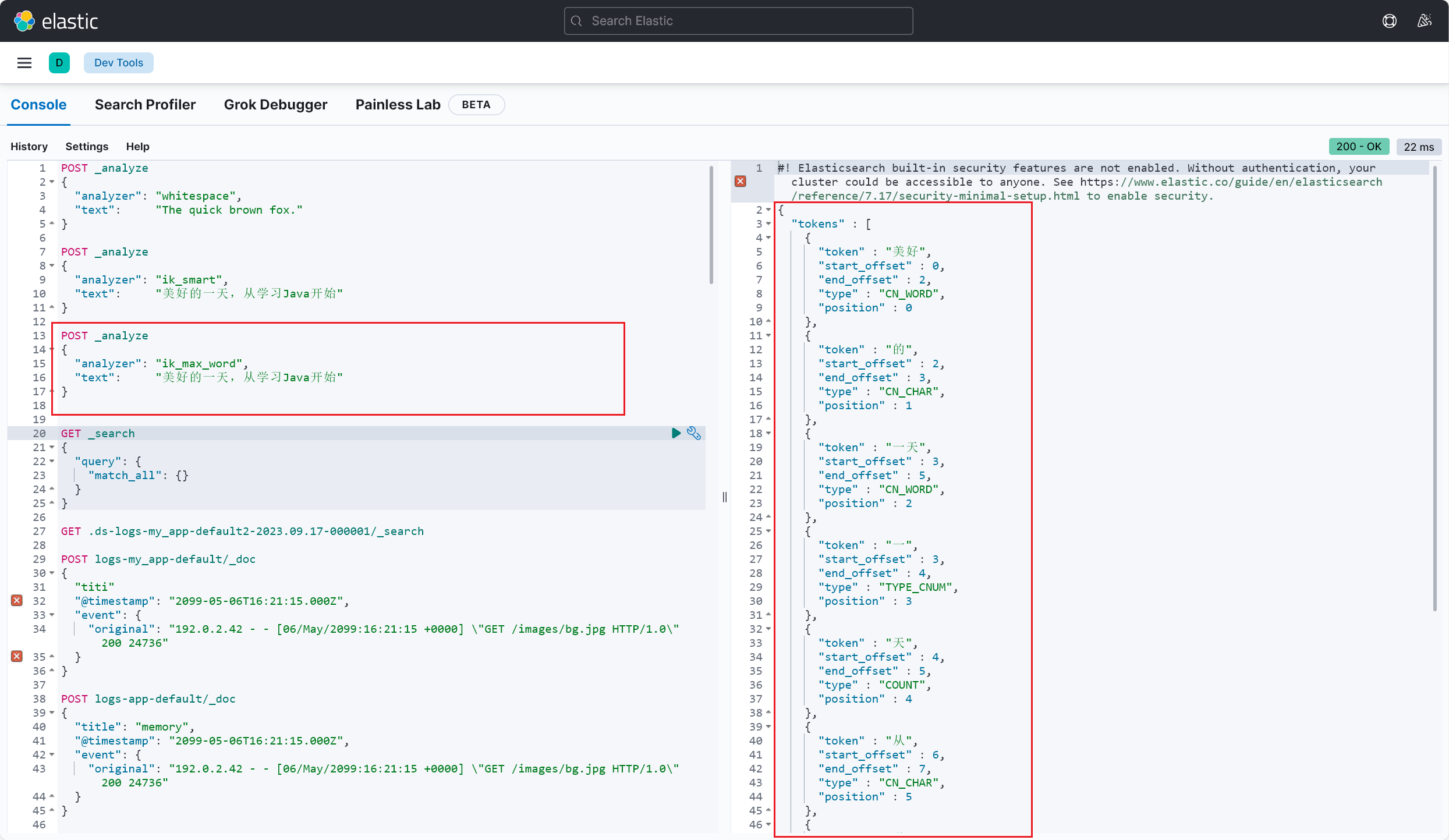
测试成功,这里也能看出来 ik_smart 和 ik_max_word 这两种不同分词模式的区别了(2023/09/20 午)
ik_smart 模式是 IK 分词器的简单模式 ,它会对文本进行较为粗粒度的切分 ,主要以将句子切分为一些较短的词语为目标,适用于快速搜索 和一般文本处理场景。该模式下的分词结果倾向于保留短词ik_max_word 模式是 IK 分词器的细粒度模式 ,它会尽可能多地将文本切分为更小的词语 ,包括一些更细致的切分,如拆分复合词和词组 等。该模式下的分词结果倾向于将文本切分为更多的词
ES 调用方式
Java 操作 ES
ES 实现搜索接口 建立索引
在 ES 中,也存在和 MySQL 类似的表结构,这里可以将二者对比一下:
MySQL Elasticsearch 说明
Table
Index
索引(index),就是文档的集合,类似数据库的表(table)
Row
Document
文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是 JSON 格式
Column
Field
字段(Field),就是 JSON 文档中的字段,类似数据库中的列(Column)
Schema
Mapping
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema)
SQL
DSL
DSL 是 elasticsearch 提供的 JSON 风格的请求语句,用来操作 elasticsearch,实现 CRUD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 create table postbigint auto_increment comment 'id' primary key,varchar (512 ) null comment '标题' ,null comment '内容' ,varchar (1024 ) null comment '标签列表(json 数组)' ,int default 0 not null comment '点赞数' ,int default 0 not null comment '收藏数' ,bigint not null comment '创建用户 id' ,default CURRENT_TIMESTAMP not null comment '创建时间' ,default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间' ,default 0 not null comment '是否删除' '帖子' collate = utf8mb4_unicode_ci;
建立索引语句: ES Mapping:
id(可以不放到字段设置里)
ES 中,尽量存放需要用户筛选 (搜索)的数据
aliases :别名(为了后续方便数据迁移)
字段类型是 text,这个字段是可被分词的、可模糊查询的;而如果是 keyword,只能完全匹配、精确查询。
analyzer (存储时生效的分词器):用 ik_max_word,拆的更碎、索引更多,更有可能被搜出来
search_analyzer (查询时生效的分词器):用 ik_smart,更偏向于用户想搜的分词
如果想要让 text 类型的分词字段也支持精确查询 ,可以创建 keyword 类型的子字段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 POST post_v1"text" ,"analyzer" : "ik_max_word" ,"search_analyzer" : "ik_smart" ,"fields" : {"keyword" ,"ignore_above" : 256 content ": {"text" ,"analyzer" : "ik_max_word" ,"search_analyzer" : "ik_smart" ,"fields" : {"keyword" ,"ignore_above" : 256 "keyword" "keyword" "date" "date" "keyword"
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-elasticsearch</artifactId > </dependency >
1 2 3 4 elasticsearch: uris: http://localhost:9200 username: root password: 123456
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 @Document(indexName = "post") @Data public class PostEsDTO implements Serializable {private static final String DATE_TIME_PATTERN = "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'" ;@Id private Long id;private String title;private String content;private List<String> tags;private Integer thumbNum;private Integer favourNum;private Long userId;@Field(index = false, store = true, type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN) private Date createTime;@Field(index = false, store = true, type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN) private Date updateTime;private Integer isDelete;private static final long serialVersionUID = 1L ;private static final Gson GSON = new Gson ();public static PostEsDTO objToDto (Post post) {if (post == null ) {return null ;PostEsDTO postEsDTO = new PostEsDTO ();String tagsStr = post.getTags();if (StringUtils.isNotBlank(tagsStr)) {new TypeToken <List<String>>() {return postEsDTO;public static Post dtoToObj (PostEsDTO postEsDTO) {if (postEsDTO == null ) {return null ;Post post = new Post ();if (CollectionUtils.isNotEmpty(tagList)) {return post;
1 2 3 public interface PostEsDao extends ElasticsearchRepository <PostEsDTO, Long> {findByUserId (Long userId) ;
增删改查
1 2 @Resource private PostEsDao postEsDao;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Test void testAdd () {PostEsDTO postEsDTO = new PostEsDTO ();5L );"test" );"test" );"java" , "python" ));1 );1 );1L );new Date ());new Date ());0 );
1 2 3 4 5 6 @Test void testFindById () {1L );
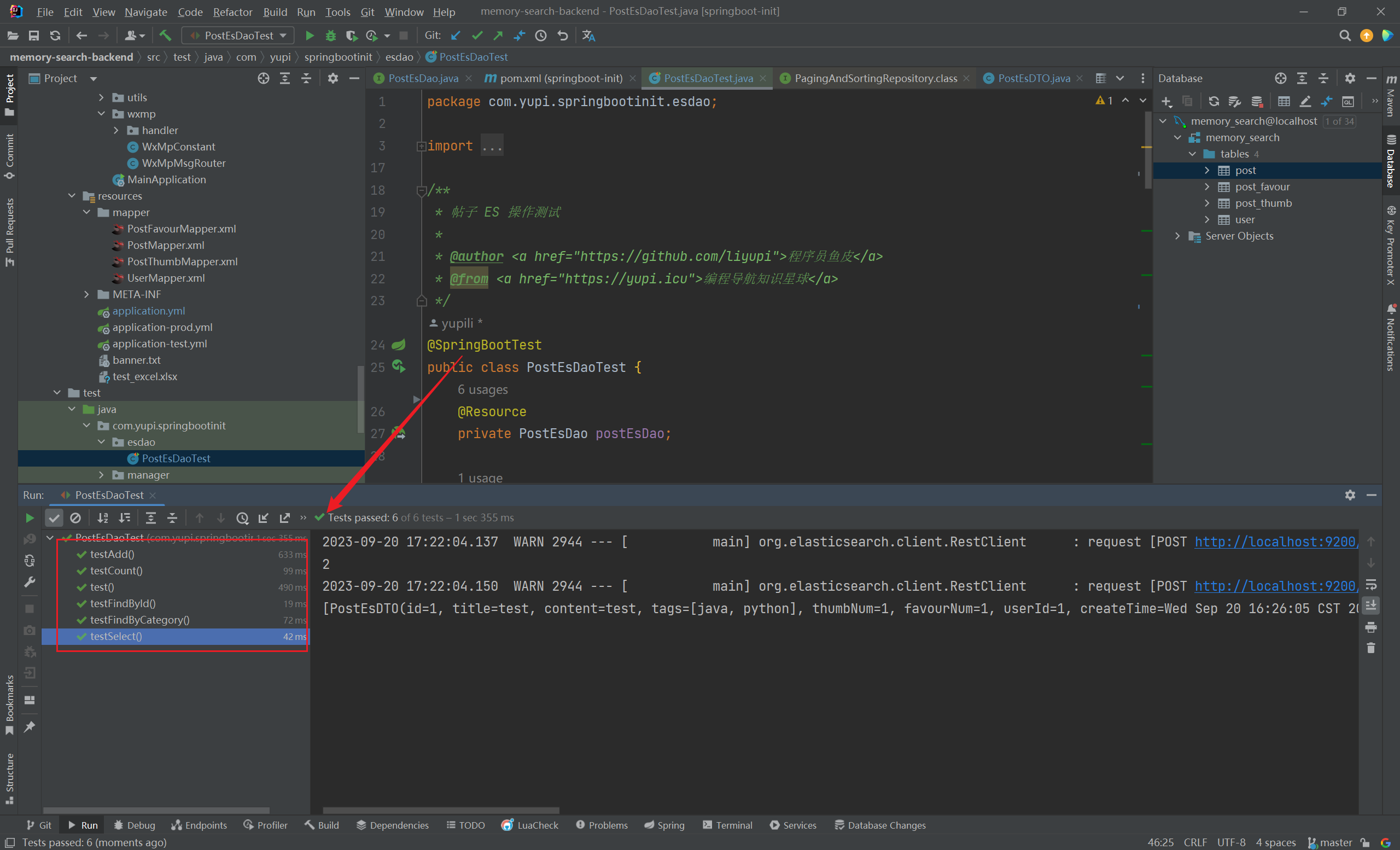
1 2 3 4 5 6 7 8 9 @Test void testSelect () {0 , 5 , Sort.by("createTime" )));
简单的增、删、改、查测试通过:(2023/09/20 晚)
DSL 查询
参考文档: [Query and filter context | Elasticsearch Guide 7.17] | Elastic [Boolean query | Elasticsearch Guide 7.17] | Elastic 详细的 DSL 查询学习可以看官网学习,待我学成归来,就在此留下我的学习笔记(2023/09/21 晚)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET post/ _search/ / 组合条件/ / 必须都满足/ / match 模糊查询/ / term 精确查询/ / range 范围
数据同步
🤡 推荐阅读:4 种 MySQL 同步 ES 方案,yyds! - 掘金 (juejin.cn)
一般情况下,如果做查询搜索 功能,使用 ES 来模糊搜索 (2023/09/21 晚)
但是数据是存放在数据库 MySQL 里 的,所以说我们需要把 MySQL 中的数据和 ES 进行同步 ,保证数据一致 (以 MySQL 为主)
MySQL => ES (单向) 首次安装完 ES,把 MySQL 数据全量同步到 ES 里,写一个单次脚本 4 种方式,全量同步(首次)+ 增量同步(新数据):
定时任务 :比如 1 分钟 1 次,找到 MySQL 中过去几分钟内(至少是定时周期的 2 倍)发 生改变的数据,然后更新到 ES。
优点:简单易懂、占用资源少、不用引入第三方中间件
缺点:有时间差 应用场景:数据短时间内不同步影响不大、或者数据几乎不发生修改
双写 :写数据的时候,必须也去写 ES;更新删除数据库同理。
事务:建议先保证 MySQL 写成功
如果 ES 写失败了,可以通过定时任务 + 日志 + 告警进行检测和修复 (补偿)
Logstash 数据同步管道 :(一般要配合 kafka 消息队列 + beats 采集器)
Canal 监听 MySQL Binlog :实时同步
Logstash
下载安装
demo 测试
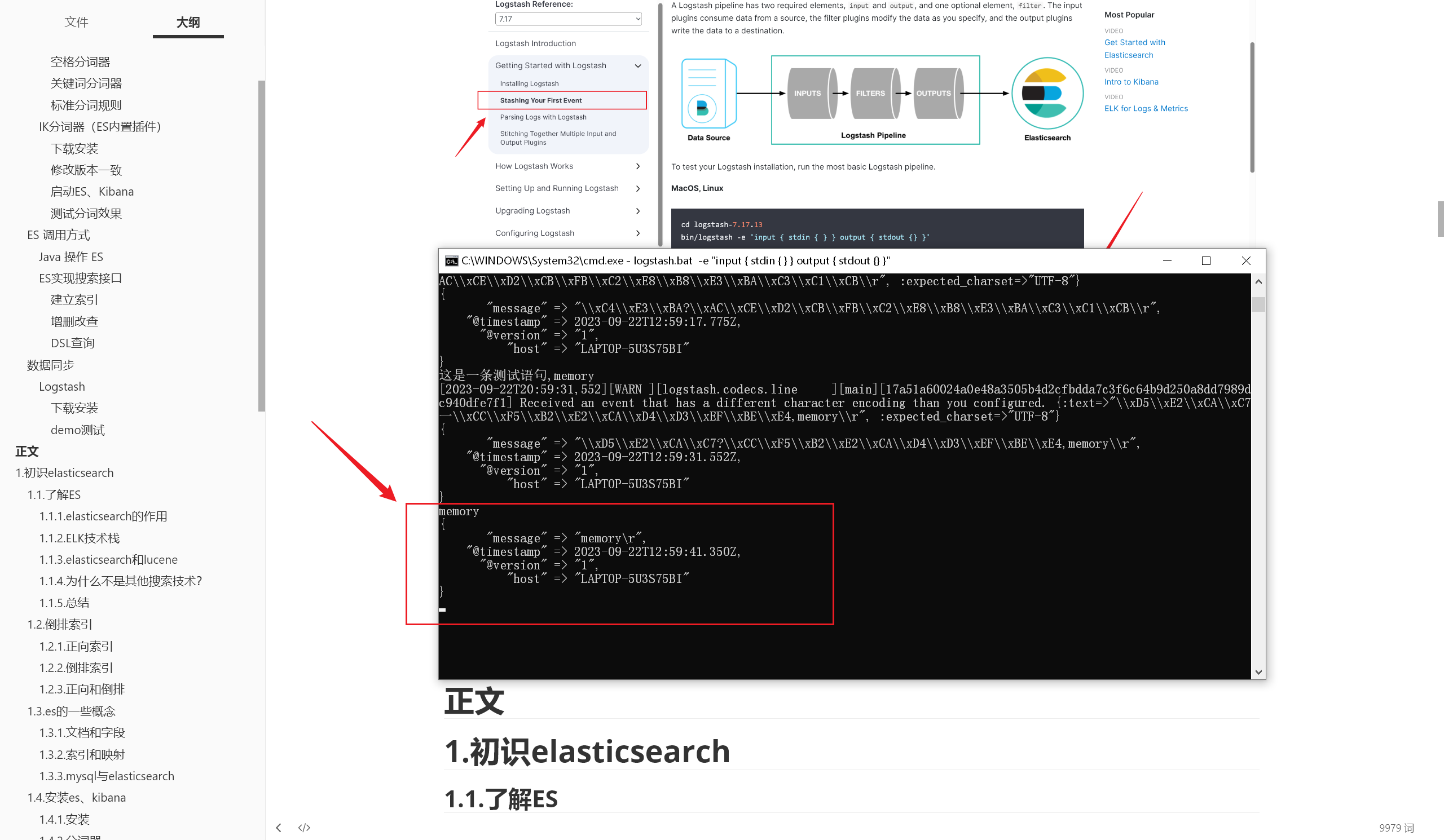
1 logstash.bat -e "input { stdin { } } output { stdout {} }"
自定义配置
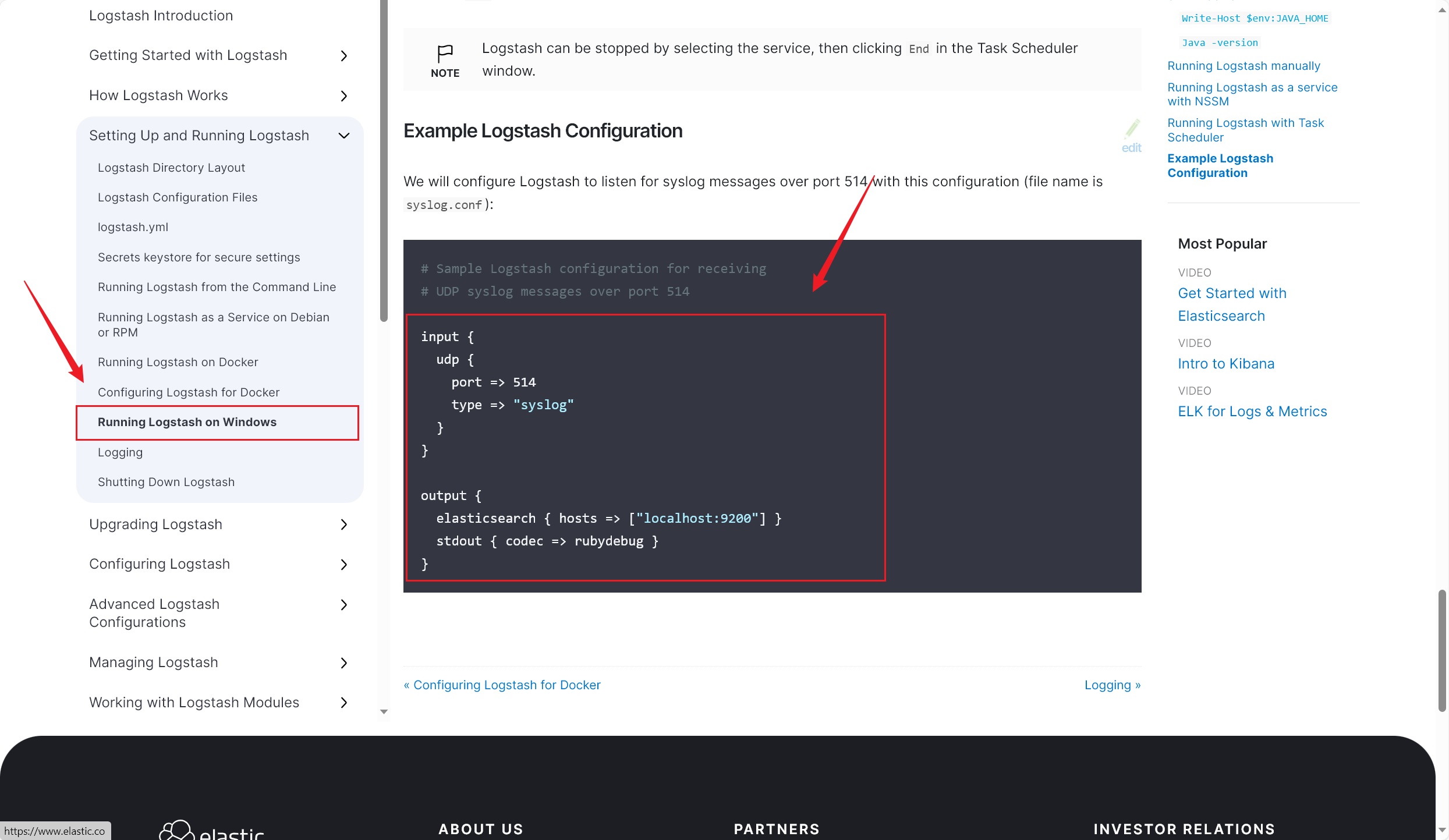
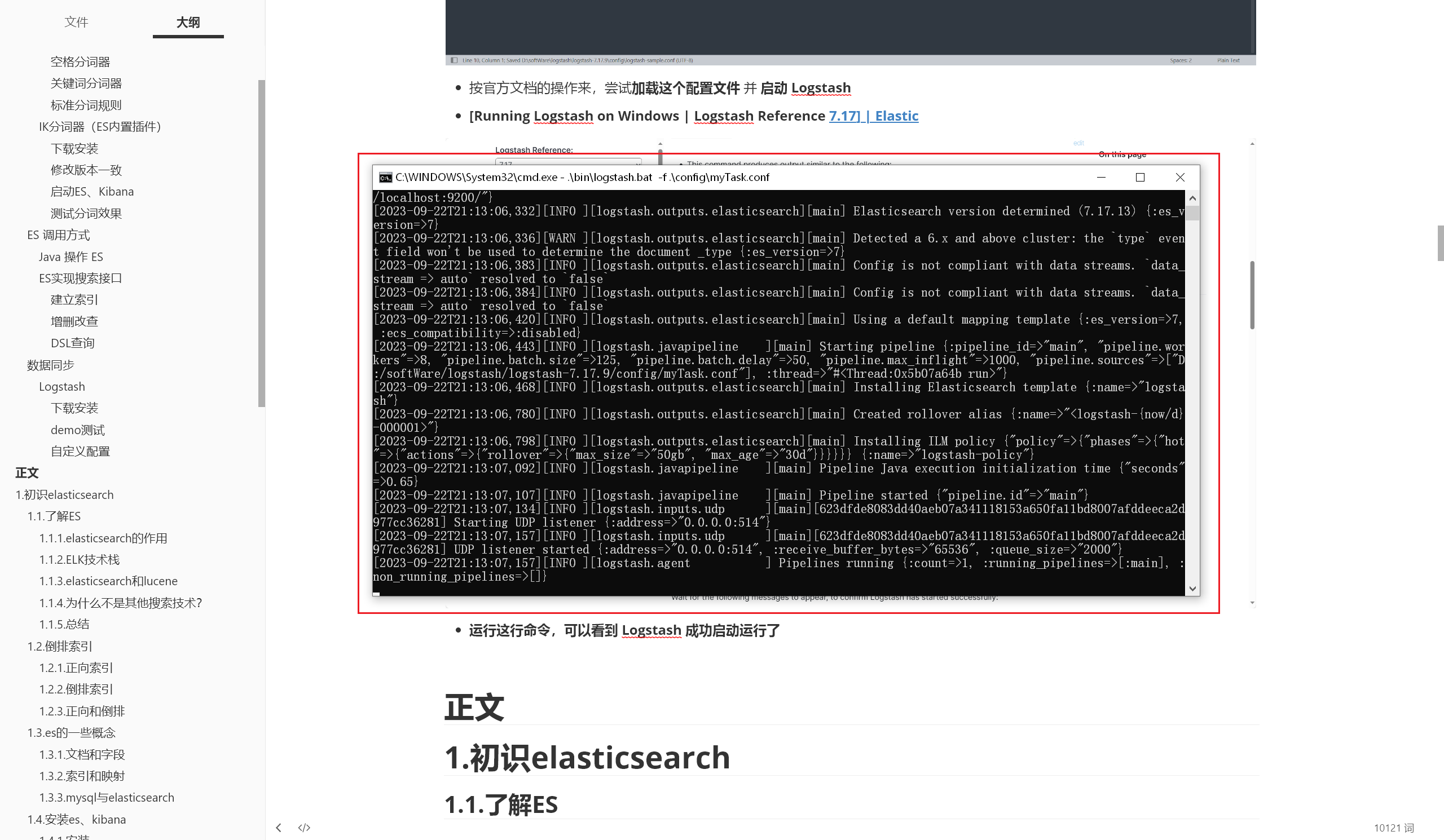
快速开始:[Running Logstash on Windows | Logstash Reference 7.17] | Elastic (2023/09/22 晚) 在官方文档中,找到这一段简单的示例配置:
将这段配置粘贴进 config 下 的 logstash-sample.conf 配置文件(可以保留该原文件,复制一份重命名) 中:
这几行配置是干什么的呢?简单来讲就是定义了输入和输出 :监听 UDP,并输出
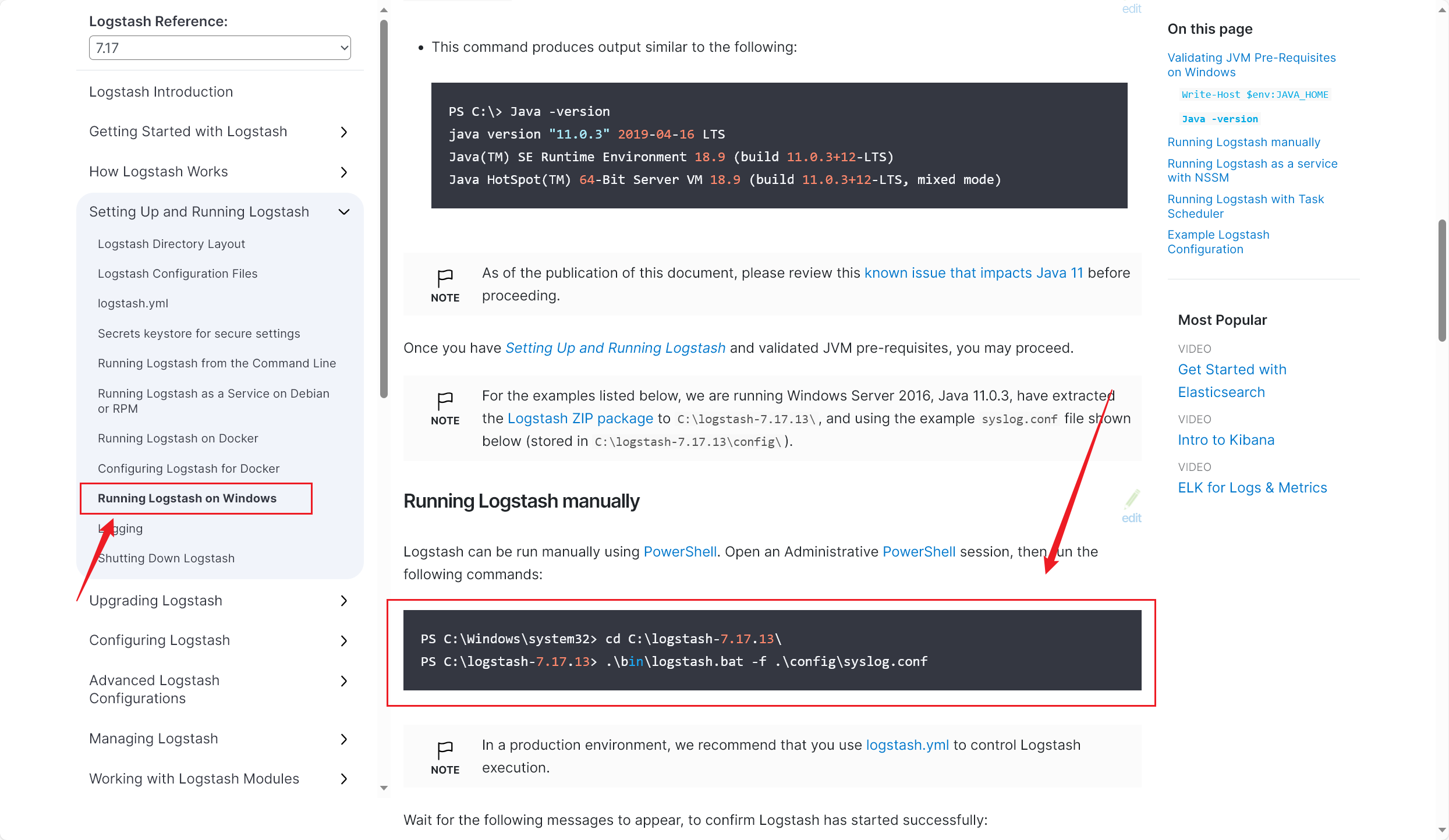
按官方文档的操作来,尝试加载这个配置文件 并 启动 Logstash :
1 .\bin\logstash.bat -f .\config\myTask.conf
运行这行命令,可以看到 Logstash 成功启动运行了
同步 MySQL
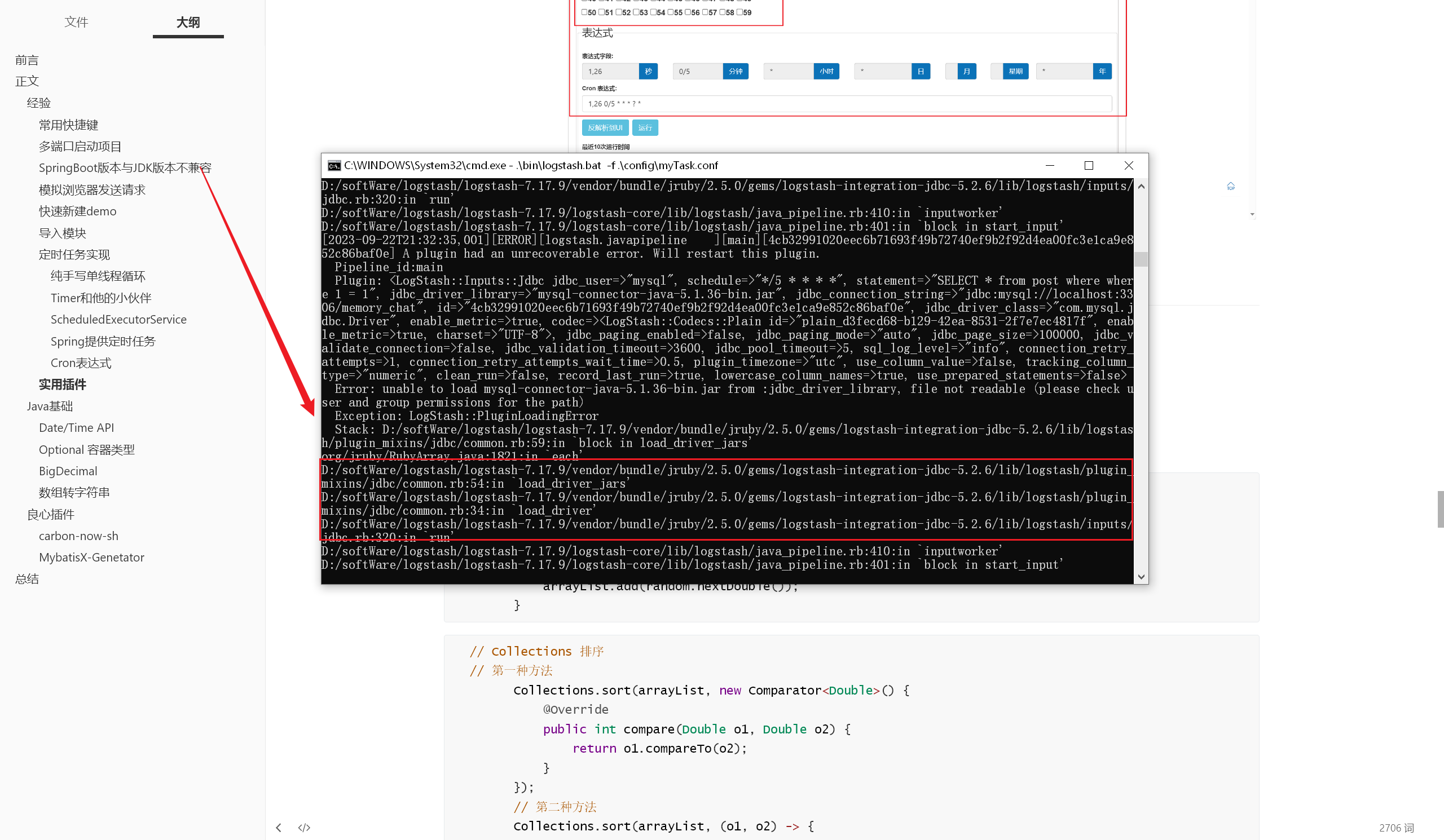
1 2 3 4 5 6 7 8 9 10 11 input {jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb" jdbc_user => "mysql" parameters => { "favorite_artist" => "Beethoven" }schedule => "* * * * *" "SELECT * from songs where artist = :favorite_artist"
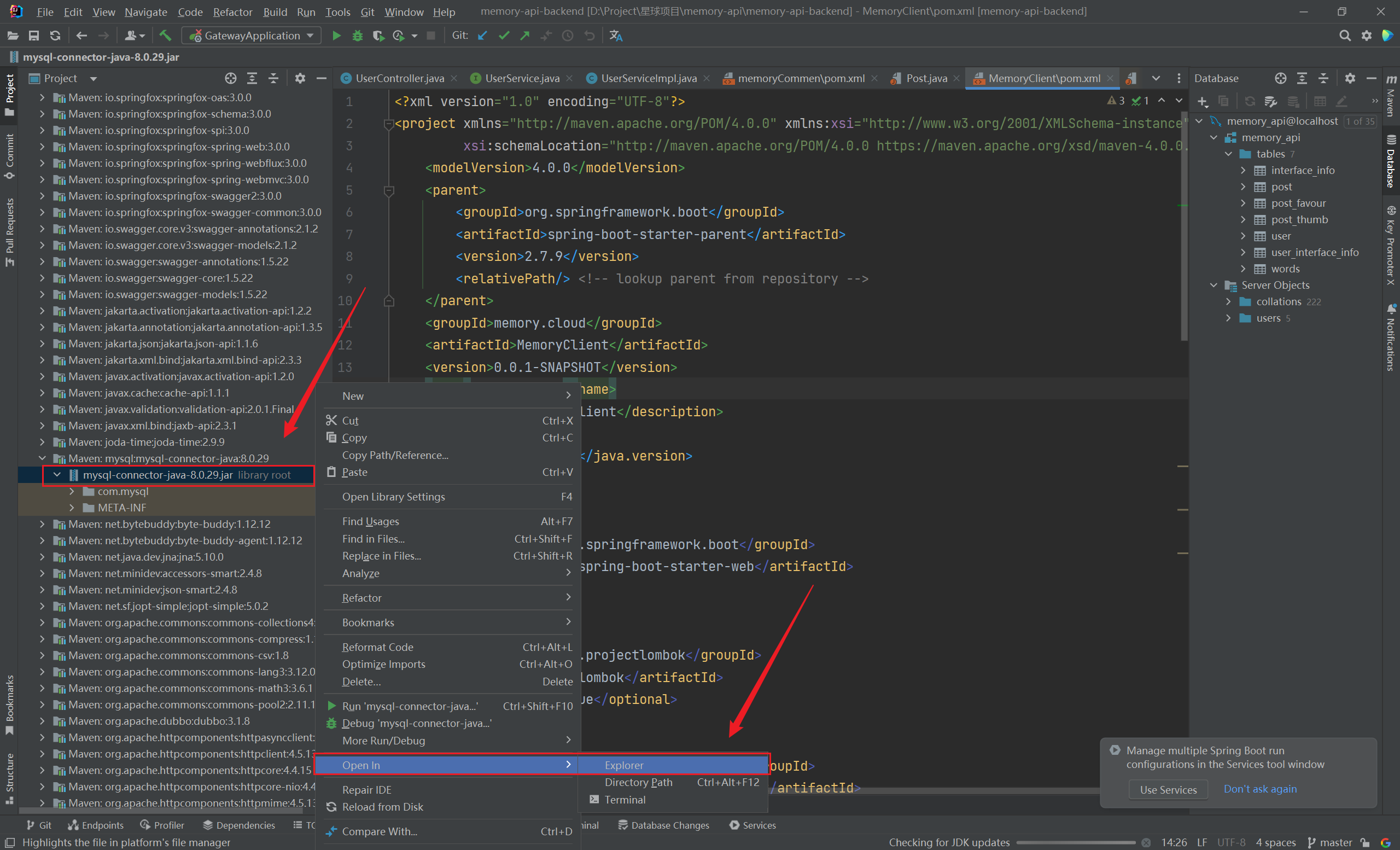
原因很简单,就是配置中的 mysql jar 包找不到,我们需要自己配置一个 mysql jar 包,并正确配置它的路径 这里有个技巧:在 IDEA 中找到项目所依赖的 jar 包
如图所示,选择对应的依赖后,可以直接在文件管理器中打开
然后直接在文件管理器中复制,粘贴到 Logstash 目录下即可
加载配置、启动 Logstash,启动成功了:
聊聊我在这段配置上踩过的坑吧:
mysql jar 包路径外层多加了一层双引号
用户名、密码配置错误
SQL 语句中 where 多写了一个
timestamp 写成 timestampe
这段配置绝对不能出现任何问题,否则就会出现严重的报错。我的最终配置是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/memory_search" jdbc_user => "root" jdbc_password => "Dw990831" statement => "SELECT * from post where 1 = 1" schedule => "*/5 * * * *" output {codec => rubydebug }
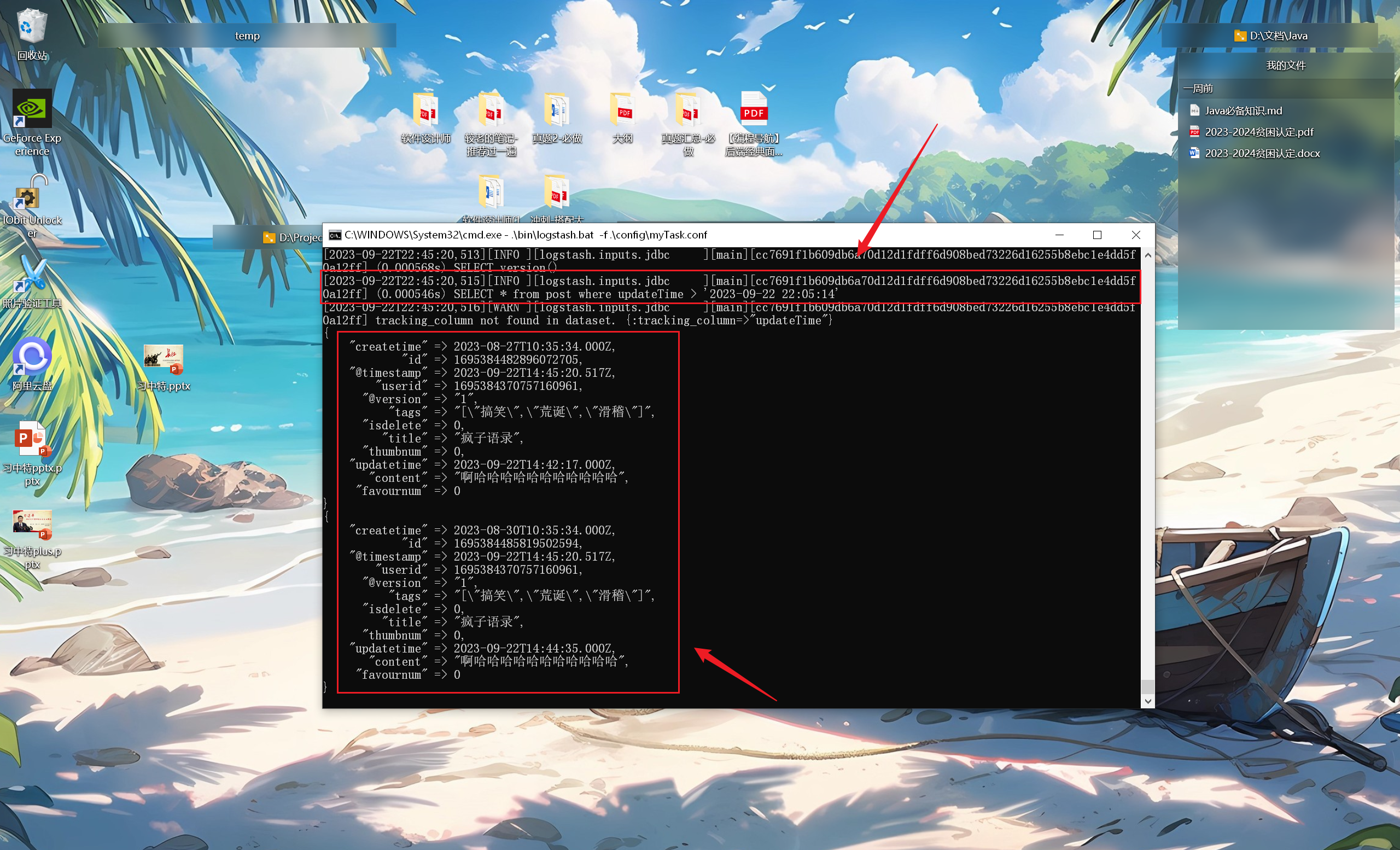
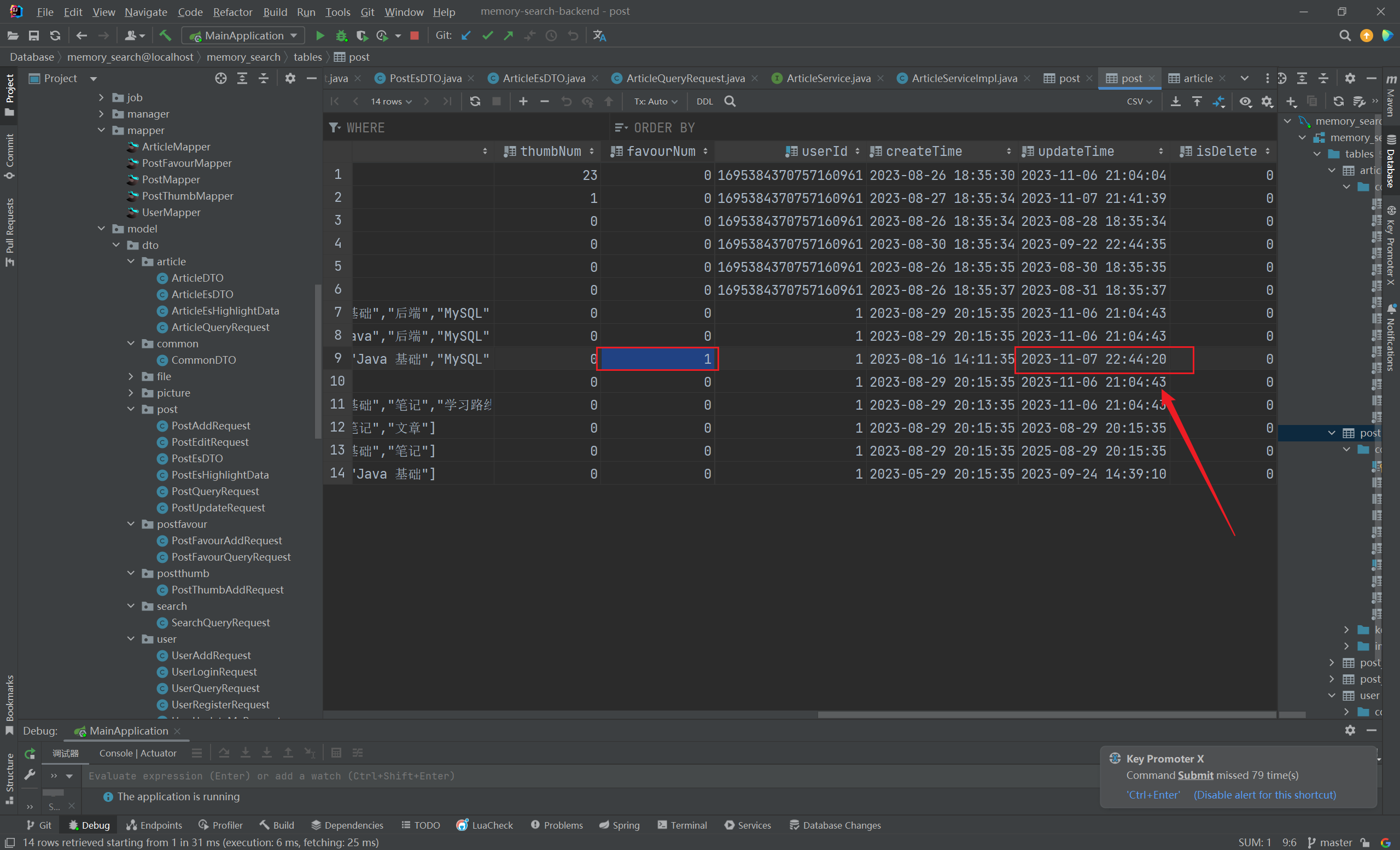
1 2 3 4 5 6 statement => "SELECT * from post where updateTime > :sql_last_value" use_column_value => true tracking_column_type => "timestamp" tracking_column => "updateTime" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai"
这段配置就是根据 updateTime 字段的最新值,同步 updateTime 大于最新值的数据:
所以说,sql_last_value 指定的是上次查到的数据的最后一行的指定字段 ,新的查询就是比较这个指定字段与 sql_last_value 的大小
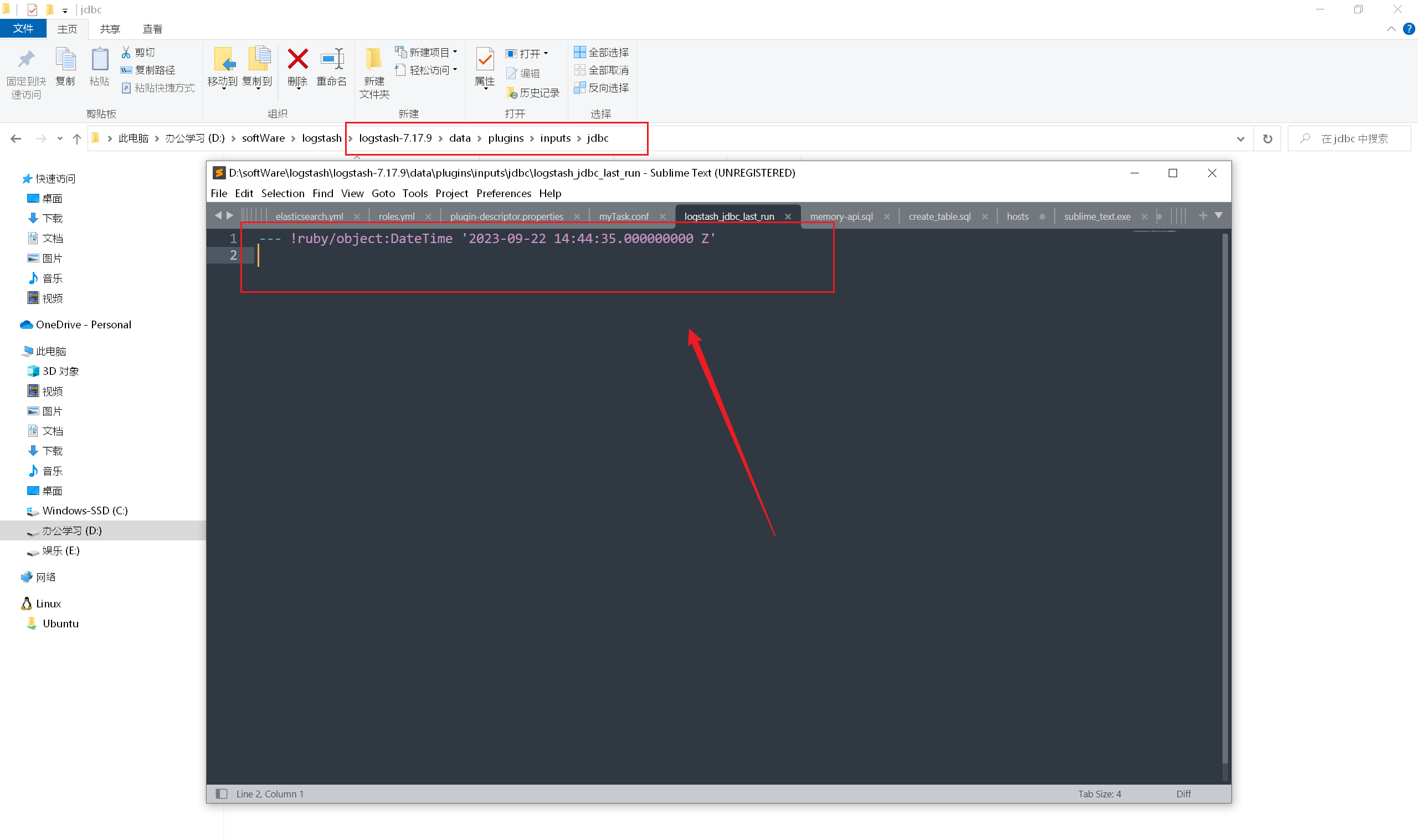
但是经过多次查询发现,这里的 sql_last_value 始终不变
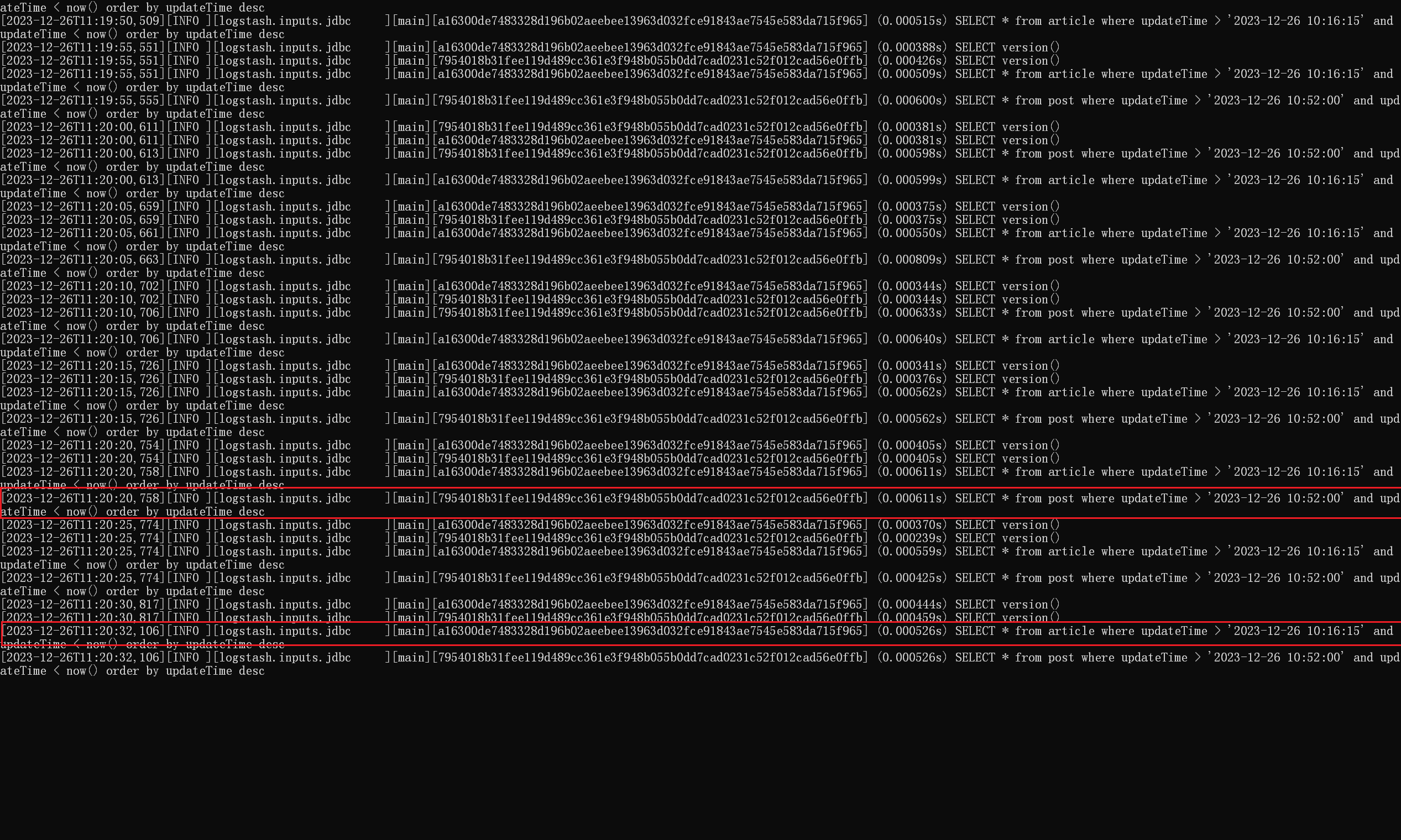
我们可以在 data\plugins\inputs\jdbc\logstash_jdbc_last_run 看到 sql_last_value 指定的数据 ,确实没有变化:
将 tracking_column => “updateTime” 的 updateTime 修改为 updatetime ,日期同步成功
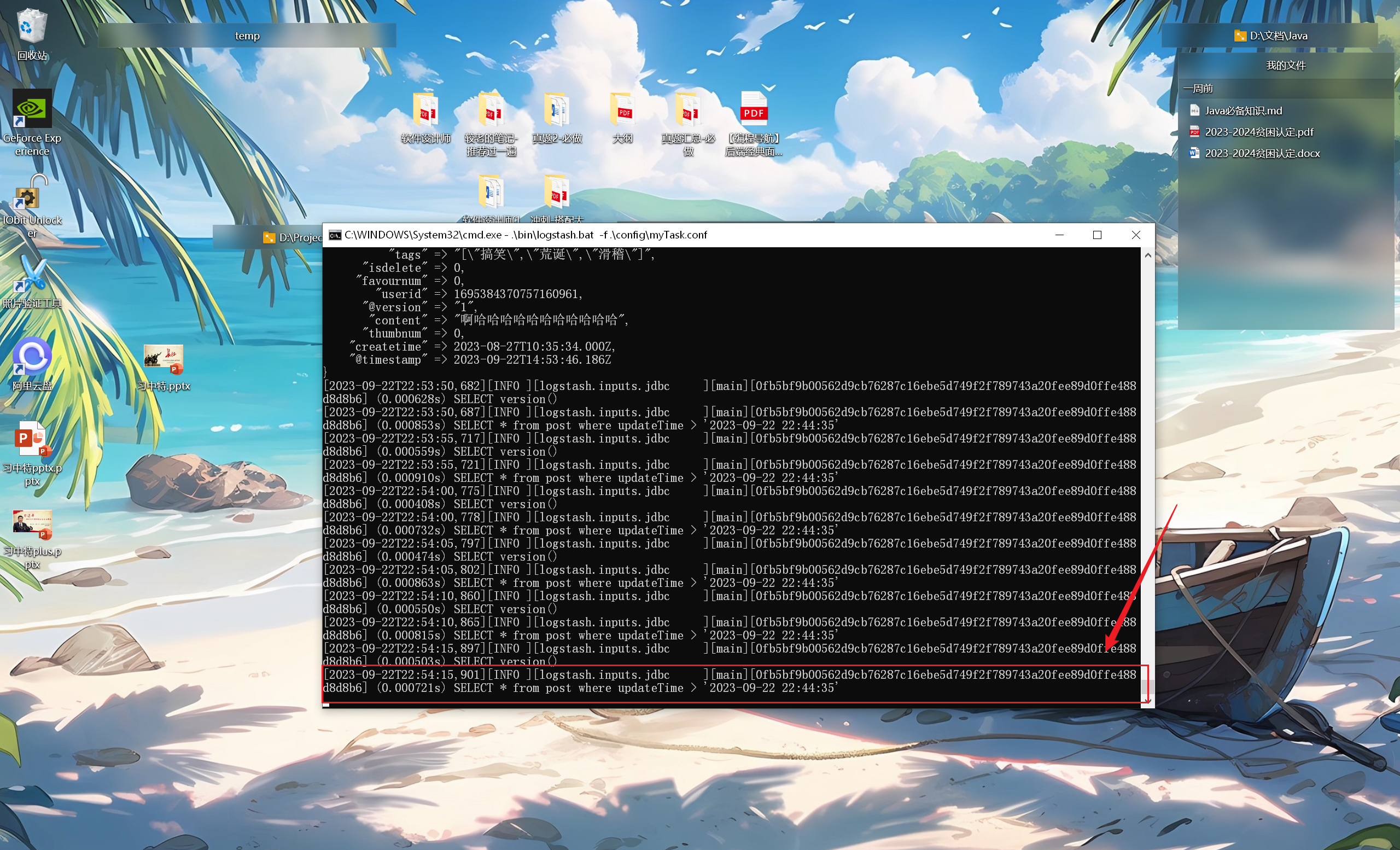
更新下数据库中的最新值,再看看效果,确实拿到了数据库中最新修改的值(参照上次修改后的最新值):
同步 ES
跟着官网简单的 demo 学就行,配置过一次就会了,这是我完成同步 ES 后的配置 :(部分私密信息已做处理 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/" ******"" jdbc_user => "******" jdbc_password => "" ******"" statement => "SELECT * from post where updateTime > :sql_last_value" use_column_value => true tracking_column_type => "timestamp" tracking_column => "updatetime" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai" output {codec => rubydebug }elasticsearch {hosts => "127.0.0.1:9200" index => "post_v1" document_id => "%{id}"
这里简单介绍下这几个配置的作用:
host :标识要进行同步的 ES 地址,即指定了:数据从 MySQL 中取出后,发送到哪 index :目标索引document_id :指定目标索引内,每一个文档的 id,就是从 SELECT * 中解构出 id 值 data_stream :特殊的数据格式,我们从数据库中取到的都是普通类型 ,不需要这行配置
其他的目前暂且不需要了解,日后再进一步学习
加载配置,运行 Logstash,可以看到运行成功了,数据库中最新更新的数据也成功同步到了本地的 ES 上了:
从同步结果来看,我们还需要解决几个问题:
排除某些不需要同步的字段
ES 中同步过来的文档数据字段都是全小写,不是驼峰式
查询结果按 updateTime 降序排列,避免重排序,导致多同步了不必要的数据,造成性能浪费
解决这三个问题当然很简单:
首先修改下 SQL 语句:(2023/09/23 午)
1 statement => "SELECT * from post where updateTime > :sql_last_value and updateTime < now() order by updateTime desc "
再写入如下过滤配置,将对应字段进行驼峰式转换,并排除不需要的字段:
1 2 3 4 5 6 7 8 9 10 11 filter {rename => {"updatetime" => "updateTime" "userid" => "userId" "createtime" => "createTime" "isdelete" => "isDelete" "thumbnum" , "favournum" ]
重新进行同步,结果完美,顺利完成:
Logstash 配置多个输入 / 输出源(已废弃,参考 Ⅱ)
🔥 最近在优化 Memory 聚合搜索平台,尝试实现博文 article 的快速搜索和关键词高亮显示等功能
主要工作如下:(2023/11/07 晚)
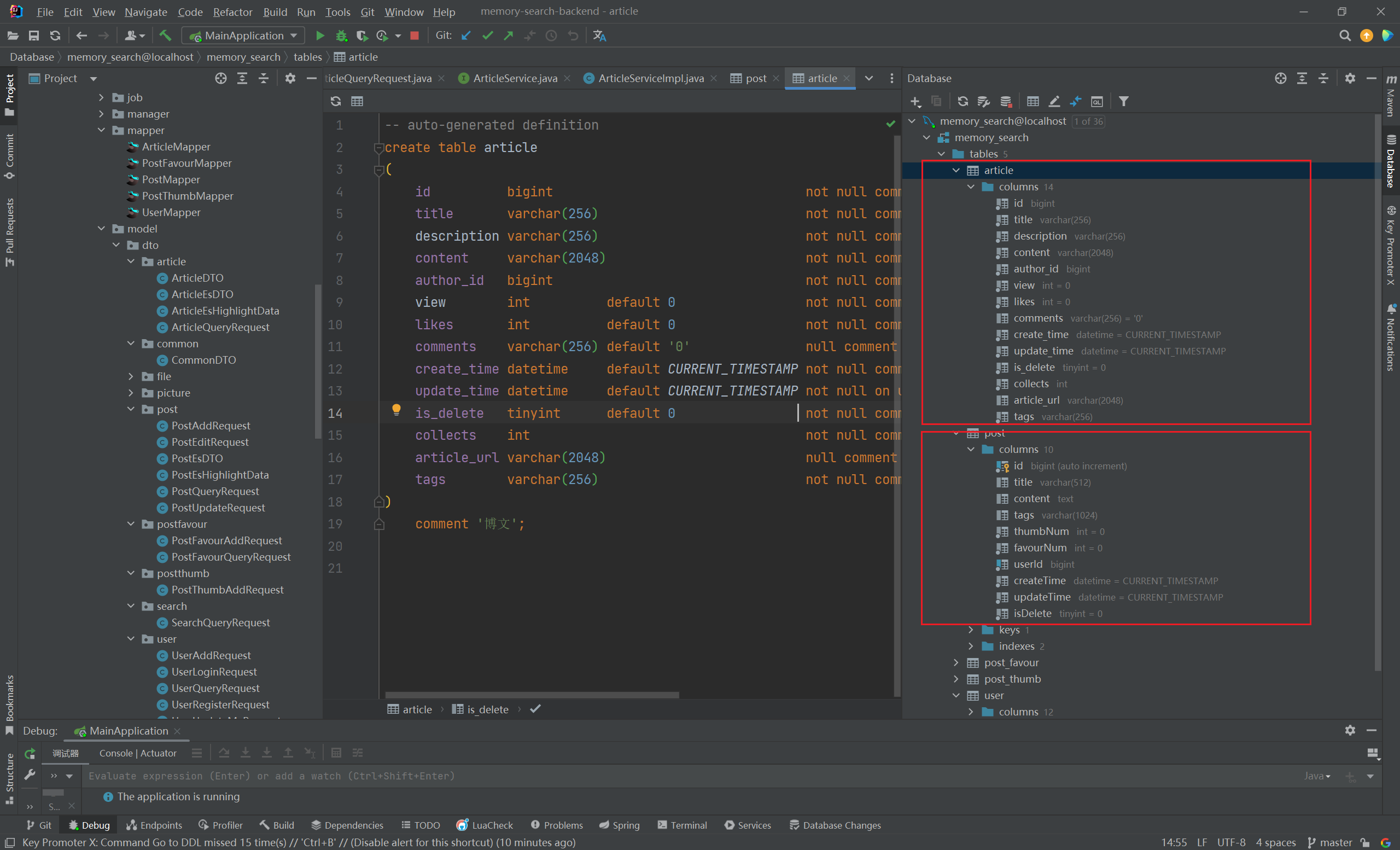
新增 article 实体,表结构 已给出 👇
新增博文的 ES 包装类 (ArticleEsDao)、博文查询参数 (ArticleQueryRequest)、博文高亮字段 (ArticleEsHighlightData)
使用 Spring Data Elasticsearch 的 QueryBuilder 组合条件查询 ,实现使用 ES 快速搜索博文 和关键词高亮显示
新增博文数据源接口 (ArticleDataSource),供聚合搜索调用
配置 Logstash 实现 MySQL 和 ES 数据同步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 create table articlebigint not null comment '文章id' ,varchar (256 ) not null comment '文章标题' ,varchar (256 ) not null comment '文章摘要' ,varchar (2048 ) not null comment '文章内容' ,bigint not null comment '创作者' ,view int default 0 not null comment '浏览量' ,int default 0 not null comment '点赞量' ,varchar (256 ) default '0' null comment '评论量' ,default CURRENT_TIMESTAMP not null comment '创建时间' ,default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间' ,default 0 not null comment '逻辑删除' ,int not null comment '收藏量' ,varchar (2048 ) null comment '封面图片' ,varchar (256 ) not null comment '文章标签' '博文' ;
同步配置
新增 article 相关实体的过程这里先不细讲 ,重点记录:如何实现 MySQL 和 ES 数据同步
在 Logstash 的 config 目录 下,我们作如下配置:(2023/11/07 晚)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/******" jdbc_user => "******" jdbc_password => "******" statement => "SELECT * from article where update_time > :sql_last_value and update_time < now() order by update_time desc" use_column_value => true tracking_column_type => "timestamp" tracking_column => "update_time" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai" input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/******" jdbc_user => "******" jdbc_password => "******" statement => "SELECT * from post where updateTime > :sql_last_value and updateTime < now() order by updateTime desc" use_column_value => true tracking_column_type => "timestamp" tracking_column => "updatetime" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai" filter {rename => {"updatetime" => "updateTime" "userid" => "userId" "createtime" => "createTime" "isdelete" => "isDelete" remove_field => ["thumbnum" , "favournum" ]output {codec => rubydebug }elasticsearch {hosts => "127.0.0.1:9200" index => "post_v1" document_id => "%{id}" output {codec => rubydebug }elasticsearch {hosts => ["localhost:9200" ]index => "article_v1" document_id => "%{id}"
🥣 我们废话少说,看清楚如上配置 👆
比较有趣的是,新增的 article 实体 的字段是下划线命名法 ,而 post 实体 的字段却是驼峰命名法 :
这样的属性名肯定是不规范的 (当然,是因为 article 是我从 Memory 缘忆交友社区下直接粘贴过来的 )
不过,正好可以比对下不同命名规范的属性 ,在 Logstash 配置中的写法区别了:(2023/11/07 晚)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 -- 下划线命名法input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/******" jdbc_user => "******" jdbc_password => "******" statement => "SELECT * from article where update_time > :sql_last_value and update_time < now() order by update_time desc" use_column_value => true tracking_column_type => "timestamp" tracking_column => "update_time" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 -- 驼峰命名法input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/******" jdbc_user => "******" jdbc_password => "******" statement => "SELECT * from post where updateTime > :sql_last_value and updateTime < now() order by updateTime desc" use_column_value => true tracking_column_type => "timestamp" tracking_column => "updatetime" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai"
ES 查询
Logstash 同步配置写完之后,当然要进行测试了,看看数据是否成功从 MySQL 成功同步到了 ES 中
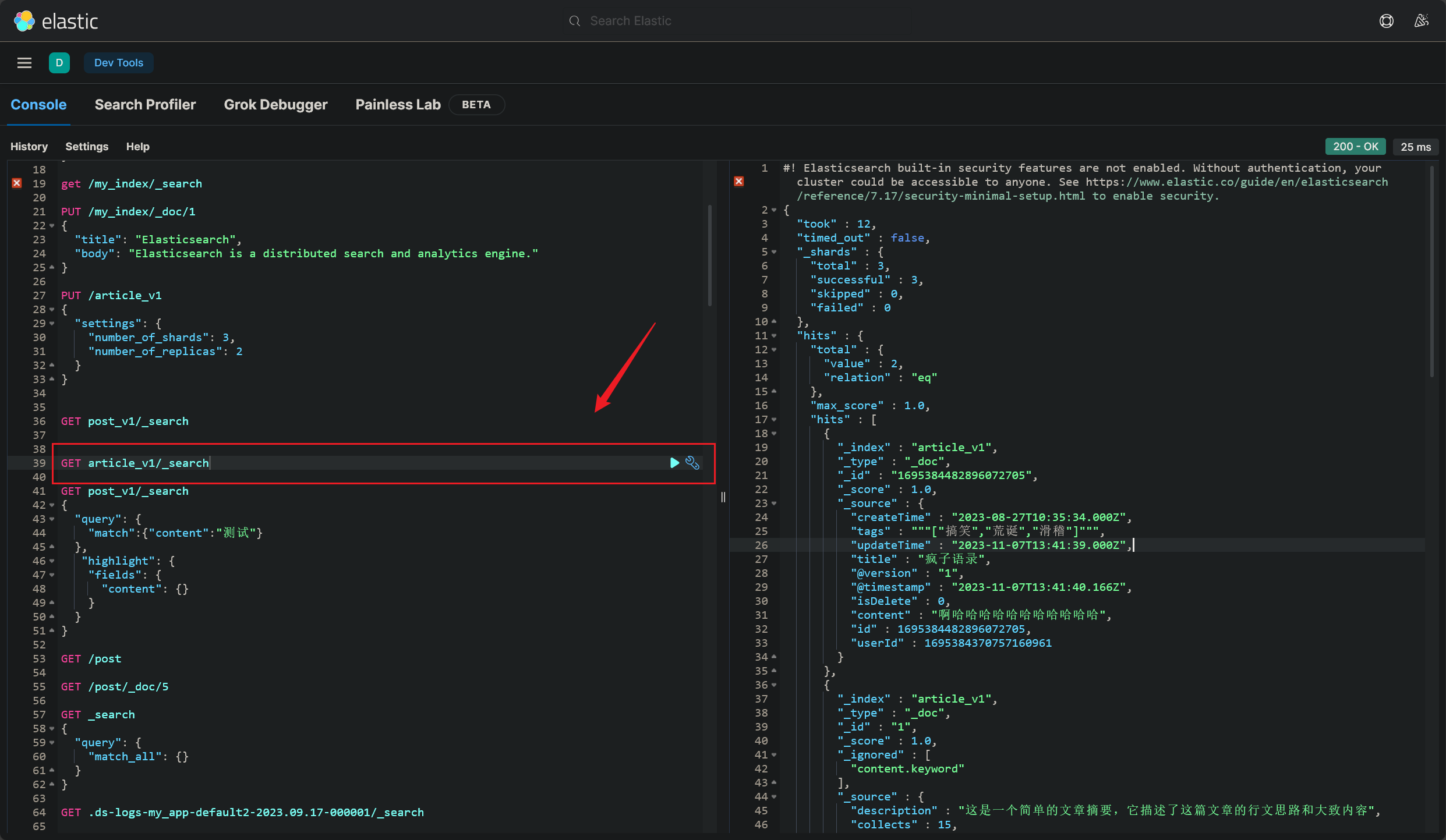
首先新增 ES 索引 ,在 Kibana 监控面板下 ,执行如下 DSL 语句:
1 2 3 4 5 6 7 PUT /article_v1"settings" : {"number_of_shards" : 3,"number_of_replicas" : 2
🔥 注意:
索引名要跟 Logstash 配置中 output 块下的 index 属性对应:
跟 ArticleEsDao 的 Document 字段对应:
1 @Document(indexName = "article_v1")
按官方文档的操作来,尝试加载这个配置文件 并 启动 Logstash :
1 .\bin\logstash.bat -f .\config\myTask.conf
随便修改一条记录 (下面的实现 updateTime 字段自动更新一栏中有提到,数据开始同步 👇:
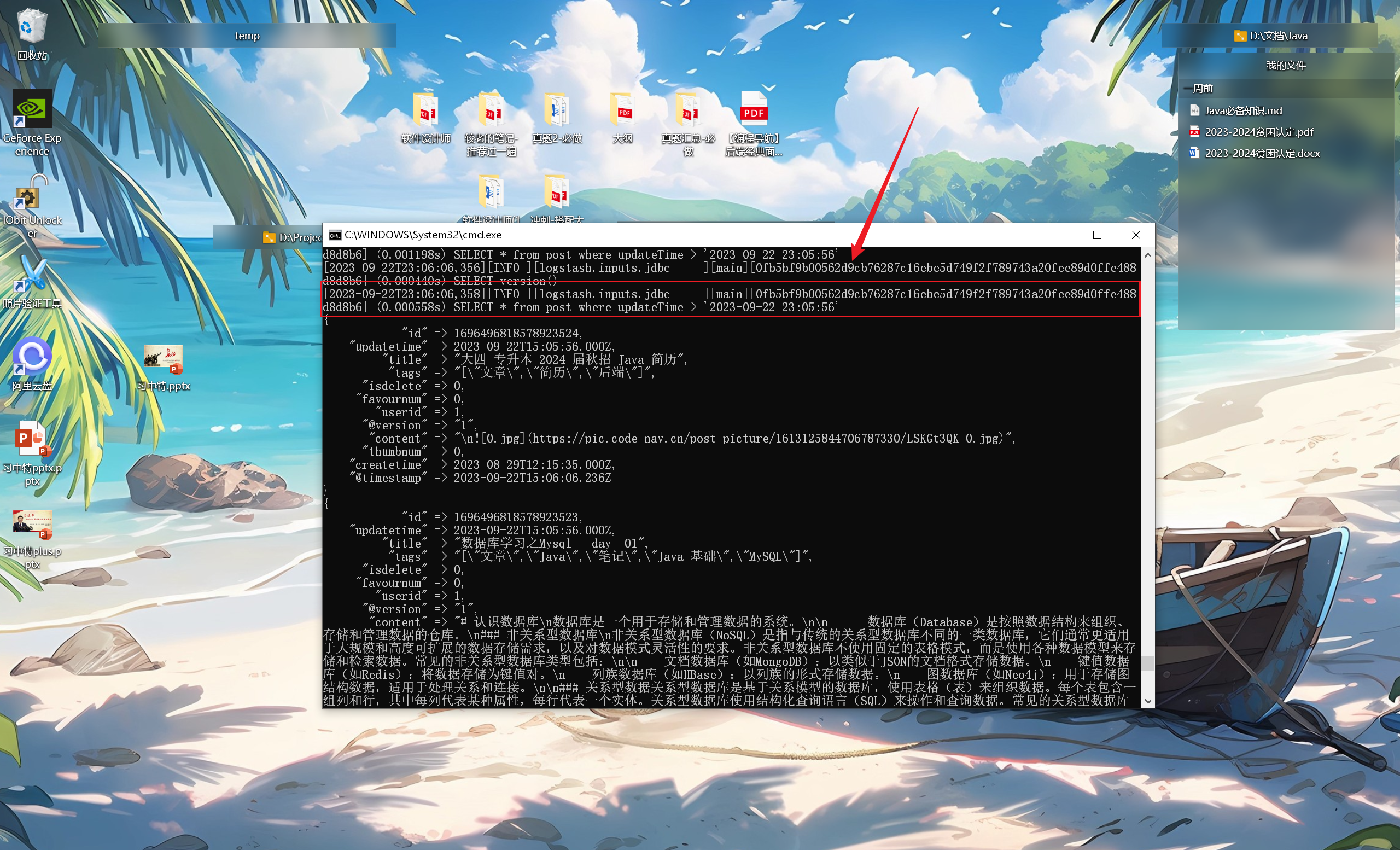
在 Kibana 监控面板 下,使用 DSL 语句执行查询 ,效果如下:
成功完成 article 实体的数据同步 (2023/11/07 晚)
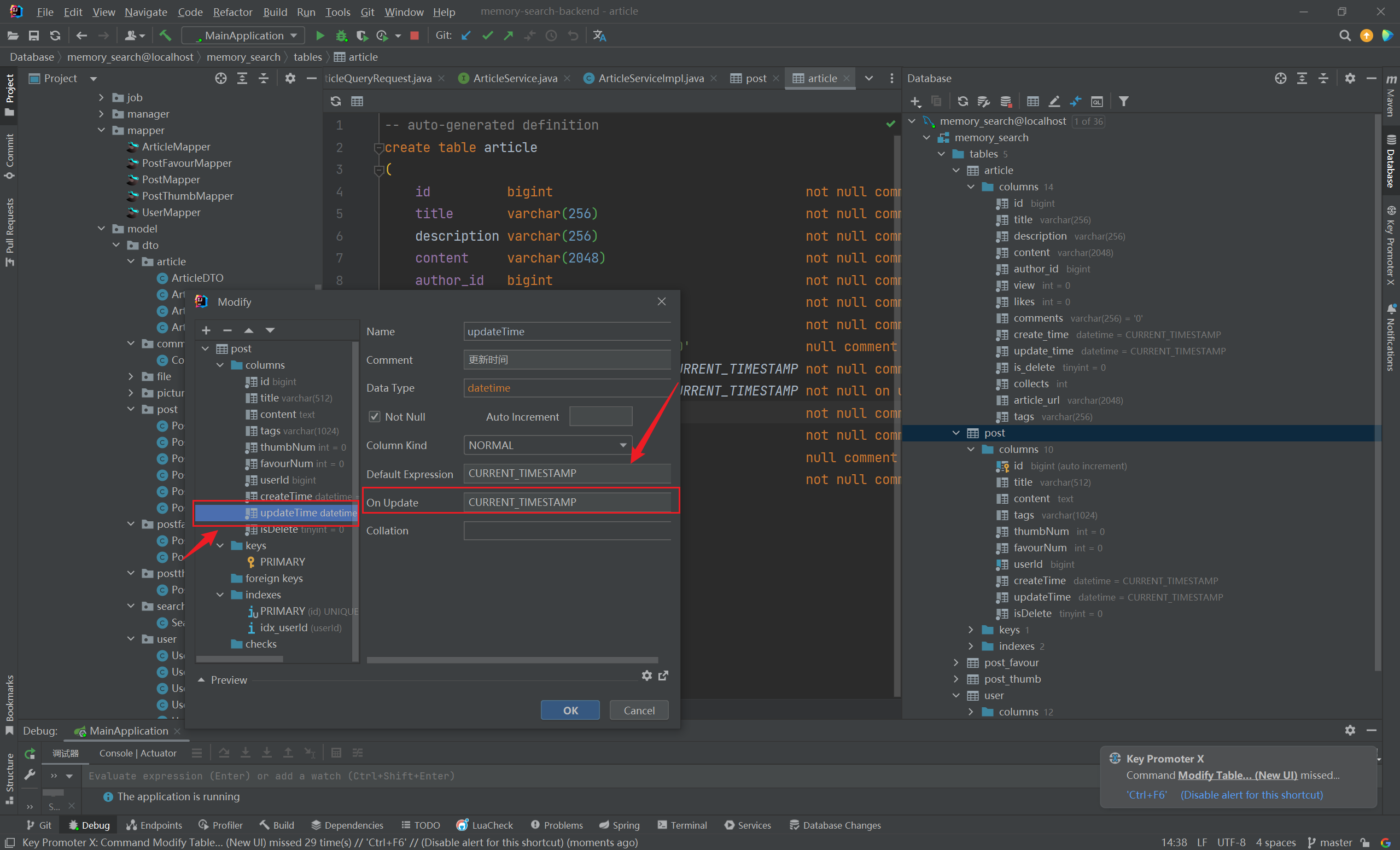
实现 updateTime 字段自动更新
什么意思呢?我们希望在修改完数据库表中的记录 后,该条记录对应的 uodateTime 字段 实现自动更新
实现方法很简单,在 IDEA 中,直接修改表的 updateTime 字段属性,如下:
1 updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间' ,
这样,我们更新记录 后,该记录 updateTime 字段会自动更新为最近修改时间 :(2023/11/07 晚)
SQL,多输入,多输出
Canal 监控数据库流水
🥣 推荐阅读:
今天晚上,我们实现了简单的通过 Canal 监控数据库流水,实现了实时监听 MySQL 中的数据变更,并实时同步变更的数据到 Elasticsearch 中,下面简单地介绍下相关流程:(2023/12/04 晚)
本地数据库配置
1 2 3 4 CREATE USER canal IDENTIFIED BY 'canal' ;GRANT SELECT , REPLICATION SLAVE, REPLICATION CLIENT ON * .* TO 'canal' @'%' ;
在本地 MySQL 中的 my.ini 文件中做如下配置(将本地的 MySQL 作为一个主节点,开启本地 binlog 生成):
1 2 3 4 [mysqld] log-bin =mysql-bin binlog-format =ROW server_id =1
Canal 的下载安装
Canal 配置
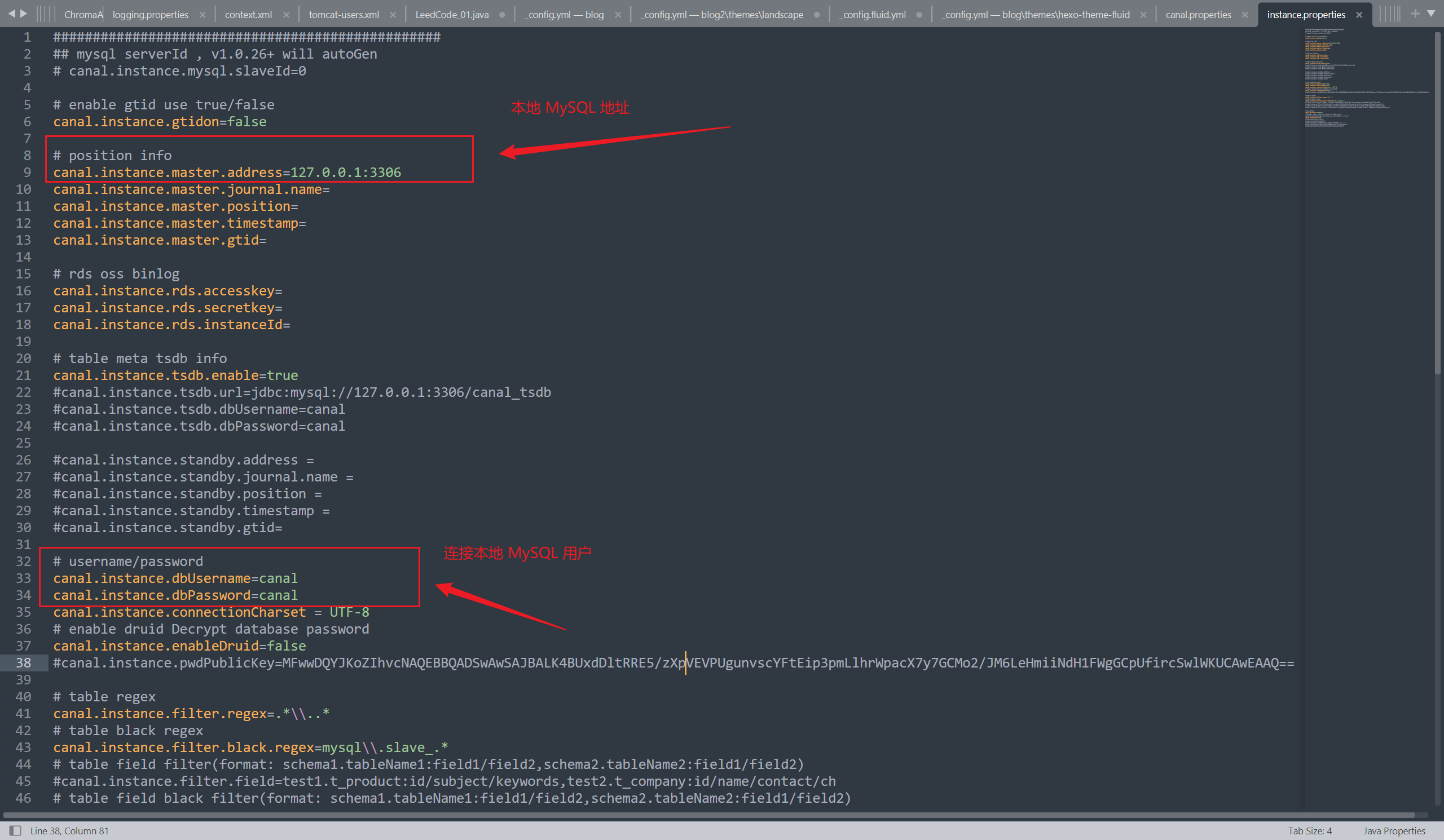
在 \conf\example\instance.properties 目录下做如下配置:
1 2 3 4 5 canal.instance.master.address=127.0.0.1:3306 canal.instance.master.journal.name=mysql-bin.000001 canal.instance.master.position= canal.instance.dbUsername=canal canal.instance.dbPassword=canal
启动 Canal
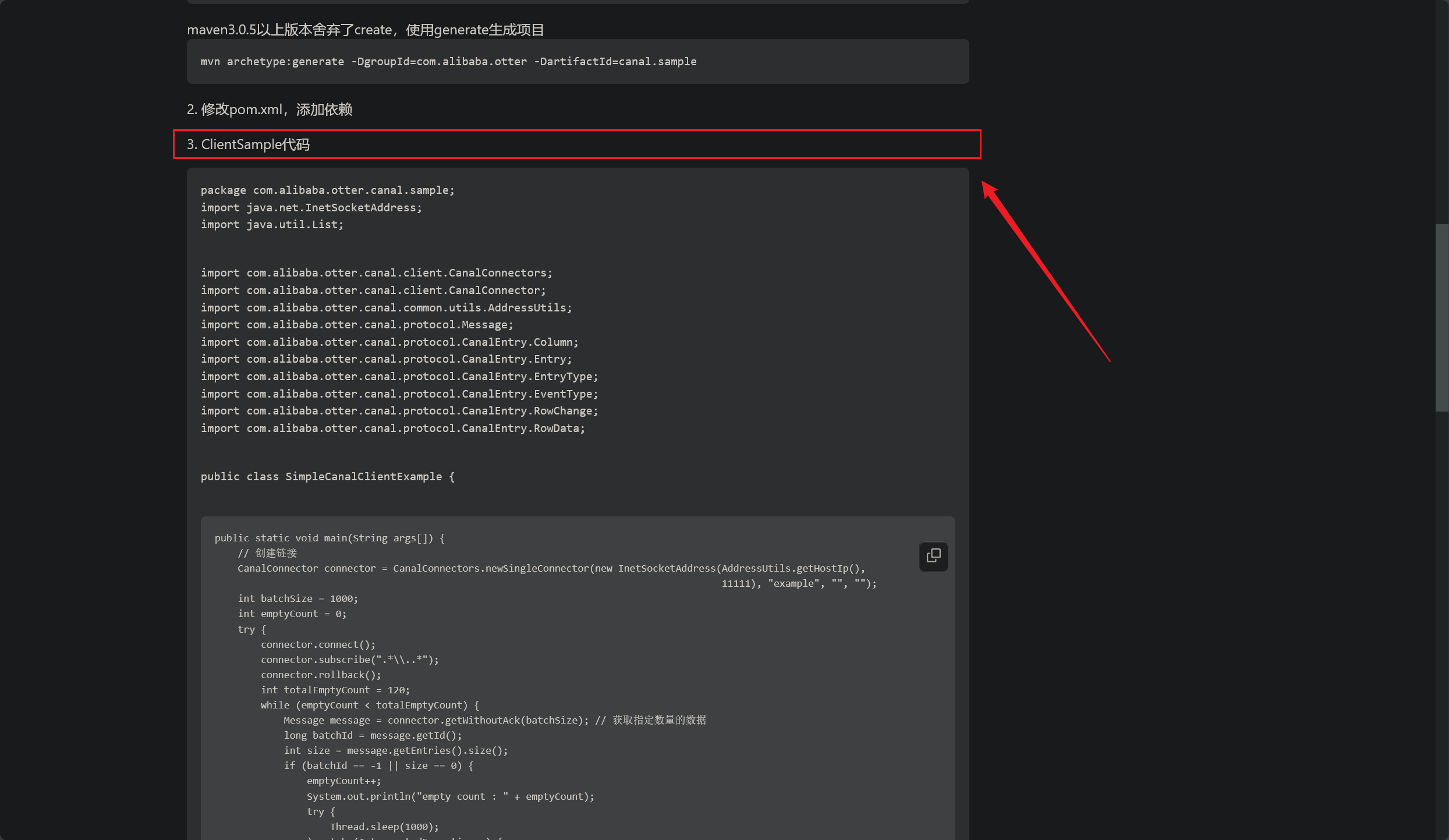
开启数据流水监控
1 2 3 4 5 <dependency > <groupId > com.alibaba.otter</groupId > <artifactId > canal.client</artifactId > <version > 1.1.0</version > </dependency >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 package com.alibaba.otter.canal.sample;import java.net.InetSocketAddress;import java.util.List;import com.alibaba.otter.canal.client.CanalConnectors;import com.alibaba.otter.canal.client.CanalConnector;import com.alibaba.otter.canal.common.utils.AddressUtils;import com.alibaba.otter.canal.protocol.Message;import com.alibaba.otter.canal.protocol.CanalEntry.Column;import com.alibaba.otter.canal.protocol.CanalEntry.Entry;import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;import com.alibaba.otter.canal.protocol.CanalEntry.EventType;import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;import com.alibaba.otter.canal.protocol.CanalEntry.RowData;public class SimpleCanalClientExample {public static void main (String args[]) {CanalConnector connector = CanalConnectorsnew InetSocketAddress (AddressUtils.getHostIp(),11111 ), "example" , "" , "" );int batchSize = 1000 ;int emptyCount = 0 ;try {".*\\..*" );int totalEmptyCount = 120 ;while (emptyCount < totalEmptyCount) {Message message = connector.getWithoutAck(batchSize);long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0 ) {"empty count : " + emptyCount);try {1000 );catch (InterruptedException e) {else {0 ;"message[batchId=%s,size=%s] \n" , batchId, size);"empty too many times, exit" );finally {private static void printEntry (List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {continue ;RowChange rowChage = null ;try {catch (Exception e) {throw new RuntimeException ("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),EventType eventType = rowChage.getEventType();"================> binlog[%s:%s] , name[%s,%s] , eventType : %s" ,for (RowData rowData : rowChage.getRowDatasList()) {if (eventType == EventType.DELETE) {else if (eventType == EventType.INSERT) {else {"-------> before" );"-------> after" );private static void printColumn (List<Column> columns) {for (Column column : columns) {" : " + column.getValue() + " update=" + column.getUpdated());
本地数据库修改数据,测试 Canal 监控数据库流水
如下,我们修改本地数据库中的一条记录 ,发现这次数据变更已经被捕捉到并打印出来了
至此,使用 Canal 实现实时监控数据变更 就完成了,当然这只是简单测试了一下,日后会着手实现基于该方法同步 MySQL 中的变更数据到 ES 中 (2023/12/04 晚)
数据处理失败,告诉 Canal 服务器,指定的批次 batchId 的数据没有被成功处理,服务器应该重新传递这批数据。这是一个重试机制,确保数据的完整性和一致性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int maxRetries = 3 ; while (maxRetries > 0 ) {try {break ; catch (Exception e) {if (maxRetries == 0 ) {
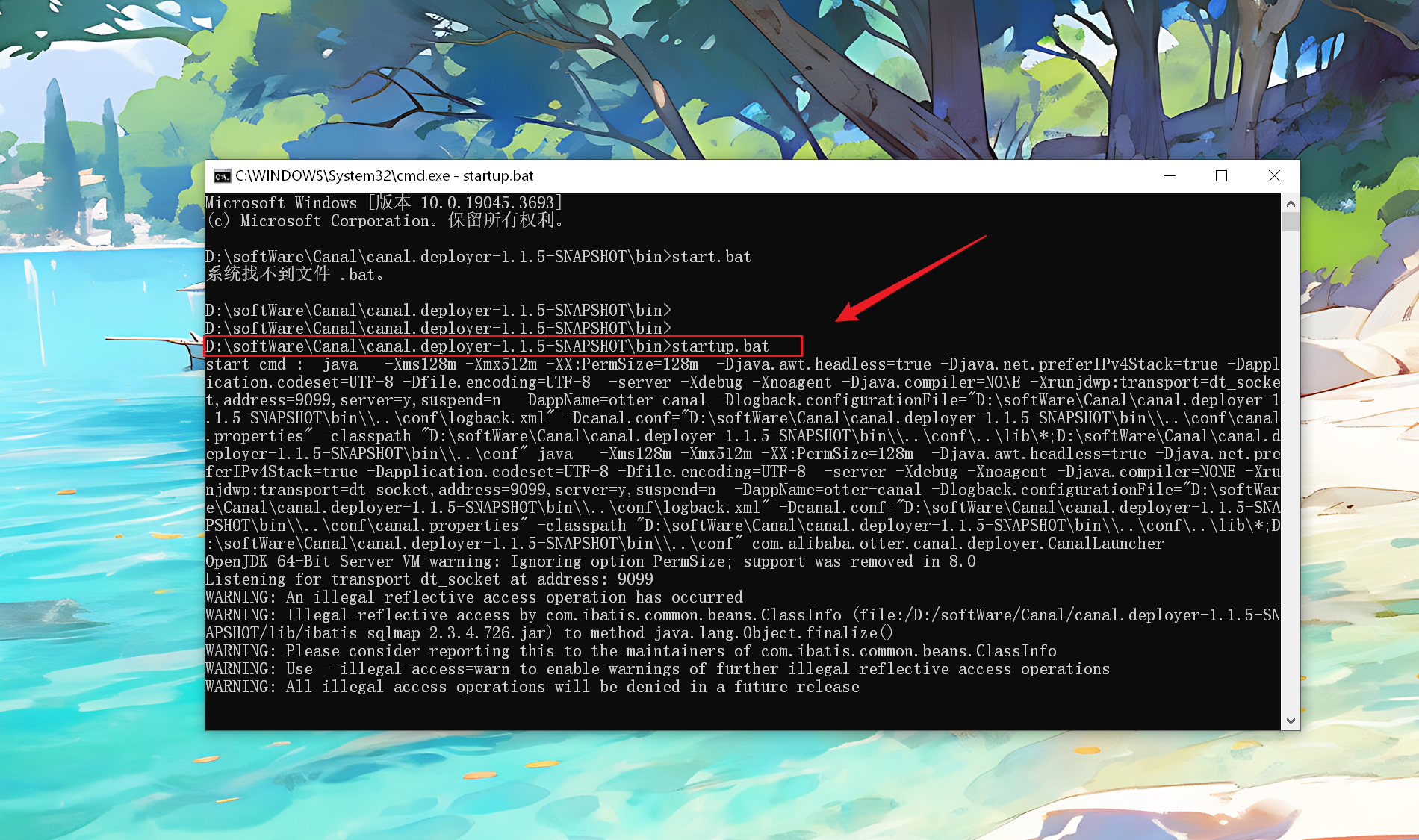
在 deployer / bin 目录下,执行以下命令:(2024/02/22 早)
启动 SimpleCanalClientExample:
实现 ES 博文搜索 严重的问题
着手使用 ES 实现博文快速搜索 + 关键词高亮显示,那执行步骤很简单 : (2023/11/08 晚)
由于之前开发过 post 的 ES 检索 + 关键词高亮显示 ,这次开发也是相当自信的
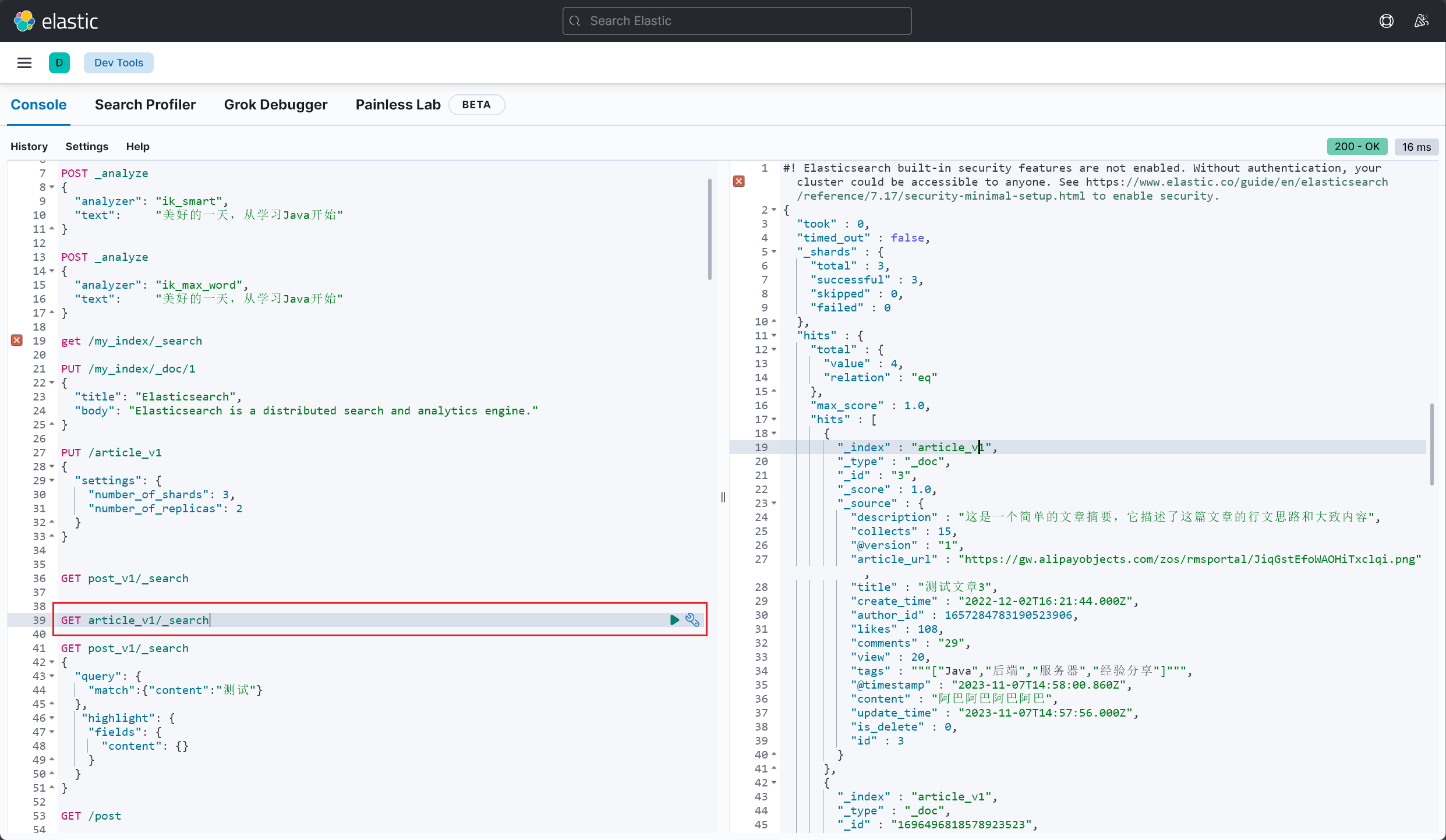
首先使用 DSL 语法,尝试获取 ES 中成功同步的的博文数据,查询成功:
结果在执行到 ArticleDataSource 的 searchFromEs() 方法时,却始终查询不到博文数据
经过一个多小时的仔细排查 ,我们终于发现错误出在这条语句的执行 上:(2023/11/08 晚)
1 2 3 4 5
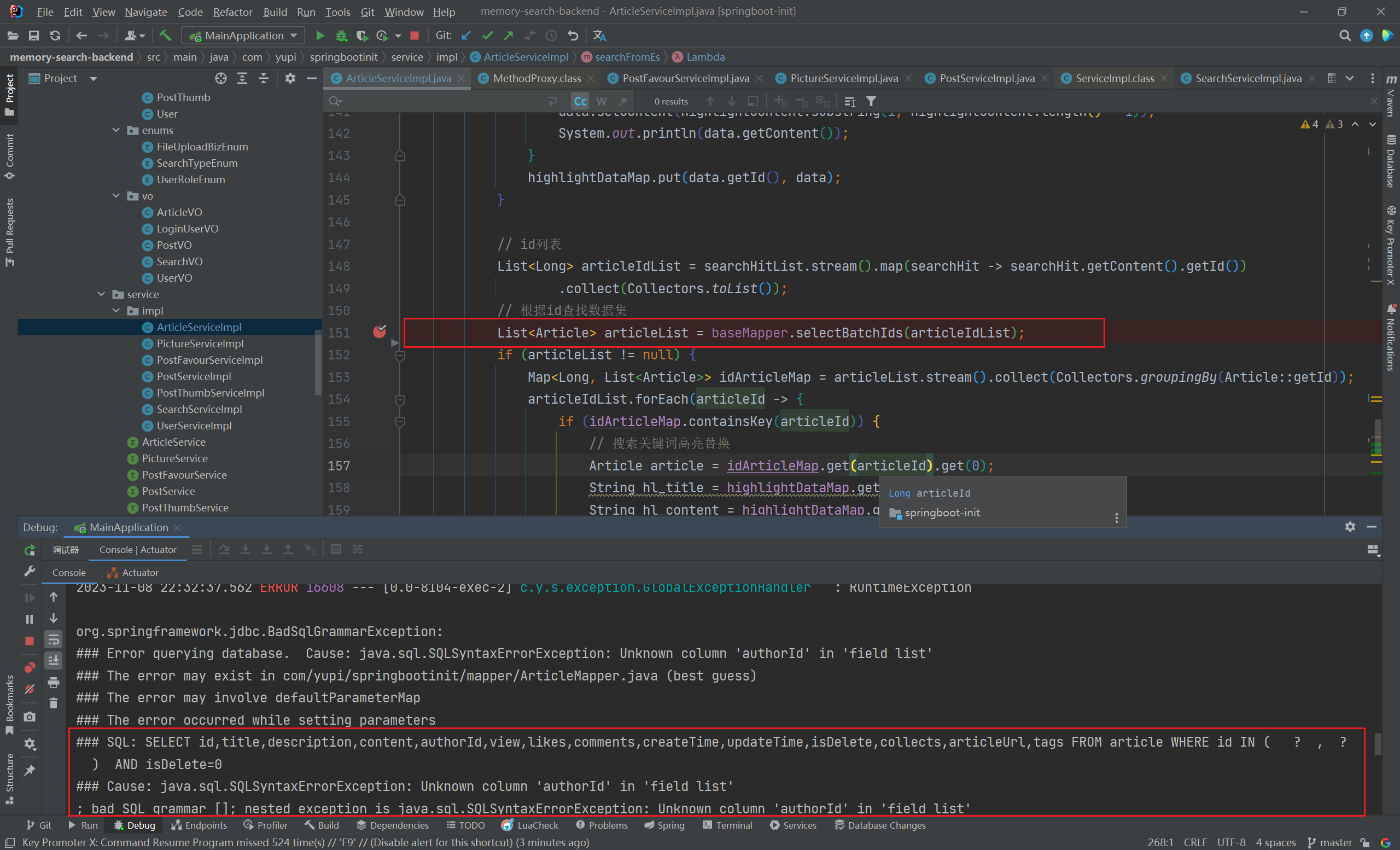
这条语句的逻辑是根据搜索条件 在 ES 中查询出符合条件的索引 id ,再根据索引 id 在本地 MySQL 中查询对应记录的详细信息
报错详情看下图执行的 SQL 语句:
1 2 3 4 5 6 7 8 org.springframework.jdbc.BadSqlGrammarException:'authorId' in 'field list' in com/yupi/springbootinit/mapper/ArticleMapper.java (best guess)0 'authorId' in 'field list' 'authorId' in 'field list'
忙活了一晚上,后端总算能正常查询出 ES 中的数据了,效果如下 :(2023/11/08 晚)
前端页面开发
1 2 3 4 5 6 7 8 9 10 <a-list-item-meta > <template #title > {{ item.title }} <div v-html ="item.title" style ="margin-bottom: 10px" > </div > </template > <template #description > <div v-html ="item.description" > </div > </template > </a-list-item-meta >
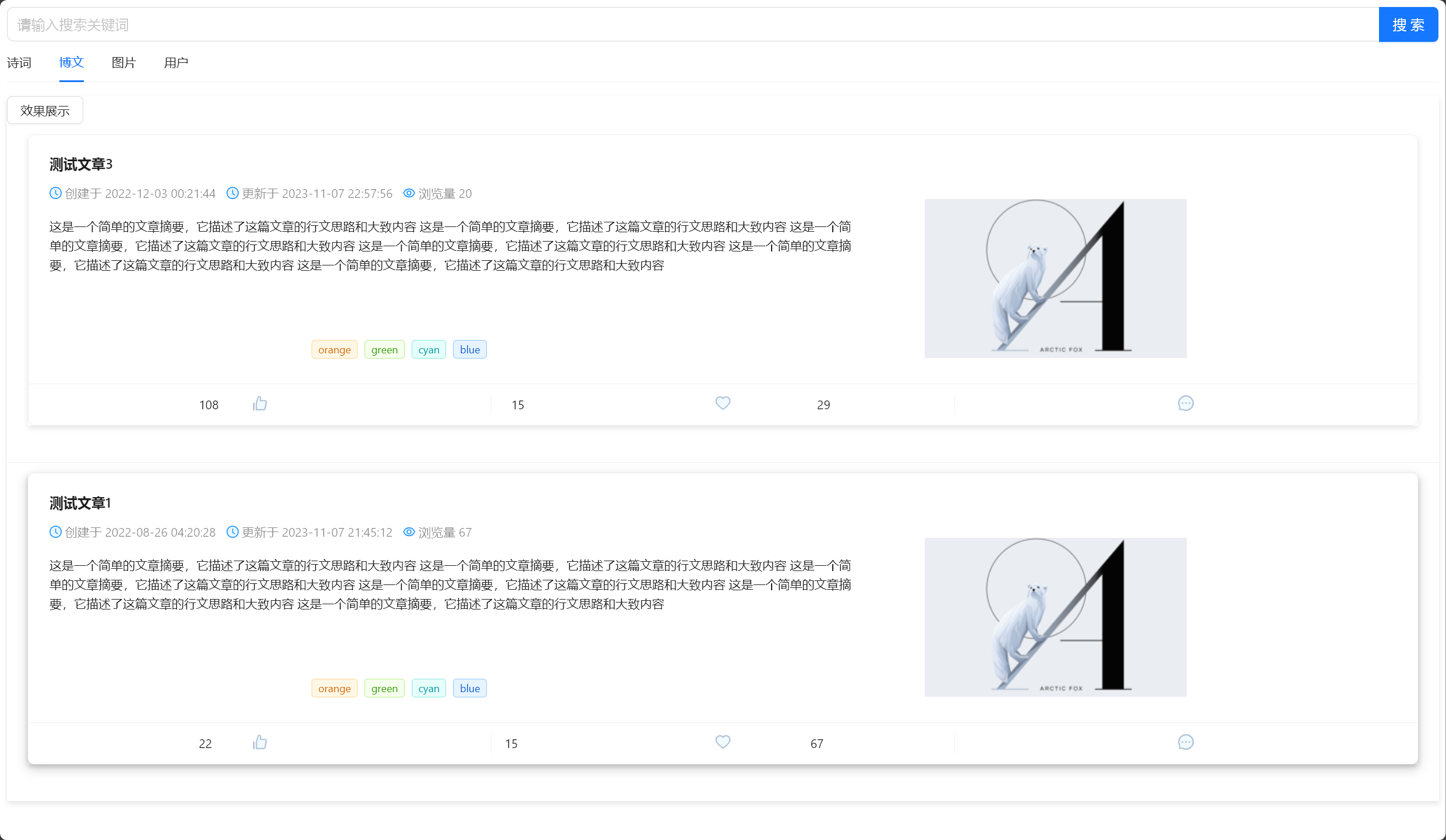
执行搜索后,根据 博文标题(title) 和 文章摘要(description) 快速检索,并实现关键词高亮 :
一个多月前,Memory 缘忆交友社区 致力于实现的核心功能 ,今天基本实现了 (2023/11/09 午)
在 新增了博文摘要(description),完成根据摘要的关键词高亮显示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Data public class ArticleEsHighlightData {private Long id;private String title;private String description;private String content;
1 2 3 4 5 6 7 8 9 10 HighlightBuilder highlightBuilder = new HighlightBuilder ()"description" )false )"<font color='#eea6b7'>" )"</font>" );"title" )false )"<font color='#eea6b7'>" )"</font>" );
构造查询(过滤 + 排序 + 分页 + 关键字高亮字段)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (StringUtils.isNotBlank(sortField)) {PageRequest pageRequest = PageRequest.of((int ) pageNum, (int ) pageSize);NativeSearchQuery searchQuery = new NativeSearchQueryBuilder ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 if (searchHits.hasSearchHits()) {new HashMap <>();for (SearchHit hit : searchHits.getSearchHits()) {ArticleEsHighlightData data = new ArticleEsHighlightData ();if (hit.getHighlightFields().get("title" ) != null ) {String highlightTitle = String.valueOf(hit.getHighlightFields().get("title" ));1 , highlightTitle.length() - 1 ));if (hit.getHighlightFields().get("description" ) != null ) {String highlightContent = String.valueOf(hit.getHighlightFields().get("description" ));1 , highlightContent.length() - 1 ));
1 2 3 4 5 6 7 8 9 10 11 12 13 if (idArticleMap.containsKey(articleId)) {Article article = idArticleMap.get(articleId).get(0 );String hl_title = highlightDataMap.get(articleId).getTitle();String hl_des = highlightDataMap.get(articleId).getDescription();if (hl_title != null && hl_title.trim() != "" ) {if (hl_des != null && hl_des.trim() != "" ) {
这个高亮字段 是我们直接获取的,官方文档 中也直接给了 demo 示例代码:
1 hit.getHighlightFields().get ("title" )
官方文档 :[Highlighting | Elasticsearch Guide 7.17] | Elastic 总算完整地过了一遍关键词高亮显示流程 了 (2023/11/09 晚)
博文阅读页面开发
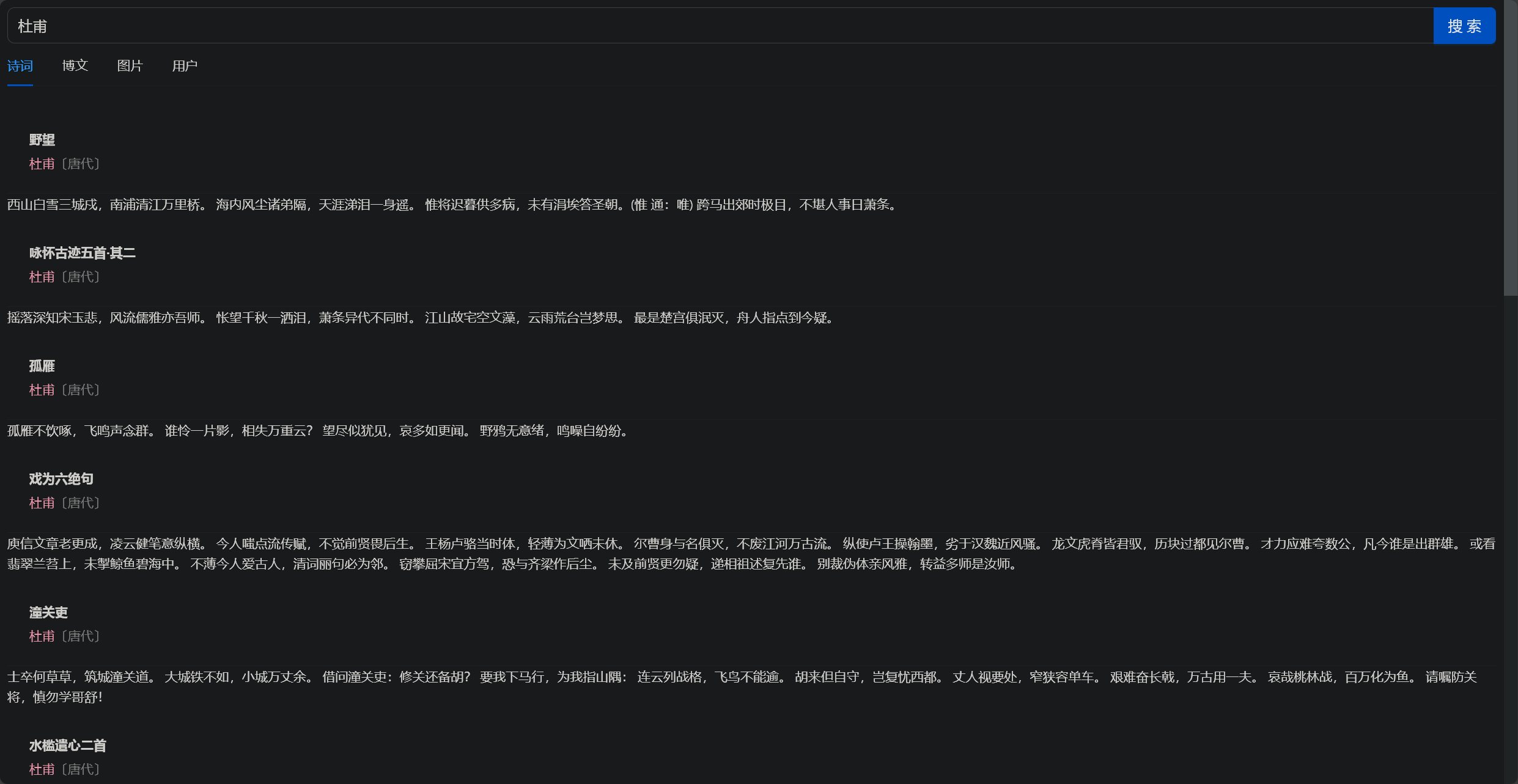
五代名句_古诗文网 (gushiwen.cn) 现在有诗词和博文两个聚合搜素,关于这两类数据的数据来源,想法是这样的:
博文就直接存储在本地数据库,因为在其他网站(掘金 / CSDN)同步到的博文信息有所欠缺(文章创作时间等等)
因为我想借这个机会,不仅将博文搜索接入聚合搜索中,还想实现基本的博文阅读功能
诗词搜索就直接调用外部接口,再同步到本地数据库,古诗词网就很不错
博文阅读页跳转
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const data = response.data;if (data.code === 0 ) {return data.data;"request error" , data);return response.data;return Promise.reject(error);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 const getArticle = (get ("/article/get/VO" , {params : {id : articleId.value ,then ((res ) => {value = res;const md = new MarkdownIt ();value = md.render (articleInfo.value .content );catch (() => {console .log ("获取文章信息失败" );
效果还可以,不过我设想的是这个搜索平台不需要登陆,用户就能享受所有服务
之后会把用户相关业务全部优化掉 (2023/11/11 晚)
图片聚合搜素
了解下 jsoup 工具如何实现网页抓取 ,并使用 HttpClient 实现解析网页内容
开发全新的聚合搜索:视频聚合搜索
诗词聚合搜索
请求古诗词网,获取诗词(如下图 👇)(2023/11/12 晚)
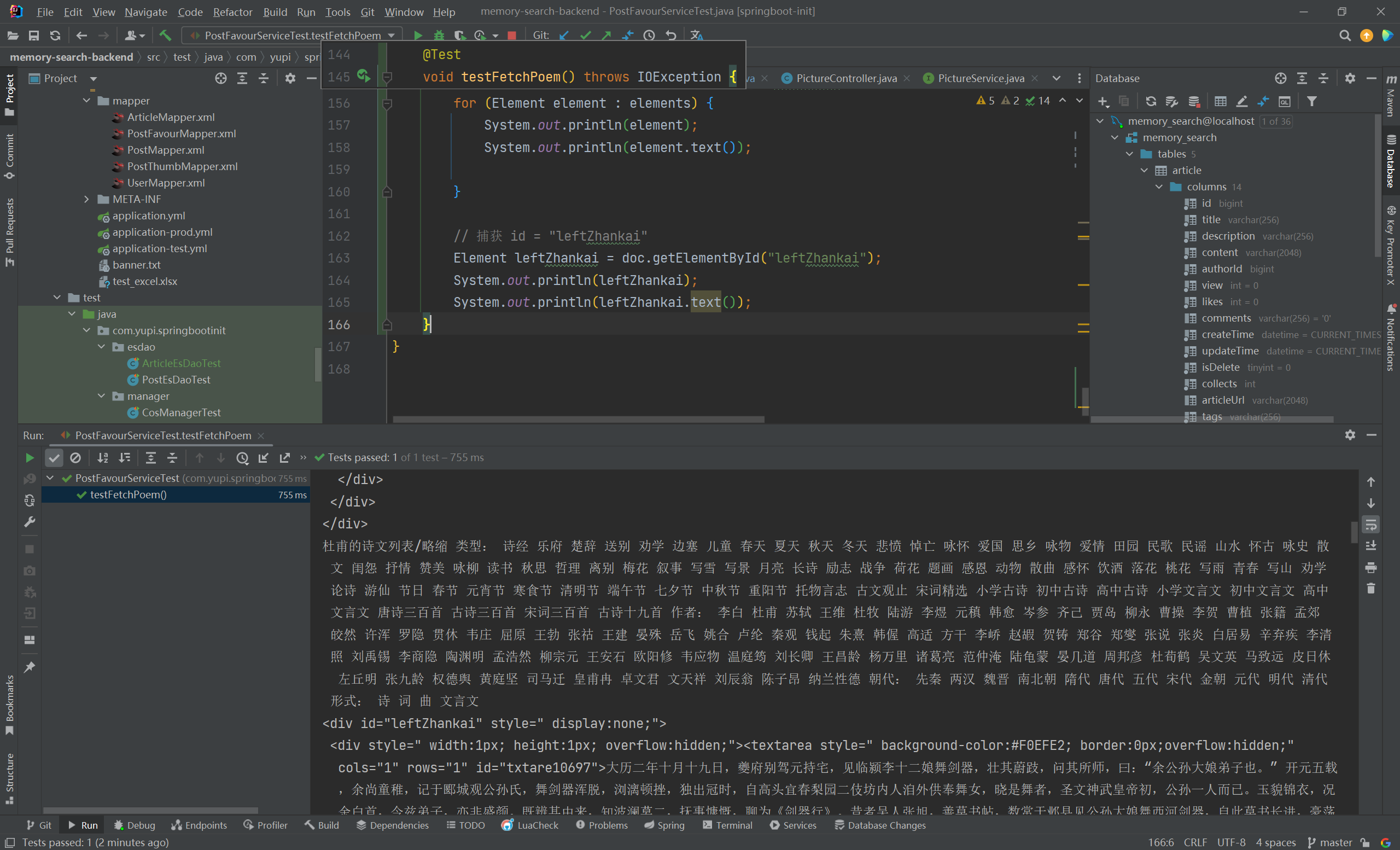
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Test void testFetchPoem () throws IOException {String url = "https://so.gushiwen.cn/shiwens/default.aspx?page=6&astr=%E6%9D%9C%E7%94%AB" ;Document doc = Jsoup.connect(url)"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62" )Elements elements = doc.select(".titletype" );for (Element element : elements) {Element leftZhankai = doc.getElementById("leftZhankai" );
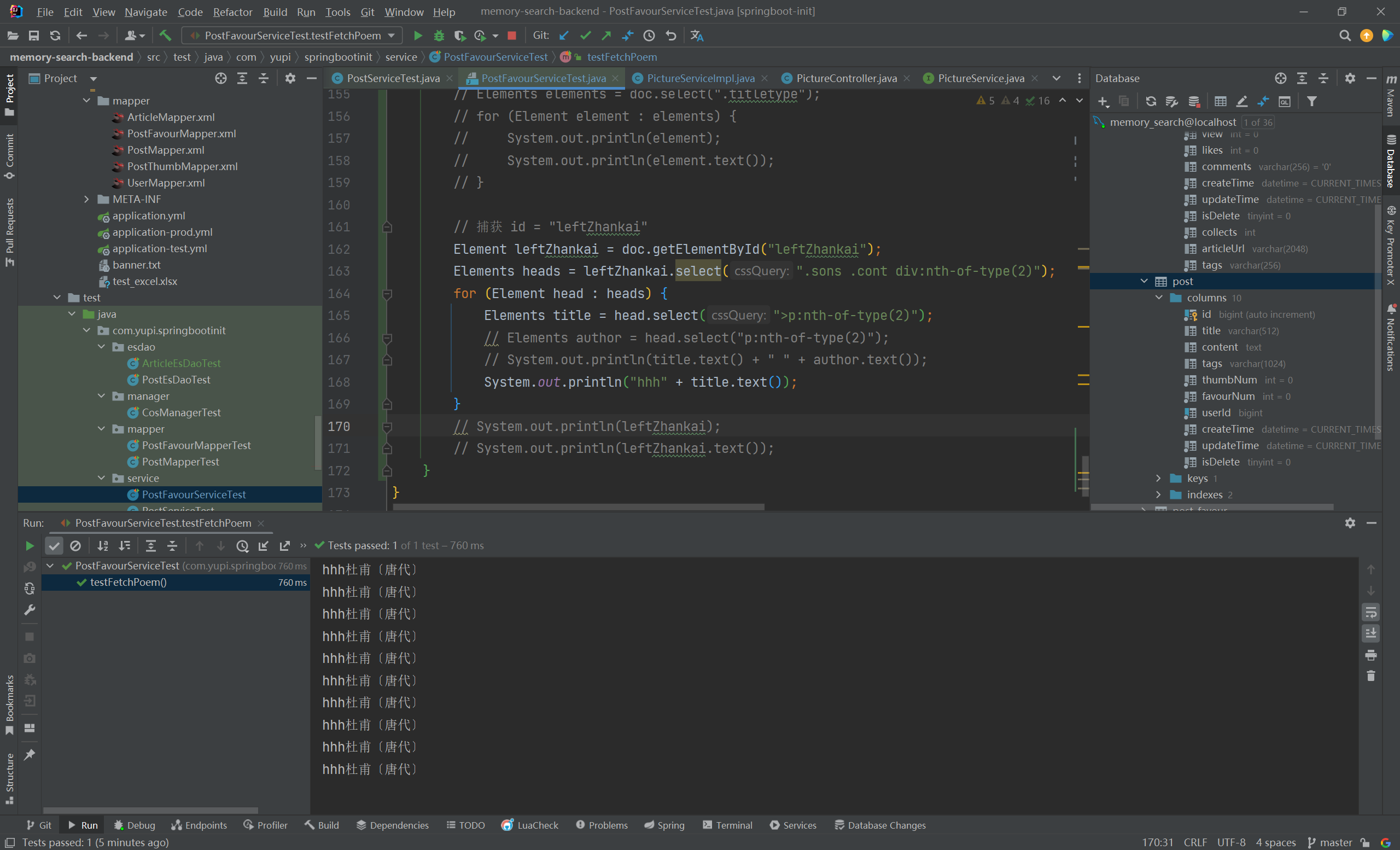
CSS 选择器巩固 1 2 3 4 5 6 7 8 9 Element leftZhankai = doc.getElementById("leftZhankai" );Elements heads = leftZhankai.select(".sons .cont div:nth-of-type(2)" );for (Element head : heads) {Elements title = head.select(">p:nth-of-type(2)" );"hhh" + title.text());
熟悉 CSS 选择器 之后,解析 HTML 文档 获取标题、诗人和内容 就很轻松了:
问题总结
基本实现了诗词聚合搜索,但有两个问题待解决:
logstash 数据数据同步,output 块和 input 块没有一一对应
可能由于分词机制,我搜索“杜甫”关键词,为什么只匹配一条数据呢
挺奇怪的,不过今天就到这里了(2023/11/12 晚)
阶段性问题解决 搜索“杜甫”未匹配文档的问题
找到了,使用搜索框输入关键词 执行搜索时,没有匹配 author 字段,补充这段代码即可:(2023/11/13 晚)
1 2 3 4 5 6 7 if (StringUtils.isNotBlank(searchText)) {"title" , searchText));"content" , searchText));"author" , searchText));1 );
无搜索关键词匹配文档过少
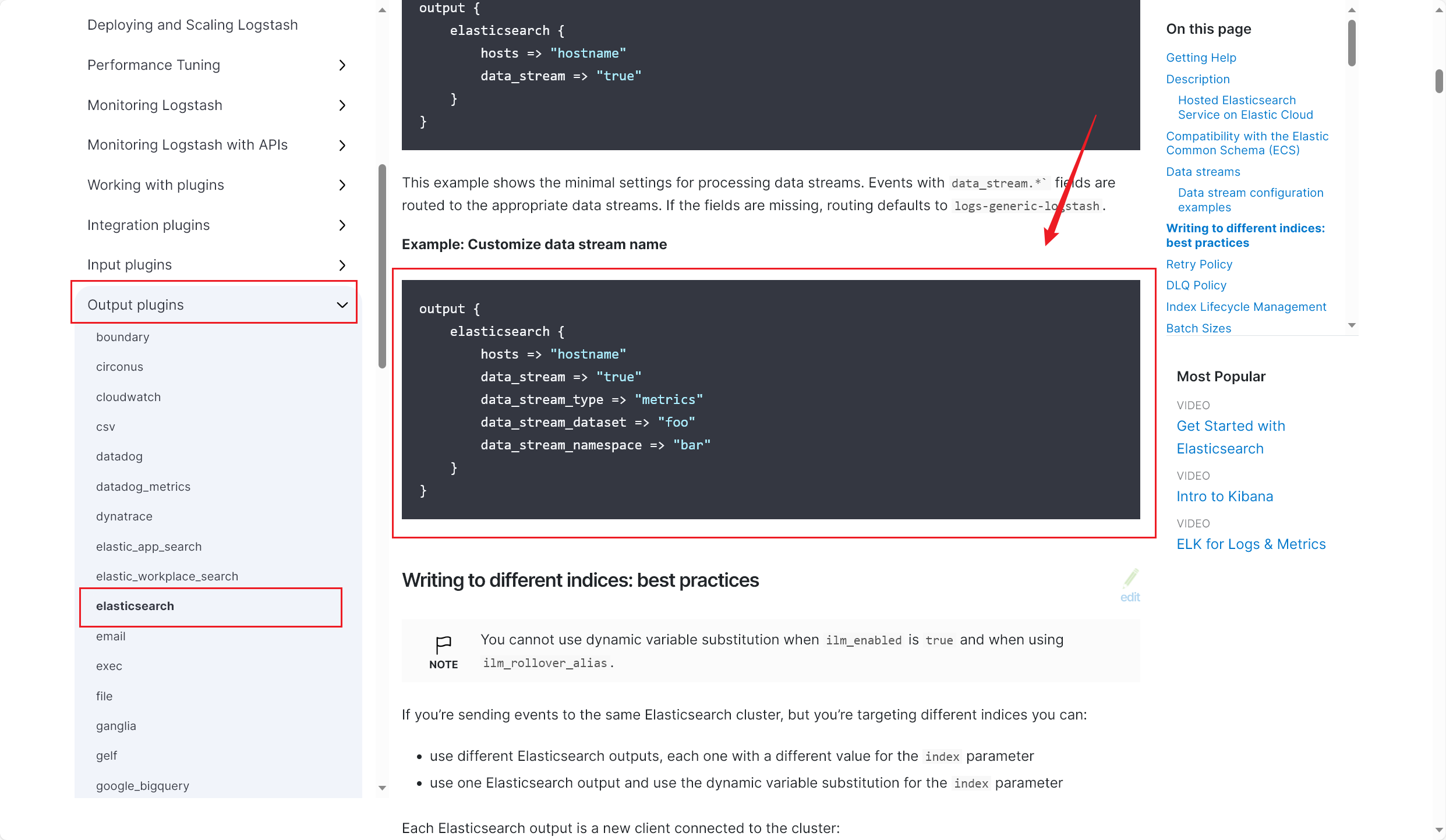
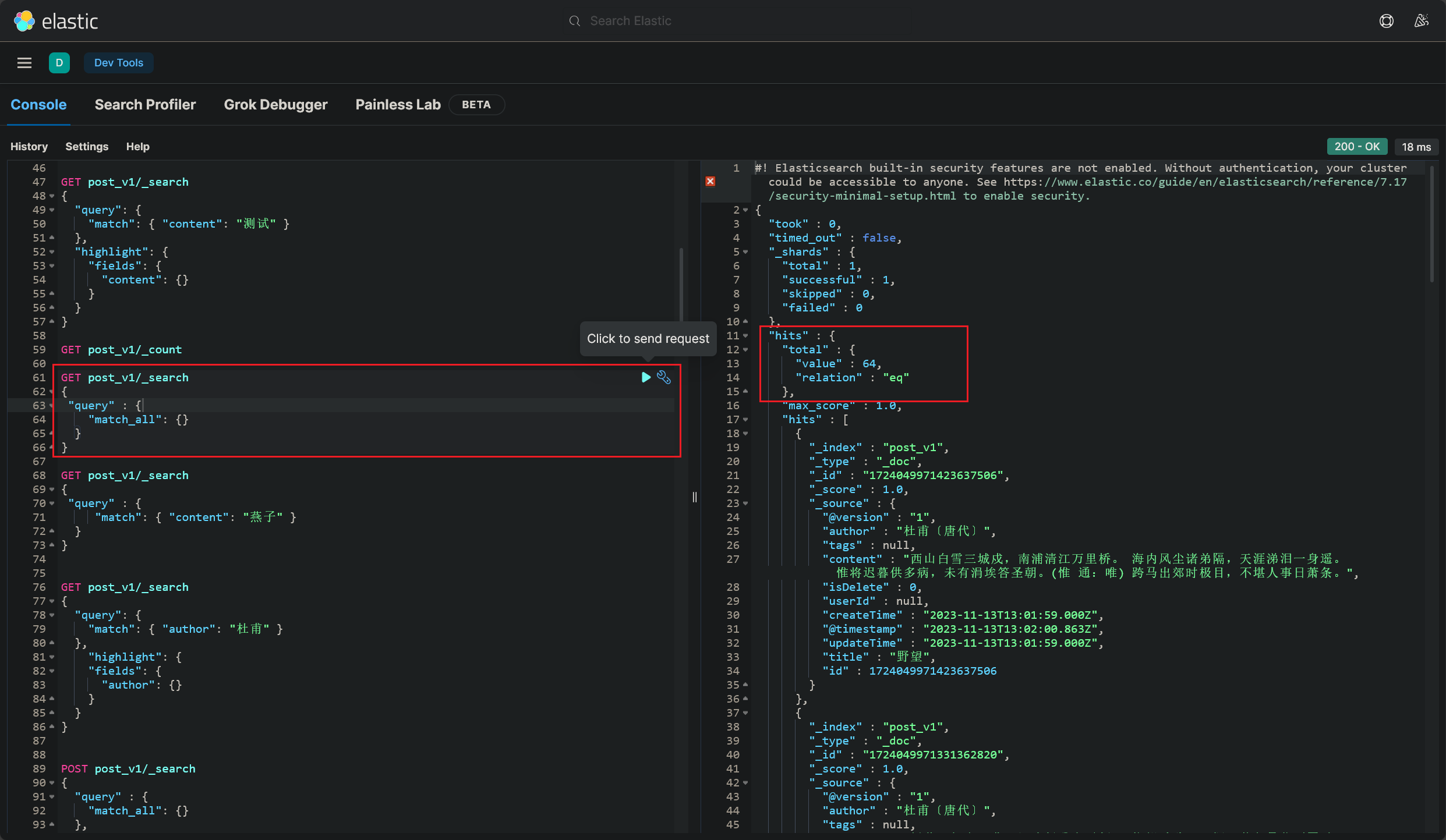
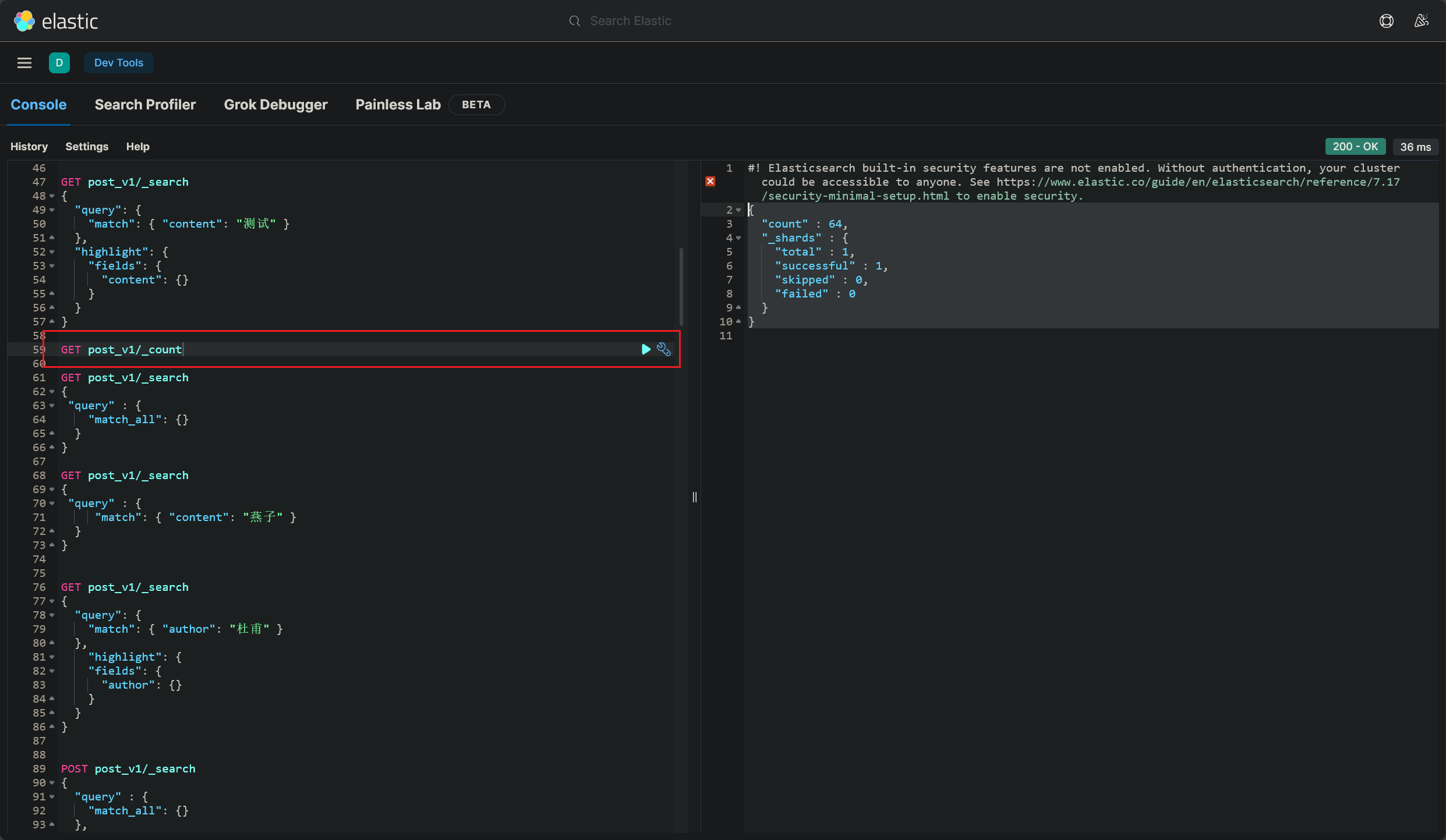
在 kibana 面板中,执行这样的 DSL 查询语句:(2023/11/13 晚)
1 2 3 4 5 6 GET post_v1/_search"query" : {"match_all" : {}
查询结果如下,显示 post_v1 索引下一共有 64 条文档:
1 2 3 4 5 6 7 8 9 PageRequest pageRequest = PageRequest.of((int ) current, (int ) pageSize);NativeSearchQuery searchQuery = new NativeSearchQueryBuilder ()
查询这个 pageSize,发现来源于前端的传参:
1 2 3 4 5 6 const initSearchParams = {type : activeKey,text : "" ,pageSize : 15 ,pageNum : 1 ,
这个就应该保留,而前端应该加个分页插件
奶奶的,分页插件不好做,换页后,要重新在 post 页面重新执行聚合查询,还得改动不少代码
算了,不是什么核心功能,改天再完善
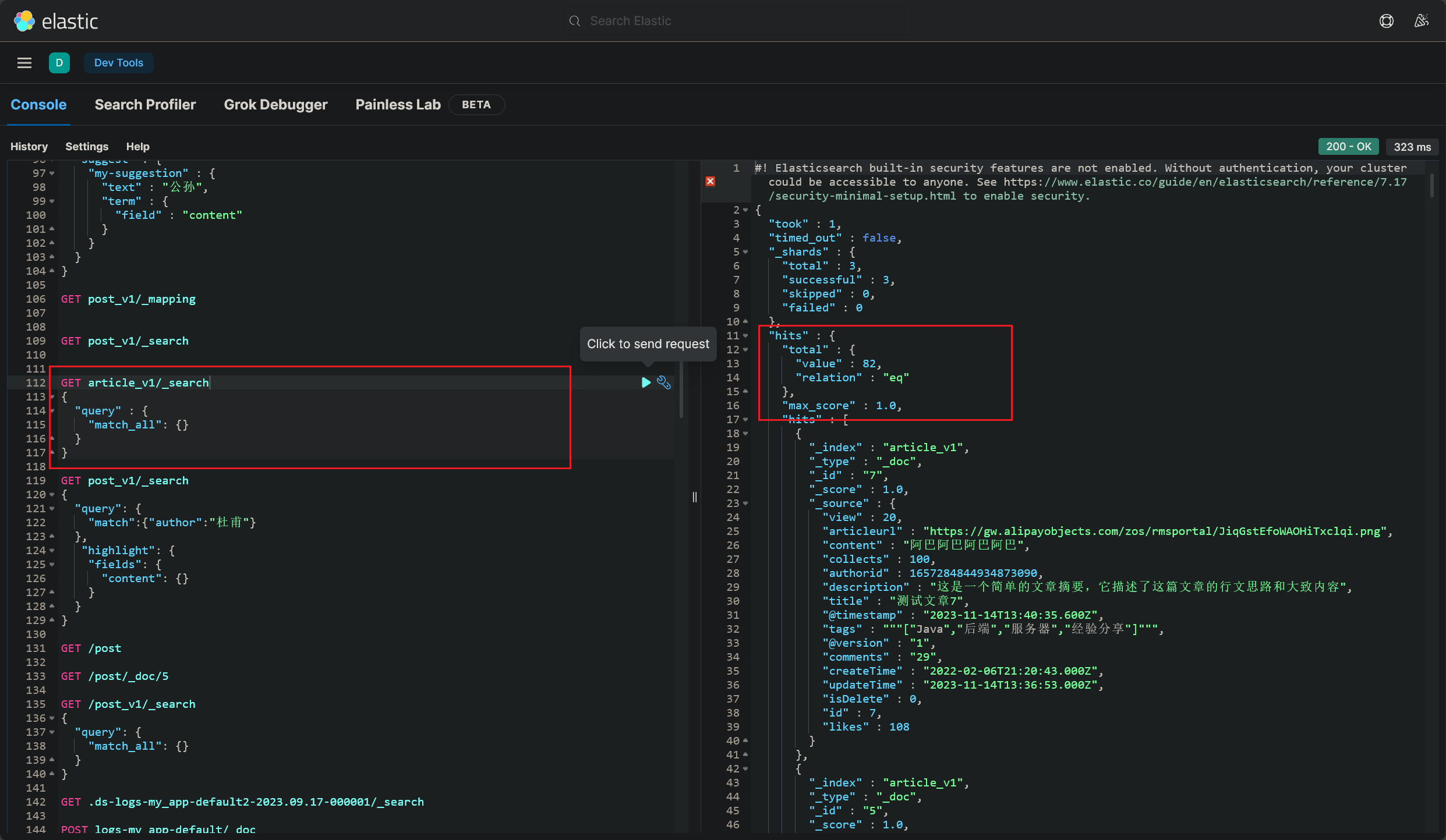
博文 ES 搜索,查询结果为空
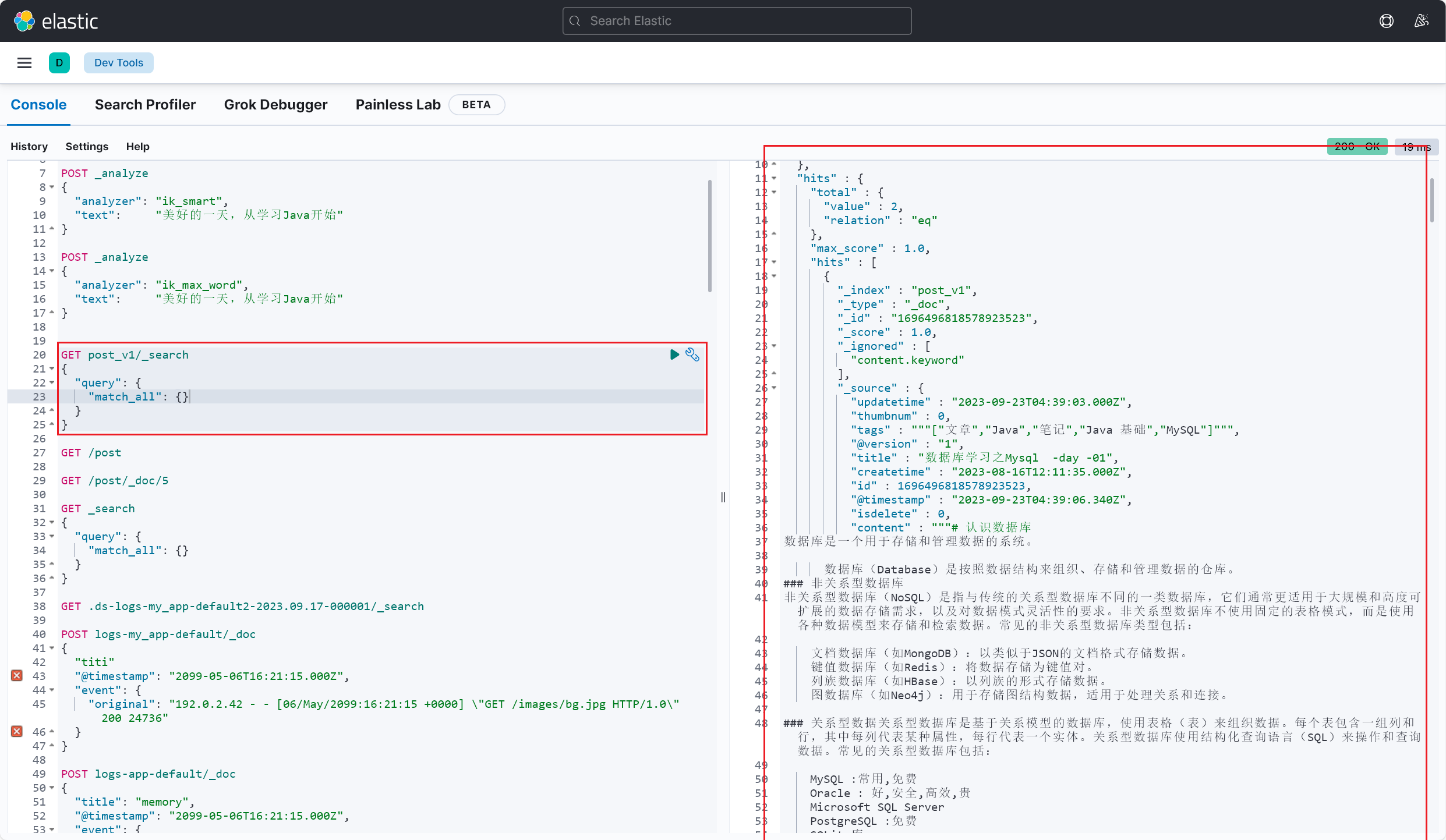
奇了怪了,Kibana 面板执行查询,显示有 82 条数据的:
Logstash 配置多个输入输出源 Ⅱ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/memory_search" jdbc_user => "root" jdbc_password => "Dw990831" statement => "SELECT * from post where updateTime > :sql_last_value and updateTime < now() order by updateTime desc" use_column_value => true tracking_column_type => "timestamp" tracking_column => "updatetime" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai" filter {rename => {"updatetime" => "updateTime" "userid" => "userId" "createtime" => "createTime" "isdelete" => "isDelete" remove_field => ["thumbnum" , "favournum" ]output {codec => rubydebug }elasticsearch {hosts => "127.0.0.1:9200" index => "post_v1" document_id => "%{id}"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 input {jdbc_driver_library => "D:\softWare\logstash\logstash-7.17.9\config\mysql-connector-java-8.0.29.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost:3306/memory_search" jdbc_user => "root" jdbc_password => "Dw990831" statement => "SELECT * from article where updateTime > :sql_last_value and updateTime < now() order by updateTime desc" use_column_value => true tracking_column_type => "timestamp" tracking_column => "updatetime" schedule => "*/5 * * * * *" jdbc_default_timezone => "Asia/Shanghai" filter {rename => {"updatetime" => "updateTime" "userid" => "userId" "createtime" => "createTime" "isdelete" => "isDelete" remove_field => ["thumbnum" , "favournum" ]output {codec => rubydebug }elasticsearch {hosts => ["127.0.0.1:9200" ]index => "article_v1" document_id => "%{id}"
1 .\bin\logstash.bat -f .\config\myTask.conf -f .\config\myTask2.conf
有关 Logstash 的配置,还需要更多了解,目前知识掌握了 MSQL 向 ES 的映射配置(2023/11/16 晚)
Logstash 配置多个输入输出源 Ⅲ
🍖 推荐阅读:柴少的官方网站-Logstash 多配置文件启动(五) (51niux.com)
今天上午,发现之前的命令并不能够同时加载多个配置文件,经过两个小时的努力,终于找到了解决之道:
我把本地的两个配置文件 myTask.conf 和 myTask.conf2 放在同一个文件夹下 conf:
1 .\bin\logstash.bat -f .\config\conf
很显然,两个配置文件都被成功加载到了:(2023/12/26 早)
搜索建议
还需要安装 suggestion 插件 ,这里给出 demo 示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 POST post_v1/ _search
优化图片搜索体验
首先优化执行关键词检索后的反馈:(2023/11/16 晚)
1 2 3 4 5 6 7 8 9 10 if (type === "post" ) {success ("成功检索出您感兴趣的诗词~" );else if (type === "user" ) {success ("成功检索出您感兴趣的用户~" );else if (type === "picture" ) {value = [];getImages ();else if (type === "article" ) {success ("成功检索出您感兴趣的博文~" );
又是经典的点击按钮后,仅展示所属弹窗 问题(绑定唯一值 ,这里是 id):
1 2 3 4 5 6 7 8 9 10 11 12 <!--下载-->
1 2 3 4 5 6 7 8 9 10 const visible = ref ({});const showModal = (id: any ) => {value [id] = true ;const handleOk = (id: any ) => {value [id] = true ;
将来引入第三方库,实现一键复制图片地址功能 (2023/11/16 晚)
代码优化,删除冗余代码
干掉所有 User 相关代码
可以了,代码算是删干净了
后续几周内会逐步增加视频聚合搜索功能,并逐步上线该项目
那么接下来,就是优化 Memory API 接口开放平台了(2023/11/18 午)
Kibana 监控面板
其实没什么好讲的,不过还是稍微体验了一下:
简单地记录一下吧:
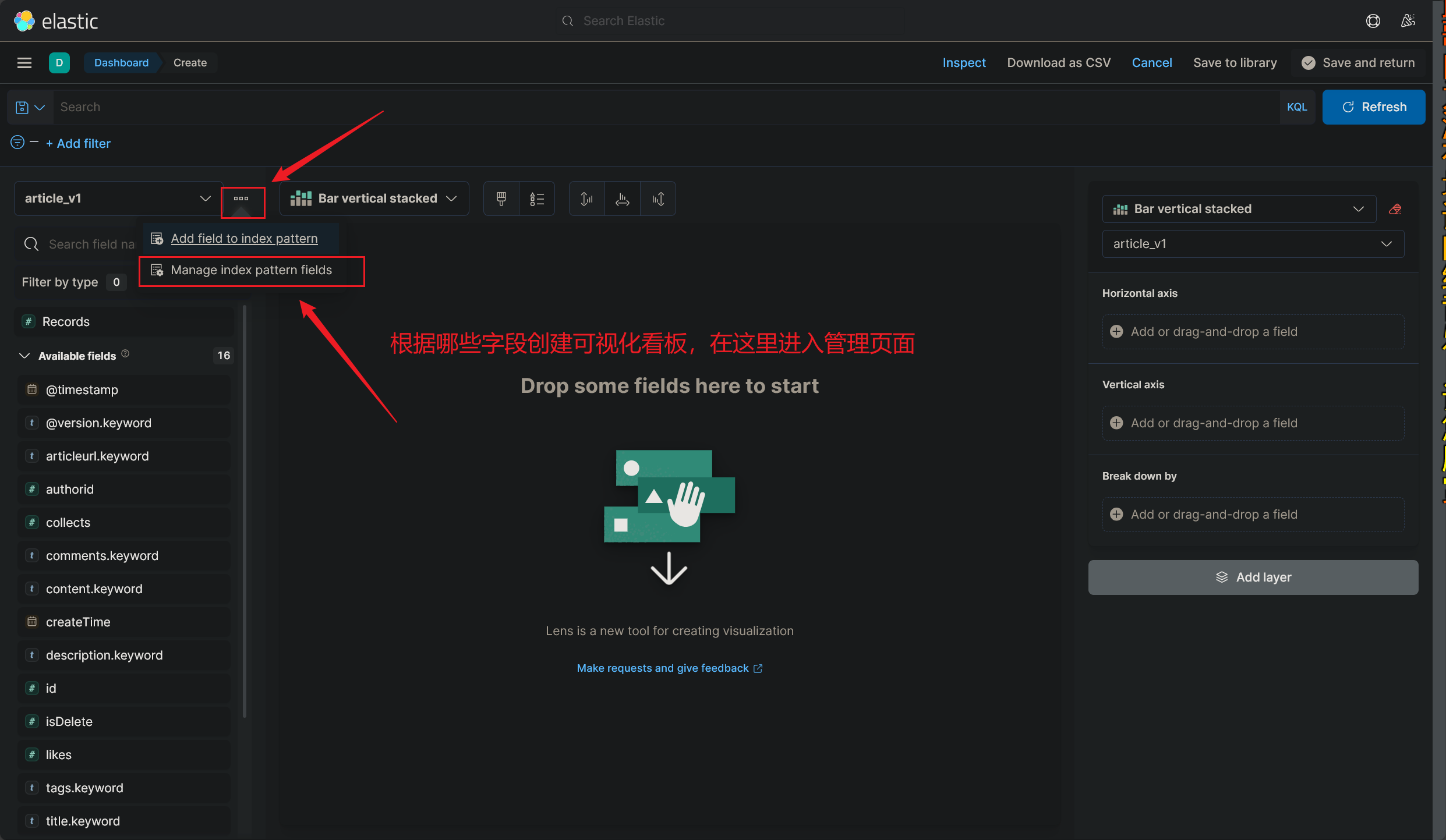
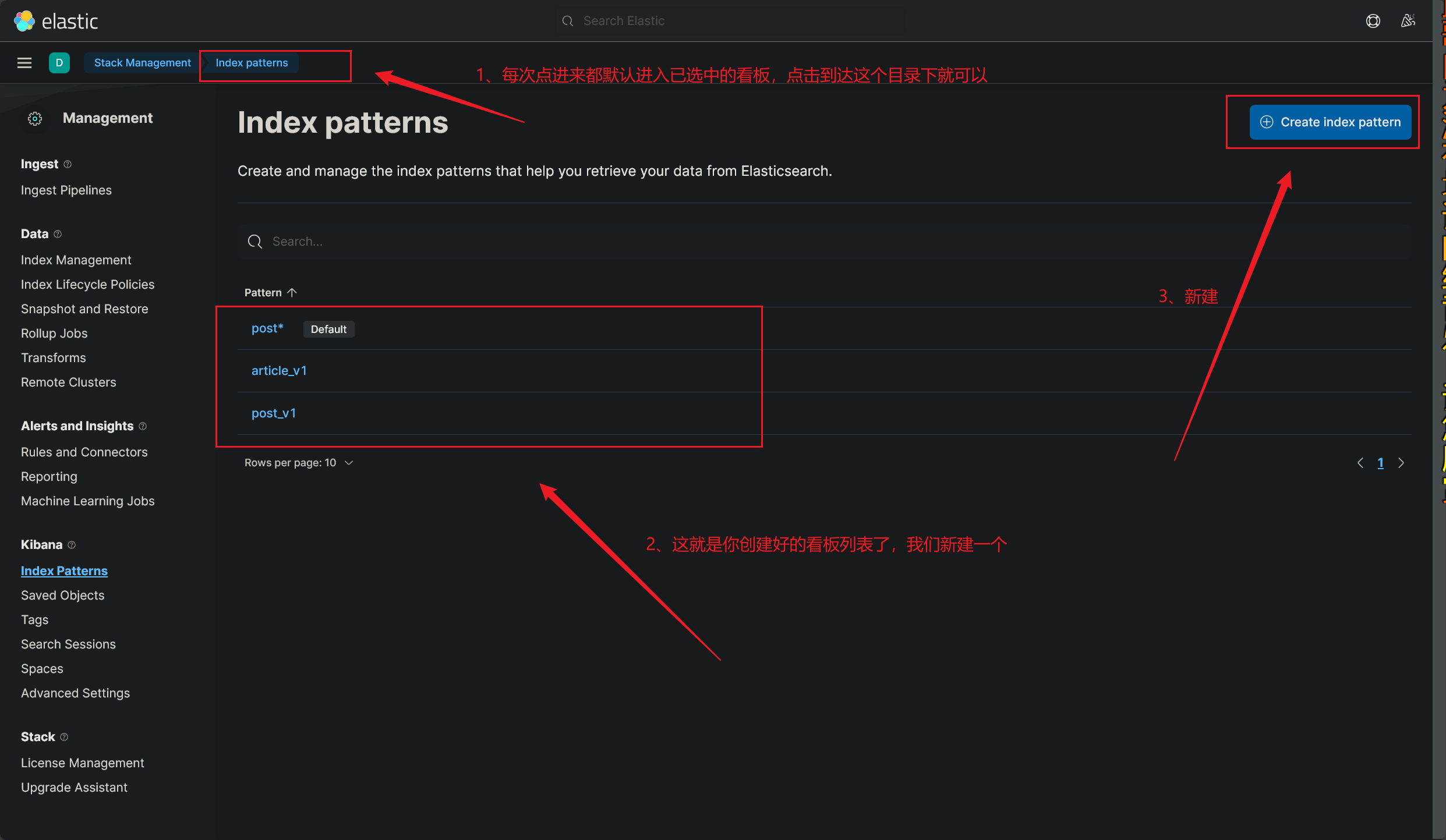
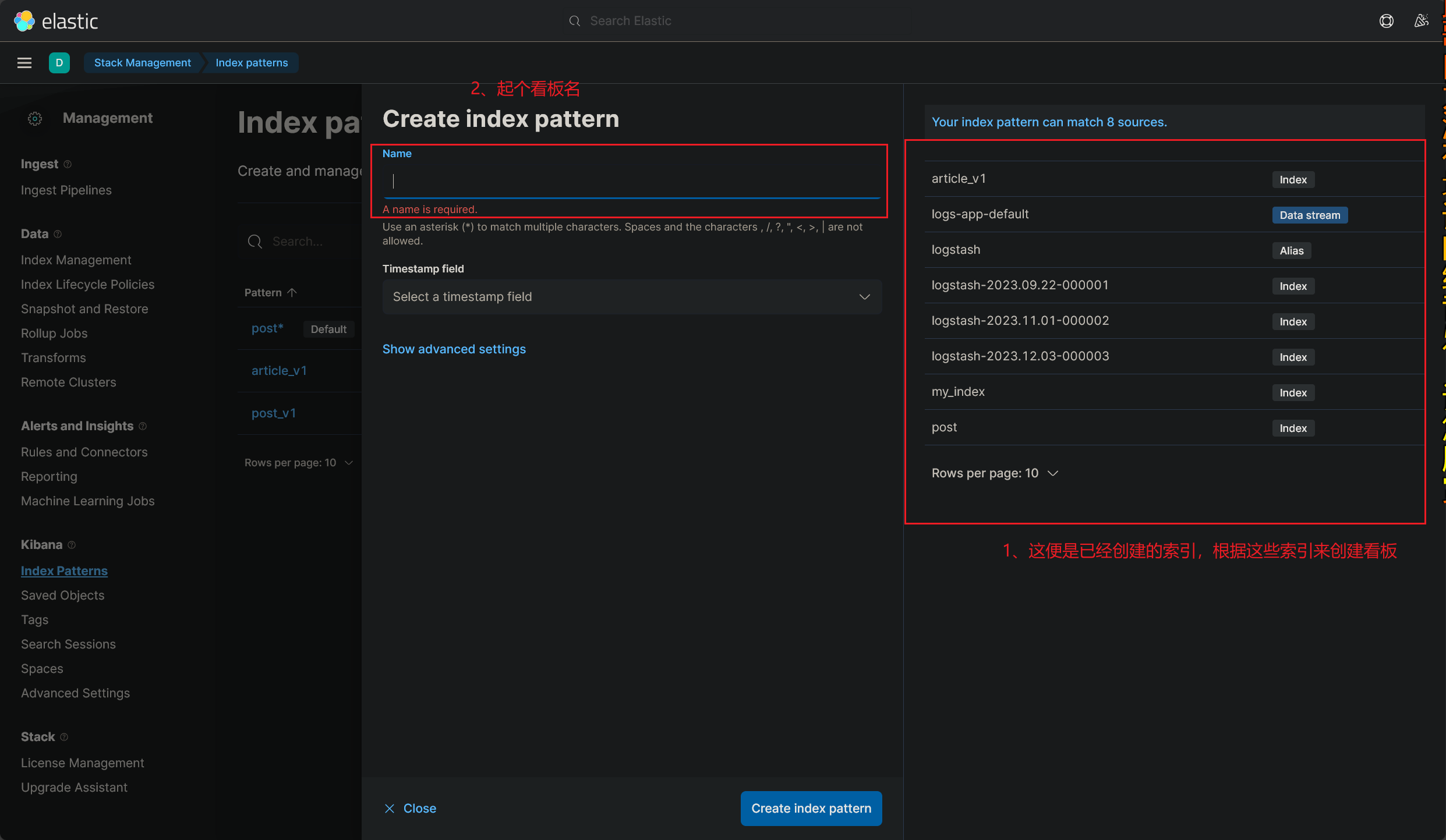
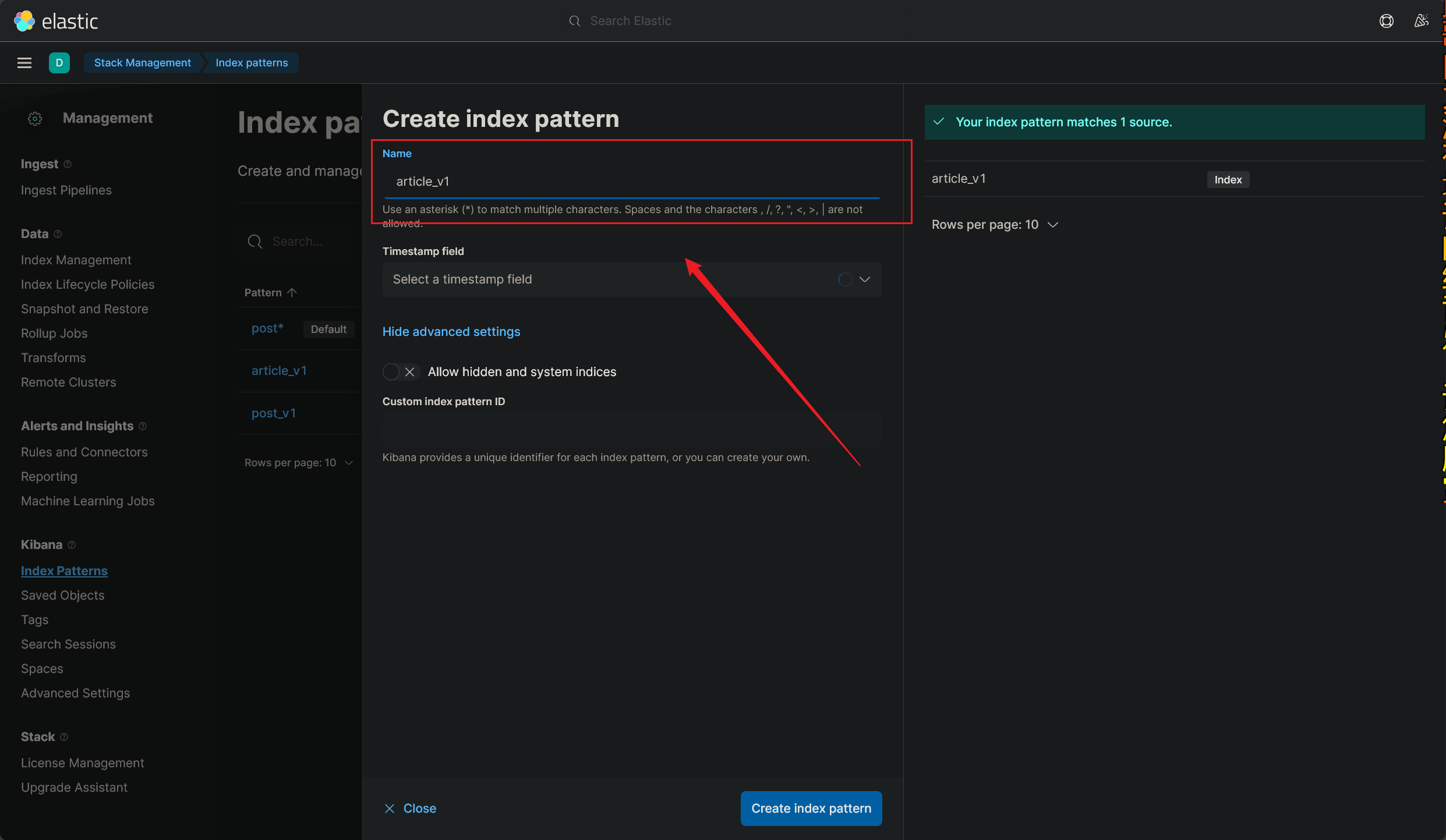
找到监控看板:
如下图所示:
看板的命名很有意思,看板的命名必须要匹配到已经创建的索引名 ,还不能重复,也就是说:
每个索引只可以创建一个看板 ,至少我目前的看法是这样的(2023/12/03 午)
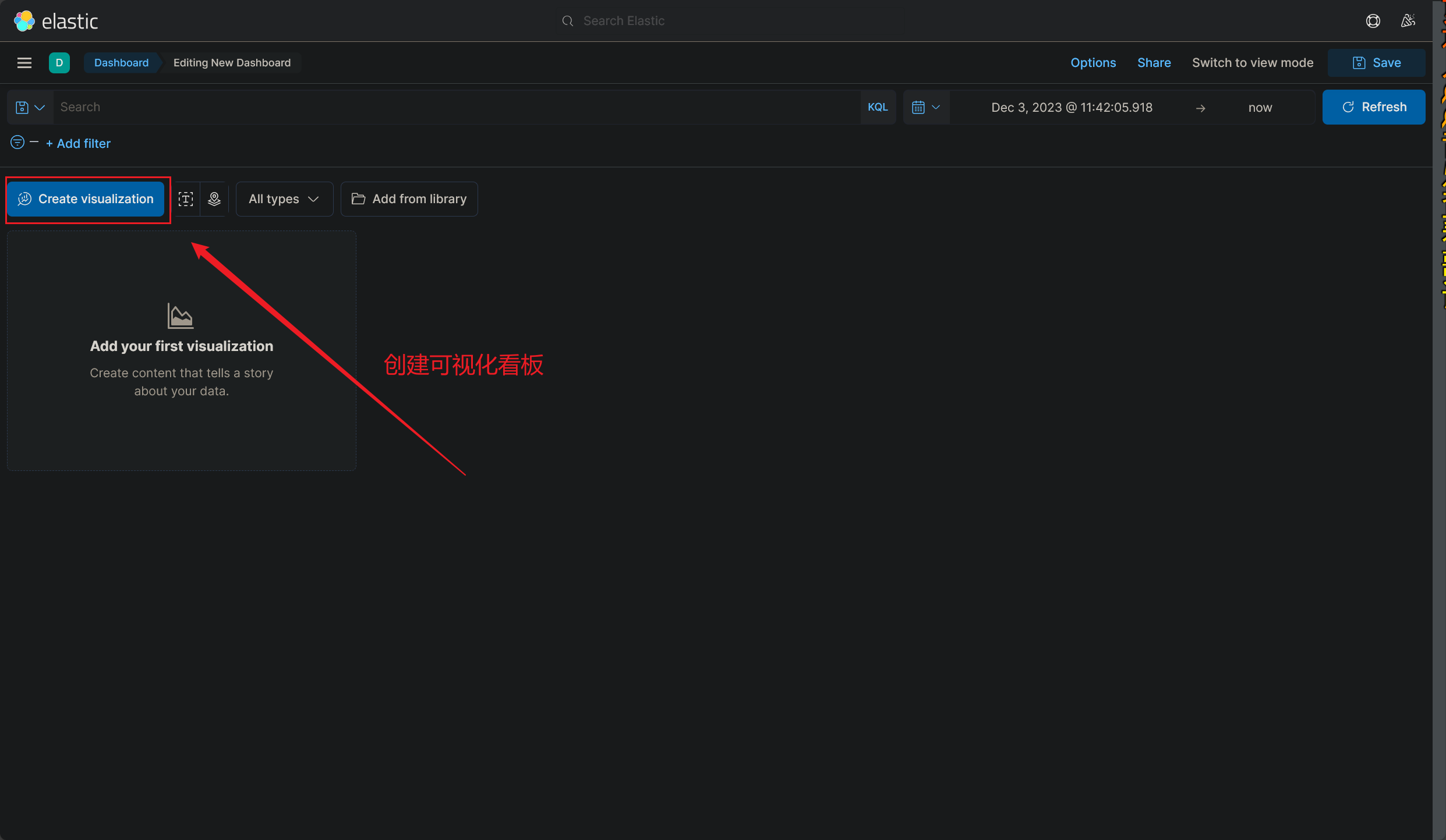
创建好新的看板之后,就可以再次进入 DashBorad 界面了,我们创建的可视化看板可以投入使用了
这里简单地介绍下各个板块的作用 吧,其他没有什么好讲的,有时间玩玩就可以
使用 Kibana 可视化监控看板的教程到这里就结束了(2023/12/03 午)
博文搜索优化
今天晚上,总算抽出时间,着手优化一下博文搜索这一大板块了:
Vue 实现外部引入页面组件
外部页面组件 ArticleList 携带参数,参数名为 compreList,参数值为 articleList
1 2 3 4 5 6 7 <a-tabs v-model:activeKey="activeKey" tab-position="left">
编写内部组件 CompreArticleList,接收参数 compreList,使用 a-list组件展示
1 2 3 4 5 6 7 8 <a-list
1 2 3 4 5 6 7 8 9 10 11 12 13 <script setup lang="ts" >import {defineProps, withDefaults} from "vue/dist/vue" ;interface Props {compreList : any [];const props = withDefaults (defineProps<Props >(), {compreList : () => [],
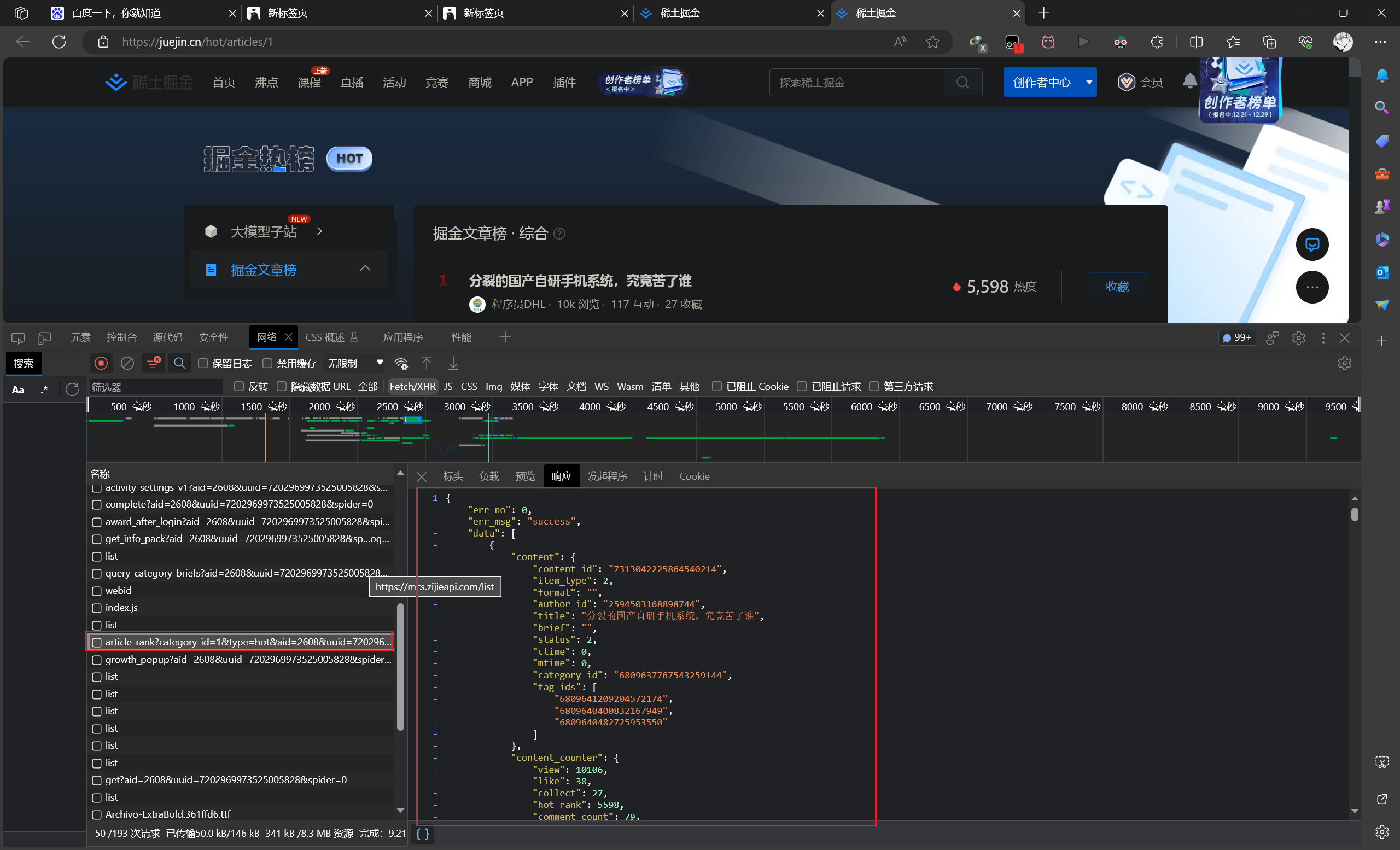
爬取掘金热榜文章
分析掘金热榜博文
编写爬虫
使用 Hutool 工具库,实现 I/O 爬虫,获取掘金热榜中的所有文章 id:
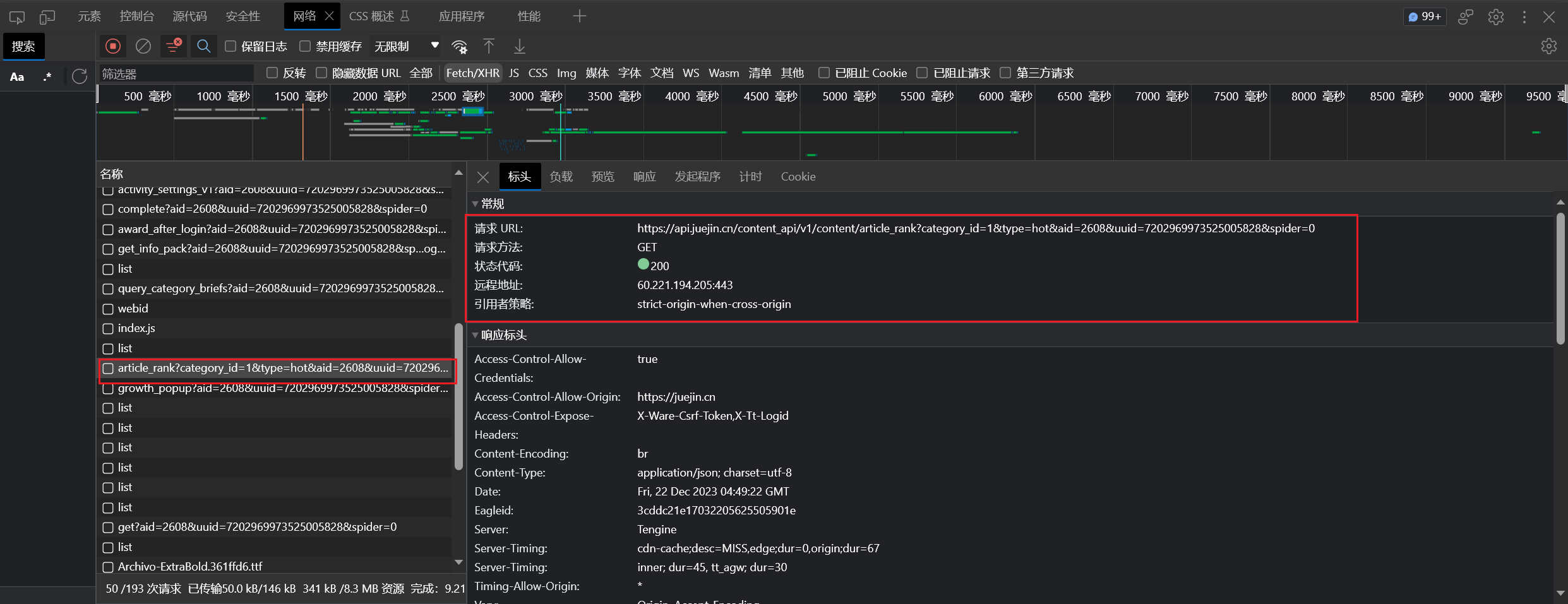
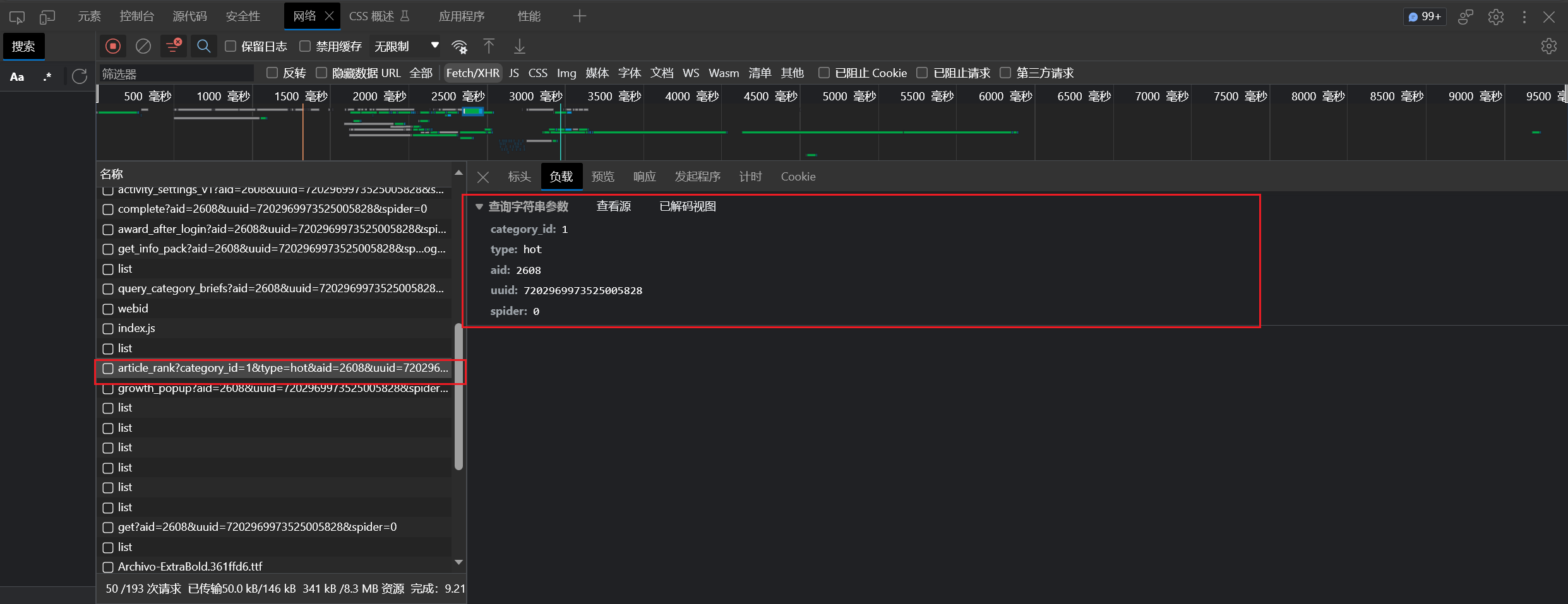
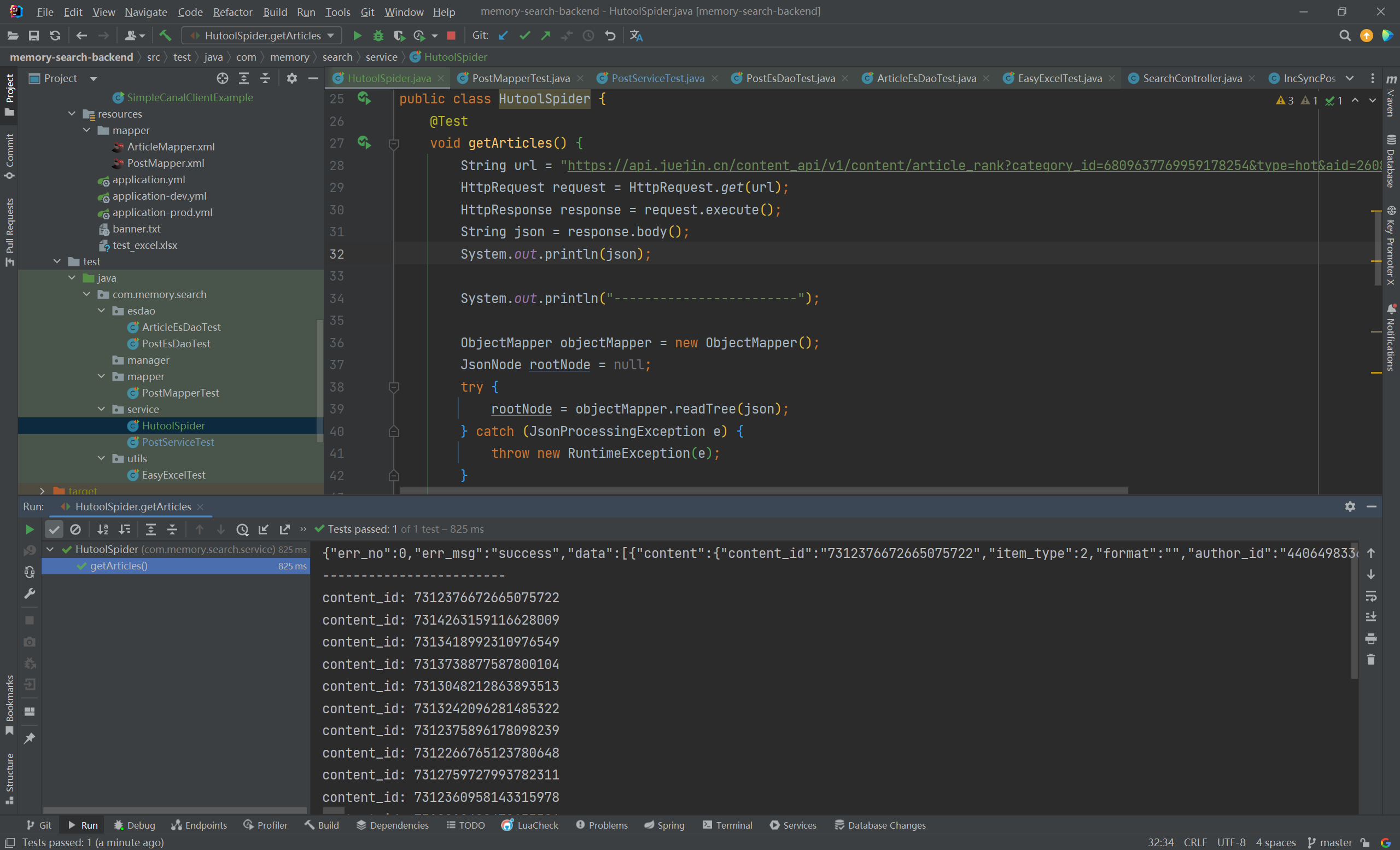
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Test void getArticles () {String url = "https://api.juejin.cn/content_api/v1/content/article_rank?category_id=6809637769959178254&type=hot&aid=2608&uuid=7202969973525005828&spider=0" ;HttpRequest request = HttpRequest.get(url);HttpResponse response = request.execute();String json = response.body();"------------------------" );ObjectMapper objectMapper = new ObjectMapper ();JsonNode rootNode = null ;try {catch (JsonProcessingException e) {throw new RuntimeException (e);JsonNode dataNode = rootNode.get("data" );for (JsonNode jsonNode : dataNode) {JsonNode contentNode = jsonNode.get("content" );String contentId = contentNode.get("content_id" ).asText();"content_id: " + contentId);
拿到掘金文章 id 后,使用 jsoup 库发起请求,获取 HTML 文档,并解析获得文章数据:
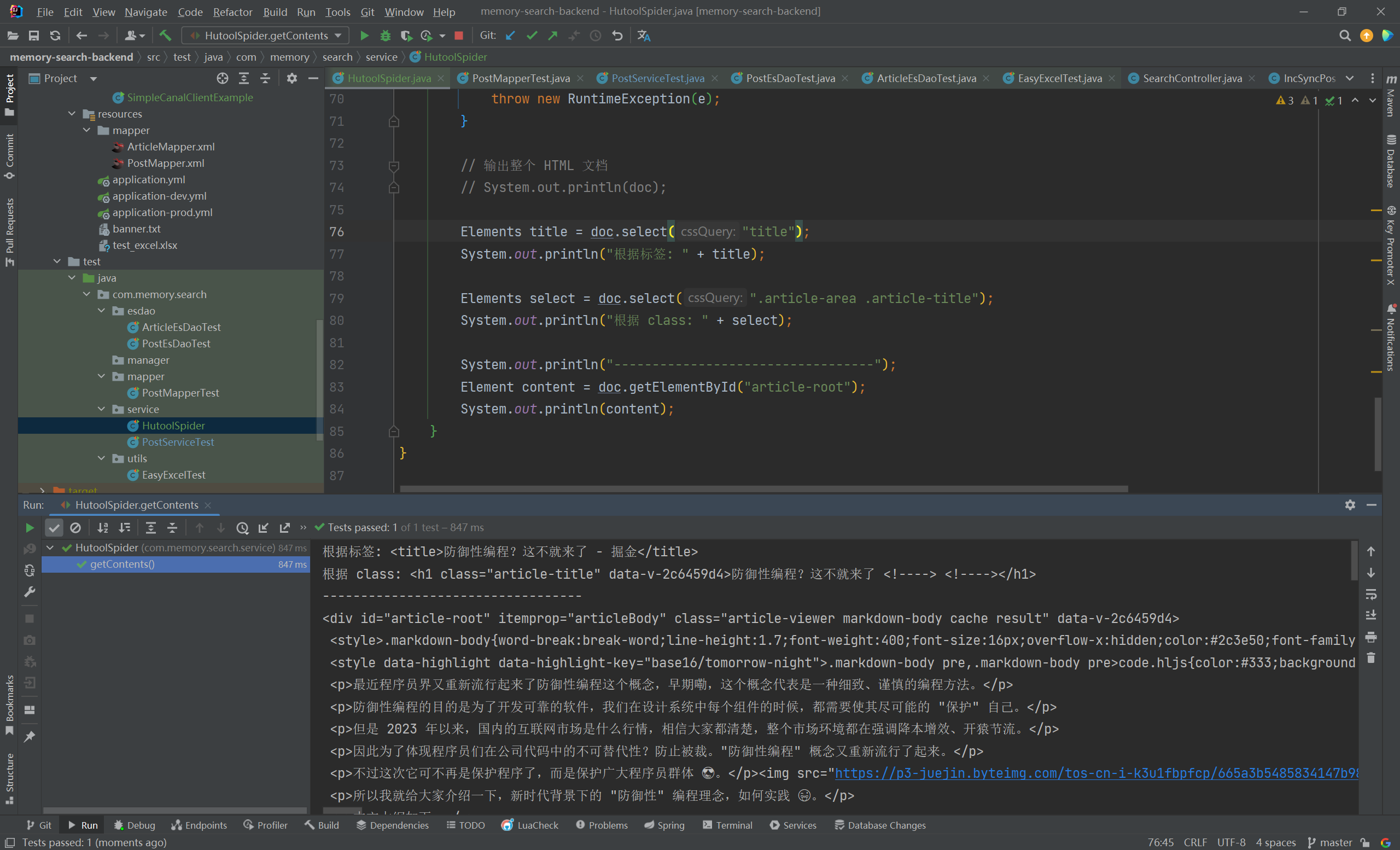
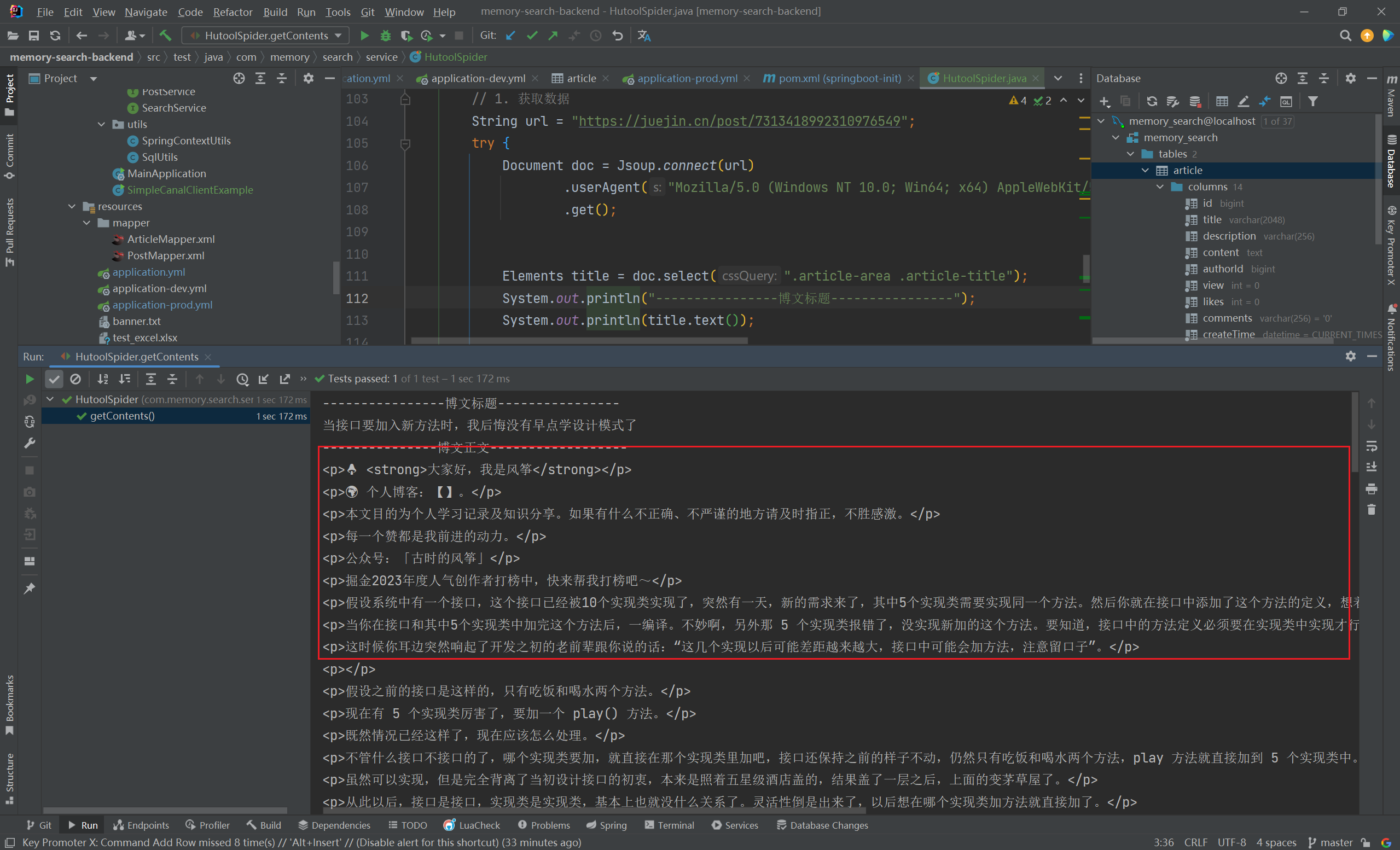
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Test void getContents () {String url = "https://juejin.cn/post/7312376672665075722" ;Document doc = null ;try {"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81" )catch (IOException e) {throw new RuntimeException (e);Elements title = doc.select("title" );"根据标签: " + title);Elements select = doc.select(".article-area .article-title" );"根据 class: " + select);"----------------------------------" );Element content = doc.getElementById("article-root" );
爬取结果
优化思路
博文来源:爬取掘金文章榜(2023/12/20 晚)
目前看来每个文章类别下有 20 篇文章,那就创建一张表吧
按照类别,可以将博文简单分类
聚合搜索时,额外添加一个条件:根据文章类别查询到对应的博文,这就需要把对博文的全局搜索推迟到 ArticleList 实现了
数据同步是这个项目的一大亮点,使用 Logstash 进行数据同步在本地测试已经很成熟了,可以考虑采用 canal 方法实现
搜索建议和关键词高亮,这也该项目的一大亮点,如果能成功完成就好了
限流,四种限流算法,就这么个小项目,虽然远不至于用到限流,但是学习限流还是很有必要的
写一个定时爬虫,定时爬取并更新博文数据
开发者文档:Memory-Tools 开发者文档,这个文档的成功开发部署,使得这个工作变得稍微简单了一些
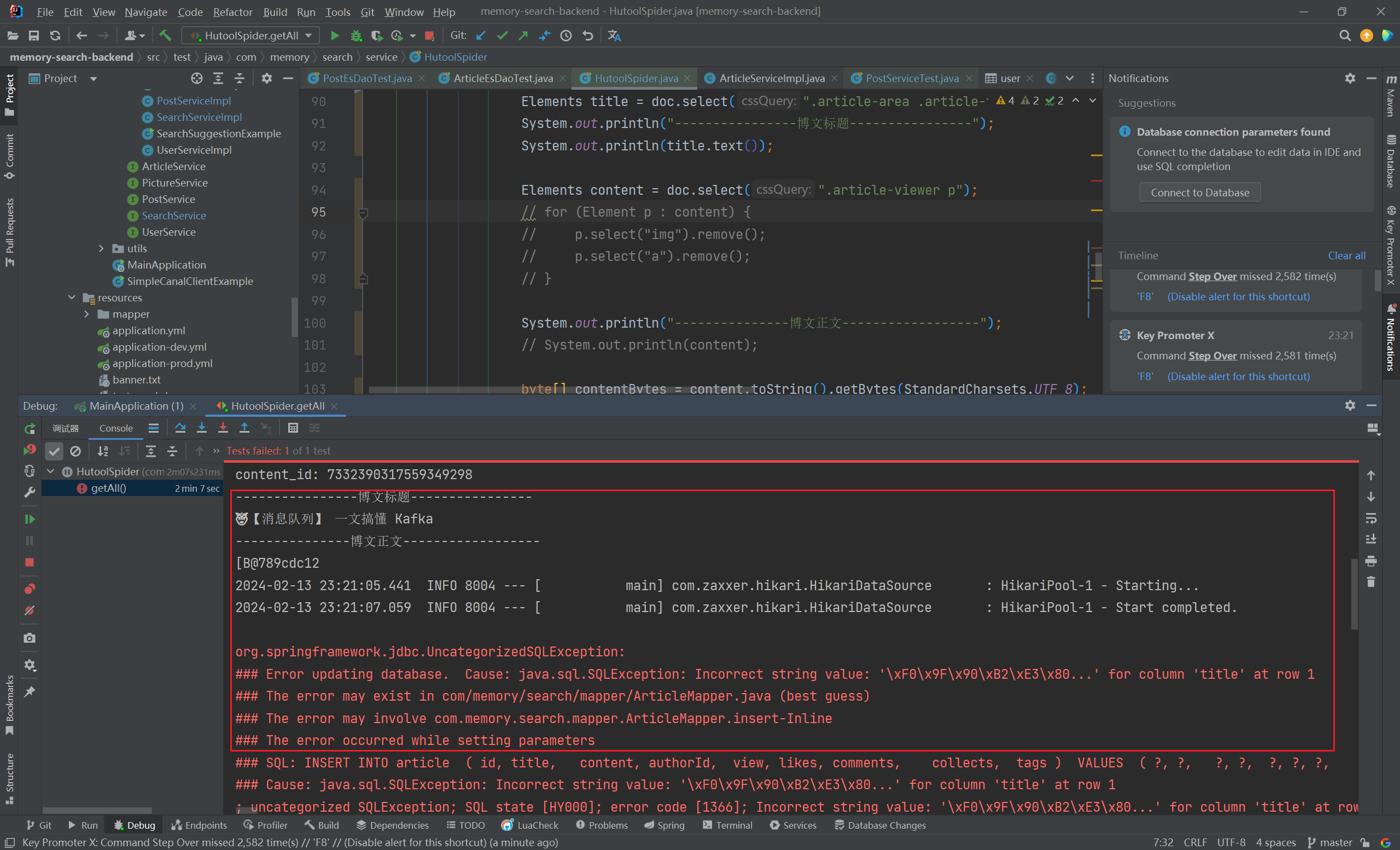
存储数据库编码错误 问题引出
1 2 3 4 org.springframework.jdbc.UncategorizedSQLException:'\xF0\x9F\x8D\x84 \xE5...' for column 'content' at row 1 in com/memory/search/mapper/ArticleMapper.java (best guess)
这是因为保存到数据库中的内容中,包含了不能正确解码的内容, 这就是直接保存 ,详细情况如下:
直接保存 数据库中,文章内容 content 字段属性为 varchar,用来保存字符串:(2023/12/24 早)
1 2 3 4 private String content;
爬取到文章内容,直接保存文章内容:
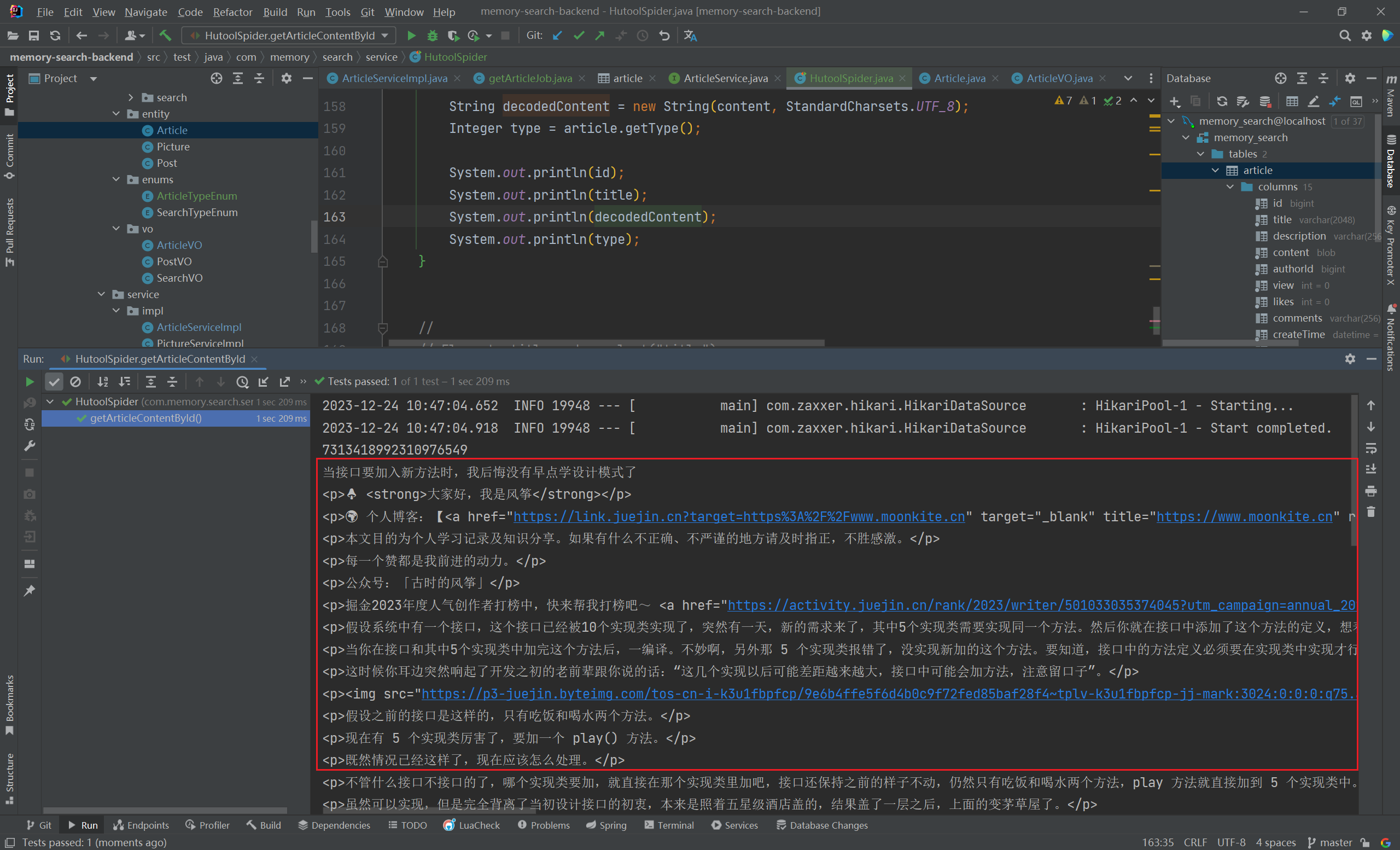
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 String url = "https://juejin.cn/post/7313418992310976549" ;try {Document doc = Jsoup.connect(url)"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81" )Elements title = doc.select(".article-area .article-title" );"----------------博文标题----------------" );Elements content = doc.select(".article-viewer p" );"---------------博文正文------------------" );byte [] contentBytes = content.toString().getBytes(StandardCharsets.UTF_8);Article article = new Article ();"7313418992310976549" ));0L );0 );0 );"" );0 );"" );catch (IOException e) {throw new RuntimeException (e);
这里直接保存,会出现字符编码无法识别而转换错误,就是因为保存的数据记录中有 emoji 这样的小图标
这里我也查询了相关文章,解决这个问题,虽然最后没有解决,但仍可做参考:
🔥 推荐阅读:
1 Error updating database. Cause: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x8D\x84 \xE5...' for column 'content' at row 1
转二进制数组保存 保存数据的时候,先转码保存(转为二进制字符数组 ),取出数据的时候,解码后再使用:
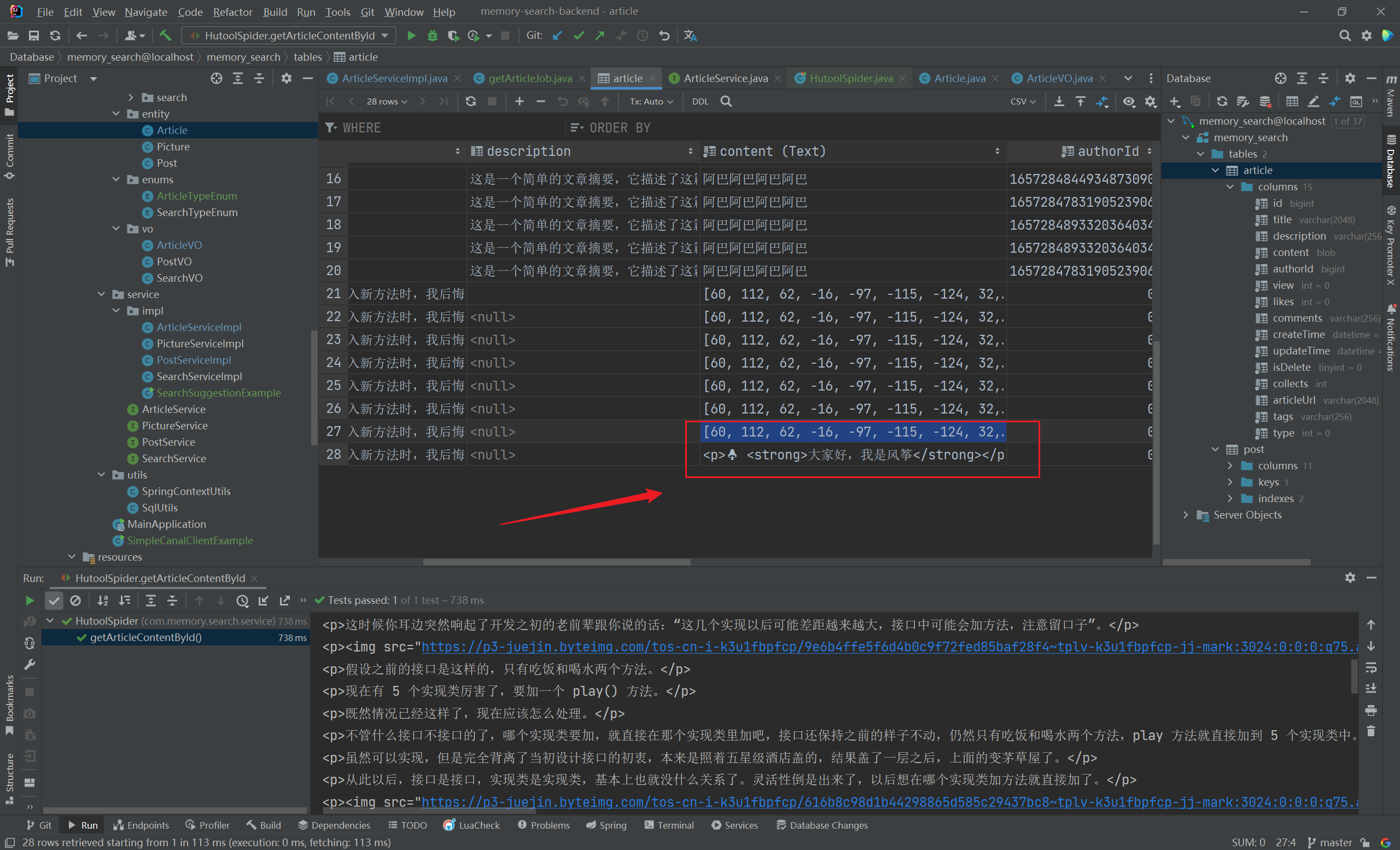
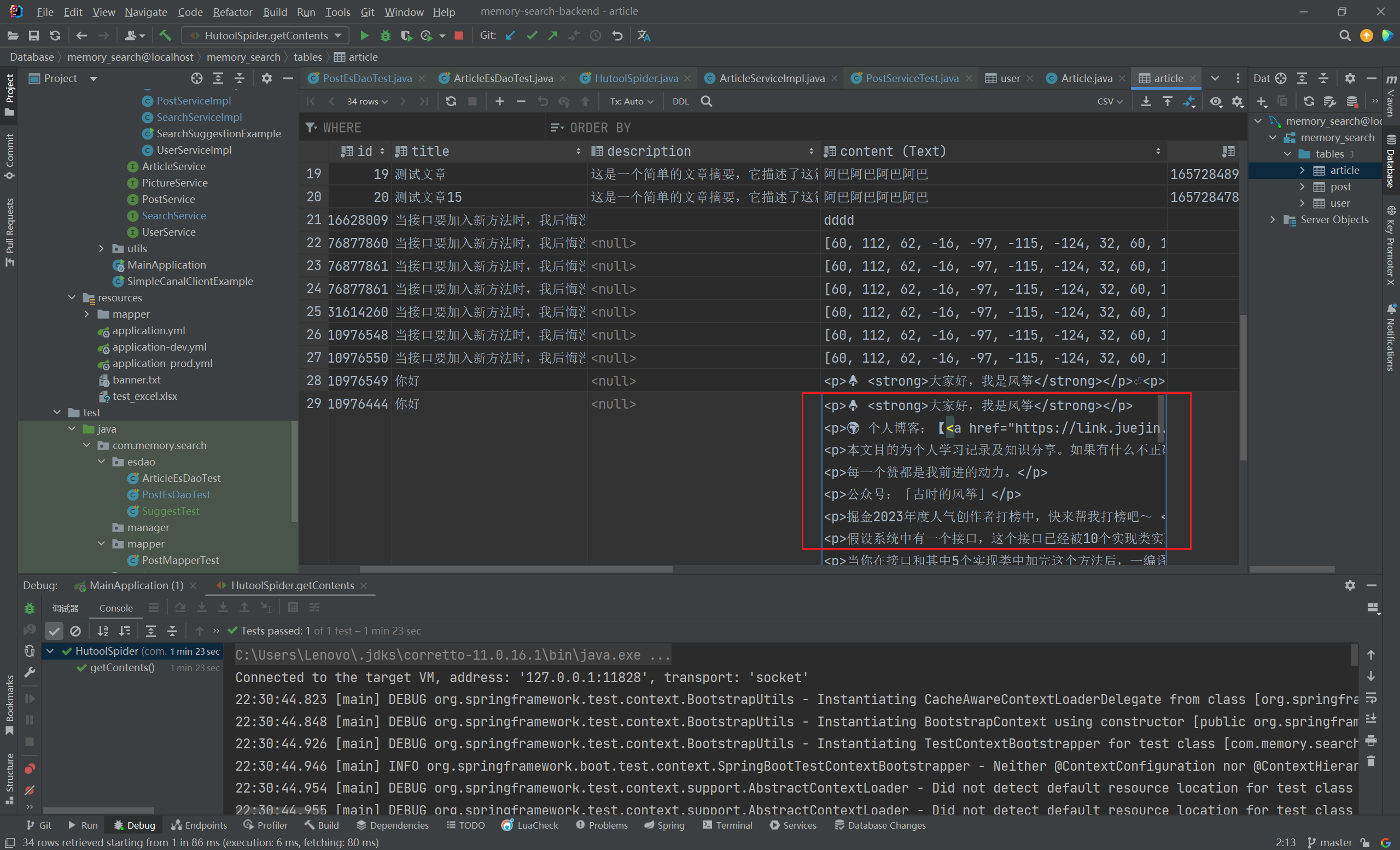
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 byte [] contentBytes = content.toString().getBytes(StandardCharsets.UTF_8);Article article = new Article ();"7313418992310976549" ));0L );0 );0 );"" );0 );"" );String decodedContent = new String (contentBytes, StandardCharsets.UTF_8);"-------------解码后--------------" );
保存到数据库中的问题解决了,接下来就是保证正确从数据库中拿到数据并解码出原数据:
1 2 String contentStr = article.getContent();byte [] contentBytes = contentStr.getBytes(StandardCharsets.UTF_8);
1 2 3 4 5 6 7 8 9 String contentStrWithoutBrackets = contentStr.substring(1 , contentStr.length() - 1 );"," );byte [] contentBytes = new byte [byteStrs.length];for (int i = 0 ; i < byteStrs.length; i++) {
经尝试,以上方法并不能成功将保存到数据库中的二进制数组成功解码成原文章字符串,解码失败
我们保存二进制数组到数据库中,成功避免了 emoji 表情转码保存失败的问题,但是这样存入数据库,取出时就不好处理了
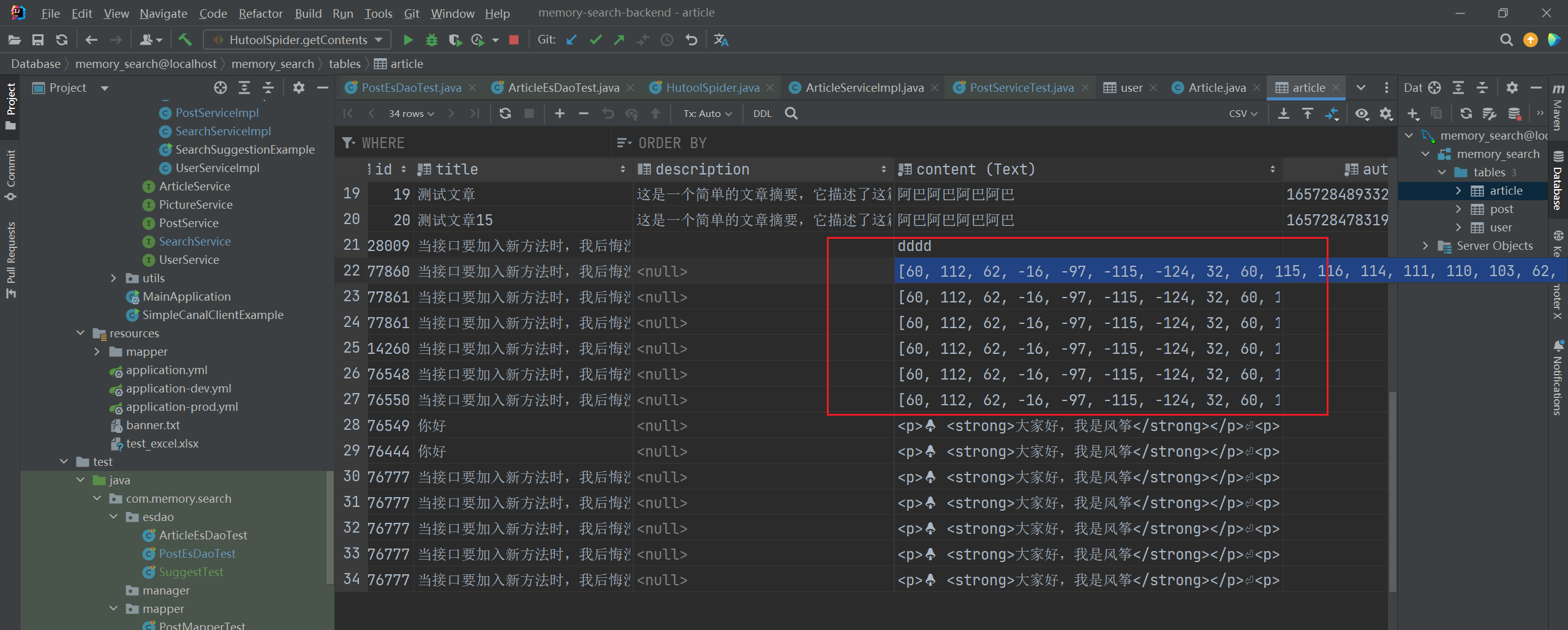
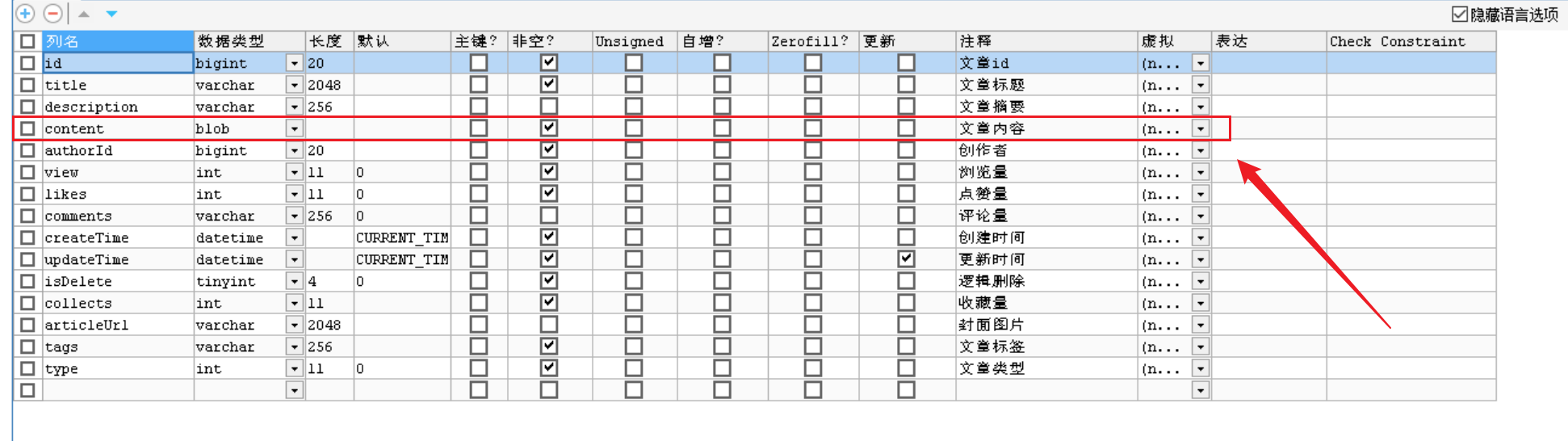
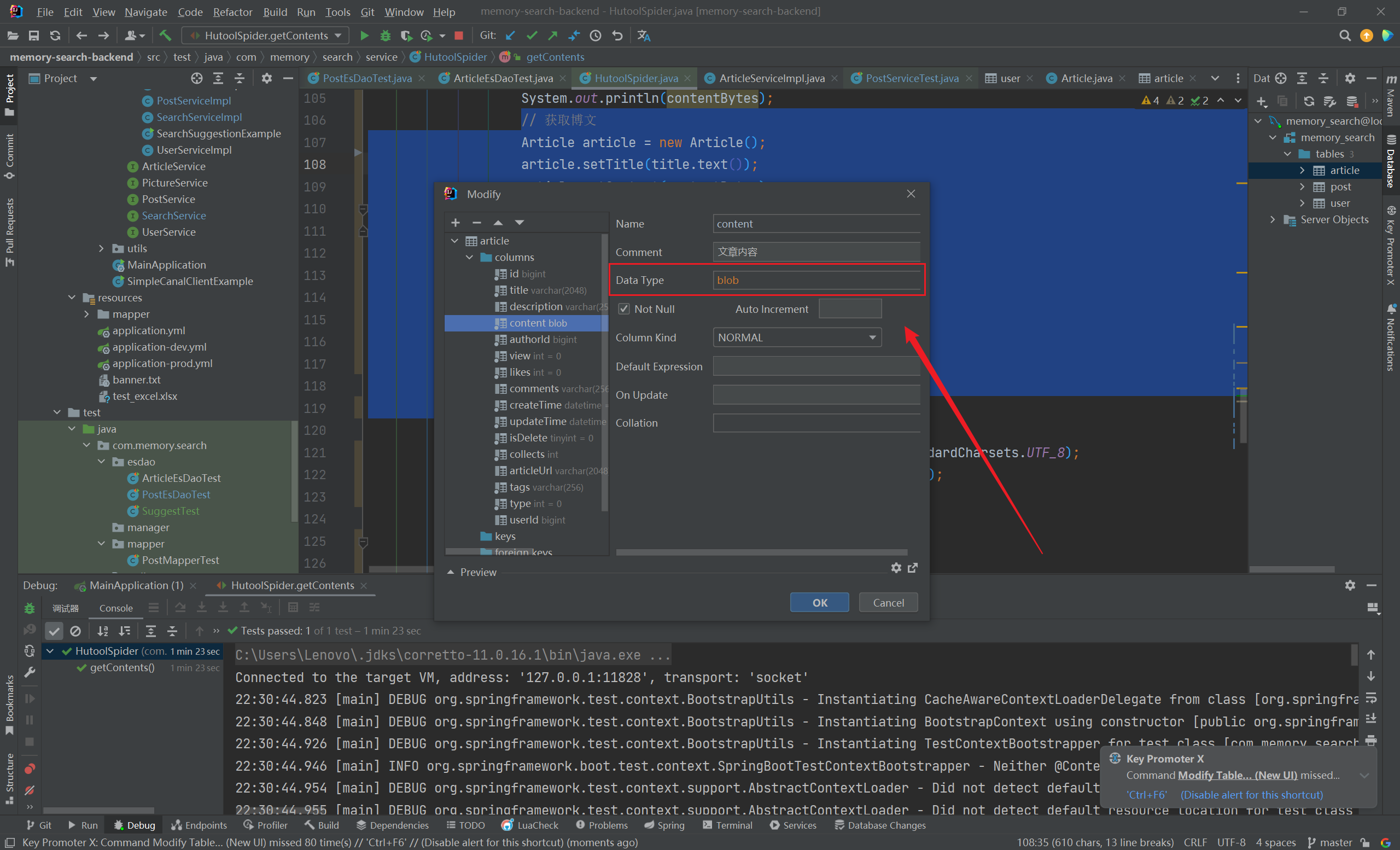
如上,对 byte [] 直接解码是可以获取原文内容 content 的,那就干脆直接保存 byte [] 到数据库中了,改变字段 content 属性为 blob:
1 2 3 4 private byte [] content;
接下来,我们选择直接保存 byte [] 到数据库中即可:
1 article.setContent(contentBytes);
这里也可以看出,将 byte [] 转字符串数组后保存和直接保存 byte [] 到数据库中的形式是很不一样的(如下图所示):
改变数据库字符集一点都不好使:(2023/12/23 晚)
用户昵称含 emoji 表情保存到数据库中报错 SQLException: Incorrect string value: ‘\xF0\x9F\x91\xA7’ for colum n …-CSDN 博客
java 后台接收获取微信昵称,昵称包含小图标保存到数据库报错-CSDN 社区
直接保存二进制 终于解决了如何正确保存含 emoji 表情数据到数据库中的问题了
经过诸多尝试,仍无法正确解码保存 emoji 表情,经过测试,转码保存解决报错:(2023/12/24 早)
经过前面的测试发现,转码后保存 byte [] 可以解决编码错误,问题是出在保存数据库时
由于字段 content 为 text(varchar 也可以,可能会出现要保存的数据记录过长而导致溢出,就选择 text 了),所以我们在保存 byte [] 到数据库中时,是先转换成字符串再保存的
1 article.setContent(Arrays.toString(contentBytes));
爬取文章,获取标题和内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Document doc = Jsoup.connect(url)"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81" )Elements title = doc.select(".article-area .article-title" );"----------------博文标题----------------" );Elements content = doc.select(".article-viewer p" );"---------------博文正文------------------" );byte [] contentBytes = content.toString().getBytes(StandardCharsets.UTF_8);
将文章内容转二进制后,保存至数据库中:
1 2 3 4 private byte [] content;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Article article = new Article ();0L );0 );0 );"" );0 );"" );
如下,成功保存文章内容至 MySQL 数据库中:
如需获取文章数据,取出二进制数组后,是可以直接解码获取原文的:
1 2 3 String decodedContent = new String (contentBytes, StandardCharsets.UTF_8);"-------------解码后--------------" );
1 2 3 4 5 6 7 8 9 10 11 12 13 Article article = articleService.getById(7313418992310976549L );Long id = article.getId();String title = article.getTitle();byte [] content = article.getContent();String decodedContent = new String (content, StandardCharsets.UTF_8);Integer type = article.getType();
至此,我们成功解决了如何正确保存数据记录到数据库中的问题,并成功解决了编码问题(2023/12/24 午)
前端后续
原因是拿到的 content 字段值无法解析,那我们将实体类 ArticleDTO 的 content 属性类型仍设为 String:
1 2 3 4 private String content;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public ArticleVO getArticleVOByArticle (Article article) {ArticleVO articleVO = new ArticleVO ();byte [] contentBytes = article.getContent();String content = new String (contentBytes, StandardCharsets.UTF_8);
编码不一致 ES 同步失败
他爷爷的,同步 MySQL 和 ES 数据的时候又出现了问题,我还得搞如何在 ES 中存储 byte [] 数据:
那就重新创建一个索引,能够使 content 字段存放二进制记录:(2023/12/24 晚)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 PUT / article_v3256
这是什么问题?ES 中 article_v4 索引中的字段 content 是 binary 属性,而二进制数据是不支持 match queries 筛选操作的:
1 2 3 4 5 6 7 if (StringUtils.isNotBlank(searchText)) {"title" , searchText));"description" , searchText));"content" , searchText));1 );
在编写 DSL 语句插入新索引时也不能对 binary 属性的字段添加 analyzer 和 search_analyzer:
1 2 3 4 5 6 7 8 9 10 11 "content": {
那我不搞了,同步博文数据时,不同步 content 字段了,使用 ES 查询到 id,再拿 id 去查询数据库就行了
搜索建议 后端
新增索引,特别指定 title 字段支持 suggest 搜索词建议:(2023/12/24 晚)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 PUT / article_v4256
使用 Logstash 同步 MySQL 和 ES,该写数据同步配置文件(排除 content 字段),开启数据同步:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 filter {= > {= > "updateTime"= > "userId"= > "createTime"= > "isDelete"= > ["thumbnum", "favournum","content"]= > rubydebug }= > ["127.0.0.1:9200"]= > "article_v4"= > "%{id}"
1 2 @Resource private ElasticsearchRestTemplate elasticsearchRestTemplate;
1 2 3 SuggestBuilder suggestBuilder = new SuggestBuilder ()"suggestionTitle" , new CompletionSuggestionBuilder ("title.suggest" ).skipDuplicates(true ).size(5 ).prefix(searchText));
注意,这里的搜索建议配置跟这条 DSL 语句是对应的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 GET article_v4/ _search/ / 这个字段是关键字,不能随便起名/ / 这个是自己起的名字/ / 这个是前缀/ / 这个是你自己定义的索引
1 2 3 4 5 6 7 8 9 10 11 PageRequest pageRequest = PageRequest.of((int ) pageNum, (int ) pageSize);NativeSearchQuery searchQuery = new NativeSearchQueryBuilder ()
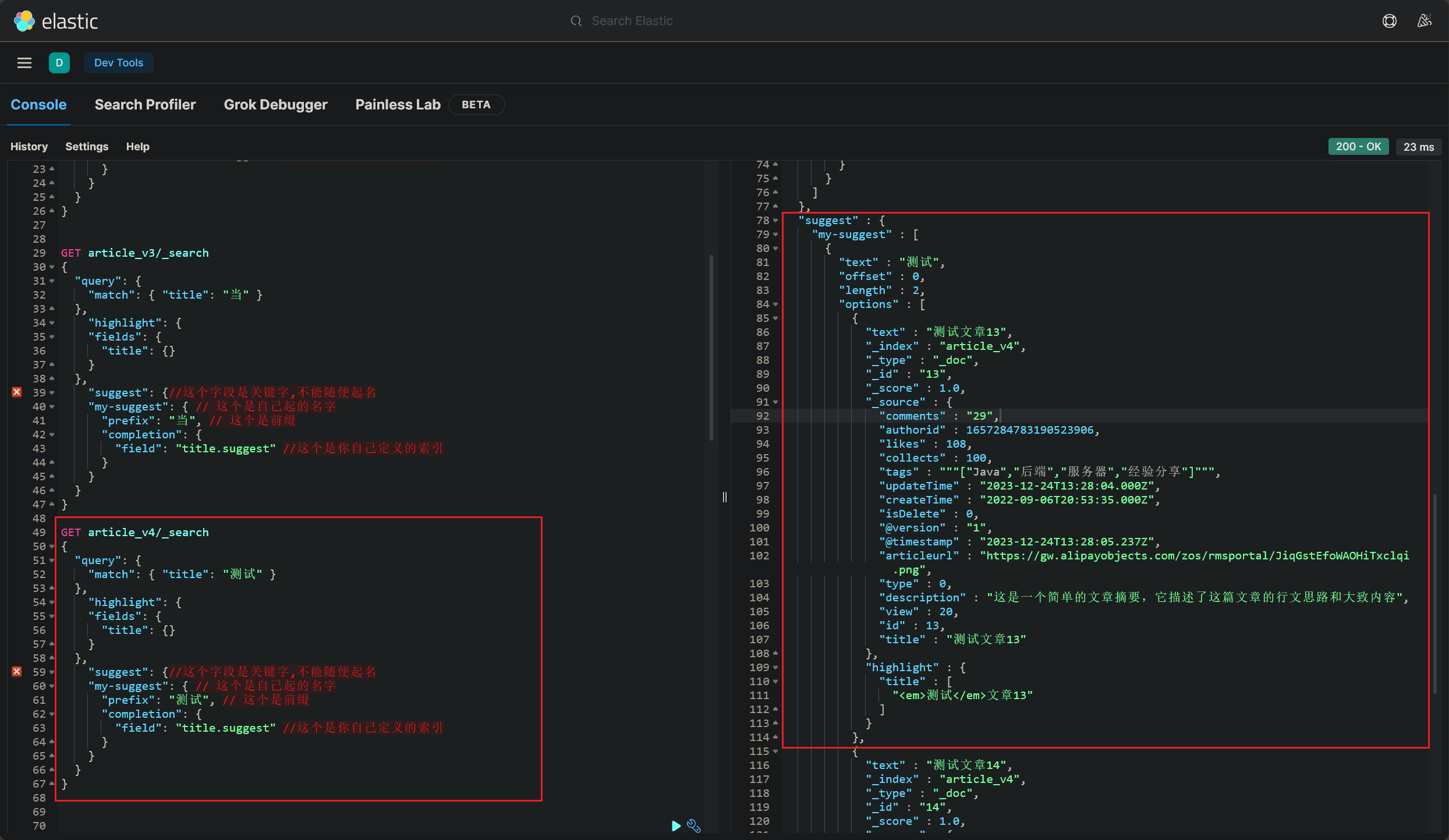
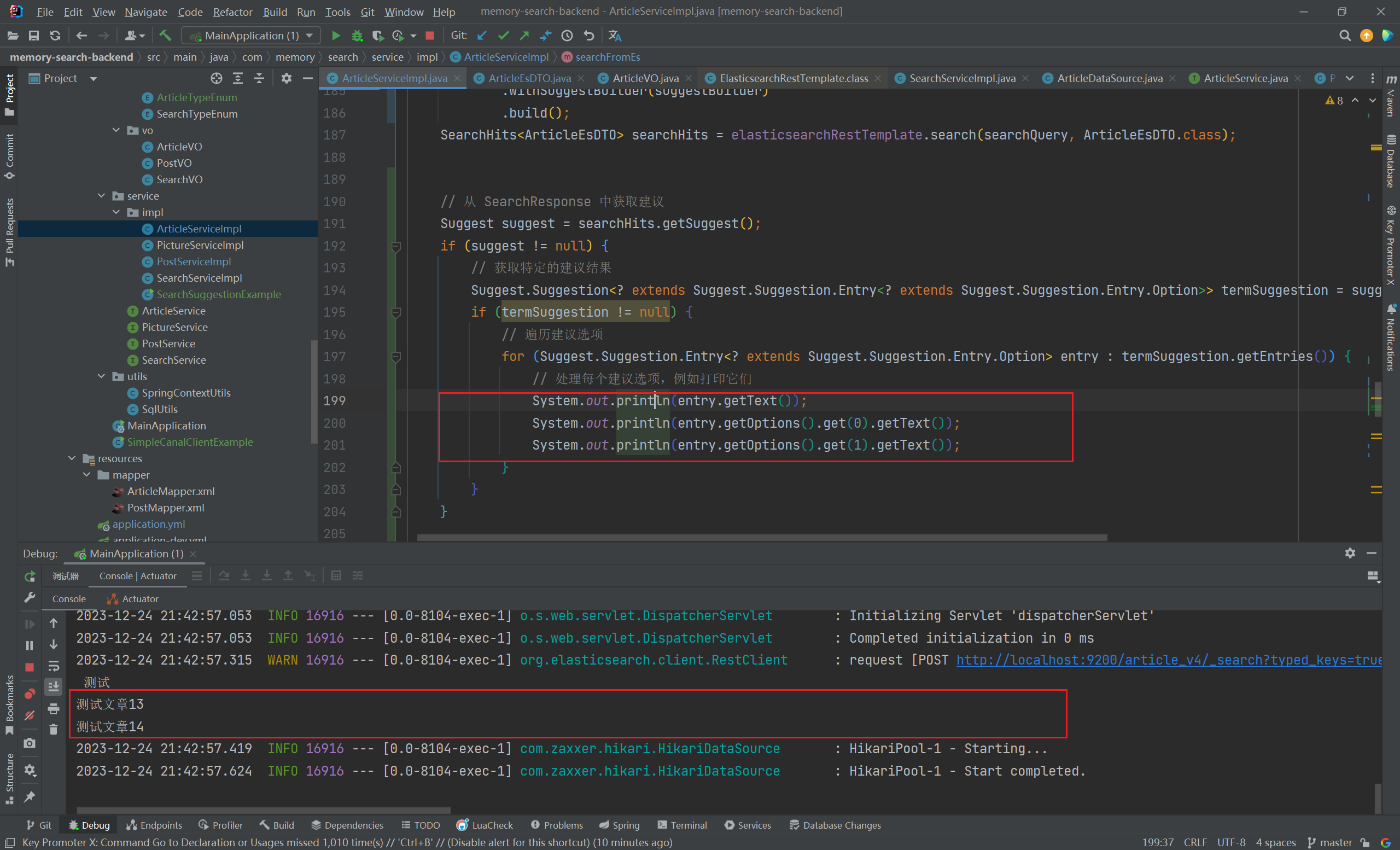
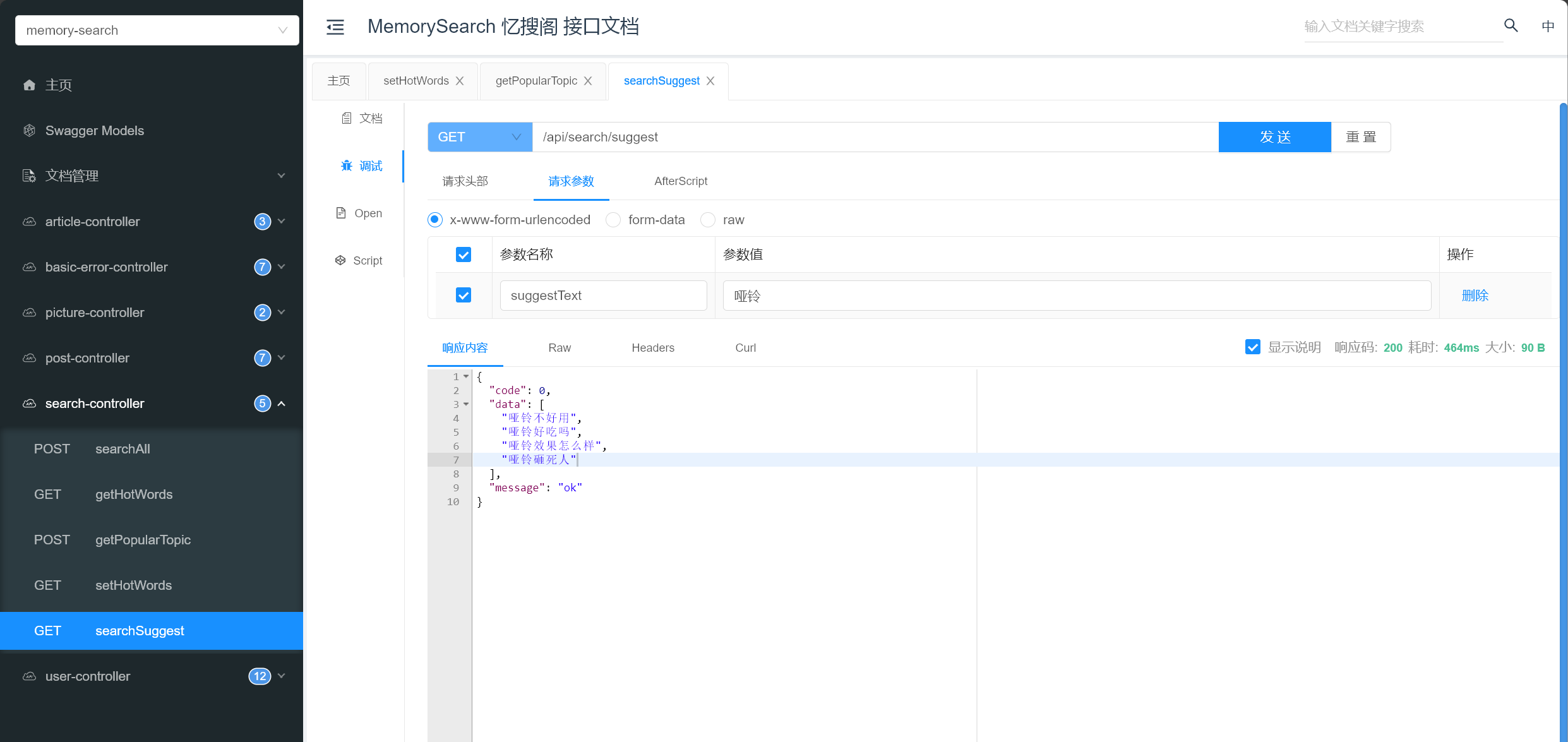
根据搜索词 searchText 从 SearchResponse 中获取建议:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Suggest suggest = searchHits.getSuggest();if (suggest != null ) {extends Suggest .Suggestion.Entry<? extends Suggest .Suggestion.Entry.Option>> termSuggestion = suggest.getSuggestion("suggestionTitle" );if (termSuggestion != null ) {for (Suggest.Suggestion.Entry<? extends Suggest .Suggestion.Entry.Option> entry : termSuggestion.getEntries()) {0 ).getText());1 ).getText());
注意看,这里可以选取的建议选项跟这里是一一对应的:
执行查询,成功获取到搜索关键词对应的查询建议:(2023/12/24 晚)
前端
1 2 3 4 5 6 7 8 <a-auto-completemodel :value="searchText" "options" "width: 200px" "请输入搜索关键词" @select ="onSelect" @search ="onSearch"
发起请求,获取搜索建议词,保存返回结果并解析(2023/12/27 早)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 const onSearchSuggest = (suggestText: string ) => {get ("/search/suggest" , {params : {suggestText : suggestText,then ((res: any ) => {if (res) {value = res;console .log ("res = " + suggestionList.value );value = !suggestTextgetSuggest (suggestionList.value [0 ]),getSuggest (suggestionList.value [1 ]),getSuggest (suggestionList.value [2 ]),getSuggest (suggestionList.value [3 ]),getSuggest (suggestionList.value [4 ]),
绑定搜索建议词到a-auto-complete中,展示搜索建议
1 2 3 4 5 6 7 8 9 10 interface Suggest {value : string ;const getSuggest = (sug : string ): Suggest =>return {value : sug,
支持从搜索建议列表中,单击选择其中一项填充到a-auto-complete输入框中
1 2 3 4 5 6 7 const options = ref<Suggest []>([]);const onSelect = (value: string ) => {console .log ("onSelect" , value);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 const onSearch = (searchText: string ) => {console .log (searchText);push ({query : {value ,text : searchText,loadData (searchParams.value );const type = route.params .category ;if (type === "post" ) {success ("成功检索出您感兴趣的诗词~" );else if (type === "user" ) {success ("成功检索出您感兴趣的用户~" );else if (type === "picture" ) {value = [];getImages ();else if (type === "article" ) {success ("成功检索出您感兴趣的博文~" );
在输入框中输入内容,即可显示建议列表
成功实现获取搜索建议词,实现代码已经在上述代码中更新,最终效果如下:(2023/12/27 早)
onSearch 函数未传参引发的问题
又解决了一个小问题:(2023/12/25 晚)
将之前的搜索框拆分成两个:自动完成输入框 和一个 Button按钮:
1 2 3 4 5 6 7 8 <!--搜索框-->
1 2 3 4 5 6 7 8 9 10 <a-auto-complete
这两个搜索函数分别执行了搜索建议词搜索和数据库记录搜索:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 const onSearchSuggest = (suggestText: string ) => {get ("/search/suggest" , {params : {suggestText : suggestText,then ((res: any ) => {console .log ("res = " + res);value = !suggestTextgetSuggest (), getSuggest (), getSuggest ()];
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 const onSearch = (searchText: string ) => {console .log (searchText);push ({query : {value ,text : searchText,loadData (searchParams.value );const type = route.params .category ;if (type === "post" ) {success ("成功检索出您感兴趣的诗词~" );else if (type === "user" ) {success ("成功检索出您感兴趣的用户~" );else if (type === "picture" ) {value = [];getImages ();else if (type === "article" ) {success ("成功检索出您感兴趣的博文~" );
结果就是因为转换成使用一个 Button 那按钮执行搜索操作,没有及时改正语法格式,写成了:
1 <a-button type="primary" @click="onSearch">搜索框</a-button>
显而易见,onSearch 函数并没有传递参数,这就导致了 ·onSearch· 函数一直不会被正确执行
还好我比较聪明,发现了这个问题(2023/12/25 晚)
热搜词统计 RedisTemplate.opsForZSet()用法简介并举例-CSDN 博客
思路一:
key 值存储搜索词条,value 值用 String 数据结构,存储:用户 id + 搜索次数 + 搜索时间 ,方便根据搜索词条查询词条相关信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 @Override public List<Message> setHotWords (String suggestTextStr, HttpServletRequest request) {if (com.qcloud.cos.utils.StringUtils.isNullOrEmpty(suggestTextStr)) {return null ;" " );new ArrayList <>();for (String suggestText : suggestTexts) {String messageStr = redisTemplate.opsForValue().get(String.format(REDIS_KEY_TEMPLATE, suggestText));Message message = null ;Gson gson = new Gson ();if (ObjectUtils.isNotEmpty(messageStr)) {Message mes = gson.fromJson(messageStr, Message.class);Integer searchNum = mes.getSearchNum();Integer newSearchNum = searchNum + 1 ;new Message (MESSAGE_ID, suggestText, newSearchNum);else {new Message (MESSAGE_ID, suggestText, SEARCH_NUM);boolean add = messageList.add(message);"记录热搜词失败" );30 , TimeUnit.DAYS);return messageList;
很方便查询所有搜索词条相关信息 ,但根据 value 值内的 searchNum 按序查询前十条数据 较困难:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override public List<Message> getHotWords () {"search:hot*" );new ArrayList <>();Gson gson = new Gson ();for (String key : Objects.requireNonNull(keys)) {String messageStr = redisTemplate.opsForValue().get(key);Message message = gson.fromJson(messageStr, Message.class);return hotWordList;
词条相关信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Data public class Message {private Long userId;private String searchText;private Integer searchNum;public Message (Long userId, String searchText, Integer searchNum) {this .userId = userId;this .searchText = searchText;this .searchNum = searchNum;public Message (Long userId, Integer searchNum) {this .userId = userId;this .searchNum = searchNum;
思路二:
使用 ZSet 数据结构,key 值存储搜索时间,可统计不同时间段内的热门搜索词
value 值存储:用户 id + 搜索次数 + 搜索时间 ,维护 score 分数,更新搜索词条searchNum,即更新score分数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 @Override public List<Message> setHotWords (String searchTextStr, HttpServletRequest request) {if (com.qcloud.cos.utils.StringUtils.isNullOrEmpty(searchTextStr)) {return null ;" " );new ArrayList <>();for (String searchText : searchTexts) {Long size = redisTemplate.opsForZSet()Message message = null ;Gson gson = new Gson ();if (size > 0 ) {Message mes = gson.fromJson(SEARCH_TIME, Message.class);Double searchNum = mes.getSearchNum();new Message (MESSAGE_ID, searchText, ++searchNum);1 );else {new Message (MESSAGE_ID, searchText, SEARCH_NUM);boolean add = messageList.add(message);"记录热搜词失败" );return messageList;
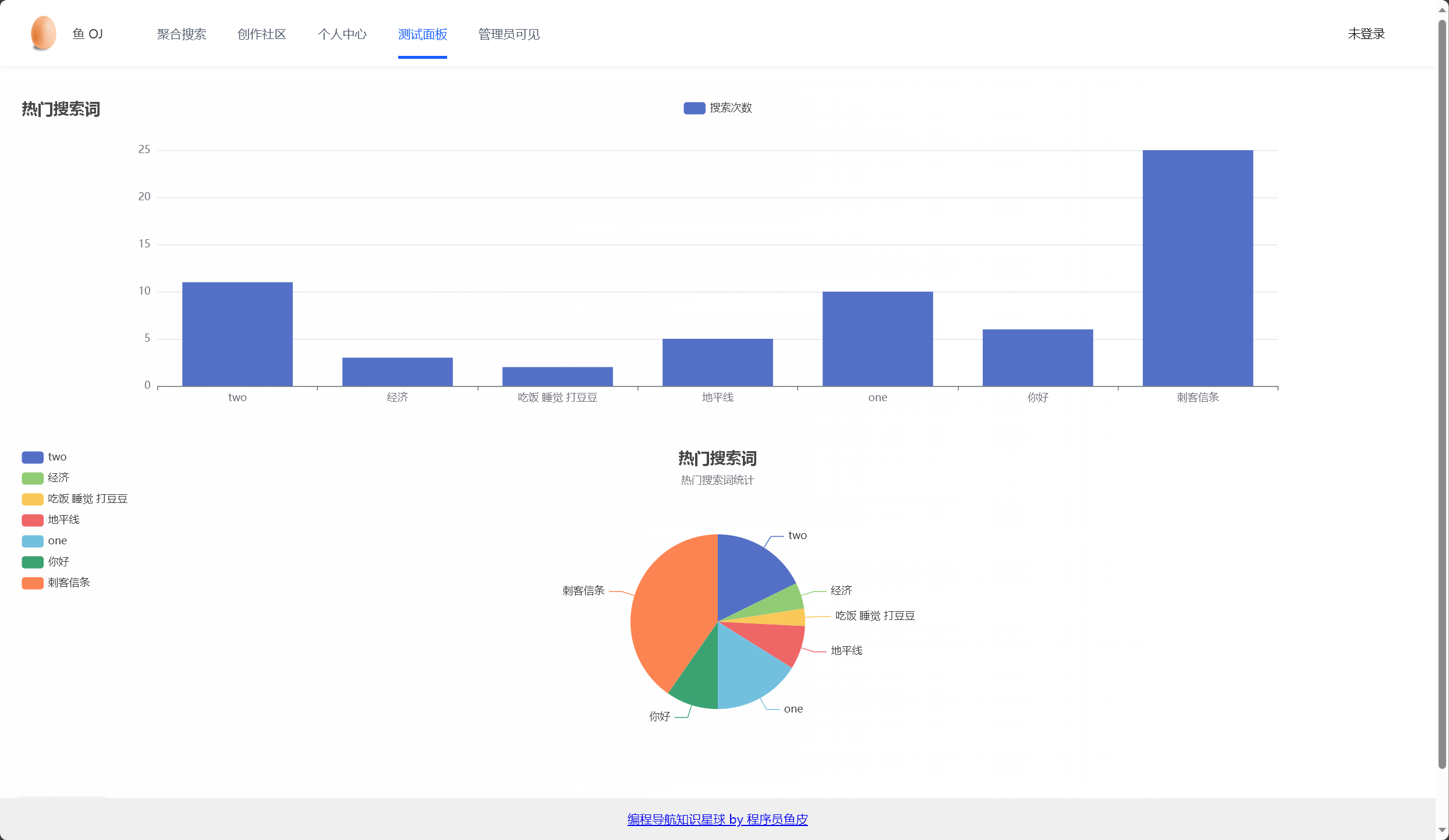
根据 score 搜索次数,十分便捷地查询出前十条词条信息,即热门搜索词条 :(2024/02/05)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Override public List<MessageVO> getHotWords () {0 , 9 );new ArrayList <>();Gson gson = new Gson ();for (String messageStr : Objects.requireNonNull(messageSet)) {Message message = gson.fromJson(messageStr, Message.class);Double score = redisTemplate.opsForZSet()MessageVO messageVO = new MessageVO ();boolean add = messageVOList.add(messageVO);"获取热搜词失败" );return messageVOList;
词条相关信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Data public class Message {private Long userId;private String searchText;public Message (Long userId, String searchText) {this .userId = userId;this .searchText = searchText;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Data public class MessageVO {private Long userId;private String searchText;private Double searchNum;public MessageVO () {public MessageVO (Long userId, String searchText, Double searchNum) {this .userId = userId;this .searchText = searchText;this .searchNum = searchNum;
权限校验 全局请求过滤器,ThreadLocal 记录登录用户信息
1 2 3 4 5 6 7 8 9 10 11 12 13 User currentUser = (User) request.getSession().getAttribute(USER_LOGIN_STATE);if (currentUser != null ) {"该用户已登录,id为{}" , userId);return ;
查询文章,携带查询用户信息
1 2 3 4 Long currentId = BaseContext.getCurrentId();User user = userService.getById(currentId);UserVO userVO = userService.getUserVO(user);
成功查询到用户信息
网站首页
主页 | vuepress-theme-hope (vuejs.press)
关于该主题的使用方法,在此简单予以说明:
首页配置:
1 2 3 4 5 6 7 8 9 10 11 ---true
注册用户管理 可算坑死我了:
1 2 3 4 5 6 7 8 9 <a-table"userColumns" "userList ? userList : []" "true" "true" "true" "true" "pagination"
千万不能写成: :data=”:data=”userList ? [] : userList”,完全低级错误,不好发现
图片缓存实现 1 2 3 4 5 2 , TimeUnit.HOURS);
Open API 生成请求接口,还经过 Spring 过滤器:
1 openapi --input http:// localhost:8104 /api/ v2/api-docs?group=memory-search --output ./g enerated --client axios
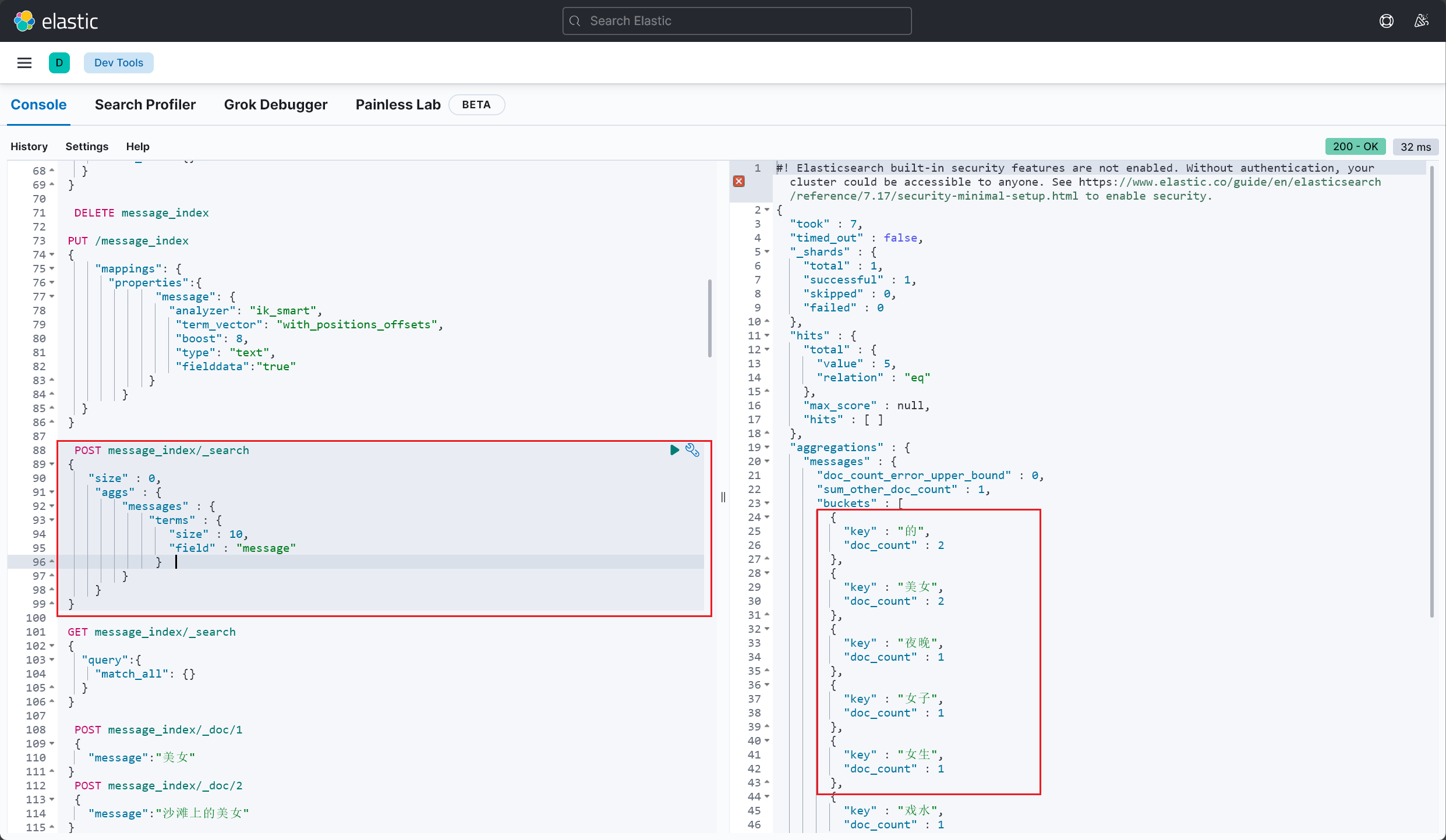
热门词分析 官方文档:[Aggregations | Elasticsearch Guide 7.17] | Elastic
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 GET / my- index-000001 / _search
如上,分别根据 title 和 description 字段分组聚合查询出热门话题,这样在代码中就需要处理多个
1 2 3 4 5 6 7 Map<String, Aggregation> asMap = aggregations1.getAsMap();Aggregation terms = asMap.get("search_terms" );String name = terms.getName();String type = terms.getType();
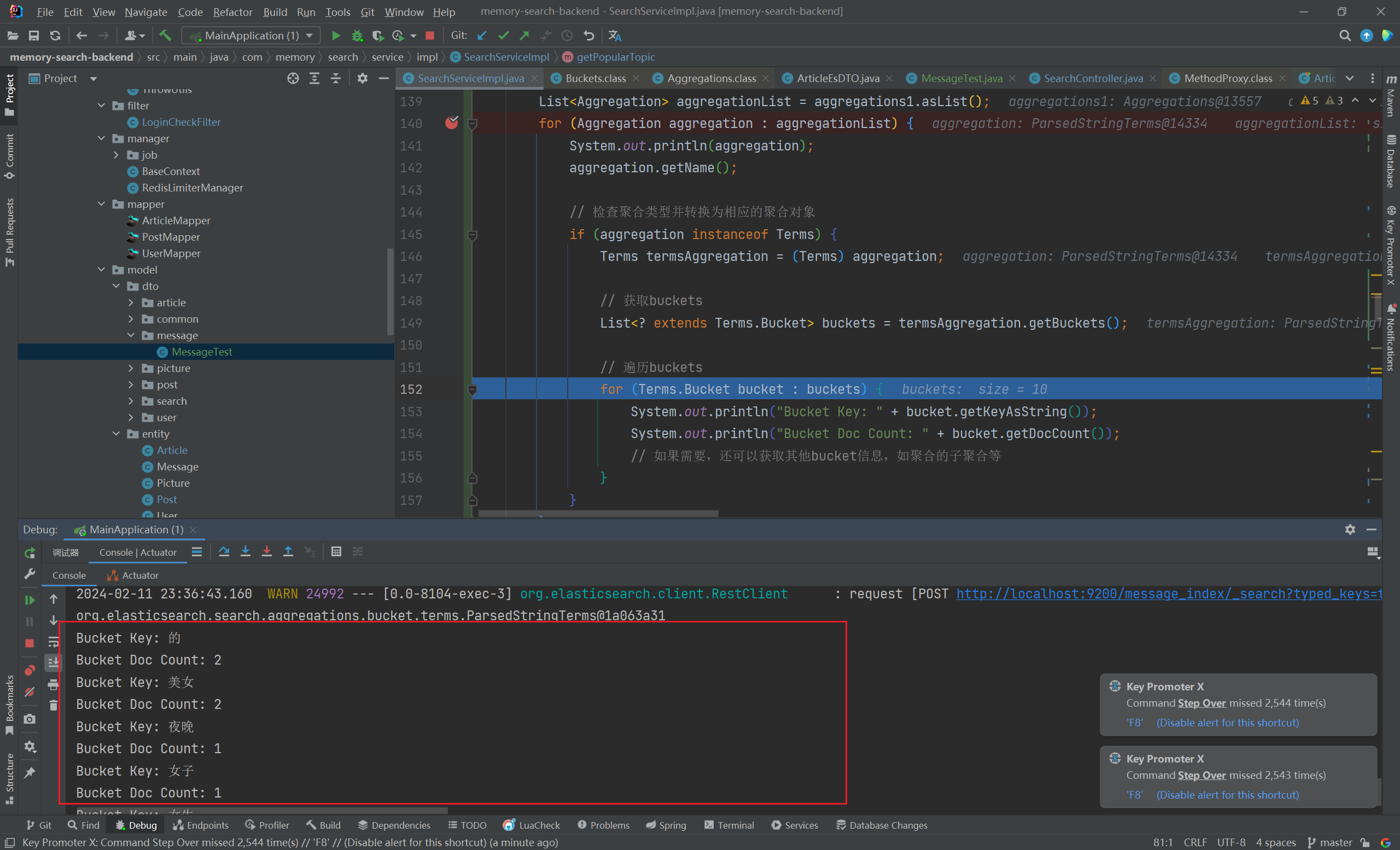
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 TermsAggregationBuilder search_terms = AggregationBuilders.terms("search_terms" ).field("message" ).size(10 );NativeSearchQuery searchQuery = new NativeSearchQueryBuilder ()ElasticsearchAggregations searchHitsAggregations = (ElasticsearchAggregations) searchHits.getAggregations();Aggregations aggregations = Objects.requireNonNull(searchHitsAggregations).aggregations();for (Aggregation aggregation : aggregationList) {if (aggregation instanceof Terms) {Terms termsAggregation = (Terms) aggregation;extends Terms .Bucket> buckets = termsAggregation.getBuckets();for (Terms.Bucket bucket : buckets) {"Bucket Key: " + bucket.getKeyAsString());"Bucket Doc Count: " + bucket.getDocCount());
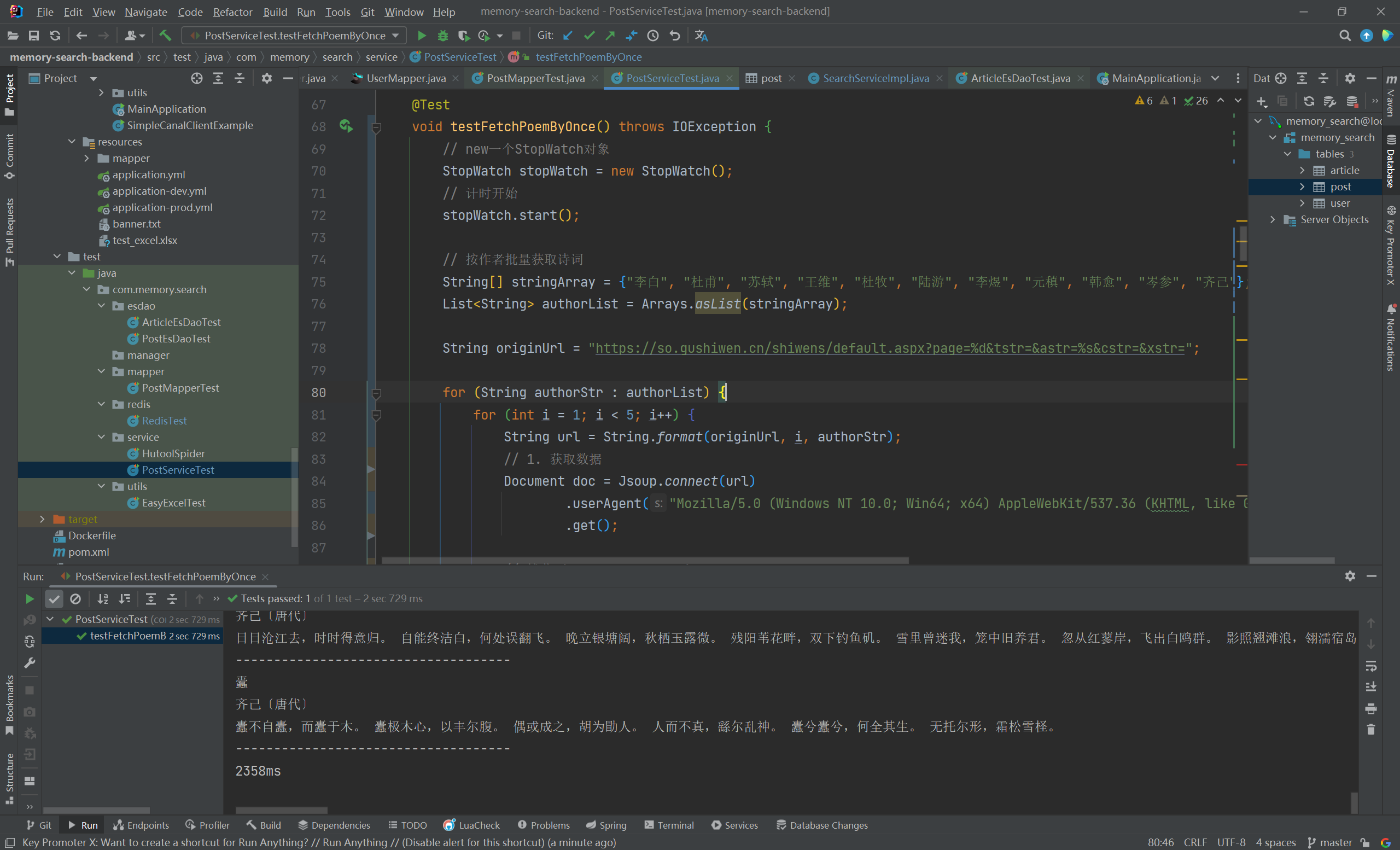
诗词抓取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 @Test void testFetchPoemByOnce () throws IOException {StopWatch stopWatch = new StopWatch ();"李白" , "杜甫" , "苏轼" , "王维" , "杜牧" , "陆游" , "李煜" , "元稹" , "韩愈" , "岑参" , "齐己" };String originUrl = "https://so.gushiwen.cn/shiwens/default.aspx?page=%d&tstr=&astr=%s&cstr=&xstr=" ;for (String authorStr : authorList) {for (int i = 1 ; i < 5 ; i++) {String url = String.format(originUrl, i, authorStr);Document doc = Jsoup.connect(url)"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81" )Element leftZhankai = doc.getElementById("leftZhankai" );Elements heads = leftZhankai.select(".sons .cont div:nth-of-type(2)" );new ArrayList <>();for (Element head : heads) {Post post = new Post ();String title = head.select(">p:nth-of-type(1)" ).text();String author = head.select(">p:nth-of-type(2)" ).text();String content = head.select(".contson" ).text();"------------------------------------" );boolean saveBatch = postService.saveBatch(postList);"批量插入诗词失败" );"ms" );
1993 ms,2066ms,2847ms,2211ms,2459ms
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 @Test public void testFetchPoemByCompletable () {StopWatch stopWatch = new StopWatch ();"李白" , "杜甫" , "苏轼" , "王维" , "杜牧" , "陆游" , "李煜" , "元稹" , "韩愈" , "岑参" , "齐己" };String originUrl = "https://so.gushiwen.cn/shiwens/default.aspx?page=%d&tstr=&astr=%s&cstr=&xstr=" ;ExecutorService executorService = Executors.newFixedThreadPool(5 );new ArrayList <>();for (String authorStr : authorList) {for (int i = 1 ; i < 5 ; i++) {String url = String.format(originUrl, i, authorStr);try {Document doc = Jsoup.connect(url)"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81" )Element leftZhankai = doc.getElementById("leftZhankai" );Elements heads = leftZhankai.select(".sons .cont div:nth-of-type(2)" );new ArrayList <>();for (Element head : heads) {Post post = new Post ();String title = head.select(">p:nth-of-type(1)" ).text();String author = head.select(">p:nth-of-type(2)" ).text();String content = head.select(".contson" ).text();"------------------------------------" );boolean saveBatch = postService.saveBatch(postList);"批量插入诗词失败" );catch (IOException e) {throw new RuntimeException (e);new CompletableFuture [0 ])).join();"ms" );
1445ms,1265ms,1400ms,1199ms,1312ms
按作者批量获取诗词,二十四个作者,每位作者四页,每页 10 首,批量插入诗词记录到数据库(题目,作者,内容)
普通批量插入:4168ms ,异步编程批量插入:1719ms
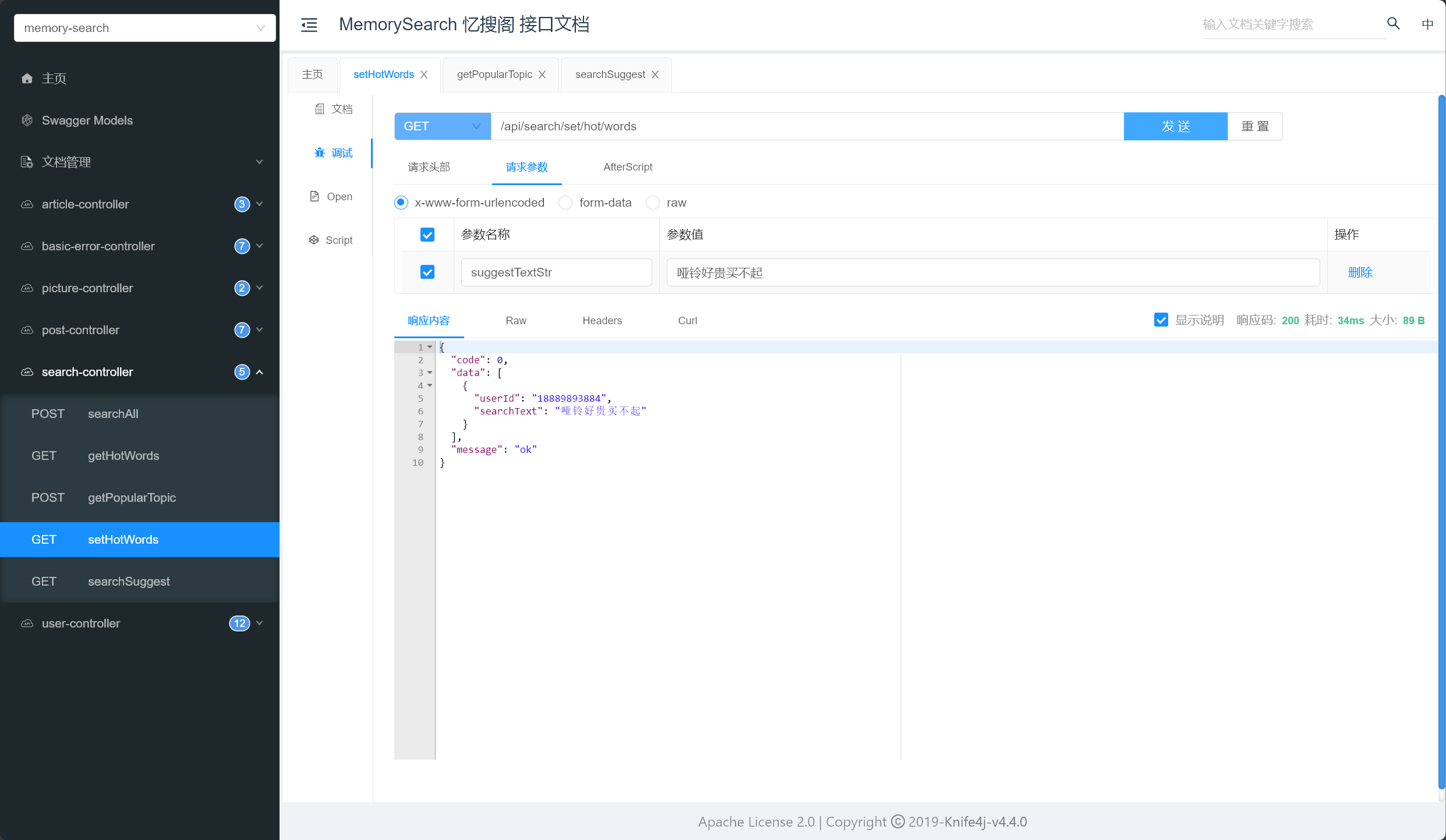
搜索词建议 优化热门搜索统计 :
1 2 3 4 5 6 const res = await SearchControllerService .setHotWordsUsingGet (searchText).then ((res ) => {console .log (res.data );
执行搜索,同步存放搜索词到 Elasticsearch 索引中:
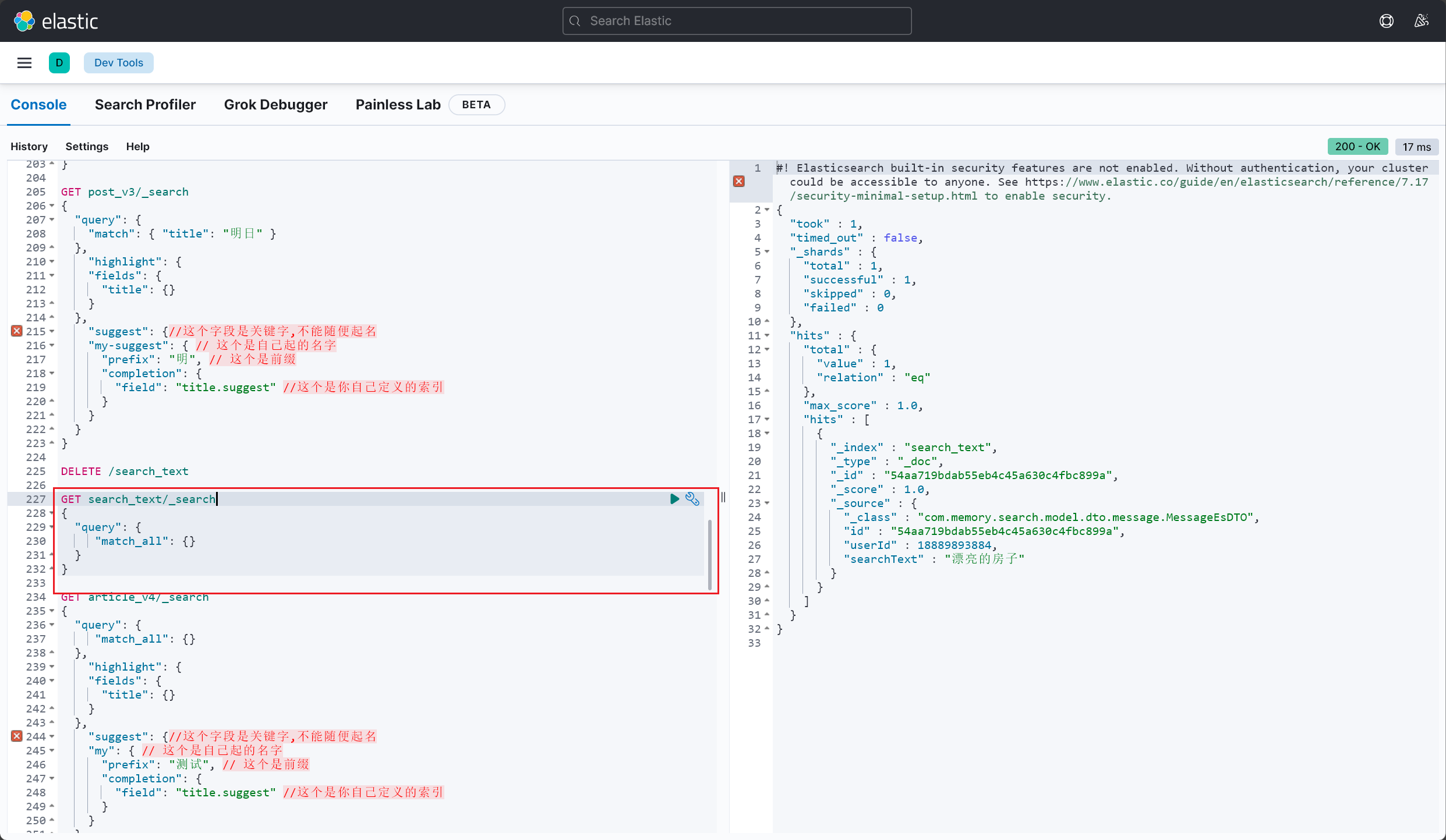
1 2 3 4 5 6 7 8 9 MessageEsDTO messageEsDTO = new MessageEsDTO ();String uniqueId = getUniqueId(searchText);MessageEsDTO save = elasticsearchRestTemplate.save(messageEsDTO);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Document(indexName = "search_text") @Data public class MessageEsDTO {@Id private String id;private Long userId;private String searchText;
根据搜索词内容,使用 MD5 摘要算法 生成唯一 id,同步保存数据到 Elasticsearch 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private String getUniqueId (String searchText) {try {MessageDigest md = MessageDigest.getInstance("MD5" );byte [] hashBytes = md.digest(searchText.getBytes());StringBuilder hexString = new StringBuilder ();for (byte b : hashBytes) {String hex = Integer.toHexString(0xff & b);if (hex.length() == 1 ) hexString.append('0' );return hexString.toString();catch (NoSuchAlgorithmException e) {throw new RuntimeException (e);
效果如下,Elasticsearch 索引中仅保存搜索词条,无需关注词条被搜索次数
新增搜索词索引,searchText 字段添加 suggest 属性,支持前缀搜索建议 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 PUT /search_text"mappings" : {"properties" : {"id" : {"type" : "text" ,"fields" : {"keyword" : {"type" : "keyword" ,"ignore_above" : 256"searchText" : {"type" : "text" ,"fields" : {"keyword" : {"type" : "keyword" ,"ignore_above" : 256"suggest" : {"type" : "completion" ,"analyzer" : "ik_max_word" ,"preserve_separators" : true ,"preserve_position_increments" : true ,"max_input_length" : 50"analyzer" : "ik_max_word" ,"search_analyzer" : "ik_smart" "userId" : {"type" : "long"
执行搜索,保存搜索词条到 Elasticsearch 索引中:
1 2 3 4 5 6 7 8 9 MessageEsDTO messageEsDTO = new MessageEsDTO ();String uniqueId = getUniqueId(searchText);MessageEsDTO save = elasticsearchRestTemplate.save(messageEsDTO);
根据搜索词条,从历史搜索词条中返回搜索建议(可优化,从热门词条中返回搜索建议):
1 2 3 4 5 6 7 8 9 10 11 SuggestBuilder suggestBuilder = new SuggestBuilder ()"suggestionTitle" , new CompletionSuggestionBuilder ("searchText.suggest" ).skipDuplicates(true ).size(5 ).prefix(suggestText));NativeSearchQuery searchQuery = new NativeSearchQueryBuilder ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 new ArrayList <>();Suggest suggest = searchHits.getSuggest();if (suggest != null ) {extends Suggest .Suggestion.Entry<? extends Suggest .Suggestion.Entry.Option>> termSuggestion = suggest.getSuggestion("suggestionTitle" );for (Suggest.Suggestion.Entry<? extends Suggest .Suggestion.Entry.Option> entry : termSuggestion.getEntries()) {for (Suggest.Suggestion.Entry.Option option : entry.getOptions()) {if (option != null ) {String text = option.getText();
文章爬取 妈的,标题还有带表情的:
亮点 设计模式:适配器模式,注册器模式,门面模式
数据抓取:
爬虫获取外部资源,爬取图片、视频,异步处理 耗时请求
定时任务:定时 同步(爬取)外部文章资源
诗词抓取:异步编程,按作者批量获取诗词,二十四个作者,每位作者四页,每页 10 首,批量插入诗词记录到数据库(题目,作者,内容)
文章爬取:
图片爬取:
数据同步方式:
自主编码实现 MySQL -> ES 数据同步;现成中间件:
Logstash 数据同步管道,配置输入输出源;
Canal + MQ 实现监听数据库流水(设想)
Elastic Stack 技术栈:
ES 和 MySQL 的比较,ES 的概念,要解决的问题
DSL 语法:简单索引的增删改,文档的增删改,复合查询、全文搜索、term 查询、聚合查询、布尔查询,搜索建议词、关键词
分词器:内置分词器、IK 分词器
Java 操作 ES:ES 官方提供 API、Spring Data Elasticsearch
Logstash 数据同步管道:配置输入输出源,同步 MySQL -> ES 的数据
Kibana 数据看板:搭建数据看板,数据分析
ES 实现搜索词条建议、关键词语高亮、热门搜索统计、热门话题分析
Redis:
用户:
sessionId / ThreadLocal 保存登录用户信息
1 用户会话管理:在Web应用中,为了跟踪用户的会话信息,通常会将用户会话数据存储在HttpSession对象中。然而,由于每个请求可能由不同的线程处理,直接使用HttpSession会导致线程安全问题。使用ThreadLocal可以将用户会话数据存储在每个线程中,确保每个线程都能独立地访问用户会话数据。
使用 Markdown 编辑器发布文章,交由审核
单设备登录限制
权限校验:
前端,校验是否登录;根据用户身份,限制普通用户访问页面
后端:全局过滤器,限制页面访问权限,校验登录
Spring AOP + 自定义注解,实现全局请求响应拦截和权限校验
高流量:如何抵御大量搜索请求,保证数据记录正确
缓存:保留近期内的搜索数据(图片,视频),保存 24 小时
限流:四大限流算法,简单限流、滑动窗口限流、漏桶限流、令牌桶限流
降级:
并发编程:对于耗时请求,异步处理:从外源搜索图片、视频
Spring:
Spring AOP + 自定义注解,实现全局请求响应拦截和权限校验
多环境配置:配置 开发环境、生产环境,方便项目开发、测试、部署上线
其他:
接口文档、Markdown 文档编辑器
思考: 如何分析文章热度? Elasticseach 数据存储在硬盘内,如何选择合适的删除策略,清理过期数据呢 Elasticsearch 一个索引内可以存放的数据条数并没有固定的上限,它主要取决于以下几个因素:
磁盘空间 :索引的大小受限于可用磁盘空间。Elasticsearch 会将索引数据存储在磁盘上,因此磁盘空间是限制索引大小的主要因素。分片配置 :Elasticsearch 通过分片(shards)来水平扩展数据,每个索引可以包含一个或多个分片。默认情况下,一个索引会有 5 个主分片(primary shards),但可以在创建索引时指定不同的分片数。分片数越多,索引可以容纳的数据量就越大,但同时也会增加集群的管理复杂性。文档大小 :单个文档的大小也会影响索引的容量。虽然 Elasticsearch 支持非常大的文档,但过大的文档可能会降低写入性能并增加索引的存储需求。
当索引达到其存储限制时,Elasticsearch 不会直接拒绝新的数据写入。相反,它会根据配置的策略来处理这种情况。常见的删除策略包括:
基于时间的删除 :使用索引生命周期管理(ILM)策略,根据时间戳字段自动删除旧数据。例如,可以设置一个策略,使得索引在创建后的一定时间后被删除。基于大小的删除 :当索引达到一定的大小时,可以配置 ILM 策略来删除旧数据,或者通过手动干预来删除不需要的数据。基于文档数量的删除 :虽然 Elasticsearch 不直接基于文档数量限制索引大小,但可以通过删除旧文档来管理索引的大小。这可以通过编写删除查询或使用 ILM 策略来实现。滚动索引 :在某些场景中,可以使用滚动索引(rolling indices)模式,即定期创建新的索引来存储新数据,而旧索引可以被删除或归档。这种策略常见于日志收集和分析场景。
在实际应用中,建议根据业务需求和数据特点来选择合适的删除策略。同时,监控 Elasticsearch 集群的健康状况和性能,确保数据的有效管理和系统的稳定运行。
Elasticsearch 默认不提供自动删除旧数据的策略。默认情况下,索引会一直存在,直到你手动删除它们或者磁盘空间耗尽。但是,Elasticsearch 提供了索引生命周期管理(ILM)功能,允许你定义自己的删除策略。
当你创建一个索引时,除非你明确指定了 ILM 策略,否则该索引不会受到任何自动删除策略的影响。这意味着你需要主动管理索引的生命周期,包括决定何时删除不再需要的索引。
在 ILM 中,你可以定义策略来根据索引的年龄、大小或其他条件自动将索引移动到只读状态,并最终删除它们。但是,如果你不配置 ILM 或使用默认的 ILM 策略,索引将不会自动被删除。
因此,为了有效地管理 Elasticsearch 中的索引和数据,建议配置适当的 ILM 策略,以确保旧数据在不再需要时被自动删除,从而释放磁盘空间并优化集群性能。
如何确保 Elasticsearch 文档的 id 唯一性? 在 Elasticsearch 中记录搜索词,每条搜索词作为一个文档,保证数据 ID 的唯一性是非常重要的。Elasticsearch 使用文档 ID 来唯一标识每个文档,因此你需要确保每个搜索词都被分配一个唯一的 ID。以下是一些方法来实现这一点:
使用 UUID :
1 2 3 4 import java.util.UUID;String uniqueId = UUID.randomUUID().toString();
基于时间戳和搜索词生成 ID :
1 2 3 4 5 6 import java.time.Instant;String timestamp = Instant.now().toString().replace("-" , "" ); String searchTerm = "你的搜索词" ;String uniqueId = "search-" + timestamp + "-" + searchTerm;
使用自增 ID :
1 2 3 AtomicInteger counter = new AtomicInteger (0 );String uniqueId = "search-" + counter.getAndIncrement();
使用哈希函数 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.security.MessageDigest;import java.security.NoSuchAlgorithmException;String searchTerm = "你的搜索词" ;try {MessageDigest md = MessageDigest.getInstance("MD5" );byte [] hashBytes = md.digest(searchTerm.getBytes());StringBuilder hexString = new StringBuilder ();for (byte b : hashBytes) {String hex = Integer.toHexString(0xff & b);if (hex.length() == 1 ) hexString.append('0' );String uniqueId = hexString.toString();catch (NoSuchAlgorithmException e) {
无论你选择哪种方法,都需要确保生成的 ID 在整个 Elasticsearch 集群中是唯一的。如果你使用了多节点集群,并且需要在不同节点之间保证 ID 的唯一性,那么使用 UUID 或基于时间戳和搜索词的方法通常是更好的选择。
总结 踩坑记录 1 2 3 4 5 6 7 8 @Override public Page<User> listUserVOByPage (UserQueryRequest userQueryRequest, HttpServletRequest request) {long pageSize = userQueryRequest.getPageSize();long current = userQueryRequest.getCurrent();return this .page(new Page <>(pageSize, current),this .getQueryWrapper(userQueryRequest));
Page 对象的 pageSize 和 currentPage 写反了,拿取第 1 页、共 10 条数据,结果变成了第 10 页,共 1 条。(2023/08/31 午)
搜索词条不兼容中文 1 2 3 4 if (StringUtils.isNotBlank(searchText)) {"UTF-8" );String url = String.format("https://cn.bing.com/images/search?q=%s&first=%s" , searchText, current);
适配器模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 @Resource private UserDataSource userDataSource;@Resource private PostDataSource postDataSource;@Resource private PictureDataSource pictureDataSource;@Override public SearchVO searchAll (SearchQueryRequest searchQueryRequest, HttpServletRequest request) {String type = searchQueryRequest.getType();SearchTypeEnum enumByValue = SearchTypeEnum.getEnumByValue(type);String searchText = searchQueryRequest.getSearchText();long pageSize = searchQueryRequest.getPageSize();long current = searchQueryRequest.getCurrent();SearchVO searchVO = null ;if (enumByValue == null ) {return postDataSource.search(searchText, pageSize, current);return userDataSource.search(searchText, pageSize, current);try {return pictureDataSource.search(searchText,pageSize,current);catch (IOException e) {throw new RuntimeException (e);try {new SearchVO ();catch (InterruptedException e) {throw new RuntimeException (e);catch (ExecutionException e) {throw new RuntimeException (e);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 else {new SearchVO ();switch (enumByValue) {case POST:PostQueryRequest postQueryRequest = new PostQueryRequest ();case USER:UserQueryRequest userQueryRequest = new UserQueryRequest ();case PICTURE:null ;try {catch (IOException e) {throw new RuntimeException (e);finally {
1 2 3 4 5 6 7 8 9 10 11 12 else {new SearchVO ();try {catch (IOException e) {throw new RuntimeException (e);return searchVO;
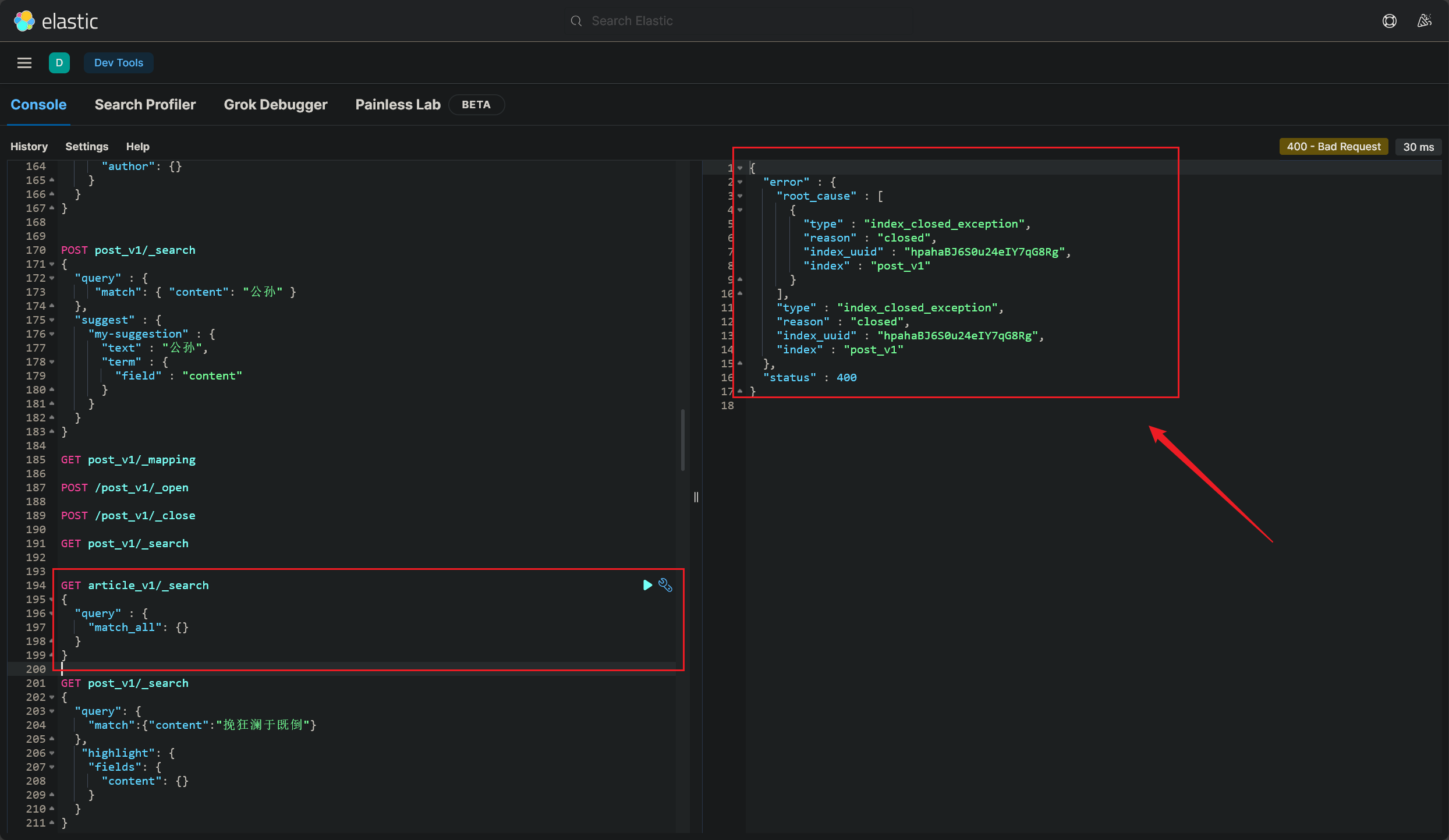
索引关闭
本来好好的,突然就这样了,这索引记录也没删呢(2023/12/03 晚)
Elasticsearch 中的索引可以被关闭,这是为了优化性能和资源使用。一旦索引被关闭,就不能再对其进行写入操作,但仍然可以进行读取操作。如果你试图对一个已关闭的索引进行写入操作,就会遇到 “index_closed_exception” 错误。
解决方案:重新打开你的索引。你可以使用以下命令重新打开一个索引:
这样就正常查询了,同样的,也可以关闭索引:(2023/12/03 晚)
TODO