砺剑出鞘:我的软件工程师求职之旅
本文最后更新于:2 个月前
写在前面
2024 年 3 月 7 日
三月份了,春招在即,我也开始着手准备今年下半年的秋招了。
现阶段的目标是能在短期内找到一份日常实习,再持续投递中大厂的暑期实习岗位。
这注定是一场持久战,从现阶段开始到接下来的九个月里,我不能有丝毫懈怠。
那么,简单记录下我的求职经历吧!
正文
求职经历
2 月 19 日,了解计算机四级网络工程师考点考纲,基本完成项目网站首页,记忆 MySQL 相关八股文,计划开始优化简历。
大三下还打算窝在学校上课,是等着毕业就失业吗?
2 月 20 日,系统分析项目核心功能,优化简历“专业技能”一栏,现阶段第一版简历完成,目标更加清晰;巩固 Spring 相关八股文。
2 月 21 日,着手梳理 Memory API 忆汇廊核心功能;想家了,有感而发,写点生活感悟。
2 月 22 日,着手配置 Canal 监听 MySQL 数据库流水;巩固蓝桥杯考点考纲,了解蓝桥杯算法,做好备考;持续完善项目文档以及 Gitee / GitHub 仓库介绍。
2 月 23 日,记忆 Java、JVM 相关八股文;下午跟小穆聊天,唠家常,唠理想;梳理项目核心功能;尝试 Spring Cloud Gateway 限流。
晚风几许撩人意,夕阳半刻醉人心
2 月 24 日,完善项目架构设计,思考项目优化点和扩展点;梳理项目核心功能,持续优化项目文档以及 Gitee / GitHub 仓库介绍;掘金学习热榜文章:自定义 Starter、MySQL 日志、事务相关知识;计划开始持续输出文章,记录生活;晚点时候,拿到电信流量卡并成功激活。
强者,从来不会抱怨环境。我他妈就是强者
2 月 25 日,简单的早间点滴;第一次来餐厅自习;完善计算机网络八股,开始阅读《HTTP 四十讲》;着手购买充电宝、便携式桌椅,为面试做准备。
没有什么光阴真正被虚度,也没有任何事情是徒劳无功的
2 月 26 日,在牛客、BOSS、实习僧等了解行情;持续学习计算机网络;基本完成项目文档编写,完善 SDK Gitee 项目介绍;阅读《孙子兵法》《朝花夕拾》。
知识改变年薪,文化改变命运
2 月 27 日,六级三战失败,血压暂时升高;优化简历“专业技能”一栏,添加设计模式、个人优势等内容;一次性完善“项目经历”一栏内容,简历第二版优化完成;持续巩固计算机网络和 Redsi;过牛客链表算法题;计划明天彻底完善简历,打点校园内的面试环境。
截至二零二四年二月二十七日,下午四时四十五分,我的个人博客共有七十余篇博文,总计九百余张图片、五十余万文字
2 月 28 日,快速记忆 Java 基础、Spring 常考面试题;完善实习僧平台信息;基本完善项目文档,优化简历;成功投递第一波简历。
2 月 29 日,持续巩固学习 MySQL、Redis、并发编程、集合等八股;持续投递本地日常实习;沟通几十个、简历几份,到目前为止还没有回应;学习 RPC、网关等微服务架构知识,系统梳理。
3 月 1 日,远程帮助小伙伴完善项目,持续学习微服务架构;终于有人要我简历了,很期待;桌子,椅子,超大容量充电宝都回来了;写点故事;
3 月 2 日,跑步半小时,连续三天在 BOSS 打招呼,计划找个本地实习,但基本已读不回;做京东笔试题;学习链表算法题;头疼,下午补觉;植物大战僵尸汉化版,休息。
3 月 3 日, BOSS 求职回复寥寥无几,心情越发浮躁;晚上读书,计划明天投递第四波简历。
3 月 4 日,学习 Java 并发编程,学习记录 JVM;谈谈我对微服务架构的理解;下午实习僧一键投递,很快啊,投了五十多份简历;实习僧收到一份七号中午的笔试邀请。
3 月 5 日,继续学习 JVM;前两次要简历的都抱歉了;BOSS 有回复,要求 Java 实习转 GO,无薪资,没有后续;学习 Maven 项目管理工具;计划明天开始投递中大厂,基本放弃本地实习机会。
xxxxxxxxxx npm list -g –depth 0 查看全局安装过的模块 npm init 生成 package.json 文件(需要手动选择配置)npm init -y 生成 package.json 文件(使用默认配置)npm i/install 一键安装 package.json 下的依赖包 npm i xxx 在项目中安装包名为 xxx 的依赖包(配置在 dependencies 下)npm i xxx –save 在项目中安装包名为 xxx 的依赖包(配置在 dependencies 下)npm install xxx@latest 更新包的版本至最新 npm i xxx –save-dev 在项目中安装包名为 xxx 的依赖包(配置在 devDependencies 下)npm i -g xxx 全局安装包名为 xxx 的依 2 赖包 npm update -g xxx 更新全局安装的包 npm uninstall -g xxx 卸载全局安装的包 npm run xxx 运行 package.json 中 scripts 下的命令 npm home xxx 打开 xxx 包的主页 npm repo xxx 打开 xxx 包的代码仓库 npm publish 将当前模块发布到 npmjs.com,需要先登录 bash
3 月 7 日,计划投递腾讯实习岗位,完善作品集;开设新博文,记录我的求职经历;完成始祖象的笔试;完成携程招聘笔试题,笔试题还挺有意思;同尹老师交流,介绍了个学长,下午吃饭前给学长投了份简历;中午投递 BOSS,约了下周一的线下面试;学习计算机网络。
3 月 8 日,写日记,好久没写日记了;上午尝试投递 BOSS,又有位 BOSS 肯理我了,现在还没有实习岗位,把我简历要过去了。一周之内如果有实习岗位,就会有答复;下午四点腾讯会议面试,第一次面试,时长三十五分钟,问得比较简单,就是没啥经验,话到嘴边表达不清楚的感觉,还得继续努力呵;始祖象算法工程师岗位又发来笔试邀请了,15 号的笔试;根据京东大佬指点意见,优化简历。
3 月 9 日,面向面经复习;简历优化,内容更加精炼;写会儿大学故事;在安居乐租房软件上了解租房动态,上 B 站了解租房注意事项;下午继续 BOSS 投递,又成功投出去一份简历;跟小穆聊天,分享求职进展;晚上面向面经,查缺补漏。
3 月 10 日,跑步,半小时;备考计算机四级网络工程师,找到完备题库,计算机四级稳了;面向面经复习;调试鱼聪明,竟然还要再充会员嘛;中午投递一波简历,又有一份回应;性能优化,Spring Boot 自动装配原理;豚鼠系列《下水道的美人鱼》;回忆大学中的每个假期;API 项目介绍,看相关面经。
3 月 11 日,投递简历,BOSS 询问进展状况;询问学长进展状况;投递各大官网;做腾讯、快手测评;洛阳寰宇网阔科技公司,人事刘先生,态度蛮不错的。事事有回音,不招在校生,还祝我前程似锦。跟导员沟通离校实习,她说不行。。果然导员没啥用。。投递百度实习生岗位;续写《该死的万柏林区》;看《雪山迷踪》;找回状态,高效巩固复习。
3 月 12 日,更新 BOSS 招呼语;跑步半小时;巩固线程池,ThreadLocal,Redis;持续投递 BOSS 平台;面经是永远背不完的!自备战日常实习以来,直到今晚我才能彻底理解这句话;了解学习 Docker 部署。
3 月 13 日,蓝桥杯真题是真看不懂,这跟代码有什么关系,全是数学题。。持续投递 BOSS 平台,太原附近完全没有实习生招生计划吗?系统学习 Elasticsearch 实现原理;拿到蓝桥杯的相关备考资料;牛客网投递了一波暑期实习招聘:五八同城、OPPO、阿里;一周前实习僧海投的岗位回应我了,上海,无兴趣;《地球脉动》。
3 月 14 日,跟太原本地初创公司交流;约了明天和后天的两个面试;再次迭代简历,添加中间件掌握情况;最后一次全面巩固复习面经,为明天的面试做准备。
自八月初优化好最新一版简历后,开始陆陆续续投递。
实训生活第三周,8 月 20 日,从上周周五即 8 月 16 日开始,每天坚持投递简历。
投递
2024 年 8 月 20 日
每次投递简历,总要一遍遍复制粘贴我的项目和实习经历介绍,真是太麻烦了,我直接粘贴在这里:
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
9 月 6 号,苏州大宇宙面试通过,通知随去时实习,暂不考虑;晚做挚友笔试;优化新版简历。
南京
2025 年 2 月 19 日
已经结束了。
还有三个月左右的时间。
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
权且当作是黄粱一梦。
继续生活。
2025 年 2 月 21 日
我希望只是预热,最好不要让我面临这样的结果。
| 项目列表 |
|---|
| 调度运行指挥自主巡航(DCS) |
| 中核运维合同项目 |
| 中卫大数据 |
| 合江智能辅控综合监控主站 |
| 华电竞争报价系统项目 |
| 金风三峡智能运检系统 |
| 山东智能巡检 |
| 新疆苇湖梁场站智能巡检系统 |
| 广东电网 2025 年大运会智慧保电指挥系统 |
| 智能操作票(DCCS) |
2025 年 2 月 24 日
周末已经过去了,还没想好后路。
2025 年 4 月 9 日
开发经验,网络协议,Nginx,JVM,AI
1 | |
2025 年 4 月 22 日
1 | |
2025 年 8 月 20 日
Spring Security,Sa-Token,JWT,Mybatis,Nginx,Websocket(即时通讯,实时更新,在线游戏,协同编辑),SSE(了解)。
Caffeine 本地缓存,Redis 分布式缓存,ShardingSphere 分库分表(了解),RabbitMQ。
2025 年 8 月 21 日
springboot3整合SpringSecurity实现登录校验与权限认证(万字超详细讲解)_springboot security-CSDN博客
mybatis看这一篇就够了,简单全面一发入魂_mybatis一发入魂-CSDN博客
Mybatis Plus 看这篇就够了,通俗易懂,一发入魂_com.baomidou.mybatisplus.core.mybatismapperannotat-CSDN博客
[Spring Boot 实战开发](https://learn.lianglianglee.com/专栏/Spring Boot 实战开发)
2025 年 8 月 29 日
问题1:在MryAPI开放平台项目中,你提到使用了Spring Cloud Gateway进行流量染色,请详细描述一下流量染色的具体应用场景以及你是如何实现的?
面试思路:考察候选人对流量染色技术的理解和实际应用能力。流量染色在灰度发布、AB测试等场景中非常重要,通过这个问题可以评估候选人是否真正掌握了这项技术,并能将其应用到实际项目中。
面试话术:在MryAPI开放平台中,我们主要使用流量染色来实现灰度发布。例如,当我们上线一个新版本的接口时,我们不希望所有用户都立即访问到新版本,而是希望先让一部分用户(例如内部测试用户或特定地区的少量用户)先体验新版本,观察是否有问题。通过流量染色,我们可以给这部分用户的请求打上特定的标记(例如header中添加一个特定的key-value),然后在Gateway中配置路由规则,将带有这个标记的请求转发到新版本的接口服务,而其他用户的请求仍然转发到旧版本的接口服务。具体实现上,我们使用了Gateway的Predicate和Filter机制,自定义了Predicate来匹配带有特定标记的请求,然后使用Filter来修改路由规则,将请求转发到指定的upstream。这样,我们就可以实现对特定流量的精确控制,从而实现平滑的灰度发布。
问题2:你提到为防止接口被恶意调用,设计了API签名认证算法,并为用户分配了唯一的ak/sk进行鉴权。请详细描述一下你的API签名认证算法的具体流程,以及你是如何保证ak/sk的安全性的?
面试思路:考察候选人在API安全方面的知识和实践经验。API签名认证是保障接口安全的重要手段,通过这个问题可以评估候选人是否了解常见的签名算法,以及如何防止ak/sk泄露和被滥用。
面试话术:我们的API签名认证算法流程如下:首先,客户端在发起API请求时,需要将请求参数按照一定的规则进行排序(例如按照参数名的字典序),然后将排序后的参数和请求体拼接成一个字符串。接着,使用HMAC-SHA256算法,以用户的sk作为密钥,对拼接后的字符串进行加密,生成签名。最后,将ak、签名和时间戳等信息放在请求头中发送给服务端。服务端收到请求后,首先根据ak找到对应的sk,然后使用相同的算法对请求参数进行签名,并与客户端传递过来的签名进行比对。如果签名一致,则认为请求是合法的。为了保证ak/sk的安全性,我们采取了以下措施:1. sk只在用户创建时显示一次,之后不再明文存储,而是存储其哈希值。2. 在数据库中对ak/sk进行加密存储。3. 限制ak/sk的使用频率,防止暴力破解。4. 定期轮换ak/sk。5. 监控API调用日志,及时发现异常请求。
问题3:你提到使用OpenFeign抽取优化公共服务,实现了网关模块轻量化和服务解耦。请详细描述一下你具体抽取了哪些公共服务?以及在抽取过程中遇到了哪些挑战,你是如何解决的?
面试思路:考察候选人对微服务架构的理解和实践能力,以及解决问题的能力。通过这个问题可以评估候选人是否能够合理地进行服务拆分和解耦,并能够应对抽取过程中可能遇到的各种问题。
面试话术:我们主要抽取了以下公共服务:1. 接口校验服务:负责对请求参数进行校验,例如校验参数类型、长度、格式等。2. 用户鉴权服务:负责验证用户的身份和权限,判断用户是否有权限调用该接口。3. 流量统计服务:负责统计接口的调用次数、响应时间等指标。在抽取过程中,我们主要遇到了以下挑战:1. 如何保证抽取后的服务性能:由于抽取后的服务需要通过网络调用,因此会增加额外的延迟。为了解决这个问题,我们使用了缓存技术,将一些常用的数据缓存在本地,减少对远程服务的调用。2. 如何保证数据的一致性:由于抽取后的服务涉及到多个服务之间的数据交互,因此需要保证数据的一致性。为了解决这个问题,我们使用了分布式事务,保证在多个服务之间的数据操作要么全部成功,要么全部失败。3. 如何处理服务之间的依赖关系:由于抽取后的服务之间存在依赖关系,因此需要合理地管理这些依赖关系。为了解决这个问题,我们使用了服务注册与发现机制,让服务能够动态地发现和调用其他服务。
对照
2025 年 9 月 1 日
你是如何基于 BitMap 实现用户年度刷题记录统计的?又如何进一步优化该接口性能? - 面试鸭 - 程序员求职面试刷题神器
招呼语
2025 年 4 月 21 日
1 | |
1 | |
1 | |
1 | |
2025 年 7 月 29 日
跨域。
解决跨域问题的本质,是往响应头里塞几个字段,即:
1 | |
因此,只要能够改写响应头的地方都可以解决跨域问题,所以市面上才会出现那么多解决跨域的方式:
- 使用
@CrossOrigin注解解决跨域问题; - 实现
WebMvcConfigurer接口解决跨域问题; - 通过自定义
Filter过滤器解决跨域问题; - 通过
Response对象实现跨域问题; - 通过实现
ResponseBodyAdvice接口解决跨域问题; - 通过设置Nginx配置解决跨域问题;
- ……
这么多种跨域解决方案听起来很唬人,但只要是服务端解决的跨域问题,殊途同归都是改写响应头罢了。
接口安全性设计。
(十二)漫谈分布式之接口设计上篇:写出一个优秀的接口我们需要考虑什么?作为一名后端开发,你会写接口吗?有人说你这不废话吗 - 掘金
2025 年 9 月 2 日
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
南京泰豪
2025 年 9 月 14 日
当然,这是一个非常详细的、基于你项目经验的“参考答案库”。你可以根据自己的实际理解进行微调,使其成为你自己的答案。
一、 关于“软件许可证管理系统”的回答思路
1. 基础原理
Q: 简单讲一下TrueLicense的工作原理和流程?
A: TrueLicense是一个基于非对称加密和数字签名的库。它的核心流程分为三部分:
- 生成证书(服务端):我们使用
keytool生成一对非对称加密的密钥对(私钥和公钥)。私钥由我们公司严格保密,用于签发许可证。当客户购买产品后,我们系统会调用私钥,将客户信息(如有效期、授权数量、绑定的硬件指纹)打包成一个License文件,并用私钥对其进行数字签名,防止篡改。 - 安装证书(客户端):客户将收到的License文件放置在程序指定目录下。我们的客户端应用启动时,会加载这个文件。
- 验证证书(客户端):客户端程序内置了对应的公钥。它会用这个公钥去验证License文件的数字签名。如果验证通过,说明这个文件确实是我们公司签发的,且未被篡改。然后程序再读取其中的授权信息(如有效期、硬件指纹)进行校验,全部通过后,软件才正常功能。
Q: 为什么选择TrueLicense?和其他开源许可库相比有什么优劣?
A: 当时技术选型时主要考察了TrueLicense和License3j。
- 选择TrueLicense的主要原因是它的生态更成熟,资料相对较多,基于Java标准库的
keytool和密码学体系,稳定可靠。 - TrueLicense的优势在于设计清晰,与Java生态集成度深,功能完善(如证书撤销列表CRL)。
- 它的劣势是配置起来稍显复杂,需要自己处理很多细节。而License3j可能更轻量,但当时评估后认为TrueLicense的功能更满足我们商业级的需求。
Q: 证书里通常包含哪些信息?
A: 除了TrueLicense自带的基本信息(如生效日期、过期日期、被授权人),我们还自定义了一些对我们业务至关重要的信息:
- 功能模块列表:允许客户使用哪些高级功能。
- 最大点数/用户数限制:例如,限制同时在线用户数。
- 唯一的硬件指纹:这是由客户端采集客户服务器的CPU、主板、硬盘等硬件信息生成的一个唯一ID,是防止许可证在不同机器间转移的关键。
2. 安全与设计
Q: “绑定设备硬件”具体是怎么实现的?采集了哪些硬件信息?
A: 我们在客户端使用了一个叫oshi-core的开源库来安全地采集硬件信息。
- 采集的信息:我们主要采集了CPU序列号、主板序列号和主硬盘的序列号。这些信息在单台服务器上具有很高的稳定性。
- 生成指纹:并不是直接使用原始序列号,而是将这些信息拼接后,进行一次MD5或SHA256哈希,生成一个唯一的、不可逆的指纹字符串。这样做既保证了唯一性,也避免暴露客户硬件的原始信息。
Q: 如何防止用户伪造这些硬件信息?
A: 这是一个攻防战,我们做了多层防护:
- 环境变量存储:如简历所说,我们将验证服务器地址等信息保存在容器环境变量中,而不是配置文件里,增加定位和篡改的难度。
- 指纹可靠性:优先选用那些在虚拟化环境中难以修改或修改会导致系统不稳定的信息(如主板序列号)。
- 校验逻辑混淆:将证书验证的代码进行一定程度的混淆和加固,增加破解者逆向分析的难度。
- 服务器端记录:每次验证请求(尤其是证书安装时)我们服务端会记录IP、硬件指纹等信息。如果发现同一个许可证对应的指纹频繁变化,会触发风控警报,人工介入调查。绝对的安全不存在,但我们的目标是大大提高伪造的成本和风险。
Q: 客户端是如何“定期校验”证书有效性的?
A: 我们采用了一种启动时全量校验 + 运行中间隔定时校验的策略。
- 客户端应用每次启动时,都会进行一次完整的证书验证(签名、有效期、硬件绑定)。
- 启动后,我们启动一个后台的定时任务(Scheduler),例如每24小时执行一次。它会再次检查证书是否即将过期(如提前7天告警)或是否已被服务器端撤销。
- 定时任务会异步地、安静地去我们的许可证服务器查询一个撤销列表(CRL),不会影响用户正常使用。
Q: 证书被撤销后,客户端是如何感知的?
A: 我们采用的是客户端主动查询的机制,因为软件可能部署在内网,服务端无法主动推送。
- 在之前提到的“定期校验”中,定时任务会携带一个凭证,去查询服务端的一个API接口(例如
/api/license/check-revoked)。 - 服务端维护着一个“证书撤销列表”。如果该证书已被列入黑名单,接口会返回一个特定的状态码。
- 客户端收到响应后,就知道证书已失效,会触发过期处理流程,例如弹出警告并限制软件功能。
3. 异常与处理
Q: 如果客户端无法连接到验证服务器,如何处理?
A: 这是关键的设计点,必须保证客户在网络隔离的情况下也能正常使用。
我们设定了优雅降级策略:
- 首次安装:必须能连通服务器,否则无法完成安装激活。
- 定期校验时断网:如果定时任务连接服务器失败,不会立即使证书失效。我们会允许软件继续正常运行,并在日志中记录网络异常。下次校验成功后再同步状态。
- 核心是“信任但验证”:我们相信本地证书的有效性,定期校验只是一个附加的安全措施和对服务器状态的同步。这保证了软件的可用性。
Q: 证书过期后,“自动处理过期状态”具体是怎么做的?
A: 我们会分阶段处理:
- 预警期:在到期前7天,每次启动软件会在日志和控制台提示“许可证即将过期,请续订”。
- 过期后: 软过期:过期后的第一天,软件功能可能不受影响,但每次启动都会弹出强提醒窗口。 硬过期:过期超过一定天数(如3天)后,软件会降级到免费版模式,限制部分高级功能,但保证核心功能可用,给客户一个缓冲时间去处理续费,而不是直接程序崩溃,体验更好。
二、 关于“部署与工程化”的回答思路
Q: 详细讲一下你的“一键远程部署”脚本是如何工作的?
A: 其实这是一个简化版的CI/CD流程,核心是一个Shell脚本。
- 本地构建:在IDEA中执行Maven命令,完成编译、打包,生成一个Docker镜像并打上标签(
myapp:latest)。 - 一键触发:我编写了一个Shell脚本(
deploy.sh)。我在IDEA中点击运行这个脚本,它会:
a. 通过SSH连接到远端的测试/生产服务器。
b. 执行远程命令:docker stop old-container && docker rm old-container(停止并移除旧的容器)。
c. 执行远程命令:docker pull myapp:latest(拉取我刚构建好的最新镜像)。
d. 执行远程命令:docker run -d --name myapp -p 8080:8080 -e LICENSE_SERVER_URL=... ... myapp:latest(以守护进程模式运行新容器,并注入环境变量)。
e. 整个过程通过SSH一次完成,实现了从本地代码到远程服务的快速更新。
Q: Dockerfile里写了哪些关键内容?
A: 我们采用了多阶段构建来优化镜像。
1 | |
Q: 如何强制 @ApiParam(required=true) 生效?
A: 光有Swagger注解是不够的,我们将其与强大的后端校验结合:
- 在Controller参数上,我们使用Spring的
@Validated注解来启用校验。 - 在DTO字段上,我们使用
@NotBlank、@NotNull、@Size等JSR 303标准注解。 - 全局异常处理:我们有一个
@ControllerAdvice来捕获MethodArgumentNotValidException异常,然后将其转换为简历中提到的标准化错误响应体({code: 10001, message: "用户名不能为空", data: null})。
这样,@ApiParam(required=true)主要给前端看,生成文档;而@NotBlank是后端真正的守护者。两者结合,确保了可靠性。
三、 项目宏观与软技能问题
Q: 这个项目中你遇到的最大技术挑战是什么?
A: 最大的挑战是设计一个兼具安全性和用户体验的许可证验证机制。
- 安全性与可用性的平衡:如果验证太频繁、太严格,可能会误伤正常客户;如果太宽松,又起不到防盗版作用。例如,如何处理“服务器网络隔离”的情况就是一个难题。
- 我的解决方案:我调研了多种方案,最终采用了“启动强校验 + 定时弱校验”的策略,并设计了离线宽限期。同时,通过硬件绑定和代码混淆来提升破解门槛。这个方案在评审时得到了团队的认可,上线后也未收到因此导致的客户投诉。
Q: 你在其中扮演了什么角色?
A: 我是这个许可证子项目的核心负责人。从技术选型(调研TrueLicense)、方案设计(与项目经理讨论授权规则)、后端API开发、客户端验证模块封装,到最后的部署和文档编写,都是由我主导完成的。期间也和前端同事协作,定义了授权状态码和错误提示信息的规范。
Q: 为什么联调成本会那么高?
A: 之前团队没有统一的规范。主要的痛点有:
- 接口契约不清晰:前端认为某个参数可选,后端认为必选,导致频繁调试和修改。
- 错误信息不明确:后端返回晦涩的异常栈信息,前端无法直接展示给用户,需要来回沟通排查。
- 响应格式不统一:有的接口成功返回对象,有的返回
{success: true, data: {...}},失败时格式更是五花八门,前端需要为每个接口写不同的处理逻辑。
Q: 这个许可证系统上线后效果如何?
A: 由于我离职时系统刚上线不久,长期的盗版率数据我还无法获取。但能衡量的直接效果非常显著:
- 部署效率:如简历所说,提升了60%。
- 联调效率:联调周期从3天缩短至1.5天。
- 客户反馈:实施团队的反馈是,许可证的安装和激活流程变得标准化了,他们只需要给客户一个文档即可,咨询类的问题变少了。
- 商业准备:为产品未来实行按年订阅付费(SaaS化)打下了坚实的技术基础,这是最重要的长期价值。
希望这些详细的回答能帮助你更好地准备面试。请务必结合你自己的实际经验来理解和调整这些答案,做到心中有数,对答如流。祝你成功!
好的,我们来深入详细地说明这两个要点。这在面试中是非常好的展示你技术深度和业务理解能力的机会。
一、 功能模块列表 (Feature Flags / Licensing)
这是一个将技术实现与商业策略直接挂钩的典型例子,是许可证系统的核心价值所在。
1. 是什么?
“功能模块列表”是指在生成的许可证文件中,不仅仅包含有效期,还包含一个明确的、加密的授权功能清单。这相当于一个功能开关(Feature Flags)的白名单或权限矩阵。
2. 为什么需要它?
- 差异化定价与销售:允许公司销售不同版本的软件(如:基础版、专业版、企业版),每个版本包含的功能不同,价格也不同。
- 增值服务(Up-sell):客户可以先购买基础版,后续再付费解锁某个高级模块(如数据分析大屏、自动化报表生成等),无需重新安装整个软件,只需更新许可证文件即可。
- 试用与推广:可以给潜在客户提供一个临时许可证,临时开启所有功能供其试用,到期后自动降级为基础版或禁用。
3. 具体实现(结合你的项目):
在证书中定义:在服务端生成证书时,除了
notBefore(生效时间)、notAfter(过期时间)、consumerAmount(用户数)等标准字段外,我们自定义了一个扩展字段,例如叫做features。数据格式:这个
features字段可以是一个用特定分隔符(如逗号)连接的字符串,或者一个JSON数组。 字符串示例:"DATA_VISUALIZATION,AUTO_REPORT,ADVANCED_AI"JSON示例:["DATA_VISUALIZATION", "AUTO_REPORT", "ADVANCED_AI"]客户端校验:
- 客户端程序在启动验证许可证时,除了校验有效期和硬件信息,还会解析出这个
features列表,并将其保存在内存或应用上下文中。 - 在软件代码中,在所有高级功能的入口处(如Controller层的方法),添加校验逻辑。
1
2
3
4
5
6
7
8
9
10// 示例代码:在某个高级功能的Controller方法中
@GetMapping("/generateAdvancedReport")
public ResponseEntity generateReport() {
// 校验当前许可证是否包含此功能权限
if (!licenseService.hasFeature("AUTO_REPORT")) {
// 返回统一的错误响应,提示“您的许可证未包含高级报表功能,请联系销售”
throw new LicenseFeatureNotFoundException("AUTO_REPORT");
}
// ... 正常执行功能逻辑
}- 客户端程序在启动验证许可证时,除了校验有效期和硬件信息,还会解析出这个
管理端操作:市场/销售人员在给客户生成许可证时,可以在管理后台界面上通过勾选复选框的方式来轻松配置该客户有权使用的功能模块。
面试时可以这样总结:“我们通过许可证中的自定义字段实现了功能模块的精细化控制,这让我们的产品从单一版本变成了可配置的、多版本的商业化产品,直接支持了公司的差异化定价和销售策略。”
二、 联调时的具体沟通痛点
联调(前后端联合调试)的痛点通常源于“契约不清晰”和“反馈不明确”,导致大量的沟通成本和重复劳动。
痛点详细说明:
“猜谜游戏”之参数问题:
- 痛点:前端需要调用一个
GET /api/users接口来获取用户列表。 - 场景:后端开发A认为分页参数是
pageNum和pageSize,而前端开发B根据习惯传了page和limit。双方都按自己的理解开发,一到联调就报错,然后开始互相询问:“你到底要传什么参数?” - 你的解决方案:通过强制使用
@ApiParam(required = true)并在Swagger文档中明确写出参数名和是否必填,形成前后端共同遵守的契约。后端看到注解就知道要校验,前端看到文档就知道要传什么。
- 痛点:前端需要调用一个
“黑盒异常”之错误处理问题:
痛点:前端提交表单,后端校验失败,直接抛出一串
NullPointerException或者Spring默认的400 Bad Request,响应体里是一大堆Java异常栈信息。场景:前端拿着这个错误不知所措,只能把截图丢到群里问后端:“这啥意思?是哪个字段错了?” 后端再去翻日志,定位问题,然后回复:“哦,是email字段没传。”
你的解决方案:通过全局异常处理(@ControllerAdvice) 和标准化API响应体,将所有异常转换为前端能直接理解和展示的格式。
1
2
3
4
5
6
7
8
9
10
11
12
13// 改造前(混乱且无法解析):
"timestamp": "2023-...",
"status": 400,
"error": "Bad Request",
"trace": "java.lang.NullPointerException: null at com.example.Controller..."
// 改造后(清晰且可编程):
{
"success": false,
"code": "USER_EMAIL_REQUIRED", // 唯一的错误码,前端可以用它做多语言映射
"message": "邮箱地址为必填项", // 直接可展示给用户的友好信息
"data": null
}这样,前端可以轻松地:
if (response.code === 'USER_EMAIL_REQUIRED') { alert('请填写邮箱'); }
“类型黑洞”之数据格式问题:
- 痛点:后端某个字段设计为
Integer类型,前端传了个字符串"123",Spring可能自动转换了,但有时又会转换失败报错。或者日期格式不统一(yyyy-MM-ddvsyyyy/MM/dd)。 - 你的解决方案:通过强大的后端校验注解(如
@NotNull,@Email,@Pattern) 和统一的异常处理,在接口入口就明确拒绝格式错误的请求,并返回非常具体的错误信息(如“生日日期格式应为YYYY-MM-DD”),而不是一个笼统的“参数错误”。
- 痛点:后端某个字段设计为
“沟通孤岛”之文档滞后问题:
- 痛点:后端接口改了(如字段名变了、接口地址变了),只是口头跟前端说了一声,或者改了忘了说。前端在不知情的情况下继续开发,等到联调时才发现接口对不上,双方都很恼火。
- 你的解决方案:通过Swagger/OpenAPI等工具,让API文档随着代码自动生成。代码即文档,后端一旦修改代码并更新了注解,文档就会自动更新,前端可以随时查看最新的接口约定,从根本上减少此类问题。
面试时可以这样总结:“联调的主要痛点本质是契约混乱和反馈无效。我们通过 ‘标准化响应体 + 全局异常处理’ 解决了反馈问题,让错误信息可读可处理;通过 ‘强制注解 + Swagger自动化文档’ 解决了契约问题,让接口约定清晰且实时同步。这直接将我们团队的联调周期从3天缩短到了1.5天。”
山西中维
2025 年 9 月 14 日
当然,这是一个非常详细的、基于你第二段项目经验的“参考答案库”。请结合你自己的实际理解进行微调,使其成为你自己的答案。
一、 关于“性能优化”的回答思路
1. 深度追问
Q: 你是怎么发现这个接口需要优化的?
A: 主要通过两种方式:
- 监控告警:我们项目接入了基础的监控,当接口响应时间超过1秒时会有日志告警。这个接口频繁触发告警。
- 前端反馈:前端同事和测试同事在联调/测试时,直接反馈这个页面加载非常慢,体验很差。我们随后在后端日志中确认了该接口的响应时间确实在1.2秒左右。
Q: 详细讲一下你使用Explain分析SQL的过程?你看到了什么?
A: 我拿到这个慢接口对应的SQL语句后,在MySQL客户端前加上了 EXPLAIN 关键字执行。
1 | |
我重点关注了几个字段:
- type: ALL: 这最致命,表示进行了全表扫描(Full Table Scan),说明MySQL正在逐行检查整个表来找到匹配的行。
- rows: 一个大数值: 比如几万甚至更多,这表示MySQL认为必须检查的行数非常多。
- possible_keys: NULL & key: NULL: 表示没有合适的索引可用,MySQL也无法使用任何索引来执行这个查询。
- Extra: Using where: 表示在存储引擎检索行后进行过滤。
看到这些结果,结论就很明确了:因为没有索引,MySQL不得不进行全表扫描来执行模糊查询,导致性能急剧下降。
Q: 你具体是加了什么索引?为什么选择这些字段?
A: 我针对 dept_name 字段创建了一个普通的二级索引(Secondary Index)。
1 | |
- 为什么选这个字段:因为
WHERE子句的查询条件就是基于dept_name的模糊匹配。这是查询的驱动字段。 - 为什么不是复合索引:因为这个查询的过滤条件只有这一个字段,没有其他联合查询条件,所以单列索引就足够了。
- 注意点:我也知道对于
LIKE '%关键词%'这种前导通配符的查询,即使加了索引也可能失效。但在我们的业务场景和MySQL版本中,添加索引后通过EXPLAIN再次查看,type变成了range(范围扫描),key显示使用了idx_dept_name,证明索引是生效的,效果立竿见影。
Q: 除了加索引,还做了其他优化吗?
A: 这是一个非常好的问题。加索引是主菜,但我还做了一些“配菜”:
- **避免 SELECT :我修改了SQL语句,将
SELECT *替换为SELECT id, name, phone...,只查询业务需要的具体字段*。这减少了网络传输的数据量,特别是在表字段很多的情况下,对性能也有提升。 - 考虑缓存:这个接口的数据变更频率不高(部门名称不会老是变)。如果后续性能要求更高,可以考虑引入Redis,将查询结果缓存起来,下次同样请求直接返回缓存数据。
2. 原理延伸
Q: 在什么情况下,即使加了索引也不会生效?(索引失效场景)
A: 常见的索引失效场景有:
- 对索引列进行运算或函数操作:例如
WHERE YEAR(create_time) = 2023,即使create_time有索引也会失效。应改为范围查询WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31'。 - 使用左模糊或全模糊查询:
LIKE '%abc'或LIKE '%abc%'会导致索引失效。右模糊LIKE 'abc%'仍然可以走索引。 - 数据类型隐式转换:例如索引字段是字符串类型
varchar,查询时用了WHERE code = 123(数字),MySQL会做类型转换,导致索引失效。 - 不符合最左前缀原则:对于复合索引
(a, b, c),查询条件没有包含最左边的列a,索引可能失效。 - 使用 OR 连接:如果
WHERE a = 1 OR b = 2,如果a和b是单独索引,可能不会使用索引。优化方法是改用UNION。 - 评估使用索引比全表扫描还慢:当表中数据量很少时,MySQL优化器可能认为直接全表扫描比走索引再回表更快。
二、 关于“技术实现”的回答思路
Q: 为什么选择EasyExcel而不是Apache POI?
A: 这是基于内存占用和使用便捷性的综合考量。
- Apache POI: 功能强大,但它在处理大数据量(比如上万行)的Excel时,采用的是将整个文件加载到内存的模型(DOM解析),非常容易导致JVM内存溢出(OOM),性能也较差。
- EasyExcel: 它的核心优势是逐行解析的监听器模式(SAX解析)。它不会一次性把整个文件读入内存,而是逐行读取解析,处理一行,释放一行的内存。内存占用极低,非常适合处理大数据量的导入导出,这也是我们选择它的最主要原因。此外,它的API设计也更友好,简化了开发。
Q: 说一下监听器机制是怎么工作的?
A: 以数据导入为例:
- 我定义了一个自定义的
AnalysisEventListener,例如EmployeeExcelListener。 - 在
invoke()方法中,EasyExcel每解析一行数据,就会将这一行数据作为一个对象(如EmployeeDTO)传入这个方法。我在这里进行数据校验和业务处理(比如存入一个临时List)。 - 在
doAfterAllAnalysed()方法中,当所有行都解析完毕后,会触发这个方法。我在这里进行批量入库操作(例如MybatisPlus的saveBatch),而不是解析一行插入一行,这极大地提高了效率。 - 整个过程内存中只会保持一批数据(比如1000条),而不是全部数据,完美避免了OOM。
Q: MyBatis-Plus相比原生MyBatis有哪些优点?
A: MP是一个强大的增强工具,而不是替代品。它的核心优点就四个字:简化开发。
- 强大的CRUD封装:内置了通用Mapper(
BaseMapper)和通用Service(IService),单表查询无需编写任何XML文件。例如userMapper.selectById(1),userService.list(new QueryWrapper().lambda().eq(User::getName, "张三")),开发效率极高。 - 强大的条件构造器:
QueryWrapper和UpdateWrapper可以通过链式调用轻松构建复杂且安全的查询条件,有效避免了SQL拼接的麻烦和SQL注入的风险。 - 丰富的插件:如分页插件(无需手动
count和limit)、性能分析插件(输出SQL执行时间)等,开箱即用。 - 代码生成器:这正是我项目中用到的,可以根据数据库表自动生成Entity、Mapper、XML、Service、Controller等全套代码,极大减少了初始搭建项目的重复劳动。
三、 关于“业务与项目”的回答思路
Q: “智能名片生成”是怎么实现的?
A: 我们的实现方案是动态生成H5页面。
- 后端设计一个名片数据的API接口,返回用户的所有信息(姓名、职位、公司、头像、电话等)。
- 前端(Vue.js)拿到这些数据后,填充到一个预先设计好的名片模板中。
- 用户分享出去的是一个带有用户ID参数的H5链接(如
https://.../card.html?userId=123)。 - 任何人点击这个链接,都会访问前端页面,前端再根据URL中的
userId去调用后端接口获取数据并渲染展示。
- 优点:灵活,易于更新(用户信息改了,名片内容自动变),且易于追踪访问数据。
Q: “人脉圈留言功能”的数据库表是怎么设计的?
A: 核心表是一张 comment 表,主要字段包括:
id: (BIGINT) 主键business_card_id: (BIGINT) 被留言的名片ID,外键关联到名片表user_id: (BIGINT) 留言者的用户IDcontent: (TEXT) 留言内容parent_id: (BIGINT) 自关联外键,用于实现回复功能。如果为0,则是顶级留言;如果有值,则是回复某条留言的回复。create_time: (DATETIME) 创建时间- 索引:会在
business_card_id和create_time上建立索引,方便根据名片ID查询并按时间排序。
Q: 你一般在禅道上提交Bug会包含哪些信息?
A: 我会尽量提供一次完整的信息,减少来回沟通的成本。一个规范的Bug提交通常包括:
- 标题:简短清晰地描述问题(如:【名片详情页】点击分享按钮无响应)。
- 环境:测试环境/生产环境,浏览器型号版本。
- 复现步骤: step1, step2, step3… 清晰描述如何操作会必然导致这个问题。
- 预期结果:期望的正常表现是什么。
- 实际结果:目前发生的异常表现是什么(最好附上截图或录屏)。
- 错误日志:如果是后端Bug,我会附上从服务器日志中查到的相关错误栈信息(StackTrace),这是最关键的解码信息。
- 关联:会关联到对应的需求或任务。
希望这些详细的回答能帮助你更好地准备面试。请务必结合你自己的实际经验来理解和调整这些答案,做到心中有数,对答如流。祝你成功!
基本导入,模型映射导入,导入类型转换器,导入监听器,导入异常处理,文件导入。
基本导出,模型映射导出,导出格式转换,排除指定列,导出行高行宽,合并单元格导出,
核心问题
2025 年 9 月 15 日
非常好!这是一个绝佳的机会来展示技术的深度和广度。我将以一名资深工程师和技术面试官的身份,为你逐一解答这些问题。这些答案不仅提供了事实,还包含了背后的原理、实践中的权衡以及更深入的思考,你可以借此来提升自己的理解。
一、Java 基础与规范
1. HashMap 原理
- 底层结构:JDK 1.8 后是“数组 + 链表 + 红黑树”。数组是主干,每个数组元素是一个
Node(链表)或TreeNode(树)。 - 哈希冲突:通过
hash(key)计算数组下标,不同 key 可能算出相同下标,这就是冲突。解决方法是“链地址法”,即在该下标处形成链表。当链表长度超过 8 且数组总长度超过 64 时,链表转为红黑树,以提升查询效率(从 O(n) 提升到 O(log n))。 - ConcurrentHashMap vs Hashtable:
Hashtable用synchronized锁住整个对象,并发度低。ConcurrentHashMap在 JDK 1.7 使用“分段锁”,1.8 改为更高效的CAS+synchronized(只锁住数组的某一个桶/链表头节点),并发度大大提升。
2. ArrayList vs LinkedList
- 区别:
ArrayList基于动态数组,随机访问快(get(i)O(1)),但中间插入删除慢(需要移动元素,O(n))。LinkedList基于双向链表,插入删除快(只需修改指针,O(1)),但随机访问慢(需遍历,O(n))。 - 扩容:
ArrayList初始容量 10,扩容时newCapacity = oldCapacity + (oldCapacity >> 1)(即 1.5 倍),然后将旧数组数据拷贝到新数组。
3. 自定义注解
- 定义:
@Target(ElementType.METHOD)表示该注解用于方法;@Retention(RetentionPolicy.RUNTIME)表示注解在运行时可用,这样我们才能通过反射解析它。 - 解析:通常结合 AOP 或 反射。例如,定义一个
@Permission(role="admin")注解。在 AOP 的切面中,通过JoinPoint.getSignature().getMethod().getAnnotation(Permission.class)获取注解,然后判断当前用户角色是否匹配。
4. Lambda & Stream
- map vs flatMap:
map是一对一映射,将元素转换成另一个元素。flatMap是一对多映射,将每个元素转换成一个Stream,然后把所有Stream扁平化连接成一个Stream。例如,将List<List<String>>扁平化为List<String>。 - 并行流注意:并行流使用
ForkJoinPool,任务拆分和合并有开销,数据量小可能更慢。要确保操作是无状态、无干扰、可 associative 的,否则易出错。
二、SpringBoot & 整合
1. 自动配置原理
核心是 @SpringBootApplication -> @EnableAutoConfiguration -> Import(AutoConfigurationImportSelector.class)。
AutoConfigurationImportSelector 会读取 META-INF/spring.factories 文件中的大量自动配置类(如 DataSourceAutoConfiguration)。这些配置类使用 @ConditionalOnClass/MissingBean 等条件注解,按需加载配置。例如,@ConditionalOnClass(DataSource.class) 表示类路径下存在 DataSource 类时,该自动配置才生效。
2. Hutool 价值
它提供了通用工具方法,避免了“造轮子”,提升了开发效率和代码可读性。例如:DateUtil.format、HttpUtil.get、StrUtil.isBlank、BeanUtil.copyProperties 等,封装了常用操作,减少了冗余代码。
三、MySQL & 性能优化
1. Explain 解读
- type:
ALL(全表扫描,最差)->index(全索引扫描)->range(索引范围查询)->ref/eq_ref(唯一索引查询)->const(最佳)。 - key:实际使用的索引。
- rows:预估需要读取的行数,越小越好。
- Extra:
Using filesort(需额外排序)、Using temporary(需用临时表)都是需要优化的信号。
2. 最左前缀原则
对于复合索引 (a, b, c),它可以有效用于查询 (a), (a, b), (a, b, c)。但如果查询条件是 (b) 或 (b, c),该索引无效。
3. 索引失效场景
- 对索引列进行计算或函数操作:
WHERE YEAR(create_time) = ... - 类型隐式转换:
varchar列传入int值。 - 左模糊查询:
LIKE '%abc'。 - 不符合最左前缀原则。
四、Redis & 缓存
1. BitMap 签到
- Key:
user:sign:{userId}:{yyyyMM} - 签到:
SETBIT key offset 1(offset 为当月第几天) - 检查某天:
GETBIT key offset - 统计连续签到:使用
BITFIELD命令获取一段位域,然后在客户端代码中计算连续为 1 的位数。
2. Lua 脚本 & 原子性
Redis 执行 Lua 脚本时是原子性的,期间不会执行其他命令。这对于需要 “判断+执行” 的复合操作至关重要。例如,秒杀扣库存:
1 | |
3. 缓存一致性
常用策略是:更新数据库,然后删除缓存。
- 为什么不是更新缓存? 因为可能有多个并发写操作,更新顺序无法保证,且计算缓存值可能很耗时。
- 为什么先删缓存再更新数据库不行? 这会导致读请求在缓存删除后、数据库更新前瞬间把旧数据又回写到缓存。
- 更复杂的方案:可以通过 Canal 监听数据库 binlog 来异步删除缓存,保证最终一致性。
五、ElasticStack
1. 高亮 & 建议
- 高亮:在 DSL 查询中添加
"highlight": { "fields": { "content": {} } }。 - 搜索建议:使用
completion suggester。需要在映射中定义类型为completion的字段。查询时在suggest体中指定该字段。
2. 数据同步
- 双写:代码中同时写 DB 和 ES。简单,但难保证一致性。
- Canal/Maxwell:推荐。通过监听 MySQL binlog,实时将数据变更同步到 MQ,再由消费者写入 ES。解耦,对业务无侵入,保证最终一致性。
六、JVM & 底层
1. 内存区域
- 线程共享:堆(Heap)、方法区(Metaspace)
- 线程私有:程序计数器、虚拟机栈(存栈帧、局部变量表等)、本地方法栈。
2. 垃圾收集器
- CMS:老年代收集器,标记-清除算法,追求低停顿,但会产生碎片。
- G1:面向全堆,将堆划分为 Region,采用标记-整理算法,可预测停顿时间,是当前主流。
- ZGC:新一代低延迟收集器,通过染色指针等技术实现停顿时间控制在 10ms 以下。
3. 双亲委派模型
一个类加载器收到加载请求时,先不自己加载,而是委派给父加载器尝试加载。只有当父加载器无法完成时,子加载器才自己加载。
- 好处:保证核心类(如
java.lang.Object)的唯一性和安全,不会被用户自定义的类替代。 - 打破场景: JDBC:
DriverManager需要加载由各类数据库厂商实现的Driver接口,这些接口类位于 classpath 下,但需要由启动类加载器加载,这需要通过Thread.currentThread().getContextClassLoader()(线程上下文类加载器)来打破。 Tomcat:每个 Web 应用需要隔离自己的类库,所以每个 WebApp 都有自己的类加载器。
七、性能/安全优化
1. 批处理
Mybatis Plus 的 saveBatch 底层并非真正的 JDBC 批处理,而是分组后一条条 INSERT。真正的高效批处理需要开启 JDBC 的 rewriteBatchedStatements=true 参数,并手动编写 addBatch() 和 executeBatch() 代码。
2. 多级缓存
本地缓存(Caffeine)-> 分布式缓存(Redis)-> 数据库。
- 策略:先读本地,未命中读 Redis,再未命中读 DB 并回填缓存。
- 挑战:如何保证本地缓存的一致性?可通过发布订阅(如 Redis Pub/Sub)来通知所有节点失效本地缓存。
3. 同端互斥登录
用户登录时,将 userId 和本次登录的 token 作为键值对存入 Redis。下次登录时,生成新 token,删除旧 token(强制旧客户端token失效),并存入新 pair。
八、Nginx
拦截IP:在
location块或http块中使用deny 192.168.1.1;或allow/deny组合。解决跨域:在
location块中配置:1
2
3
4add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods 'GET, POST, OPTIONS';
add_header Access-Control-Allow-Headers 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range,Authorization';
if ($request_method = 'OPTIONS') { return 204; } # 处理预检请求负载均衡:
upstream块中定义服务器组,在location中proxy_pass到该组。策略有轮询、weight(权重)、ip_hash(同一IP固定到一台服务器)。
九、SpringCloud & 微服务
1. Nacos vs Eureka
- Eureka:AP 架构,保证高可用,但可能读到旧数据。
- Nacos:同时支持 CP 和 AP 模式。还提供强大的配置中心功能,这是 Eureka 没有的。Nacos 集群基于 Raft 协议,性能更高。
2. OpenFeign 原理
它基于动态代理。你定义接口后,Feign 会在运行时为你创建一个实现类。发起的请求会被拦截器处理,然后由 Ribbon(负载均衡器)从服务注册中心(如 Nacos)获取服务实例列表,并选择一个实例,最后通过 HTTP 客户端(默认是 JDK 的 HttpURLConnection,可替换为 OKHttp)发送请求。
3. 微服务改造挑战
- 拆分粒度:如何划分微服务?(按业务域划分,如用户服务、订单服务)
- 分布式事务:如何保证跨服务的数据一致性?(引入 Seata 或采用最终一致性方案,如可靠事件模式)
- 联调测试:环境更复杂,需要更好的 API 管理和文档工具(如 Swagger + OpenAPI)。
十、RBAC & SpringSecurity
1. RBAC 表结构
5张核心表:用户表 -> 用户-角色中间表 -> 角色表 -> 角色-权限中间表 -> 权限表。
权限表通常存储权限字符串,如 user:delete。
2. SpringSecurity 流程
请求经过一系列 过滤器链。JWT 校验通常在自定义的 JwtAuthenticationFilter 中完成,该过滤器应放在链的前部。它解析 token,成功后会将认证信息存入 SecurityContextHolder。后续的授权过滤器(如 FilterSecurityInterceptor)会从中获取信息进行鉴权。
springboot3整合SpringSecurity实现登录校验与权限认证(万字超详细讲解)_springboot security-CSDN博客
3. 方法级注解
需要在配置类上添加 @EnableGlobalMethodSecurity(prePostEnabled = true) 来启用 @PreAuthorize。其原理是基于 AOP,在方法调用前进行权限切面检查。
十一、Docker
高效 Dockerfile:
1 | |
使用 .dockerignore 忽略 .git, *.md, target/ 等文件,加速构建和减小镜像上下文。
十二、Spring AI & AI 应用 (核心亮点)
1. RAG (Retrieval-Augmented Generation)
- 工作流: 知识库处理:将文档(PDF、Word等)进行分块。 向量化:使用 Embedding 模型(如 OpenAI text-embedding-ada-002)将文本块转换为向量。 存储:将这些向量存入向量数据库(如 ChromaDB, Pinecone)。 检索:用户提问时,先将问题向量化,然后在向量库中检索最相似的 Top-K 个文本块。 增强生成:将检索到的文本块作为上下文,与用户问题一起组合成 Prompt,发送给 LLM(如 GPT-4)。LLM 基于这些知识生成回答,避免幻觉。
2. 工具调用 (Function Calling)
LLM 本身无法执行代码、查询数据库。工具调用允许 LLM 理解用户请求后,决定需要调用哪个工具(函数),并生成符合函数参数的 JSON 数据。应用程序执行该函数,将结果返回给 LLM,LLM 再组织成最终回答。
- 例子:用户问“北京天气怎么样?”。LLM 识别出需要调用
get_weather(location: string)函数,并生成{"location": "北京"}。程序执行天气查询 API,将结果返回,LLM 总结:“北京今天晴,25摄氏度。”
3. MCP (Model Context Protocol)
由 OpenAI 提出,是一种标准化协议,用于让 LLM 与外部工具、数据源和服务进行更安全、高效的交互。它解决了不同工具集成方式不一、难以管理的问题。MCP 服务器提供工具,MCP 客户端(如 AI 应用)通过标准协议与服务器通信,使 LLM 能无缝使用这些工具。
4. 会话记忆 (Session Memory)
通常将完整的对话历史(或摘要)存储在外部(如 Redis),并以 session_id 为键。每次请求时,将历史记录作为上下文再次发送给 LLM,从而实现连续对话的能力。
十三、开发工具 & 效率
1. Git 工作流
常用 Feature Branch Workflow:
- 从
develop分支切出feature/user-auth。 - 在特性分支上开发、提交。
- 完成後,向
develop发起 Pull Request(合并请求)。 - 代码评审(Code Review)通过后,合并到
develop。 - 这是一种非常清晰和协作友好的流程。
2. AI 助手提效
- 代码生成:快速生成样板代码、单元测试、SQL查询。
- BUG 排查:将错误日志贴给它,让它帮助分析可能的原因。
- 学习新技术:让它解释概念、提供入门示例代码。
- 代码重构:建议更好的写法、识别代码坏味道。
希望这些深入的回答不仅能帮助你应对面试,更能加深你对这些技术的理解。祝你马到成功!
重点知识总结
操作系统
进程调度:
先来先服务:先来后到
最短作业优先:长作业可能没有执行机会
高响应比优先:等待时间 + 执行时间 / 执行时间,等待时间越长,长作业就越有机会被执行
时间片轮转:为每个进程分配时间片,用完或者提前结束,其他进程就可以抢占 CPU,不好把控时间片大小
最高优先级:为进程设置优先级,静态优先级、动态优先级,优先级低的可能没有执行机会
多级反馈队列调度:多个阻塞队列,按照不同的优先级排列,优先级越低的队列,可执行时间越长。
Java 中的锁机制
Java 中的锁机制是用于处理多线程并发情况下数据一致性的重要工具。在 Java 中,有多个层面的锁机制,包括 synchronized 关键字和 Lock 接口等。
- synchronized 关键字
- 这是 Java 语言内置的一种锁机制。
- 它可以用来实现对代码块或方法的同步控制,确保同一时刻只有一个线程可以执行被锁定的代码块或方法。
- 当一个线程获取锁时,它会将对象头中的标志位设置为锁定状态,其他线程在尝试获取锁时,如果发现标志位已被设置为锁定状态,就会进入等待状态,直到锁被释放。
- Lock 接口
- 提供了比 synchronized 更灵活的锁机制。
- 它提供了显式的锁获取和释放操作,允许更细粒度的控制。
- Lock 接口有多种实现,包括 ReentrantLock 等。
在 Java 的锁机制中,还可以根据锁的特性进行进一步分类:
- 公平锁与非公平锁
- 公平锁:按照线程申请锁的顺序来获取锁,类似于日常排队。
- 非公平锁:线程获取锁的顺序并不是按照申请锁的顺序,可能存在插队现象。
- 可重入锁(递归锁)
- 允许同一线程在外层方法获取锁后,进入内层方法时仍能持有该锁并继续运行。
- 自旋锁
- 当线程尝试获取锁失败时,不是立即阻塞等待,而是采用循环的方式尝试获取锁。
- 这可以减少线程上下文切换的消耗,但当循环次数过多时,会消耗 CPU 资源。
- 读写锁
- 分为写锁和读锁。写锁是独占锁,一次只能被一个线程持有;读锁是共享锁,可被多个线程持有。
- 读写锁适用于读操作远多于写操作的场景,可以大大提高读操作的性能。
Java 的锁机制为多线程编程提供了丰富的工具,开发者可以根据具体的业务需求选择适合的锁类型,以确保数据的一致性和线程的安全性。
推荐阅读:[19 你知道哪几种锁?分别有什么特点? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/19 你知道哪几种锁?分别有什么特点?.md)
Synchronized 实现原理
JVM 基于进入和退出 Monitor 对象来实现方法同步和代码块同步,但两者的实现细节不一样。
代码块同步是使用 monitorenter 和 monitorexit 指令实现的,而方法同步是使用另外一种方式实现的。
monitorenter 指令是在编译后插入到同步代码块的开始位置,而 monitorexit 是插入到方法结束处和异常处,
JVM 要保证每个 monitorenter 必须有对应的 monitorexit 与之配对。
任何对象都有 一个 monitor 与之关联,当且一个 monitor 被持有后,它将处于锁定状态。线程执行到
monitorenter 指令时,将会尝试获取对象所对应的 monitor 的所有权,即尝试获得对象的锁。
Java 并发容器
HashMap
HashMap 的put流程和扩容原理是 Java 集合框架中非常重要的部分,下面我将详细地描述这两个过程。
HashMap 的 put 流程
- 计算 key 的哈希值:首先,HashMap 会根据 key 的 hashCode()方法计算出一个哈希值,这个哈希值会用来确定 key 在 HashMap 中的存储位置。
- 计算数组索引:HashMap 内部有一个 Entry 数组,用来存储键值对。计算出的哈希值会进一步通过一个算法(通常是哈希值与数组长度取模)转换成一个数组索引。
- 检查是否存在键值对:在对应的数组索引位置,HashMap 会检查是否已经存在一个键值对。如果存在,并且 key 相同,那么就用新的 value 替换旧的 value。
- 处理哈希冲突:如果计算出的数组索引位置已经有键值对,并且 key 不同,那么就发生了哈希冲突。HashMap 通过链表或红黑树(在 JDK 1.8 及以后版本中,当链表长度超过一定阈值时,会转换为红黑树)来解决哈希冲突。
- 插入新的键值对:如果数组索引位置是空的,或者 key 相同但 value 需要更新,那么就在该位置插入新的键值对。
HashMap 的扩容原理
当 HashMap 中的元素数量超过数组容量的一定比例(负载因子,默认是 0.75)时,就会触发扩容操作。
- 创建新的数组:HashMap 会创建一个新的数组,其容量通常是原数组容量的两倍。
- 重新计算索引:扩容后,原来的键值对需要根据新的数组长度重新计算索引。由于新的数组长度是原来的两倍,所以原来的哈希值取模的结果要么不变,要么变为原来的索引加上原数组长度。这个特性被称为“幂等扩容”,它保证了在扩容过程中,只需要对原数组中的元素进行一次重新索引操作,而不需要遍历整个数组。
- 移动键值对:HashMap 会遍历原数组中的每个位置,对于每个非空的键值对,重新计算其在新数组中的索引,并将其移动到新的位置。这个过程可能会触发哈希冲突的解决操作(即链表的插入或红黑树的调整)。
需要注意的是,扩容操作是一个相对耗时的过程,因为它涉及到内存的重新分配和键值对的重新索引。因此,在实际使用中,应该尽量避免频繁的扩容操作,可以通过预估合适的初始容量和负载因子来优化 HashMap 的性能。
ArrayList
简单介绍一下 ArrayList:
实现了 RandomAccess 接口,支持随机访问;实现了 Clonable 接口,支持复制;实现了 Serializable,支持序列化传输。
底层使用数组实现,该数组为可变长数组,也称之为动态数组。默认初始容量为 10,超出容量限制会自动扩容 1.5 倍。
扩容就是新建一个 1.5 倍容量大的数组,把原数组内容拷贝到新数组中,将新数组作为扩容后的数组。数组扩容代价很高,使用时应该尽量避免数组扩容,要预知要保存元素的多少,构建 ArrayList 时就指定其初始容量。
remove() 方法有按照索引删除,也有按照元素值删除。会使从所删除元素的下标开始,到数组末尾的元素全部向前移动一个位置,置空最后一位,方便 GC 回收。删除中间元素,需要挪动大量的数组元素,操作代价很大;如果是末尾元素,代价是最小的。
不是线程安全的,只能用在单线程环境下。在多线程环境中,可以考虑使用 Collections.synchronizedList(List l)函数返回一个线程安全的 ArrayList 类。
采用了 Fail-Fast 机制,面对并发的修改时,迭代器很快就会完全失败,报异常 concurrentModificationException(并发修改一次)
add(E e) 实现原理:
ensureCapacityInternal(size +1),修改 modCount 标识自增一,calculateCapacity() 确保数组已使用长度加一后不会溢出,即足够存放下一个元素,不满足就使用 grow() 扩容为原容量的 1.5 倍。
ElementData[size++] = e,添加新元素到数组中。
返回新元素添加成功的布尔值。
add(int index, E element) 实现原理:大同小异。
首先确保要插入元素的位置小于等于当前数组长度,并且不能小于 0,否则抛出异常。
判断是否需要扩容后,确保了数组有足够的容量。使用 System.arraycopy() 将要插入的位置之后的所有元素向后移动一位,再将新的数组元素放到指定位置 ElementData[index] = e。
扩容原理:ArrayList 的扩容原理主要涉及到底层数组的容量调整。当 ArrayList 中的元素数量达到当前数组的容量时,它会自动进行扩容以容纳更多的元素。
具体来说,ArrayList 的扩容过程如下:
- 计算新容量:默认情况下,新的容量会是当前容量的 1.5 倍。这通常是通过将当前容量右移一位(相当于除以 2)然后加上当前容量来实现的。例如,如果当前容量是 10,那么新的容量会计算为 10 + (10 >> 1) = 15。
- 创建新数组:根据计算出的新容量,ArrayList 会创建一个新的数组。
- 复制元素:将原数组中的元素复制到新数组中。这个过程涉及到遍历原数组,并将每个元素依次放入新数组的对应位置。
- 更新引用:将 ArrayList 的内部引用从原数组更新为新数组。
需要注意的是,ArrayList 在初始化时会有一个默认的容量(通常为 10),当第一个元素被添加时,如果还没有进行初始化,那么就会创建一个默认容量的数组。之后的扩容操作都是基于这个原理进行的。
频繁的扩容操作可能会对性能产生影响,因为每次扩容都需要创建新数组并复制元素。因此,在实际使用中,如果可能的话,最好预先估计所需容量并设置合适的初始容量,以减少扩容的次数。
另外,与 ArrayList 不同,LinkedList 是基于双向链表实现的,因此它不需要扩容机制。在 LinkedList 中,添加或删除元素只需要调整链表的节点连接,而不需要像 ArrayList 那样复制整个数组。这使得 LinkedList 在元素增加和删除操作上的效率通常比 ArrayList 要高。
remove() 的实现过程:从列表中删除指定元素,有多种重载形式。按值删除,遍历整个列表寻找给定元素,找到就删除,同时将后面元素向前移动一个位置。按索引删除,直接定位到给定索引的元素,执行删除操作。
remove() 的实现原理:以按照索引删除为例。ElementData 数组根据索引下标找到元素值;根据 size - index - 1 判断删除元素是否为最后一个元素。如果不是最后一个元素,执行 System.arraycopy() 数组拷贝,所有元素向前移动一个位置。最后,把数组最后一位置空,为 null,为 GC 做准备。
Fail-Fast 机制:这是一个错误检测机制,用于在并发修改列表时抛出 ConcurrentModificationException 异常。
当使用迭代器遍历 ArrayList 时,如果列表在迭代过程中被结构性地修改了(例如,通过 add、remove 或 clear 方法),迭代器就会快速失败并抛出 ConcurrentModificationException。结构性修改是指那些改变列表大小的操作,或者那些可能干扰迭代器行为的操作。
这种机制的实现依赖于 ArrayList 内部的一个 modCount 字段。每当列表被结构性修改时,modCount 就会增加。迭代器在每次迭代时都会检查 modCount 是否与迭代器创建时的 expectedModCount 相等。如果不相等,就抛出 ConcurrentModificationException。
如果你尝试在迭代过程中使用 list.remove(item) 来删除元素,就会触发 Fail-Fast 机制并抛出异常。因此,总是应该使用迭代器的 remove 方法来删除元素,当你需要在迭代过程中修改列表时。
虽然 Fail-Fast 机制可以帮助发现并发问题,但它并不是线程安全的解决方案。在多线程环境中,你仍然需要使用适当的同步机制(如 synchronized 块或 Collections.synchronizedList)来确保线程安全。Fail-Fast 机制主要是为了帮助开发者在开发过程中更早地发现并发问题,而不是作为一个完整的并发控制机制。
循环中删除 ArrayList 的元素:
- 使用
ArrayList的remove方法直接删除元素:普通 for 循环通常是通过索引来遍历数组或容器中的元素的,而在循环中删除元素,列表的大小会改变,后续元素会向前移动,可能会抛出数组越界异常问题。 - 使用迭代器的
remove方法:Fail-Fast 机制 - 使用增强型 for 循环删除元素:增强型 for 循环(也称为”foreach”循环)在内部使用迭代器,因此当在循环体内部使用
ArrayList的remove方法时,会抛出ConcurrentModificationException。 - 从列表末尾向前删除元素:这种从后向前迭代的方法特别适用于需要基于索引删除元素的情况,因为它不会受到删除元素后列表大小变化的影响。
普通 for 循环本身不会抛出ConcurrentModificationException
类加载器
类加载器是一个负责加载类的对象,用于实现类加载过程中的加载这一步。每个 Java 类都有一个引用指向加载它的 ClassLoader。类加载器的主要作用就是加载 Java 类的字节码( .class 文件)到 JVM 中(在内存中生成一个代表该类的 Class 对象)。 字节码可以是 Java 源程序(.java文件)经过 javac 编译得来,也可以是通过工具动态生成或者通过网络下载得来。
类加载机制
首先要明确的一点是,JVM 启动的时候,并不会一次性加载所有的类,而是根据需要去动态加载。也就是说,大部分类在具体用到的时候才会去加载,这样对内存更加友好。
对于已经加载的类会被放在 ClassLoader 中。在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。也就是说,对于一个类加载器来说,相同二进制名称的类只会被加载一次。
类加载器分类
JVM 中内置了三个重要的 ClassLoader:BootstrapClassLoader(启动类加载器):最顶层的加载类,由 C++实现,通常表示为 null,并且没有父级,主要用来加载 JDK 内部的核心类库;ExtensionClassLoader(扩展类加载器);AppClassLoader(应用程序类加载器):面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。除了这三种类加载器之外,用户还可以加入自定义的类加载器来进行拓展,以满足自己的特殊需求。
双亲委派模型
每当一个类加载器接收到加载请求时,它会先将请求转发给父类加载器。在父类加载器没有找到所请求的类的情况下,该类加载器才会尝试去加载。
- 在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载(每个父类加载器都会走一遍这个流程)。
- 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器
loadClass()方法来加载类)。这样的话,所有的请求最终都会传送到顶层的启动类加载器BootstrapClassLoader中。 - 只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载(调用自己的
findClass()方法来加载类)。 - 如果子类加载器也无法加载这个类,那么它会抛出一个
ClassNotFoundException异常
双亲委派模型保证了 Java 程序的稳定运行,可以避免类的重复加载。原因是这样的:JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类。JVM 不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。
打破双亲委派模型
自定义加载器的话,需要继承 ClassLoader 。如果我们不想打破双亲委派模型,就重写 ClassLoader 类中的 findClass() 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 loadClass() 方法。
我们比较熟悉的 Tomcat 服务器为了能够优先加载 Web 应用目录下的类,然后再加载其他目录下的类,就自定义了类加载器 WebAppClassLoader 来打破双亲委托机制。这也是 Tomcat 下 Web 应用之间的类实现隔离的具体原理。
类加载过程
类的加载过程:首先要了解执行 Java 程序之后,由编译器将 Java 代码编译转换为字节码,再由 JVM 逐条解释执行字节码,类的加载就发生在 JVM 解释执行阶段。
当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
在加载阶段,通过类的全限定名获取指定类的字节流,将字节流代表的静态存储结构转换为方法区的动态运行时结构,同时在内存中生成 Class 对象,作为将来在方法区访问数据的入口。这里需要了解下 JVM 内存结构和类加载器、双亲委派模型等。
在连接阶段,首先进行 Class 文件格式检查、字节码语义检查、程序语义检查等工作,确保字节流中的信息符合规范。还要进行符号引用验证,确保该类所使用的其他类、方法、字段是否存在。完成类相关信息验证之后,开始为类变量分配内存并赋初值。最后,针对类、接口、类方法和接口方法,JVM 会将常量池内的符号引用替换为直接引用,也就是得到类或字段在内存中的指针或者偏移量,确保了在程序执行方法时,系统能够明确该方法所在位置。
在初始化阶段,作为类加载的最后一个阶段,JVM 开始真正执行指定类的 Java 程序代码,即字节码文件,对类进行初始化,创建类的对象实例。这个阶段我们了解到如果要初始化一个类,首先保证其父类完成初始化。整个初始化过程就是实例化对象并投入使用,过程也简单:在堆中分配内存空间 + 初始化对象 + 将该对象指向堆中分配的内存空间地址。
至此,一个类的加载就已经完成了,并且可以创建实例对象投入使用了。这里需要了解下 Java 对象的创建过程。
使用阶段不必多言,使用完毕之后进入卸载阶段。由于所有的对象实例都存放在堆中,当一个类的所有实例对象都已被 GC,在堆中已经不存在该类的实例对象了、该类没有在任何地方被引用,且该类的类加载器的示例也已被 GC 后,这个类就可以被卸载,即该类的 Class 对象被 GC。这里需要了解一下垃圾回收器、垃圾回收算法等。
JVM 内存模型
运行时数据区域
程序计数器:字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
虚拟机栈:方法调用的数据需要通过栈进行传递,每一次方法调用都会有一个对应的栈帧被压入栈中,每一个方法调用结束后,都会有一个栈帧被弹出。栈由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法返回地址。和数据结构上的栈类似,两者都是先进后出的数据结构,只支持出栈和入栈两种操作。
- 局部变量表 主要存放了编译期可知的各种数据类型和对象引用。
- 操作数栈 用于存放方法执行过程中产生的中间计算结果和计算过程中产生的临时变量。
- 动态链接 用于管理调用其他方法的符号引用,主要服务一个方法需要调用其他方法的场景。
栈帧随着方法调用而创建,随着方法结束而销毁。无论方法正常完成还是异常完成都算作方法结束。
堆:Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
方法区:当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
运行时常量池:Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic Reference)的 常量池表(Constant Pool Table) 。
字面量是源代码中的固定值的表示法,即通过字面我们就能知道其值的含义。字面量包括整数、浮点数和字符串字面量。常见的符号引用包括类符号引用、字段符号引用、方法符号引用、接口方法符号。常量池表会在类加载后存放到方法区的运行时常量池中。
以前在永久代即运行时数据区域,现在存放在元空间即本地内存。
字符串常量池:字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。以前在永久代即运行时数据区域,现在存放在堆中。
主要是因为永久代(方法区实现)的 GC 回收效率太低,只有在整堆收集 (Full GC)的时候才会被执行 GC。Java 程序中通常会有大量的被创建的字符串等待回收,将字符串常量池放到堆中,能够更高效及时地回收字符串内存。
直接内存:直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
垃圾回收
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 Java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
如果 TLAB 中没有足够的内存空间,就会在共享 Eden 区(shared Eden space)之中分配。如果共享 Eden 区也没有足够的空间,就会触发一次 年轻代 GC 来释放内存空间。如果 GC 之后 Eden 区依然没有足够的空闲内存区域,则对象就会被分配到老年代空间(Old Generation)。
各种垃圾收集器的实现细节虽然并不相同,但总体而言,垃圾收集器都专注于两件事情:
- 查找所有存活对象
- 抛弃其他的部分,即死对象,不再使用的对象。
第一步,记录(census)所有的存活对象,在垃圾收集中有一个叫做 标记(Marking) 的过程专门干这件事。
标记 阶段完成后,GC 进行下一步操作,删除不可达对象。
删除不可达对象(Removing Unused Objects)
各种 GC 算法在删除不可达对象时略有不同,但总体可分为三类:清除(sweeping)、整理(compacting)和复制(copying)。[下一小节] 将详细讲解这些算法。
Java 对象的创建过程
类加载检查:遇到一条 new 指令,指定实例化哪个类,检查该类是否已经加载完成。如果没有,先执行类加载操作。
分配内存:类加载完成,即类加载检查通过后,在堆中为实例对象划分空间,分配内存。根据不同的垃圾回收机制,如果存在内存碎片,即堆内存不规整,虚拟机会维护一个列表分配一块连续的存储空间。如果不存在内存碎片,虚拟机会使用分界指针找到空闲的内存区域来分配内存空间。
初始化零值:虚拟机将所分配的所有内存空间全部初始化零值,实现了对象实例的成员属性有默认值,不赋初始值就能直接使用。
设置对象头:要确保如何根据实例对象找到该对象对应的类,需要设置对象头。对象头中包括了类信息、GC 分代收集年龄、对象哈希码等内容。
执行构造方法:按照程序员意愿初始化对象,至此,Java 对象创建完成。
MySQL
MySQL 默认的 InnoDB 引擎中,索引数据结构是 B+树。索引按数据结构分类可以分为 B 树、B+树、Hash 表等。
索引的运作原理?自平衡的多叉树,按照索引键实现快速检索数据。有主键就用主键作索引键,再者用非空且唯一字段,或者生成一个隐式自增 id 作为索引键。
聚簇索引和非聚簇索引,回表查询,覆盖索引。
MySQL 索引为什么用 B+树?B+树的数据结构特点,都是自平衡树多叉树
- 它只有叶子节点存放数据,非叶子节点只存放索引键(能存放更多的索引键高度更加低,结构更加“矮胖”,磁盘 IO 次数会更少;单点查询,波动更小)
- 叶子节点构成有序链表(范围查询,更快)
- (插入和删除效率更高,有冗余节点,非叶子节点都是冗余节点,不会发生复杂的变化)
如何创建索引?
1 | |
主键索引,唯一索引,普通索引,联合索引什么是最左匹配原则?索引失效的原因有哪些?索引下推是什么?
什么时候需要创建索引?
- 索引的优点:最大的好处就是提高查询速度。
- 缺点:占用的物理空间大;数据量增大、数据的增删改,使得创建索引和维护索引更耗时
所以索引也要在合适的场景下使用。比如字段有唯一性限制的,编码;经常用于作查询条件的,多个字段还可以建立联合索引,提高查询速度;频繁用于排序的字段。表数据量很少、字段频繁更新、区分度不大(男女),就不需要创建索引了。
如何优化索引呢?
当然是使用执行计划分析语句了,explain
- 使用覆盖索引,在指定字段上创建索引,尽量减少回表操作;
- 防止索引失效,模糊匹配、联合索引不遵循最左匹配原则、在查询条件中对索引列做了计算、函数、类型转换等操作,都会发生索引失效,走全表扫描。
执行一条 SQL 语句,期间发生了什么?
一条简单的 select 查询语句,它的执行流程是这样的:
MySQL 架构分为两层:
- Server 层:负责建立连接、分析执行 SQL 语句
- 存储引擎层:负责数据的存储和提取(InnoDB 成为 MySQL 的默认存储引擎,支持并默认使用 B+树索引)
执行过程:
- 连接器:经过 TCP 三次握手,启动 MySQL 服务,验证用户名和密码,获取用户操作权限。默认空闲连接时常为八小时,长短连接。
1 | |
- 查询缓存:键值对保存形式,键为 SQL 查询语句,值为 SQL 语句查询结果。很鸡肋,表频繁更新,查询缓存会被清理,MySQL 8.0 删除了查询缓存。
- 解析 SQL:解析器,词法分析,检查字符串中的字段,找出关键字
select这些;语法分许,更具语法规则,判断是否满足 MySQL 语法,不满足(关键词拼写错误)就出错,满足就构建语法树。 - 执行 SQL:
- 预处理:表不存在、字段不存在
- 优化器:制定执行计划,将 SQL 语句的执行方案确定下来,比如作索引优化,使用覆盖索引避免回表查询等
- 执行器:真正开始执行 SQL 语句,与存储引擎交互。使用聚簇索引也好,使用全表扫描也罢,整体思路就是:执行器的查询过程就是一个 while 循环,会调用一个函数指针,可以理解为调用存储引擎去查询记录。根据制定的 SQL 语句执行计划,存储引擎通过 B+树结构或者全表扫描定位数据记录,将结果返回给执行器,并报告查询完毕。执行器收到存储引擎报告的查询完毕的信息,退出循环,停止查询。
这里可以了解到一个索引优化策略:索引下推。
索引下推是怎样的呢?当联合索引遇到范围查询时,会停止匹配。不用索引下推的话,执行过程是这样的:存储引擎根据指定的 SQL 查询计划,根据联合索引的第一条索引,定位到该记录获取主键值,回表查询整行记录值,并将结果返回给 Server 层。Server 层拿到记录,会再次根据第二条索引判断该记录是否满足,满足就返回记录,不满足就跳过该记录。
使用了索引下推之后,存储引擎在根据联合索引第一条索引定位到记录获取主键值之后,不会先回表查询,而是直接根据第二条索引判断记录是否满足,不满足就直接跳过,满足后再回表查询整行记录值,最后返回结果到 Server 层。
索引下推,就是在联合索引索引失效之后,直接在存储引擎层根据所有索引,过滤出满足的条件的记录主键值之后,才进行回表查询,节省了很多回表操作。
事务
事务有哪些特性?经典的转账问题。原子性(undo log)、持久性(redo log)、隔离性(MVCC,锁机制),才能保证事务的一致性
事务一定要保证隔离性,并发事务可能会带来的问题:脏读(一个事务读到了另一个事务未提交的数据)、不可重复读(两次读取到的数据不一样)、幻读(两次读取到的记录数量不一样)。
这就要提到 SQL 标准提出的四种隔离级别:读未提交、读提交、可重复读和串行化。读提交解决了脏读,一个事务提交了之后,它所做的变更才能被其他事务看到;可重复读解决了不可重复读,事务在执行过程中看到的数据,一直跟这个事务启动时看到的是一样的。MySQL 是通过 MVCC 实现这两种隔离级别的。针对幻读,MVCC 也能解决一部分幻读,比如普通的 select 查询语句是快照读,事务在执行过程中看到的数据,一直跟这个事务启动时看到的是一样的,避免了幻读。而针对当前读,事务读取到的数据总是最新的,使用记录锁 + 间隙锁解决了幻读问题。
那么 MVCC 是如何工作的?明确两点:Read View(快照版本)和聚簇索引记录中的两个与事务有关的隐藏列。
每个事务启动之后,会生成一个 Read View,有四个重要的字段:创建该快照的事务 id、当前数据库中活跃的事务 id 列表(已启动还未提交)、i 最小的事务 id(启动最早的)、应该给到的下一个事务 id。
对于使用 InnoDB 存储引擎的数据库表,聚簇索引记录中的两个与事务有关的隐藏列:当某个事务对该记录进行改动之后,记录该事务 id;隐藏的指针,指向旧的版本记录,形成版本链,通过版本链可以找到修改前的记录。
一个事务去访问记录的时候,除了自己的更新记录可见,会这样做:
- 生成一个 Read View,先判断已经提交的事务:
- 查看该记录的 trx_id,即最近一次对该记录修改的事务 id,比较 Read View 中的 min_trx_id,小,那就是比当前最小的活跃事务都小,说明该提交记录在创建该 Read View 之前就提交了,可见的。
- 查看该记录的 trx_id,即最近一次对该记录修改的事务 id,比较 Read View 中的 max_trx_id,大于等于,那就是比应该给到的下一个事务都大,说明该提交记录在创建该 Read View 之后才提交,不可见的。
- 如果 trx_id 在这两者之间,即该事务在创建 Read View 之后启动,需要判断该事务是否提交。根据快照的活跃事务列表,,仍然活跃,说明未提交,不可见;反之可见。
这就是通过版本链来控制并发事务访问同一个记录的行为,这就是 MVCC。可重复读跟读提交隔离级别的区别就是:前者在启动事务时生成一个 Read View,在整个事务期间都在用这个 Read View,而后者是在每次读取数据时,都会重新生成一个新的 Read View。
Undo log 作用:实现事务原子性、实现 MVCC,Redo log 实现 事务的持久化;Bin log 实现数据恢复和主从同步。
网络传输安全
防止窃听,机密性
- 对称加密算法:通信双方使用唯一的密钥来加密通信数据。
问题:通信之前,如何把用来加密数据的密钥安全地传输给对方?无法保证。
- 非对称加密算法:通信双方各持有一个密钥对,公钥是公开的,私钥自己持有。使用对方的公钥加密数据,只有对方才能用私钥解密
问题:非对称算法的运算速度很慢、性能很差,如果传输过程中频繁使用非对称加密算法加密数据,网络的传输效率是很低的
- 混合加密:将对称加密算法和非对称加密算法结合,通信开始前使用双方使用非对称加密方式传输密钥,保证了密钥的安全传输,此后通信双方可以使用该密钥来加密通信数据,保证了通信数据的保密性。
防止篡改,完整性
- 摘要算法:一种特殊的单向加密的压缩算法,它能够把任意长度的数据“压缩”成固定长度、而且独一无二的“摘要”字符串,就好像是给这段数据生成了一个数字“指纹”。摘要和原数据是完全等价的,加密后的数据无法解密,不能从摘要逆推出原文。发送方把加密后的数据,使用摘要算法生成摘要,把加密数据和该摘要一同发往接收方。接收方使用同样的摘要算法对加密数据进行计算,比照生成的摘要和接受的摘要是否一致,保证了通信数据的完整性。
身份认证,真实性
数字签名:发送方要保证通信数据是真实可信的,不是别人伪造的。使用自己的私钥对摘要加密,生成数字签名。数字签名和加密数据被一同发往接收方。接收方使用发送方的公钥解密,验证签名,拿到摘要,再比对原数据验证完整性。这样就可以像签署文件一样,证明消息确实是发送方发的。
数字证书:接收方能够使用公钥验签,但是公钥是公开的。我们还缺少防止黑客伪造公钥的手段,也就是说,怎么来判断这个公钥就是发送方的公钥呢?CA(证书认证机构)具有极高的可信度,由它来为各个公钥签名,这样的公钥就是可信的。CA 对公钥的签名认证也是有格式的,不是简单地把公钥绑定在持有者身份上就完事了,还要包含序列号、用途、颁发者、有效时间等等,把这些打成一个包再签名,完整地证明公钥关联的各种信息,形成数字证书。
通信双方的数据是加密传输的,保证了数据是保密的,没有被窃听;使用摘要保证了数据的完整性,没有被篡改;使用数字签名,保证了发送方的身份是可靠的,没有被伪造;使用数字证书,保证了接收方的身份是可信的。
Redis 基础
熟悉 Redis 基础知识:什么是 Redis,Redis 为什么这么快,Redis 线程模型,Redis 内存管理,Redis 底层数据结构
Redis 缓存
熟悉常见的生产问题:缓存雪崩,缓存击穿,缓存穿透,保证 Redis 缓存和数据库的一致性(即 Redis 读写策略)
Redis 持久化
AOF 日志:
写后日志,先执行命令,后写日志,然后把日志写入内存缓冲区,在合适的时机刷入磁盘(避免写入错误的命令,减小检查开销;不会阻塞当前的写入操作)
写后日志也会带来问题:不阻塞当前写操作,但可能会阻塞后面的写操作;先执行命令后,服务挂了,日志没有及时写入。这就要研究 AOF 写入磁盘的时机了。
同步写回:每条命令执行完毕,立刻写回磁盘;每秒写回:每隔一秒把缓冲区内容写回磁盘;不写回,由操作系统判断合适的时机写回磁盘。这三种策略性能越来越好,对主线程的影响越来越小;但数据完整性越来越差,可能导致更多的数据丢失,无法及时写回磁盘。
随着写命令越来越多,AOF 文件会越来越大:文件过大,无法保存;文件过大,追加命令的效率变低;文件过大,数据恢复效率变低。
Redis AOF 重写日志。AOP 日志记录的内容就是具体的键值和命令,扫描整个日志文件,只保存最新的数据:把旧文件中的多条命令,改写为一条命令,减小日志文件体量。
AOF 重写日志也会阻塞主线程,重写的过程很有趣(一次拷贝,两个日志):
总的来说,AOF 日志文件能很好地保证数据完整性,尽最大限度减少数据丢失,但数据恢复有点慢。
RDB 快照:
直接记录某一时刻的数据,写入内存中,再写回磁盘。
我们要对哪些数据做快照?快照期间,数据还能变化吗?
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。save 会阻塞主线程,bgsave 会创建一个子线程,专门用来执行全量快照。
写时复制机制:现在保证了执行快照期间,可以不阻塞主线程。那么如何保证执行快照的同时,主线程也能正常执行写操作,变化数据呢。
写时复制机制保证快照期间数据可修改,这个过程也很有趣(拟修改,数据副本):
如何控制快照频率?频繁地执行全量快照写入磁盘,会给磁盘带来很大压力。可以执行增量快照,只写入变化的数据。这就需要记住哪些数据被修改(键值对),也会带来空间性能开销。
总的来说,RDB 快照实现了数据的快速恢复,但是不能很好的保证数据的完整性,因为频率不好把控。
混合持久化:设置合适的快照间隔,在两次快照的间隔期间,使用 AOF 日志持久化。AOF 日志能很好地解决两次快照期间的数据丢失问题,当第二次快照执行完毕,前一次 AOF 日志就可以直接清空,使用新的 RDB 快照进行快速回复就行了。这个方法既能享受到 RDB 文件快速恢复的好处,又能享受到 AOF 只记录操作命令、尽可能保证数据不丢失的简单优势。
Redission 分布式锁
解决问题:分布式锁,即分布式系统中的锁,主要用于在分布式系统中控制共享资源的访问。
主要基于 Redis 的 setnx 命令实现,还使用 lua 脚本保证了释放锁的原子性。
实现原理:
多个客户端同时竞争锁。客户端在尝试获取锁时,向 Redis 发送 setnx 命令,设置一个随机的 UUID 作为 value。如果设置成功,则说明该客户端抢到锁了,可以执行临界区的代码。如果设置失败,客户端可以选择等待一段时间再次获取,或者直接立即返回。临界区代码执行完毕,该客户端需要释放锁,使用 lua 脚本实现正确释放锁,保证释放锁的原子性。为了防止执行过程中崩溃导致锁无法及时释放,还实现了锁的自动续期机制。使用定时任务,当客户端持有锁时,延长锁的过期时间。用户释放锁,就取消定时任务,直接释放锁。
使用步骤:根据 key 创建锁对象,并在临界区代码前后分别调用 lock()和 unlock()方法来获取和释放锁。
Reddssion 分布式限流
解决问题:在分布式系统中,对系统的访问进行限流,以避免过多的请求导致系统崩溃。
主要基于 Redis 的 list 数据结构实现,还使用 lua 脚本保证获取和释放令牌的原子性。
实现原理:
当客户端请求到达,会向 Redis 发送一个 lua 脚本尝试获取令牌,即往 list 数据结构中添加一个元素,list 容量反映了令牌发放的数量。客户端成功获取到令牌,就可以进行接下来的操作。如果 list 已满,即达到最大容量,客户端就获取不到令牌。此时客户端可以选择等待、重试。为了防止令牌堆积,实现了令牌的过期机制,当令牌存在的时间超过一定阈值,就会自动移除令牌。
使用步骤:根据 key 创建限流器对象,设置每秒生成多少令牌,刷新间隔为多少,调用 tryAcquire()方法尝试获取令牌。
常见的限流算法:主要包括计数器限流、滑动窗口限流、漏桶限流和令牌桶限流。这些算法都用于控制接口或服务的访问频率,以避免系统过载或崩溃。
- 计数器限流
- 原理:在固定时间段内记录并限制接口调用的次数。例如,设定每分钟只能调用 100 次接口。
- 实现:每次接口被调用时,计数器加 1。如果当前时间与第一次调用时间的间隔不超过设定时间段(如 1 分钟),且计数器超过限定的次数(如 100 次),则拒绝新的调用。
- 缺陷:在时间段临界值附近,如果请求密集,可能导致单位时间内调用次数超过限流次数。
- 滑动窗口限流
- 原理:以时间窗口为滑动单位,记录并限制在窗口时间内的接口调用次数。
- 实现:窗口随时间滑动,每次检查当前时间窗口内的调用次数是否超过限定值。
- 优点:解决了计数器限流在临界值附近的问题。
- 漏桶限流
- 原理:将请求比作水,漏桶比作系统处理能力。无论流入多少水,漏桶流出的水是恒定的。
- 实现:请求按照固定速率流出,当请求流入速率超过漏桶的流出速率时,多余的请求会被拒绝。
- 特点:限制了请求的流出速率,平滑了突发请求。
- 令牌桶限流
- 原理:系统以固定速率往令牌桶中添加令牌,每次请求需要消耗一个令牌。
- 实现:如果请求到来时桶中有令牌,则消耗一个令牌并处理请求;否则,拒绝请求。
- 特点:允许一定程度的突发流量,只要桶中有令牌就可以处理请求。
这些限流算法各有特点,选择哪种算法取决于具体的业务场景和需求。例如,计数器限流实现简单但可能存在临界值问题;滑动窗口限流解决了临界值问题但实现相对复杂;漏桶限流平滑了突发请求但可能限制了系统的处理能力;令牌桶限流则允许突发请求并提供了较好的灵活性。
Redission 分布式 session
当然,基于 Redis 的分布式 Session 是一种解决分布式系统中 Session 共享问题的方案。下面我尽量用简单明了、通俗易懂的方式为您介绍。
首先,我们要明白什么是 Session。Session 简单来说,就是服务器为每一个客户端(如浏览器)创建的会话,用来保存用户的状态信息。在传统的单机系统中,Session 信息通常保存在服务器的内存中。
然而,当我们的系统变成分布式系统,也就是说有多个服务器节点时,问题就出现了。因为每个节点都是独立的,它们之间的 Session 信息并不共享。这就会导致一个用户从一个节点登录后,访问另一个节点时却需要重新登录,因为那个节点没有他的 Session 信息。
为了解决这个问题,我们可以使用 Redis 来实现分布式 Session。Redis 是一个高性能的内存数据库,可以作为共享存储来保存 Session 信息。
基于 Redis 的分布式 Session 的原理是这样的:当用户在一个节点上登录时,服务器会在 Redis 中为这个用户创建一个 Session,并保存用户的状态信息。然后,服务器会把这个 Session 的 ID 返回给客户端(通常是放在 Cookie 里)。接下来,无论用户访问哪个节点,这个节点都会从 Redis 中根据 Session ID 获取用户的 Session 信息,从而知道用户的状态。
这种方式的好处是,所有的 Session 信息都保存在 Redis 这个共享的存储中,所以无论用户访问哪个节点,都能获取到正确的 Session 信息。这就实现了 Session 的共享,解决了分布式系统中的 Session 问题。
总的来说,基于 Redis 的分布式 Session 是一种高效、可靠的解决方案,能够让我们在分布式系统中方便地管理用户的会话状态。
定时任务的原理
简单来说,@Scheduled 注解在 Spring 框架中就像一个定时钟,你可以告诉它每隔多少时间或者按照什么规律来执行某个方法。当 Spring 应用启动时,它会检查哪些方法上使用了这个注解,并按照设定的规则自动去调用这些方法。这样,你就可以很方便地实现定时任务,比如每天定时发送邮件、每小时检查一次数据库等,而不需要手动去编写复杂的线程和调度逻辑。
在 Java 中,@Scheduled 注解通常与 Spring 框架一起使用,用于实现定时任务。这个注解提供了一种简洁的方式,使得开发者可以很容易地配置定时任务,而无需手动创建和管理线程。
以下是 @Scheduled 注解的一些关键点及其工作原理:
- 注解定义:
@Scheduled是 Spring 框架中的一个注解,它用于标记一个方法作为定时任务。这个注解可以定义任务的执行频率、开始延迟等。 - 配置:
为了使用@Scheduled注解,你需要在 Spring 配置中启用任务调度功能。这通常通过在配置类上添加@EnableScheduling注解来完成。 - 任务注册:
当 Spring 容器启动时,它会扫描所有带有@Scheduled注解的方法,并将这些方法注册为定时任务。 - 任务调度器:
Spring 内部使用一个任务调度器(例如,基于 Java 的ScheduledThreadPoolExecutor)来管理这些定时任务。调度器会根据@Scheduled注解中定义的规则(如固定速率、固定延迟或 Cron 表达式)来安排任务的执行。 - 线程管理:
调度器使用一个线程池来执行这些任务,这意味着多个定时任务可以并发执行。线程池的大小和配置可以根据需要进行调整。 - 异常处理:
如果定时任务在执行过程中抛出异常,Spring 会捕获这个异常并记录它。你可以配置异常处理器来进一步处理这些异常,例如,发送通知或记录到日志文件中。 - 动态性:
虽然@Scheduled注解提供了一种静态的方式来定义定时任务,但 Spring 还提供了更高级的功能,如动态地创建和修改定时任务。这通常通过编程方式使用TaskScheduler接口来实现。
下面是一个简单的示例,展示了如何使用 @Scheduled 注解来创建一个定时任务:
1 | |
在这个例子中,reportCurrentTime 方法会被 Spring 每隔 5 秒调用一次,因为我们在 @Scheduled 注解中设置了 fixedRate = 5000(以毫秒为单位)。
总之,@Scheduled 注解提供了一种声明式的方式来创建和管理定时任务,使得开发者能够专注于业务逻辑,而无需过多关注任务的调度和执行细节。
TCP 三次握手 / 四次挥手扩展问题
TCP 连接三次握手的过程是怎样的?
TCP 是面向连接的协议,使用 TCP 前必须建立连接。
- 一开始,客户端和服务端都处于 CLOSE 状态。
- 服务端主动监听某端口,进入 LISTEN 状态。
- 客户端随机初始化序号(c1),即 TCP 报文首部的序号字段,同时把同步标志位置为 1,表示这是一个 TCP 连接请求报文。接着客户端把该报文发往服务端,表示向服务端发起连接,之后客户端进入同步已发送状态。
- 服务端收到客户端的 TCP 连接请求报文。
- 服务端首先初始化序号(s1),即 TCP 报文首部的序号字段;然后初始化确认应答号为 c1 + 1,表示该序号之前的内容全部接收完成,期望收到该序号之后的报文。同时把同步标志位和确认标志位置为 1,表示这是一个 TCP 连接响应报文。最后把该报文发往客户端,表示已收到并回应客户端的连接请求,之后服务端进入同步已接收状态。
- 客户端收到服务端的 TCP 连接响应报文。
- 客户端还要向服务端发送最后一个应答报文,这个报文是普通的 TCP 报文。客户端设置确认应答号为 s1 + 1,同时设置确认标志位为 1,表示这是一个普通的 TCP 应答报文。客户端把该报文发往服务端,这次报文可以携带客户端的数据到服务端,之后客户端进入已连接状态。
- 服务端收到客户端的应答报文后,也进入已连接状态。
一旦完成三次握手,双方都处于已连接状态,连接建立完成,客户端和服务端就可以相互发送数据了。
TCP 四次挥手的过程是怎样的?
双方都可以主动断开连接,以客户端主动断开连接为例。
- 客户端打算关闭连接,把终止标志位置为 1,表示这是一个连接终止请求报文。客户端把该报文发往服务端,进入终止等待 1 状态。
- 服务端收到该报文,向客户端发送普通的 TCP 应答报文,之后服务端进入关闭等待状态。
- 客户端收到服务端的应答报文,之后进入终止等待 2 状态。
- 等待服务端处理完数据,服务端再把终止标志位置为 1,向客户端发送连接终止请求报文,之后服务端进入最后等待状态。
- 客户端收到该报文,再次往服务端发送一个普通的 TCP 应答报文,之后客户端进入时间等待状态。
- 服务端收到该应答报文,之后进入关闭状态,至此服务端已经完成了连接的关闭。
- 客户端在经过 2MSL(最大报文存活时间)后,自动进入关闭状态,至此客户端也完成了连接的关闭。
JWT 原理
Session / Cookie
性能优化方案
代码层面的优化:
算法改进
- 选择更高效的算法来替代低效的算法。例如,使用快速排序替代冒泡排序,使用哈希表替代线性搜索等。
- 尽量减少时间复杂度较高的操作,如嵌套循环和递归调用。
数据结构选择
- 根据数据的特点和使用场景,选择合适的数据结构。例如,如果需要频繁地插入和删除元素,可以使用链表或哈希表;如果需要保持元素的顺序,可以使用数组或平衡二叉树。
- 避免不必要的数据结构转换和复制操作,以减少内存消耗和 CPU 时间。
代码精简与复用
- 移除冗余代码和重复逻辑,提高代码的可读性和可维护性。
- 使用函数和模块来封装重复使用的代码,减少代码的重复编写和调试工作。
系统层面的优化:
缓存策略
- 利用缓存技术来存储和复用频繁访问的数据,减少对数据库或远程服务的访问次数。
- 选择合适的缓存策略,如 LRU(最近最少使用)算法,来管理缓存空间,确保缓存中的数据是最有价值的。
并发控制
- 利用多线程或多进程技术,实现任务的并行处理,提高系统的吞吐量和响应速度。
- 使用合适的并发控制机制,如锁、信号量或条件变量,来避免并发访问导致的数据冲突和死锁问题。
网络优化
优化网络传输协议和参数设置,减少网络延迟和丢包率。
使用压缩算法对传输的数据进行压缩,减少网络带宽的占用。
数据库层面的优化:
索引设计
- 根据查询需求和表结构,设计合适的索引。选择具有高选择性的列作为索引键,以提高查询效率。
- 定期分析和优化索引的使用情况,避免索引失效或冗余索引导致的性能问题。
查询优化
- 优化 SQL 查询语句,减少不必要的 JOIN 操作、子查询和聚合函数的使用。
- 使用数据库提供的查询执行计划工具,分析查询的执行过程,找出性能瓶颈并进行优化。
分区与分片
- 对于大型数据库表,可以使用分区技术将数据分成多个部分,提高查询和管理效率。
- 在分布式数据库系统中,可以使用分片技术将数据分散到多个节点上,实现负载均衡和水平扩展。
数据库配置与参数调优
- 根据硬件环境和业务特点,调整数据库的配置参数,如缓冲区大小、连接池大小等,以获得最佳的性能表现。
- 监控数据库的性能指标,如响应时间、吞吐量、CPU 利用率等,及时发现和解决性能问题。
需要注意的是,性能优化是一个持续的过程,需要不断地对系统进行监控和分析,并根据实际情况进行调整和优化。同时,在优化过程中要权衡利弊,避免过度优化导致系统复杂性和维护成本的增加。
设计模式
什么是设计模式
设计模式是软件设计中常见的问题解决方案的归纳总结,是在特定情境下的经验性的解决方案。
它们被广泛接受和应用于软件开发中,旨在提高代码的可重用性、可维护性和灵活性。
七大原则
设计模式的七大原则是作为设计模式的基础准则,可以用来指导设计模式的选择和应用。这些原则是:
- 单一职责原则(SRP):一个类应该只有一个引起它变化的原因。
- 开放-封闭原则(OCP):软件实体(类、模块、函数等)应该对扩展是开放的,对修改是封闭的。
- 里氏替换原则(LSP):子类型必须能够替换其基类型,而不会影响程序的正确性。
- 接口隔离原则(ISP):建立最小的依赖,不要依赖不需要的接口。
- 依赖倒置原则(DIP):依赖于抽象,而不是具体实现。
- 迪米特法则(LoD):一个对象应该对其他对象保持最少的了解。
- 组合/聚合复用原则(CARP):优先使用组合和聚合,而不是继承。
分类
设计模式根据功能和用途可以分为三大分类:
- 创建型设计模式:这些模式关注对象的创建机制,主要包括工厂模式、抽象工厂模式、单例模式、原型模式和建造者模式等。
- 结构型设计模式:这些模式关注如何组合和使用对象,主要包括适配器模式、装饰器模式、代理模式、组合模式、享元模式和桥接模式等。
- 行为型设计模式:这些模式关注对象之间的通信和协作方式,主要包括策略模式、模板方法模式、观察者模式、迭代器模式、访问者模式、命令模式、备忘录模式、状态模式和解释器模式等。
这些分类和原则将设计模式划分到更具体的范畴,并提供了指导设计和实施设计模式的准则。理解和应用这些原则和分类有助于开发人员更好地使用设计模式来解决问题。
Maven
Maven 学习:
基础:Maven 的下载安装、IDEA 创建 Maven 项目,了解 Maven 项目结构
依赖管理:依赖坐标(GAV)、依赖范围管理、Maven 的工作原理、Maven 的生命周期
依赖冲突:依赖的传递性、自动解决依赖冲突、排除依赖
分模块开发:通过 mvn install 命令,将不同的 Maven 项目安装到本地仓库,其他工程就能通过 GAV 坐标引入该工程了。实现业务模块拆分,简化项目管理,提高代码复用性,方便团队协作
聚合工程:一个项目允许创建多个子模块,多个子模块组成一个整体,可以统一进行项目的构建。公共的依赖、配置、插件等,都可以配置在父工程里。父工程可以定义可选依赖<dependencyManagement>,该标签里的依赖项,子工程可选择使用。子工程可以使用<optional>true</optional>开启隐藏依赖,该依赖不会传递给其他工程。Maven聚合工程可以对所有子工程进行统一构建,而不需要像传统的分模块项目一样,需要挨个打包、测试、发布。
Maven 属性:在 <properties> 标签下,自定义属性(依赖版本,项目环境属性,Java 环境变量等)。
多环境配置:
多模块开发:
① 简化项目管理,拆成多个模块/子系统后,每个模块可以独立编译、打包、发布等;
② 提高代码复用性,不同模块间可以相互引用,可以建立公共模块,减少代码冗余度;
③ 方便团队协作,多人各司其职,负责不同的模块,Git管理时也能减少交叉冲突;
④ 构建管理度更高,更方便做持续集成,可以根据需要灵活配置整个项目的构建流程
巩固复习了 Maven,终于明白了 API 接口开放平台的运作原理。
Maven 是什么,Maven 是一个项目构建和管理工具,是 Apache 下的一个纯 Java 开发的开源项目,我们现在基本都在使用 Maven 来构建和管理 Java 项目,当然也有其他类似的的项目构建和管理工具,比如 Gradle。(2023/12/01 晚)
那么我们为什么要使用 Maven 呢?使用它有什么好处?我们首先要认识到,在没有使用 Maven 工具之前,项目构建和管理存在很多问题:
- 依赖关系管理困难:在手动构建项目时,需要手动下载和添加项目所需的依赖库,这不仅耗时而且容易出错。此外,如果项目中有多个模块,需要确保每个模块都有正确的依赖版本,这需要花费大量时间和精力。
- 构建过程繁琐:在没有自动化构建工具的情况下,开发人员需要手动编译、测试和打包项目。这不仅耗时,而且容易出错。此外,如果项目中有多个模块,需要分别构建每个模块,这会进一步增加构建的复杂性。
- 项目结构五花八门:在没有统一的项目构建和管理规范的情况下,每个项目可能会有自己独特的项目结构,这使得项目之间的协作和交流变得困难。
- 版本控制和发布困难:在没有 Maven 之前,版本控制和发布需要手动完成,这不仅耗时而且容易出错。此外,如果项目中有多个模块,需要分别发布每个模块,这会进一步增加发布的复杂性。
- 团队协作效率低下:在没有 Maven 之前,团队成员之间需要手动共享项目文件和依赖库,这不仅效率低下,而且容易出错。此外,如果项目中有多个模块,需要分别管理每个模块的代码和依赖库,这会进一步降低团队协作的效率。
总之,没有 Maven 之前,项目构建和管理可能会面临许多痛点,包括依赖关系管理困难、构建过程繁琐、项目结构五花八门、版本控制和发布困难以及团队协作效率低下等问题。而 Maven 等自动化构建工具的出现有效地解决了这些问题,提高了项目构建和管理的效率和准确性。
那么 Maven 项目的结构是怎样的呢?通常包括以下几个部分:
src:包含了项目所有的源代码和资源文件以及测试代码。其中 src/main/java 这个目录下储存 java 源代码,src/main/resources 储存主要的资源文件,比如 spring 的 xml 配置文件和 log4j 的 properties 文件,src/test/java 存放测试代码。target:编译后内容放置的文件夹。pom.xml:这是 Maven 的基础配置文件,也是 Maven 项目核心配置文件,相当关键,用于配置项目的基本信息、依赖范围管理、解决依赖冲突、实现分模块开发、多环境配置
其他相关的还有:Maven 的私服搭建、配置 Maven 镜像源、Maven 的生命周期
Mybatis 工作流程
加载配置文件:读取 MyBatis 的配置文件(mybatis-config.xml),包含全局配置信息:运行环境、数据库连接信息。加载映射文件,包含将要执行的 SQL 语句。
构建会话工厂:即创建 SqlSessionFactory:使用配置文件创建 SqlSessionFactory 对象,该对象负责创建创建会话对象 SqlSession。
创建会话对象,根据会话工厂 SqlSessionFactory 获取 SqlSession 对象,SqlSession 包含了执行 SQL 的所有方法,代表一次会话。
执行映射文件:使用会话对象 SqlSession ,根据 Mybatis 提供的 API(增删改查语句),执行映射文件中定义的 SQL 语句。
处理操作结果:解析传入的参数,构建最终要执行的 SQL 语句,获取数据库连接,执行 SQL,将 SQL 执行的结果进行转换,映射为 Java 对象或集合。
返回处理结果:释放与数据库的连接资源,关闭会话对象 SqlSession,返回最终的处理结果。
结合工作实践来讲,MyBatis 所具备的亮点可总结为如下三个方面。
第一,MyBatis 本身就是一款设计非常精良、架构设计非常清晰的持久层框架,并且 MyBatis 中还使用到了很多经典的设计模式,例如,工厂方法模式、适配器模式、装饰器模式、代理模式等。 在阅读 MyBatis 代码的时候,你也许会惊奇地发现:原来大师设计出来的代码真的是一种艺术。所以,从这个层面来讲,深入研究 MyBatis 原理,甚至阅读它的源码,不仅可以帮助你快速解决工作中遇到的 MyBatis 相关问题,还可以提高你的设计思维。
第二,MyBatis 提供了很多扩展点,例如,MyBatis 的插件机制、对第三方日志框架和第三方数据源的兼容等。 正由于这种可扩展的能力,让 MyBatis 的生命力非常旺盛,这也是很多 Java 开发人员将 MyBatis 作为自己首选 Java 持久化框架的原因之一,反过来促进了 MyBatis 用户的不断壮大。
第三,开发人员使用 MyBatis 上手会非常快,具有很强的易用性和可靠性。这也是 MyBatis 流行的一个很重要的原因。当你具备了 MySQL 和 JDBC 的基础知识之后,学习 MyBatis 的难度远远小于 Hibernate 等持久化框架。
什么是 Spring MVC?
MVC 是一种常用的软件设计思想,它将业务逻辑、数据模型和界面显示分离,使得代码更加清晰、可维护。
SpringMVC 是 Spring 框架中的一个重要模块,它基于 MVC(Model-View-Controller)设计模式,是一个用于构建 Web 应用程序的轻量级 Web 框架。
在 SpringMVC 中,Controller(控制器)负责处理用户请求并返回响应。
Model(模型)是数据的表示,它包含了应用程序的状态和业务逻辑。
View(视图)是用户界面的表示,它负责显示数据给用户。
Spring MVC 工作原理
客户端(浏览器)发送请求, DispatcherServlet拦截请求。
DispatcherServlet 根据请求信息调用 HandlerMapping 。HandlerMapping 根据 URL 去匹配查找能处理的 Handler(也就是我们平常说的 Controller 控制器) ,并会将请求涉及到的拦截器和 Handler 一起封装。
DispatcherServlet 调用 HandlerAdapter适配器执行 Handler 。
Handler 完成对用户请求的处理后,会返回一个 ModelAndView 对象给DispatcherServlet,ModelAndView 顾名思义,包含了数据模型以及相应的视图的信息。Model 是返回的数据对象,View 是个逻辑上的 View。
ViewResolver 会根据逻辑 View 查找实际的 View。
DispaterServlet 把返回的 Model 传给 View(视图渲染)。
把 View 返回给请求者(浏览器)。
当用户发送请求到 Web 服务器时,SpringMVC 的 DispatcherServlet(前端控制器)会拦截这些请求,HandlerMapping(处理映射器)根据请求的 URL 映射 / 匹配查找能处理的 Handler(也就是我们平常说的 Controller 控制器),并调用 HandlerAdapter(处理适配器)执行相应的 Controller。Controller 会调用业务逻辑层(通常是 Service 层)来处理请求,获取相应的数据,然后将数据传递给 Model。Model 将数据传递给 View 进行渲染;最后,View 将渲染结果返回给用户。
总的来说,SpringMVC 通过 MVC 设计模式将 Web 应用程序的不同部分进行分离,使得代码更加清晰、可维护,提高了开发效率。同时,SpringMVC 还提供了丰富的功能和特性,如数据绑定、异常处理、拦截器等,帮助开发人员更好地构建 Web 应用程序。
RequestMapping
在 SpringMVC 中,@RequestMapping是一个用于映射 Web 请求到特定处理器函数(通常是 Controller 中的方法)的注解。它可以定义 URL 路径、HTTP 请求方法(GET、POST 等)、请求头、请求参数等,使得 Controller 能够处理特定的请求。
请求控制器
请求控制器在 SpringMVC 中通常指的是 Controller 类及其中的方法。它们负责处理用户的请求,调用业务逻辑,并返回视图或数据。Controller 是 MVC 模式中的 C 部分,负责接收请求和发送响应。
拦截器
拦截器(Interceptor)在 SpringMVC 中用于在请求处理过程中拦截用户的请求和响应,可以在请求到达 Controller 之前或响应返回给用户之前执行一些预处理或后处理操作。例如,可以用来进行权限验证、日志记录、性能监控等。
请求参数封装
在 SpringMVC 中,请求参数可以自动封装到 Controller 方法的参数中。SpringMVC 利用参数绑定机制,可以将请求中的参数(如 GET 请求的查询参数、POST 请求的请求体等)自动绑定到 JavaBean、Map 或其他数据类型中,简化了参数的获取和处理。
请求过滤器
请求过滤器(Filter)是 Servlet 规范中的一部分,与 SpringMVC 不完全相关,但经常在 Java Web 应用程序中使用。过滤器可以在请求到达 Servlet 容器中的任何资源之前或之后执行代码。它们常用于处理编码问题、记录日志、压缩响应、身份验证等。
全局异常处理
在 SpringMVC 中,可以通过实现HandlerExceptionResolver接口或使用@ControllerAdvice和@ExceptionHandler注解来全局处理异常。这样,当 Controller 中的方法抛出异常时,可以统一捕获和处理这些异常,避免在 Controller 中分散处理异常代码,提高了代码的可维护性。
RestFul 风格
RestFul 风格是一种 Web 服务的设计和开发方式,它强调资源的表示、状态转移和 HTTP 方法的正确使用。在 RestFul 风格的 Web 服务中,每个 URL 代表一个资源,不同的 HTTP 方法(GET、POST、PUT、DELETE 等)用于操作这些资源。这种设计方式使得 Web 服务更加简洁、直观和易于理解。
JSON 框架
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。在 Java Web 应用程序中,常用的 JSON 框架有 Jackson、Gson 等。这些框架可以帮助 Java 应用程序将 Java 对象转换为 JSON 格式的字符串,或者将 JSON 格式的字符串转换为 Java 对象,从而方便地与前端进行数据交换。
Bean 的生命周期
简单总结 Spring Bean 生命周期流程:
- 实例化:启动 Spring 应用,IOC 容器为所有已声明的 Bean 创建一个实例
- 属性赋值:实例化后,Spring 通过反射机制给 Bean 的属性赋值
- 调用 Bean 的初始化方法:调用 Bean 配置的
@PostConstruct、afterPropertiesSet方法或者init-method指定的方法 - Bean 运行期:Bean 已经准备好被程序使用了,它已经被初始化并赋值完成
- Bean 销毁:当容器关闭时,调用
Bean的销毁方法
Spring 的启动流程
Spring 的启动流程大致有以下几个关键步骤:
加载配置文件:Spring 在启动时,首先加载其 XML 格式的配置文件,配置文件中定义了 Spirng 容器中管理的 Bean 属性以及依赖关系。
解析配置文件:加载完配置文件,由 XML 解析器将将配置文件中的 Bean 定义转化为 Spring 容器可以理解和使用的内部数据结构。
创建并初始化 Bean:根据解析得到的 Bean 定义,Spring 开始创建相应的 Bean 实例,进行初始化,包括设置属性值、处理依赖关系。
注册 Bean:Bean 初始化完成会被注册到 Spring 容器中,其他 Bean 就可以通过容器获取这些 Bean 引用进行使用,这就是依赖注入。
至此,当所有的 Bean 都创建并初始化完成后,Spring 启动完成,可以对外提供服务了。
Spring Boot 的启动流程跟 Spring 的启动流程在核心逻辑上基本上是一致的,但存在一些差异:
自动化配置:传统的 Spring 应用程序,需要在 appicationContext.xml 或者 mybatis-config,xml 中手动配置数据源,包括数据库 URL、用户名、密码等,很繁琐。而 Spring Boot 提供了自动配置功能:导入 jar 包依赖,在 resource 下的 yaml / properties 配置文件里简单地写清楚配置。Spring Boot 就会自动创建已经配置好的数据源 Bean,不再需要手动配置数据源。
简化依赖管理:Spring Boot 提供了一系列 starter 依赖,只需要在项目中引入 starter 依赖,Spring Boot 便会自动引入所需的库。不再需要自己处理复杂的依赖关系,比如解决依赖冲突、版本兼容等问题,大大简化了依赖管理。
内嵌服务器:不同于 Spring 需要开发者手动配置和部署 Web 服务器。Spring Boot 内嵌了常用的 Web 服务器(如 Tomcat、Jetty 等),使得开发者无需单独配置和部署 Web 服务器。只需导入 jar 包依赖(GAV 坐标),在 resource 的 yaml / properties 配置文件中指定监听端口,在启动 Spring Boot 应用程序时,内置服务器就会自动启动并监听相应的端口。
快速启动:由于 Spring Boot 的自动化配置、简化依赖管理、内嵌服务器等,只需要直接运行 @SpringBootApplication 标注的启动类,就可以一键启动 Spring Boot 应用程序。
简化部署:通过一行命令:java -jar 等即可快速将 Spring Boot 应用程序打包成一个可执行的 JAR 或 WAR 文件。再将打包好的文件复制到目标服务器上,通过一行命令就可以一键启动,部署变得十分简单和方便。
Spring 自动配置原理
Starter 依赖,集成第三方,启动类,扫描并加载所在包以及子包的 Bean,开启自动配置功能,发现并加载自动配置类,根据条件注解等,实现自动装配。
@SpringApplication是 Spring Boot 的核心注解,它包含了@SpringBootConfiguration、@EnableAutoConfiguration和@ComponentScan等注解。
@SpringBootConfiguration:声明当前类是配置类,允许使用@Bean注解定义 bean。@EnableAutoConfiguration:根据项目的依赖关系,自动配置 Spring Boot 项目。@ComponentScan:让 Spring 扫描到 Configuration 类并把它加入到程序上下文。
SpringBoot 的自动装配原理主要基于 Spring 框架的依赖注入和条件化 Bean 机制,并结合 SpringBoot 的特定功能和设计原则实现的。
首先,SpringBoot 通过引入一系列 starter 依赖,使得开发者能够便捷地集成各种第三方库和框架。每个 starter 都包含了一系列预定义的配置和 Bean 定义,用于简化特定功能的集成过程。
在 SpringBoot 应用启动时,@SpringBootApplication注解起到了关键作用。这个注解实际上是一个复合注解,其中@EnableAutoConfiguration是实现自动装配的核心。它告诉 SpringBoot 开启自动配置功能。
SpringBoot 的自动配置功能通过加载META-INF/spring.factories文件来发现并加载各种自动配置类。这些自动配置类使用条件注解(如@ConditionalOnClass、@ConditionalOnProperty等)来确定是否应该创建和配置特定的 Bean。条件注解允许根据类路径、属性设置、Bean 是否存在等条件来启用或禁用自动配置。
当 SpringBoot 启动时,它会扫描这些自动配置类,并根据条件注解的判断来决定是否创建和注册相应的 Bean 到 Spring 容器中。如果某个自动配置类满足其条件注解指定的条件,那么它定义的 Bean 就会被创建并注入到 Spring 容器中,从而完成自动装配过程。
除了自动配置类,SpringBoot 还利用了一些核心组件来实现自动装配,如AutoConfigurationImportSelector和SpringFactoriesLoader。AutoConfigurationImportSelector负责从spring.factories中加载自动配置类,并根据条件进行筛选。SpringFactoriesLoader则用于加载META-INF/spring.factories文件中定义的配置。
通过这种方式,SpringBoot 能够自动配置应用的很多方面,如数据库连接、消息队列、Web 服务等,从而大大简化了开发者的配置工作,提高了开发效率。
需要注意的是,虽然自动装配能够极大地简化配置工作,但在某些情况下,开发者仍然需要手动配置一些 Bean 或覆盖自动配置的默认设置,以满足特定的业务需求。因此,理解 SpringBoot 的自动装配原理并熟悉其配置方式,对于开发者来说是非常重要的。
Spring 的扩展点
API 项目介绍
API 项目介绍:分为四个模块:api-core,实现用户管理、接口管理、接口调用等;api-gateway,做统一的访问控制、流量染色、用户鉴权,完成统一登录校验、API 签名校验、接口调用统计和请求响应前后的日志处理;api-client,自主设计对外提供接口服务;api-common,抽象公共接口 / 方法、公共实体类。
使用 Maven 聚合工程管理子模块,都需要在本地 install。接口调用的逻辑:请求 api-core 的接口调用服务:首先校验参数,判断接口是否存在。获取当前登录用户,拿到 ak 和 sk,以此作为参数构建 SDK 客户端。SDK 客户端通过封装请求参数(包含用户信息、调用接口信息),使用 Hutool 工具包,发送请求到网关。
网关实现全局过滤,获取请求头的一切信息:请求参数、请求路径、请求来源地址等。做 API 签名校验,鉴定用户身份;根据请求路路径和方法判断接口状态,是否存在,是否发布或下线;设置 ip 黑白名单,只允许当前服务器的请求可以通过;流量染色,给请求添加统一的请求头。完成一系列校验之后,将该合法请求转发给真正的接口服务,处理接口调用,返回响应。最后在 haddleReponse 响应处理器中,完成接口调用统计等业务逻辑,更新相关字段,比如用户剩余调用次数、接口调用总次数等。返回响应,结束整个调用流程。
不希望引入复杂的业务逻辑,为减小网关模块体量,遵循单一原则,抽象公共业务逻辑和公共实体类到 api-common 模块。引入 Dubbo 轻量的 RPC 框架,用 EnabbleDubbo、@DubboReference、@DubboServie 等,使用 Nacos 做注册中心,实现服务注册。网关服务作为消费者实现服务拉取。实现服务间方法调用。
微服务架构
从单体应用迁移到微服务架构:
单体应用线上发布和部署效率低下、团队协作开发成本高、系统可用性差。
相较于单体应用,微服务实现了更细粒度的服务拆分、更高效的服务部署和独立维护、提供了更清晰的服务治理方案。
要实现从单体应用迁移到微服务架构,就要做好服务化拆分,设计服务间调用。明确微服务架构的基本组件:服务描述、注册中心、服务框架、服务监控、服务追踪、服务治理。
CAP 理论
- CAP 定理指出,一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个基本需求。
- 在设计分布式系统时,需要根据实际需求权衡这三个属性。
- 大多数分布式系统会选择牺牲一致性(CP)或可用性(AP)来满足分区容错性。
CAP 理论是分布式系统设计中的一个基本原则,它涉及的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)和 Partition Tolerance(分区容错性)这三个目标之间的关系。CAP 理论断言,在一个分布式系统中,最多只能同时满足其中的两个目标,而无法同时满足三个。
具体来说,一致性要求分布式系统中的所有数据备份在同一时刻具有相同的值。可用性则意味着在集群中一部分节点故障后,集群整体仍然能够响应客户端的读写请求,即系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。分区容错性则是指分布式系统虽然由多个节点组成,但对外应该表现为一个整体,即使内部某个节点或网络出现故障,系统对外也不应出现异常。
根据 CAP 理论,存在两种常见的模式供系统设计者选择:CP 模式和 AP 模式。在 CP 模式下,系统会优先保证数据的一致性和分区容错性,这意味着在网络分区发生时,系统可能会拒绝部分请求以确保数据的一致性。这种模式适用于对数据一致性要求较高的场景,如金融系统。而在 AP 模式下,系统则会优先保证可用性和分区容错性,即使在网络分区发生时,系统仍然可以接受请求并提供部分功能,这种模式适用于对可用性要求较高的场景。
因此,在设计分布式系统时,需要根据实际应用场景和需求来权衡这三个目标,从而选择适合的 CAP 策略。
服务发布和引用
注册中心(服务注册和发现)
在微服务架构下,主要有三种角色:服务提供者(RPC Server)、服务消费者(RPC Client)和服务注册中心(Registry),三者的交互关系请看下面这张图,我来简单解释一下。
RPC Server 提供服务,在启动时,根据服务发布文件 server.xml 中的配置的信息,向 Registry 注册自身服务,并向 Registry 定期发送心跳汇报存活状态。
RPC Client 调用服务,在启动时,根据服务引用文件 client.xml 中配置的信息,向 Registry 订阅服务,把 Registry 返回的服务节点列表缓存在本地内存中,并与 RPC Sever 建立连接。
当 RPC Server 节点发生变更时,Registry 会同步变更,RPC Client 感知后会刷新本地内存中缓存的服务节点列表。
RPC Client 从本地缓存的服务节点列表中,基于负载均衡算法选择一台 RPC Sever 发起调用。
RPC 调用
想要完成 RPC 调用,你需要解决四个问题:
- 客户端和服务端如何建立网络连接?
- 服务端如何处理请求?(选择合适的通信框架比如 Netty,解决客户端与服务端如何建立连接、管理连接以及服务端如何处理请求的问题)
- 数据传输采用什么协议?(选择合适的通信协议比如 HTTP,解决客户端和服务端采用哪种数据传输协议的问题)
- 数据该如何序列化和反序列化?(多种序列化格式比如 Java 原生序列化、JSON、XML、Thrift,解决客户端和服务端采用哪种数据编解码的问题)
Socket 通信
Socket 通信是基于 TCP/IP 协议的封装,建立一次 Socket 连接至少需要一对套接字,其中一个运行于客户端,称为 ClientSocket ;另一个运行于服务器端,称为 ServerSocket 。就像下图所描述的,Socket 通信的过程分为四个步骤:服务器监听、客户端请求、连接确认、数据传输。
- 服务器监听:ServerSocket 通过调用 bind()函数绑定某个具体端口,然后调用 listen()函数实时监控网络状态,等待客户端的连接请求。
- 客户端请求:ClientSocket 调用 connect()函数向 ServerSocket 绑定的地址和端口发起连接请求。
- 服务端连接确认:当 ServerSocket 监听到或者接收到 ClientSocket 的连接请求时,调用 accept()函数响应 ClientSocket 的请求,同客户端建立连接。
- 数据传输:当 ClientSocket 和 ServerSocket 建立连接后,ClientSocket 调用 send()函数,ServerSocket 调用 receive()函数,ServerSocket 处理完请求后,调用 send()函数,ClientSocket 调用 receive()函数,就可以得到得到返回结果。
服务监控
服务监控主要包括四个流程:数据采集、数据传输、数据处理和数据展示
监控对象有用户端监控、接口监控、资源监控、基础监控,监控指标有请求量、响应时间和错误率
服务追踪
在微服务架构下,由于进行了服务拆分,一次请求往往需要涉及多个服务,每个服务可能是由不同的团队开发,使用了不同的编程语言,还有可能部署在不同的机器上,分布在不同的数据中心。
如果有一个系统,可以跟踪记录一次用户请求都发起了哪些调用,经过哪些服务处理,并且记录每一次调用所涉及的服务的详细信息,这时候如果发生调用失败,你就可以通过这个日志快速定位是在哪个环节出了问题,这个系统就是今天我要讲解的服务追踪系统。
服务治理
在一次服务调用过程中,服务提供者、服务消费者、注册中心、网络都有可能出问题。我们要尽可能保证服务调用成功,这就是服务治理。
服务治理可以从很多方面考虑:
- 从服务健康状态考虑。要做到服务节点管理,比如使用心跳检测机制,这种机制要求服务提供者定时的主动向注册中心汇报心跳
- 从服务节点访问优先级考虑。一般情况下,服务提供者节点不是唯一的,多是以集群的方式存在。要选择合适的负载均衡策略,充分利用机器的性能。
- 从调用的健康状态考虑。服务调用并不总是一定成功的,对于服务调用失败的情况,需要有手段自动恢复,来保证调用成功。
Dubbo 的工作原理
Dubbo 框架的工作原理主要基于服务注册与发现、远程调用、负载均衡以及服务监控等核心机制。以下是 Dubbo 框架工作原理的详细解释:
- 服务注册与发现:
- 服务提供者(Provider)在启动时,会将自己提供的服务接口信息注册到注册中心(Registry)。注册中心是一个服务目录框架,用于服务的注册和服务事件的发布和订阅。
- 服务消费者(Consumer)在启动时,会向注册中心订阅自己所需的服务。注册中心会返回服务提供者地址列表给消费者。如果服务提供者地址列表有变更,注册中心会基于长连接推送变更数据给消费者。
- 远程调用:
- Dubbo 采用了代理机制来实现远程调用。服务消费者通过代理对象来调用远程服务,而代理对象会负责将调用请求序列化为网络传输格式,并通过网络通信框架发送给服务提供者。
- 服务提供者接收到请求后,会进行反序列化,并执行相应的服务逻辑。执行结果同样会被序列化为网络传输格式,并返回给服务消费者。
- 负载均衡:
- Dubbo 提供了多种负载均衡策略,如随机、轮询、一致性哈希等。服务消费者在调用远程服务时,会根据负载均衡策略从服务提供者地址列表中选择一个合适的服务提供者进行调用。
- 如果调用失败,服务消费者可以根据配置选择重试或切换到其他服务提供者。
- 服务监控:
- Dubbo 提供了服务监控中心(Monitor),用于统计服务的调用次数、调用时间等日志信息。服务提供者和消费者在内存中累计调用次数和调用时间,并定时发送统计数据到监控中心。
- 监控中心可以对这些数据进行分析和可视化展示,帮助开发人员了解服务的运行状况,并进行性能调优和故障排查。
总的来说,Dubbo 框架通过注册中心实现了服务的动态注册与发现,通过代理机制实现了远程调用的透明化,通过负载均衡策略保证了服务的可用性和性能,通过监控中心提供了服务的运行状况分析和优化手段。这些机制共同构成了 Dubbo 框架的核心工作原理,使得分布式系统中的服务调用更加高效、可靠和易于管理。
Dubbo 是一个高性能、轻量级的开源 Java RPC 框架,主要用于服务之间的远程调用。其实现原理和流程如下:
实现原理:
- 代理机制:Dubbo 通过 Java 的动态代理或 CGLIB 代理生成服务消费者端的代理对象。当消费者调用服务时,实际上是调用这个代理对象。
- 注册中心:服务提供者将服务注册到注册中心(如 Zookeeper、Nacos 等),服务消费者从注册中心订阅所需的服务。注册中心负责服务的发现和通知。
- 序列化与反序列化:Dubbo 使用特定的序列化协议(如 Hessian2、Kryo 等)将请求和响应数据进行序列化和反序列化,以便在网络中传输。
- 通信协议:Dubbo 定义了自己的通信协议,包括请求头、请求体等结构,用于服务提供者和消费者之间的通信。
流程:
- 服务提供者启动时,将服务注册到注册中心。
- 服务消费者启动时,向注册中心订阅所需的服务。
- 注册中心通知消费者可用的服务提供者列表。
- 消费者通过负载均衡策略选择一个提供者,并通过代理对象发起远程调用。
- 代理对象将调用请求序列化后发送给选定的提供者。
- 提供者接收到请求后,进行反序列化,并执行相应的服务逻辑。
- 提供者将执行结果序列化后返回给消费者。
- 消费者接收到结果后,进行反序列化,并返回给调用方。
为什么可以调用到对应服务:
Dubbo 通过注册中心实现了服务的动态发现和注册,使得服务消费者能够知道哪些服务提供者是可用的。同时,Dubbo 的代理机制和通信协议使得消费者能够通过网络调用远程服务提供者。这种机制保证了服务的透明性和可扩展性,使得消费者无需关心服务的具体位置和实现细节,只需关注服务接口即可。
Dubbo 是一个高性能、轻量级的开源 Java RPC 框架。它的核心作用是实现远程服务调用,即在不同的进程或机器之间进行通信。Dubbo 采用了服务提供者和服务消费者的角色划分,通过注册中心进行服务的注册与发现。服务提供者将服务接口实现暴露出来,并注册到注册中心;服务消费者从注册中心获取服务提供者的地址列表,然后通过代理对象调用远程服务。Dubbo 支持多种通信协议和序列化方式,可以根据不同的场景选择合适的配置。
在使用 Dubbo 时,我会先定义服务接口,并在服务提供者中实现该接口。然后,在 Dubbo 的配置文件中指定服务接口的实现类、注册中心地址等信息。服务提供者启动后,Dubbo 会自动将服务注册到注册中心。在服务消费者端,我只需要引入服务提供者的接口依赖,并在 Dubbo 的配置文件中指定所需服务的名称和注册中心地址。Dubbo 会为我们生成代理对象,通过该对象就可以像调用本地方法一样调用远程服务。
Nacos 工作原理
Nacos 的核心运作原理主要围绕服务注册与发现、配置管理、服务管理以及集群管理展开。
首先,服务注册与发现。当服务提供者启动时,它会将自身的服务信息,如 IP 地址、端口号、服务名称等,注册到 Nacos 平台。而服务消费者则通过订阅或轮询的方式,从 Nacos 平台获取可用的服务列表,以便在需要时调用这些服务。这样,服务提供者和服务消费者就可以实现动态的关联和通信。
其次,配置管理。Nacos 提供了一个集中式的配置中心,开发人员可以将各种配置信息,如数据库连接信息、系统参数等,存储在这个中心化的配置中心中。服务消费者可以实时地从配置中心获取最新的配置信息,而无需重启应用程序。这大大提高了系统的灵活性和可维护性。
再者,服务管理。Nacos 提供了丰富的服务管理功能,包括服务的启停、监控、日志查看等。开发人员可以通过 Nacos 的界面或 API 对服务进行实时的管理和控制,确保服务的稳定运行。
最后,集群管理。Nacos 支持服务的集群管理,通过负载均衡、容错和故障转移等机制,确保服务的可用性和可靠性。即使部分服务节点出现故障,Nacos 也能自动调整服务调用策略,确保服务的连续性和稳定性。
总的来说,Nacos 通过集中式的服务注册与发现、配置管理、服务管理以及集群管理等功能,为分布式系统提供了一套高效、稳定且易于管理的解决方案。这使得开发人员能够更专注于业务逻辑的实现,而无需过多关注服务的部署、管理和维护等琐碎事务。
首先,Nacos 是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它的注册中心功能主要实现了服务的注册与发现。当服务提供者启动时,它会将自己的服务信息注册到 Nacos 注册中心;服务消费者启动时,会从 Nacos 注册中心获取所需服务提供者的地址列表。这样,服务消费者就可以通过负载均衡策略选择一个服务提供者进行通信。同时,Nacos 还支持服务的健康检查、服务上下线通知等功能,以确保服务的可用性和稳定性。
在实际使用中,我会根据项目的需求配置 Nacos 服务端的地址和端口,然后在服务提供者和消费者中引入 Nacos 的客户端依赖。在服务提供者中,我会配置服务名称、版本等信息,并启动服务注册。在服务消费者中,我会配置所需服务的名称和版本,然后启动服务发现。通过 Nacos 的 API,我可以方便地获取服务提供者的地址列表,并进行负载均衡调用。
通过结合使用 Nacos 注册中心和 Dubbo RPC 框架,我能够构建出高效、稳定且易于扩展的分布式系统。在实际项目中,我会根据业务需求进行配置和优化,确保服务的性能和可靠性。同时,我也会关注相关的技术动态和最佳实践,不断学习和提升自己的能力。
希望以上回答能够满足您的要求,如果有进一步的问题或需要更多的细节,请随时提问。
Elasticsearch
什么是 Elasticsearch?
Elasticsearch 是一个基于 Lucene 构建的开源、分布式、RESTful 搜索引擎。它设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Elasticsearch 的运作原理主要基于以下几个关键概念:
- 节点与集群:每个节点是一个运行在单个机器上的独立的 Elasticsearch 实例。集群中的节点通过互相通信和协调工作来实现数据的分布式存储和搜索。这种分布式的架构使得 Elasticsearch 能够处理大规模的数据集,并提供高可用性和容错能力。
- 索引与文档:在 Elasticsearch 中,索引是逻辑上相关的文档集合,类似于关系数据库中的数据库。文档是可以被索引和搜索的基本信息单位,它由一组字段组成,每个字段包含一个数据值。文档使用 JSON 格式表示,可以包含各种字段的复杂结构。
- 分片与副本:为了支持横向扩展和处理大规模数据集,Elasticsearch 将索引分割成多个分片。每个分片是一个独立的索引,可以分布在不同的节点上。分片可以并行处理搜索请求,并在集群中进行负载均衡。此外,为了数据的冗余备份和故障恢复,Elasticsearch 还提供了副本机制,副本分布在不同的节点上,确保数据的可靠性和高可用性。
- 倒排索引:Elasticsearch 使用倒排索引来加速搜索过程。倒排索引与传统的正向索引不同,它不是按照文档的 ID 来建立索引,而是以词为单位,记录每个词在哪些文档中出现以及出现的位置等信息。这样,当用户进行搜索时,Elasticsearch 可以快速定位到包含相关词的文档,并返回结果。
在运作过程中,用户将数据提交到 Elasticsearch 数据库中,数据首先经过分词控制器进行分词处理,然后将分词结果和权重信息存入倒排索引中。当用户发起搜索请求时,Elasticsearch 根据倒排索引快速定位到相关文档,并根据权重进行排名和打分,最终将结果呈现给用户。由于 Elasticsearch 采用了近实时搜索技术,从建立索引到索引可以被搜索之间的延迟通常很小,通常是 1 秒左右,这使得 Elasticsearch 能够满足实时搜索的需求。
总的来说,Elasticsearch 通过分布式架构、倒排索引以及实时搜索等技术,实现了高效、可靠的大规模数据搜索和处理能力。
Elasticsearch 的运作原理
首先,我们要理解 Elasticsearch 的基本架构和核心概念。Elasticsearch 是一个基于 Lucene 构建的分布式搜索和分析引擎,它的核心是由多个节点组成的集群,每个节点上运行着 Elasticsearch 的实例。
数据写入过程:
- 创建索引:在 Elasticsearch 中,索引是一个包含多个文档的集合。当我们需要存储数据时,首先会定义一个索引,并为它配置相应的设置和映射。
- 写入文档:向 Elasticsearch 写入数据是通过发送 HTTP 请求来实现的,通常是将 JSON 格式的文档发送到指定的索引中。每个文档都有一个唯一的 ID,用于在索引中标识它。
- 分词与倒排索引:当文档被写入 Elasticsearch 时,它首先会通过分词器进行分词处理。分词器将文档中的文本分解成单独的词或词组(称为词条)。然后,Elasticsearch 为每个词条创建倒排索引。倒排索引是一个数据结构,它记录了每个词条在哪些文档中出现,以及出现的位置和频率等信息。这样,当执行搜索查询时,Elasticsearch 可以快速定位到包含相关词条的文档。
搜索查询过程:
- 发送查询请求:用户通过发送 HTTP 请求来执行搜索查询。查询请求可以包含各种条件,如关键词、范围、过滤器等。
- 解析查询:Elasticsearch 接收到查询请求后,会解析查询语句,将其转换为内部可执行的查询对象。
- 搜索倒排索引:Elasticsearch 使用解析后的查询对象在倒排索引中进行搜索。它会查找与查询条件匹配的词条,并获取包含这些词条的文档列表。
- 排序与评分:根据查询条件,Elasticsearch 会对文档进行排序和评分。排序可以根据字段的值进行升序或降序排列,而评分则基于文档与查询的匹配程度进行计算。
- 返回结果:最后,Elasticsearch 将搜索结果的文档列表返回给用户。这个结果列表通常包含文档的 ID、字段值以及评分等信息。
在整个过程中,Elasticsearch 的分布式架构发挥了重要作用。通过将索引分成多个分片,并在集群中的不同节点上进行存储和查询,Elasticsearch 能够实现水平扩展,处理大规模的数据集。同时,通过复制分片到不同的节点,Elasticsearch 还提供了高可用性和容错能力,确保数据的可靠性和稳定性。
此外,Elasticsearch 还支持实时搜索和近实时搜索。实时搜索意味着在文档被写入后立即就可以进行搜索,而近实时搜索则允许在文档写入后有极短的延迟时间(通常是几百毫秒到几秒)后进行搜索。这种实时或近实时的能力使得 Elasticsearch 非常适合于需要快速响应的搜索和分析场景。
总结来说,Elasticsearch 通过分词、倒排索引、分布式存储和查询等技术,实现了高效、可靠的大规模数据搜索和分析功能。
RabbitMQ 消息队列
RabbitMQ 实现消息队列的功能,主要依赖于其内部的几个核心组件以及它们之间的交互。以下是 RabbitMQ 实现消息传递的基本过程:
- 生产者(Producer)与交换机(Exchange)
- 生产者负责创建并发送消息。这些消息不是直接发送到队列,而是首先发送到交换机。
- 交换机负责接收来自生产者的消息,并根据其类型、路由键(Routing Key)或其他属性来决定这些消息应该发送到哪些队列。RabbitMQ 支持多种类型的交换机,如直接交换机、主题交换机等,每种类型都有其特定的路由逻辑。
- 队列(Queue)
- 队列是存储消息的容器。交换机根据路由规则将消息发送到相应的队列。
- 队列是持久的,即使 RabbitMQ 服务器重启,队列中的消息也不会丢失(当然,这取决于队列和消息的持久化设置)。
- 消费者(Consumer)
- 消费者是从队列中接收并处理消息的程序。
- 消费者通过订阅队列来接收消息。一旦有消息到达队列,且消费者处于活跃状态,消息就会被传递给消费者进行处理。
- 绑定(Binding)
- 绑定是交换机和队列之间的连接关系。它定义了交换机如何将消息路由到队列。
- 通过定义绑定,可以实现灵活的路由策略,使得消息能够按照预期的方式流动。
- 确认机制(Acknowledgment)
- 为了确保消息的可靠传递,RabbitMQ 提供了消息确认机制。当消费者成功处理一条消息后,它会发送一个确认信号给 RabbitMQ,RabbitMQ 收到确认后才会从队列中删除该消息。
- 如果消费者在处理消息时失败或崩溃,而没有发送确认信号,RabbitMQ 会认为该消息没有被成功处理,并重新将其放回队列以供其他消费者处理。
- 持久化(Persistence)
- 为了确保在 RabbitMQ 服务器故障时不会丢失数据,可以将交换机、队列和消息标记为持久的。这样,即使服务器重启,这些数据也会被保留下来。
综上所述,RabbitMQ 通过交换机、队列、消费者、绑定、确认机制和持久化等功能,实现了消息的可靠传递和系统的解耦。这使得 RabbitMQ 成为一个强大且灵活的消息队列系统,广泛应用于各种分布式系统和微服务架构中。
项目扩展思考
2024 年 2 月 20 日
正如标题所说,这个栏目就暂时放置一些我在逐步完善 MemorySearch 忆搜阁 项目过程中的扩展思考,为后续的学习提供思路:
ES 删除策略
Elasticseach 数据存储在硬盘内,如何选择合适的删除策略,清理过期数据呢
Elasticsearch 一个索引内可以存放的数据条数并没有固定的上限,它主要取决于以下几个因素:
- 磁盘空间:索引的大小受限于可用磁盘空间。Elasticsearch 会将索引数据存储在磁盘上,因此磁盘空间是限制索引大小的主要因素。
- 分片配置:Elasticsearch 通过分片(shards)来水平扩展数据,每个索引可以包含一个或多个分片。默认情况下,一个索引会有 5 个主分片(primary shards),但可以在创建索引时指定不同的分片数。分片数越多,索引可以容纳的数据量就越大,但同时也会增加集群的管理复杂性。
- 文档大小:单个文档的大小也会影响索引的容量。虽然 Elasticsearch 支持非常大的文档,但过大的文档可能会降低写入性能并增加索引的存储需求。
当索引达到其存储限制时,Elasticsearch 不会直接拒绝新的数据写入。相反,它会根据配置的策略来处理这种情况。常见的删除策略包括:
- 基于时间的删除:使用索引生命周期管理(ILM)策略,根据时间戳字段自动删除旧数据。例如,可以设置一个策略,使得索引在创建后的一定时间后被删除。
- 基于大小的删除:当索引达到一定的大小时,可以配置 ILM 策略来删除旧数据,或者通过手动干预来删除不需要的数据。
- 基于文档数量的删除:虽然 Elasticsearch 不直接基于文档数量限制索引大小,但可以通过删除旧文档来管理索引的大小。这可以通过编写删除查询或使用 ILM 策略来实现。
- 滚动索引:在某些场景中,可以使用滚动索引(rolling indices)模式,即定期创建新的索引来存储新数据,而旧索引可以被删除或归档。这种策略常见于日志收集和分析场景。
在实际应用中,建议根据业务需求和数据特点来选择合适的删除策略。同时,监控 Elasticsearch 集群的健康状况和性能,确保数据的有效管理和系统的稳定运行。
Elasticsearch 默认不提供自动删除旧数据的策略。默认情况下,索引会一直存在,直到你手动删除它们或者磁盘空间耗尽。但是,Elasticsearch 提供了索引生命周期管理(ILM)功能,允许你定义自己的删除策略。
当你创建一个索引时,除非你明确指定了 ILM 策略,否则该索引不会受到任何自动删除策略的影响。这意味着你需要主动管理索引的生命周期,包括决定何时删除不再需要的索引。
在 ILM 中,你可以定义策略来根据索引的年龄、大小或其他条件自动将索引移动到只读状态,并最终删除它们。但是,如果你不配置 ILM 或使用默认的 ILM 策略,索引将不会自动被删除。
因此,为了有效地管理 Elasticsearch 中的索引和数据,建议配置适当的 ILM 策略,以确保旧数据在不再需要时被自动删除,从而释放磁盘空间并优化集群性能。
确保 ES 文档的 id 唯一性
如何确保 Elasticsearch 文档的 id 唯一性?
在 Elasticsearch 中记录搜索词,每条搜索词作为一个文档,保证数据 ID 的唯一性是非常重要的。Elasticsearch 使用文档 ID 来唯一标识每个文档,因此你需要确保每个搜索词都被分配一个唯一的 ID。以下是一些方法来实现这一点:
使用 UUID:
UUID(Universally Unique Identifier)是一种广泛使用的唯一标识符生成方法。你可以为每个搜索词生成一个 UUID,并将其用作文档的 ID。UUID 具有全局唯一性,可以确保即使在不同的系统或时间点上生成的 ID 也不会冲突。1
2
3
4import java.util.UUID;
String uniqueId = UUID.randomUUID().toString();
// 使用uniqueId作为文档的ID基于时间戳和搜索词生成 ID:
如果你的搜索词量不是特别大,并且你希望 ID 具有一定的可读性或者顺序性,你可以考虑使用时间戳和搜索词来生成 ID。例如,你可以将时间戳和搜索词拼接起来,并可能加上一个前缀或后缀来确保唯一性。1
2
3
4
5
6import java.time.Instant;
String timestamp = Instant.now().toString().replace("-", ""); // 移除时间戳中的"-"字符
String searchTerm = "你的搜索词";
String uniqueId = "search-" + timestamp + "-" + searchTerm;
// 使用uniqueId作为文档的ID使用自增 ID:
如果你的搜索词量不是很大,并且你不需要跨多个节点或集群保证唯一性,你可以考虑使用自增的 ID。但是,请注意,如果你有多个节点或者需要扩展集群,自增 ID 可能会导致 ID 冲突。1
2
3AtomicInteger counter = new AtomicInteger(0);
String uniqueId = "search-" + counter.getAndIncrement();
// 使用uniqueId作为文档的ID使用哈希函数:
如果你希望 ID 更短,你可以考虑使用哈希函数(如 MD5 或 SHA-1)对搜索词进行哈希处理,并将结果作为文档的 ID。但请注意,哈希函数可能会产生相同的输出(即哈希碰撞),尽管这种可能性非常低。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
String searchTerm = "你的搜索词";
try {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] hashBytes = md.digest(searchTerm.getBytes());
StringBuilder hexString = new StringBuilder();
for (byte b : hashBytes) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) hexString.append('0');
hexString.append(hex);
}
String uniqueId = hexString.toString();
// 使用uniqueId作为文档的ID
} catch (NoSuchAlgorithmException e) {
// 处理异常
}
无论你选择哪种方法,都需要确保生成的 ID 在整个 Elasticsearch 集群中是唯一的。如果你使用了多节点集群,并且需要在不同节点之间保证 ID 的唯一性,那么使用 UUID 或基于时间戳和搜索词的方法通常是更好的选择。
异步编程为什么更快
异步编程更快的原因主要有以下几点:
- 非阻塞性:异步编程允许程序在等待某个操作完成时继续执行其他任务,而不是阻塞在那里等待。这样可以避免因等待某个耗时操作而导致整个程序的阻塞,提高了程序的执行效率。
- 并行处理:异步编程可以充分利用多核处理器的优势,将多个任务分配给不同的处理器核心同时执行,从而提高程序的执行速度。
- 减少资源占用:异步编程可以减少程序在等待 I/O 操作(如网络请求、文件读写等)完成时的资源占用,例如内存和 CPU。这样可以让程序在等待这些操作时执行其他任务,提高资源利用率。
- 简化代码逻辑:异步编程可以将复杂的同步代码逻辑转换为更简单、易于理解的异步代码,降低了代码的复杂度和维护成本。
总之,异步编程通过提高程序的执行效率、充分利用多核处理器和减少资源占用等方面的优势,使得程序在处理耗时操作时能够更快地完成任务。
系统性能优化
当然,除了异步编程优化数据插入性能外,还可以考虑以下几种技术上的优化策略来进一步提升系统性能:
- 内存缓存
- 使用缓存库:如 Redis 或 Memcached,将频繁访问的数据(如热门作者或诗词)缓存在内存中,减少对数据库的访问次数。
- 本地缓存:对于单个应用实例,可以使用如 Google 的 Guava Cache 或 EhCache 等本地缓存库,缓存部分数据以减少数据库访问。
- 数据库优化
- 索引优化:确保数据库表的关键字段(如作者、标题等)有适当的索引,以加速查询速度。
- 批量操作:继续利用批量插入操作来减少数据库交互次数,提高数据写入效率。
- 数据库连接池:使用连接池来管理数据库连接,避免频繁地创建和销毁连接,减少资源消耗。
- HTTP 请求优化
- 请求合并:对于多个小的 HTTP 请求,可以考虑合并成一个大的请求,以减少网络延迟和服务器处理时间。
- 请求缓存:对于不经常变动的数据,可以在客户端或代理服务器上缓存 HTTP 响应,避免重复请求。
- 并发控制
- 限流与降级:在并发量过高时,通过限流策略保护核心资源,同时可以采用降级策略,暂时关闭部分功能以保证整体系统的稳定性。
- 解析优化
- 流式解析:使用如 Jsoup 的流式解析功能,避免一次性加载整个 HTML 文档到内存中,减少内存消耗。
- 日志与监控
- 性能监控:通过日志记录和性能监控工具(如 Prometheus, Grafana 等)持续跟踪系统性能,发现瓶颈并进行针对性优化。
- 系统架构优化
- 微服务化:将系统拆分为多个微服务,每个服务负责处理特定的功能,以提高系统的可扩展性和可维护性。
- 负载均衡:使用负载均衡器分发请求到多个应用实例,避免单点故障,提高系统可用性。
- 代码层面优化
- 避免 N+1 查询问题:在数据访问层优化查询逻辑,避免因为不恰当的查询策略导致的过多数据库访问。
- 使用合适的数据结构和算法:确保代码中使用高效的数据结构和算法,减少不必要的计算和资源消耗。
综上所述,通过结合多种优化策略,可以进一步提升系统的整体性能和响应速度。
单体架构升级到分布式架构
从单体架构升级到分布式架构,需要注意以下几个方面:
- 系统拆分:需要对原有的单体系统进行合理的拆分,将其分解为多个可以独立部署和运行的子系统或服务。这一过程中要考虑服务的边界划分,确保每个服务的职责单一,便于管理和维护。
- 数据一致性:在分布式系统中,数据可能会分布在不同的服务或数据库中,因此需要确保数据的一致性。这可能涉及到分布式事务的处理,以及选择合适的一致性模型(如强一致性、最终一致性等)。
- 通信机制:服务之间需要进行通信,需要选择合适的通信机制,如同步调用、异步消息队列等。同时,要考虑到网络延迟、服务可用性等因素,设计容错和重试机制。
- 服务发现与注册:在分布式环境中,服务的位置可能会动态变化,需要实现服务发现和注册机制,以便服务之间能够相互找到并通信。
- 负载均衡:为了提高系统的伸缩性和可用性,需要实现负载均衡机制,使得请求能够均匀地分发到不同的服务实例上。
- 监控与日志:分布式系统的监控和日志记录比单体系统更加复杂。需要有一套完善的监控体系来跟踪系统的性能和健康状况,同时要有集中的日志管理系统,以便于问题的定位和分析。
- 安全性:分布式系统的安全性也是一个重要考虑点。需要确保各个服务之间的通信是安全的,同时还要考虑到服务对外的 API 安全,防止未授权的访问。
- 部署与运维:分布式系统的部署和运维比单体系统更加复杂。需要考虑如何快速部署新版本的服务,以及如何处理服务间的依赖关系。
- 容灾备份:为了保证系统的高可用性,需要设计容灾备份方案,包括数据备份、服务冗余等,确保在出现故障时能够快速恢复。
- 业务改造:从单体架构向分布式架构迁移时,可能需要对现有业务逻辑进行改造,以适应新的架构模式。这可能涉及到代码重构和业务流程的调整。
- 组织文化:分布式架构的引入不仅仅是技术层面的改变,还可能影响到团队的组织文化和工作方式。团队成员需要适应新的开发、部署和运维流程。
- 技术选型:在选择分布式架构的具体实现技术时,需要考虑技术的成熟度、社区支持、学习曲线等因素,选择适合自己团队和业务需求的技术栈。
- 渐进式迁移:如果条件允许,可以考虑采用渐进式迁移的策略,逐步将单体架构中的模块转化为分布式服务,而不是一次性全面转型,这样可以减少风险和压力。
总的来说,从单体架构升级到分布式架构是一个复杂的过程,涉及到系统架构、技术选型、团队协作等多个方面。需要仔细规划和逐步实施,以确保迁移过程的平稳和系统的稳定运行。
CompletableFuture 异步编程
CompletableFuture 是 Java 8 引入的一个功能强大的类,用于异步编程和函数式编程。它提供了一种简单而灵活的方式来处理并发编程中的异步操作和结果。介绍 CompletableFuture 时,可以从以下几个方面入手:
- 基础概念:
- 解释什么是异步编程,为什么在现代应用中需要它。
- 引入
CompletableFuture的概念,并解释其与传统的Future和Callable的区别。
- 创建 CompletableFuture:
- 展示如何使用
CompletableFuture.supplyAsync和CompletableFuture.runAsync创建异步任务。 - 解释这两种方法的参数,如
Supplier和Runnable,并讨论它们的用途。
- 展示如何使用
- 链式编程:
- 展示如何使用
thenApply,thenAccept,thenCompose等方法链接多个异步操作。 - 解释这些方法的返回值类型和作用。
- 展示如何使用
- 异常处理:
- 讨论如何处理
CompletableFuture中的异常。 - 展示如何使用
exceptionally方法处理异常。
- 讨论如何处理
- 组合和合并操作:
- 介绍
allOf,anyOf和completedFuture等方法,用于组合和等待多个CompletableFuture实例。 - 讨论这些方法的使用场景。
- 介绍
- 等待结果:
- 展示如何使用
get和join方法等待异步操作的结果。 - 讨论这两种方法的区别和适用场景。
- 展示如何使用
- 取消操作:
- 解释如何使用
cancel方法取消一个异步操作。 - 讨论取消操作的限制和可能的后果。
- 解释如何使用
- 与其他并发工具的比较:
- 比较
CompletableFuture与其他并发工具(如Future,ExecutorService,RxJava等)的优缺点。
- 比较
- 最佳实践和注意事项:
- 强调避免阻塞等待异步结果的重要性。
- 讨论如何避免创建过多的线程,以及如何优雅地处理异常和取消操作。
- 实际案例:
- 提供一个或多个实际使用
CompletableFuture的案例,以展示其在实际项目中的应用。
- 提供一个或多个实际使用
最后,确保在介绍过程中结合示例代码,以便读者更好地理解和实践所学内容。
API 项目 思考:
设计更多优秀的接口,比如根据用户需求和提交的数据,调用 AI 大模型接口,在线生成图表。对于这种响应时间较长的服务,可以考虑使用异步编程,或者引入消息队列来提高系统响应速度,有效提升系统性能
客户端 SDK 的设计要保持精简,遵循相关规范,保证用户通过 SDK 调用接口服务的简洁性,提升用户体验
切实保障接口调用的性能、稳定性和可用性,可以考虑在网关增加限流和降级保护,以及严格的权限校验机制。给每个用户分配一对密钥,作为调用接口服务的凭证;对每个用户的接口调用次数加以限制;推出充值系统和订单系统,用户可充值购买接口调用次数,以享受接口调用服务
作为一个接口开放平台,目前仅提供了通过客户端 SDK 调用接口服务,应该考虑到如何便捷地添加新的接口服务、如何提高其它开发者接入平台的效率、安全性等,真正地让平台成为开放平台
现在的 客户端 SDK 仅支持下载代码至本地,在本地使用 mvn install 命令打包 SDK,在本地项目中引入 SDK 依赖即可使用
考虑在微服务网关前搭建 Nginx 网关,通过负载均衡实现高并发
多阅读官网文档,Spring Cloud Gateway、Dubbo、Ant Design Pro
你的项目 QPS 是多少?
简单知识复盘
怎么让两个线程轮流执行?使用 wait()和 notify()。一个线程执行完之后调用 notify()唤醒正在等待中的线程,自身调用 wait()进入等待状态。
static 静态变量有什么优势/缺点?节省内存空间,方便访问;数据不一致,难以理解和维护。
UDP 与 TCP 比较。无连接,不可靠,实时性较高,能容忍一定的数据丢失,不保证数据的顺序性完整性,没有序列号、确认机制、超市重传、流量控制、拥塞控制。
为什么选择 Redis?Redis 是单独的中间件,不同客户端把 session 存放在 redis 上,实现在分布式结构中的资源可见性,解决用户登录失效问题;Redis 单线程,支持 lua 脚本,保证了并发操作安全的同时,能很好地实现分布式锁;作为缓存数据库,存储热门数据,减轻数据库压力。
项目的开发流程:参考已有的产品学习了解,总结比较好的功能点。结合自己扩展的功能特色,做整体设计,经过需求分析后得到产品原型。选用合适的技术,解决具体的业务问题。
为什么使用 Dubbo RPC?首先为了减小网关模块的体量,避免引入复杂的业务逻辑,保证设计模式遵循的单一原则,决定使用 RPC 实现服务间调用。OpenFeign 的方式也考虑过,本质上是构建 HTTP 请求,发送请求去调用对外提供的服务。这种方式需要添加很多请求头,使用 JSON 序列化的效率也不高,更加适合外部服务。选用 Dubbo,基于 TCP 协议,避免无用的请求头,序列化为二进制流传输,效率高。
如何使用 RPC 框架?详细的业务流程。实现服务间交互,先说说具体的技术选型 👆 和实现原理(Nacos 注册中心、服务消费者、服务生产者等),获取用户相关信息,用户是否存在,有没有权限调用,API 签名校验是否通过;获取接口相关信息,接口是否存在,免费的还是付费的,是否发布或者已下线;做好接口调用统计,在 HaddleResponse 处理器中,发起 RPC 调用,操作数据库,用户可调用次数减少、接口被调用次数增加(如何实现?👇)。
网关保证接口可用和稳定性,隐藏真实的接口地址,请求转发。实现全局过滤,获取请求头的一切信息:请求参数、请求路径、请求来源地址等。做 API 签名校验,鉴定用户身份;根据请求路路径和方法判断接口状态,是否存在,是否发布或下线;设置 ip 黑白名单,只允许当前服务器的请求可以通过;流量染色,给请求添加统一的请求头。完成一系列校验之后,将该合法请求转发给真正的接口服务,处理接口调用,返回响应。最后在 haddleReponse 响应处理器中,完成接口调用统计等业务逻辑,更新相关字段,比如用户剩余调用次数、接口调用总次数等。返回响应,结束整个调用流程。
接口调用次数排行怎么实现?每次接口调用完成,在 haddleResponse 处理器中发起 RPC 请求,更新数据库。并发请求下,会出现统计不准确的问题。没有在业务层面加锁,数据库并发写,压力太大。可以使用 Redis,Sorted Set 数据结构,score 权值实现排序。不使用加锁影响效率,同时单线程 Redis 很好解决并发问题。持久化。
怎么实现 SDK 的?实现过程 + 实现原理。添加依赖,编写自动配置类,添加 @Configuration 注解;在 resouce / MEATA-INF 下的 spring.factories 文件下,指定自动配置类的全路径;绑定配置文件,@ CofigurationProperties 加载配置文件,映射为 Java 类;执行 mvn install 命令,安装到本地仓库,其他模块导入依赖后,编写配置文件中的 ak,sk,即可拿到客户端 SDK 对象,发起接口调用。
实现原理就是 Spring Boot 自动装配机制。
一个对象的创建流程?(最好能接着说类加载机制;最好能说出创建对象有几种方式:反射,序列化,unsafe 类实现 Cloneable 接口重写 clone 方法)
arrayList 的 remove 是怎么实现的?从列表中删除指定元素,有多种重载形式。按值删除,遍历整个列表寻找给定元素,找到就删除,同时将后面元素向前移动一个位置。按索引删除,直接定位到给定索引的元素,执行删除操作。
Java 8 的新特性有用过哪些?stream 流,Date/Time API,BigDecimal,Optional 容器等。
有了解过 HashMap 的 put() 和扩容机制吗?有了解过 ArayList 的 add() 和扩容机制吗?
对于开源框架的深入理解,比如 Spring 的启动流程、Spring IOC 创建流程、Bean 的生命周期、Spring MVC 处理流程、Spring Boot 的启动流程和自动配置原理、Spring Boot 的扩展点等。了解了这些,就更能认识到 Spring Boot 的简洁和快速。
设计模式的七大原则:
- 单一职责原则:一个类应该只有一个引起变化的原因。
- 开放封闭原则:软件实体(类、模块、函数等)应该是可扩展的,但是不可修改。
- 里氏替换原则:子类必须能够替换其基类。
- 接口隔离原则:使用多个专门的接口,而不使用单一的总接口,客户端不应该依赖它不需要的接口。
- 依赖倒置原则:要依赖于抽象,不要依赖于具体。
- 迪米特法则(最少知道原则):一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立。
- 合成复用原则:尽量使用合成/聚合的方式,而不是使用继承。
for 循环使用迭代器删除元素
解决慢 SQL 问题
解决慢 SQL 问题通常涉及以下步骤:
- 使用 SQL 执行计划分析查询。
- 优化索引,确保查询能够高效利用索引。
- 避免在查询中使用 SELECT *,只选择需要的字段。
- 减少 JOIN 操作或优化 JOIN 条件。
- 避免在 WHERE 子句中使用非 SARGable 函数。
- 考虑对数据库进行分区或分片。
- 监控数据库性能,定期审查和调整 SQL 语句。
分布式锁的实现方式
分布式锁的实现方式有多种,包括但不限于:
- 基于数据库实现,如使用数据库的排他锁。
- 基于 Redis 实现,利用 Redis 的 setnx 命令或 RedLock 算法。
- 基于 Zookeeper 实现,利用 Zookeeper 的临时顺序节点和 watch 机制。
线程池的核心参数通常包括
- corePoolSize:核心线程数,即使线程处于空闲状态,也不会被销毁,除非设置了 allowCoreThreadTimeOut。
- maximumPoolSize:线程池允许的最大线程数。
- keepAliveTime:线程空闲时间,当线程数大于核心线程数时,此为终止前多余的空闲线程等待新任务的最长时间。
- workQueue:用于存放待执行的任务的阻塞队列。
拒绝策略有四种:
- AbortPolicy:直接抛出 RejectedExecutionException 异常。
- CallerRunsPolicy:用调用者所在的线程来执行任务。
- DiscardOldestPolicy:丢弃阻塞队列中等待最久的任务,然后重新尝试执行任务。
- DiscardPolicy:直接丢弃任务,不处理。
JVM 如何判断对象存活
JVM 通过垃圾回收器来判断对象是否存活。主要使用两种算法:引用计数法和可达性分析。现代 JVM 主要使用可达性分析算法。
可达性分析的基本思路是:从一系列称为“GC Roots”的对象开始向下搜索,搜索走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的。
在 Java 中,可作为 GC Roots 的对象包括:
- 虚拟机栈中引用的对象,如方法中的局部变量。
- 方法区中类静态属性引用的对象。
- JNI(Java Native Interface)中引用的对象。
- 本地方法栈中 JNI 引用的对象。
当进行垃圾回收时,JVM 会遍历这些 GC Roots,然后递归地搜索它们所引用的对象,标记为存活。未被标记的对象则被认为是不可达的,即垃圾对象,可以被回收。
ConcurrentHashMap 的实现原理及扩容机制
实现原理:
ConcurrentHashMap(简称 CHM)是 Java 并发包java.util.concurrent下提供的一个线程安全的 HashMap 实现。- CHM 内部将数据分为多个段(Segment),每个段其实就是一个小的 HashMap,每个段都有自己的锁。这样,多线程并发访问时,不同段的数据可以并行处理,从而提高并发性能。
- 每个段内部使用链表+红黑树的组合来存储键值对,当链表长度超过一定阈值(TREEIFY_THRESHOLD,默认为 8)时,会转化为红黑树来优化查询性能;当树的大小小于 UNTREEIFY_THRESHOLD(默认为 6)时,会退化为链表。
扩容机制:
- 当 CHM 中的元素数量超过当前容量的某个阈值时(通常是容量的 0.75 倍),会触发扩容。
- 扩容时,会创建一个新的数组,其容量是原数组的两倍。
- 然后遍历原数组中的每个段,重新计算每个键值对的索引位置,并放入新数组中。
- 为了保证线程安全,这个过程会采用分段锁的方式,确保同一时间只有一个线程在扩容某个段。
GC 算法:
- 标记-清除(Mark-Sweep): 分为两个阶段,标记阶段从根对象开始递归访问所有可达对象并标记它们,清除阶段则回收未被标记的对象。优点是简单,但缺点是会产生内存碎片。
- 复制(Copying): 将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。优点是简单且没有内存碎片,但缺点是内存利用率低。
- 标记-整理(Mark-Compact): 标记阶段和标记-清除算法相同,但在清除阶段会将所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。优点是解决了内存碎片问题,但缺点是效率相对较低。
- 分代收集(Generational Collection): 根据对象存活周期的不同将内存划分为几块。一般是把 Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清除”或者“标记-整理”算法来进行回收。
优缺点:
- 标记-清除: 优点是实现简单,缺点是会产生内存碎片,需要定期进行内存碎片整理。
- 复制: 优点是避免了内存碎片问题,缺点是内存利用率低,只适合对象存活率较低的场景。
- 标记-整理: 优点是解决了内存碎片问题,且内存利用率高,但缺点是算法效率相对较低。
- 分代收集: 优点是结合了多种算法的优点,根据对象的存活周期选择合适的算法,提高了垃圾收集的效率。缺点是实现相对复杂。
对象的生命周期:
- 创建阶段: 使用 new 关键字或者反射 API 等方式创建对象实例。
- 使用阶段: 对象被程序引用并使用,执行相应的操作。
- 不可达阶段: 当对象没有任何引用指向它时,该对象就变得不可达了。此时,它将被垃圾收集器标记为可回收。
- 回收阶段: 在垃圾收集器运行期间,不可达的对象会被清理掉,释放其占用的内存空间。
项目中的数据权限怎么实现
数据权限的实现通常涉及到以下几个方面:
- 基于角色的权限控制: 为不同的角色分配不同的数据访问权限。例如,管理员可以访问所有数据,而普通用户只能访问自己的数据。
- 基于数据字段的权限控制: 对于某些敏感字段,可以设定只有特定角色或用户才能查看或修改。
- 数据行级权限控制: 根据某些条件(如用户 ID、部门 ID 等)来控制用户能够访问的数据行。
- 权限校验: 在用户访问数据时,系统需要进行权限校验,确保用户只能访问其被授权的数据。这通常涉及到在业务逻辑中加入权限判断的代码,或者通过数据库层面的视图、存储过程等来实现。
- 日志记录: 记录用户对数据的访问和操作行为,以便在发生问题时进行审计和追踪。
Java 中的锁机制是用于处理多线程并发情况下数据一致性的重要工具。在 Java 中,有多个层面的锁机制,包括 synchronized 关键字和 Lock 接口等。
- synchronized 关键字
- 这是 Java 语言内置的一种锁机制。
- 它可以用来实现对代码块或方法的同步控制,确保同一时刻只有一个线程可以执行被锁定的代码块或方法。
- 当一个线程获取锁时,它会将对象头中的标志位设置为锁定状态,其他线程在尝试获取锁时,如果发现标志位已被设置为锁定状态,就会进入等待状态,直到锁被释放。
- Lock 接口
- 提供了比 synchronized 更灵活的锁机制。
- 它提供了显式的锁获取和释放操作,允许更细粒度的控制。
- Lock 接口有多种实现,包括 ReentrantLock 等。
在 Java 的锁机制中,还可以根据锁的特性进行进一步分类:
- 公平锁与非公平锁
- 公平锁:按照线程申请锁的顺序来获取锁,类似于日常排队。
- 非公平锁:线程获取锁的顺序并不是按照申请锁的顺序,可能存在插队现象。
- 可重入锁(递归锁)
- 允许同一线程在外层方法获取锁后,进入内层方法时仍能持有该锁并继续运行。
- 自旋锁
- 当线程尝试获取锁失败时,不是立即阻塞等待,而是采用循环的方式尝试获取锁。
- 这可以减少线程上下文切换的消耗,但当循环次数过多时,会消耗 CPU 资源。
- 读写锁
- 分为写锁和读锁。写锁是独占锁,一次只能被一个线程持有;读锁是共享锁,可被多个线程持有。
- 读写锁适用于读操作远多于写操作的场景,可以大大提高读操作的性能。
Java 的锁机制为多线程编程提供了丰富的工具,开发者可以根据具体的业务需求选择适合的锁类型,以确保数据的一致性和线程的安全性。
好的,针对您提出的问题,我将逐一进行回答:
1、介绍一下 Redis
Redis 是一个开源的使用 ANSI C 语言编写的、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(string)、哈希(Hash)、列表(list)、集合(sets)、有序集合(sorted sets) 等类型。Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启后可以再次加载进行使用。
2、介绍一下 Redis 的数据结构及其底层实现原理
Redis 支持多种数据结构,每种数据结构都有其特定的底层实现原理:
- 字符串(String):字符串是最简单的数据类型,其底层实现就是一个简单的动态字符串。当对这个字符串进行修改的时候,如果超过了当前分配的空间,会进行 2 倍的空间扩展。
- 哈希(Hash):哈希类型实际上是 field 和 value 的映射表,类似于 Java 中的 HashMap。Redis 的哈希类型底层实现为压缩列表或哈希表两种数据结构。当哈希类型元素较少时,使用压缩列表;当元素较多时,则使用哈希表。
- 列表(List):列表类型用来存储多个有序的字符串元素,列表中的元素可以重复。列表类型有两个特点:可以添加重复的元素和保留元素插入的顺序。其底层实现为双向链表或压缩列表。
- 集合(Set):集合类型用来存储多个无序的字符串元素,且集合中的元素不能重复。其底层实现为整数集合或哈希表。
- 有序集合(Sorted Set):有序集合与集合一样不允许有重复的元素,但每个元素都会关联一个 double 类型的分数,Redis 正是通过分数来为集合中的元素从小到大进行从小到大的排序。其底层实现为压缩列表或跳跃表和哈希表的组合。
3、介绍一下你对 Redis 线程模型的了解
Redis 是单线程模型,这里的单线程主要指的是 Redis 的网络 I/O 和键值对读写是由一个线程来完成的。虽然 Redis 的其他功能,如持久化、异步删除、集群数据同步等,是由额外的线程来处理的,但这些并不会影响 Redis 主线程处理网络 I/O 和键值对读写的工作。Redis 采用单线程模型主要是为了避免多线程带来的锁竞争和上下文切换的开销,从而确保 Redis 的高性能。
4、介绍一下 Redis 集群,以及 Redis 是如何实现高可用的
Redis 集群是一个提供在多个 Redis 节点间进行数据共享的程序集。Redis 集群不支持那些需要同时操作多个键的 Redis 命令,因为这需要在不同的节点间移动数据,从而无法达到像单个 Redis 实例那样的性能,在设计的时候这就是不被支持的。
Redis 实现高可用主要通过以下几种方式:
- 主从复制:Redis 支持主从复制功能,即一个主节点可以有多个从节点。当主节点出现故障时,从节点可以接管主节点的任务,继续提供服务,从而实现高可用。
- 哨兵(Sentinel):哨兵是 Redis 的高可用性解决方案:由一个或多个 Sentinel 节点组成的 Sentinel 系统可以监视任意数量的主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
- 集群(Cluster):Redis 集群实现了数据的分片存储,每个节点只存储部分数据。当某个节点出现故障时,其他节点仍然可以正常工作,并且可以通过重新分配数据来恢复数据的完整性。此外,Redis 集群还支持在线扩容,可以方便地添加新的节点来提高系统的处理能力和存储容量。
5、说一下 Redis 中的 hot key 应该如何处理
hot key 是指那些被频繁访问的 Redis 键。处理 hot key 可以从以下几个方面入手:
- 缓存穿透:当查询一个不存在的数据时,由于缓存中也没有,因此每次请求都会直接打到数据库上,造成缓存穿透。对于这类情况,我们可以将空对象或默认值进行缓存,或者对查询条件进行校验,避免无效的查询。
- 缓存雪崩:当缓存中大量的 key 在同一时间失效或者 Redis 服务宕机时,所有的请求都会直接打到数据库上,造成缓存雪崩。为了避免这种情况,我们可以设置不同的 key 的过期时间,或者使用 Redis 的持久化功能来确保数据的可靠性。
- 热点 key 的访问:对于热点 key,我们可以考虑使用分布式锁来限制并发访问,或者使用本地缓存来减少对 Redis 的访问次数。此外,还可以考虑对热点 key 进行拆分或者增加其副本数量来分散访问压力。
6、你用过 Redis 吗?说一下你在哪些场景下用的
是的,我在实际项目中经常使用 Redis。以下是一些我使用 Redis 的场景:
缓存:这是 Redis 最常见的使用场景。我将一些热点数据或者计算结果存储在 Redis 中,作为缓存使用,以减少对数据库的访问压力,提高系统的响应速度。
计数器:Redis 的原子操作特性使得它非常适合用于实现计数器功能。例如,我可以使用 Redis 来记录网站的访问量、用户的点赞数等。
排行榜:Redis 的有序集合(Sorted Set)数据结构使得实现排行榜功能变得非常简单。我可以根据分数将元素进行排序,从而轻松获取排行榜信息。
消息队列:Redis 的列表(List)数据类型可以被用作简单的消息队列。生产者可以将消息推送到队列中,消费者可以从队列中拉取消息进行处理。
分布式锁:Redis 的 setnx 命令可以实现分布式锁的功能。在多个进程或线程需要同时访问共享资源时,我可以使用 Redis 的分布式锁来确保资源的安全访问。
会话管理:在 Web 应用中,我可以将用户的会话信息存储在 Redis 中,实现跨服务器的会话共享。
社交功能:Redis 也常被用于实现一些社交功能,如用户的关注列表、粉丝列表等。由于这些列表通常需要频繁地进行添加、删除和查询操作,Redis 的高性能特性使得它成为实现这些功能的理想选择。
以上只是我使用 Redis 的一些常见场景,实际上 Redis 的应用场景非常广泛,几乎涵盖了所有需要高性能数据存储和访问的场景。
如何保证 Redis 缓存一致性?
选择合适的缓存读写策略:
旁路缓存策略,可分为读策略和写策略。读穿 / 写穿策略,写回策略。
读策略的步骤是:
- 从缓存中读取数据;
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:
- 更新数据库中的记录;
- 删除缓存记录。
先删除缓存,后更新数据库呢?更新数据库效率相对来讲比较低,在两者之间如果有读请求(读缓存,缓存未命中,读数据库,回写缓存),缓存被回写了,此时更新后的数据库就与缓存不一致了。

使用线程池的好处
使用线程池比手动创建线程主要有三点好处。
- 第一点,线程池可以解决线程生命周期的系统开销问题,同时还可以加快响应速度。因为线程池中的线程是可以复用的,我们只用少量的线程去执行大量的任务,这就大大减小了线程生命周期的开销。而且线程通常不是等接到任务后再临时创建,而是已经创建好时刻准备执行任务,这样就消除了线程创建所带来的延迟,提升了响应速度,增强了用户体验。
- 第二点,线程池可以统筹内存和 CPU 的使用,避免资源使用不当。线程池会根据配置和任务数量灵活地控制线程数量,不够的时候就创建,太多的时候就回收,避免线程过多导致内存溢出,或线程太少导致 CPU 资源浪费,达到了一个完美的平衡。
- 第三点,线程池可以统一管理资源。比如线程池可以统一管理任务队列和线程,可以统一开始或结束任务,比单个线程逐一处理任务要更方便、更易于管理,同时也有利于数据统计,比如我们可以很方便地统计出已经执行过的任务的数量。
拒绝策略
- 第一种拒绝策略是 AbortPolicy,这种拒绝策略在拒绝任务时,会直接抛出一个类型为 RejectedExecutionException 的 RuntimeException,让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
- 第二种拒绝策略是 DiscardPolicy,这种拒绝策略正如它的名字所描述的一样,当新任务被提交后直接被丢弃掉,也不会给你任何的通知,相对而言存在一定的风险,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
- 第三种拒绝策略是 DiscardOldestPolicy,如果线程池没被关闭且没有能力执行,则会丢弃任务队列中的头结点,通常是存活时间最长的任务,这种策略与第二种不同之处在于它丢弃的不是最新提交的,而是队列中存活时间最长的,这样就可以腾出空间给新提交的任务,但同理它也存在一定的数据丢失风险。
- 第四种拒绝策略是 CallerRunsPolicy,相对而言它就比较完善了,当有新任务提交后,如果线程池没被关闭且没有能力执行,则把这个任务交于提交任务的线程执行,也就是谁提交任务,谁就负责执行任务。这样做主要有两点好处。
- 第一点新提交的任务不会被丢弃,这样也就不会造成业务损失。
- 第二点好处是,由于谁提交任务谁就要负责执行任务,这样提交任务的线程就得负责执行任务,而执行任务又是比较耗时的,在这段期间,提交任务的线程被占用,也就不会再提交新的任务,减缓了任务提交的速度,相当于是一个负反馈。在此期间,线程池中的线程也可以充分利用这段时间来执行掉一部分任务,腾出一定的空间,相当于是给了线程池一定的缓冲期。
线程池的内部结构主要由四部分组成
- 第一部分是线程池管理器,它主要负责管理线程池的创建、销毁、添加任务等管理操作,它是整个线程池的管家。
- 第二部分是工作线程,也就是图中的线程 t0~t9,这些线程勤勤恳恳地从任务队列中获取任务并执行。
- 第三部分是任务队列,作为一种缓冲机制,线程池会把当下没有处理的任务放入任务队列中,由于多线程同时从任务队列中获取任务是并发场景,此时就需要任务队列满足线程安全的要求,所以线程池中任务队列采用 BlockingQueue 来保障线程安全。
- 第四部分是任务,任务要求实现统一的接口,以便工作线程可以处理和执行。
你可以看到,这几种自动创建的线程池都存在风险,相比较而言,我们自己手动创建会更好,因为我们可以更加明确线程池的运行规则,不仅可以选择适合自己的线程数量,更可以在必要的时候拒绝新任务的提交,避免资源耗尽的风险。
选择合适的线程数量
CPU 密集型任务
首先,我们来看 CPU 密集型任务,比如加密、解密、压缩、计算等一系列需要大量耗费 CPU 资源的任务。对于这样的任务最佳的线程数为 CPU 核心数的 1~2 倍,如果设置过多的线程数,实际上并不会起到很好的效果。此时假设我们设置的线程数量是 CPU 核心数的 2 倍以上,因为计算任务非常重,会占用大量的 CPU 资源,所以这时 CPU 的每个核心工作基本都是满负荷的,而我们又设置了过多的线程,每个线程都想去利用 CPU 资源来执行自己的任务,这就会造成不必要的上下文切换,此时线程数的增多并没有让性能提升,反而由于线程数量过多会导致性能下降。
针对这种情况,我们最好还要同时考虑在同一台机器上还有哪些其他会占用过多 CPU 资源的程序在运行,然后对资源使用做整体的平衡。
耗时 IO 型任务
第二种任务是耗时 IO 型,比如数据库、文件的读写,网络通信等任务,这种任务的特点是并不会特别消耗 CPU 资源,但是 IO 操作很耗时,总体会占用比较多的时间。对于这种任务最大线程数一般会大于 CPU 核心数很多倍,因为 IO 读写速度相比于 CPU 的速度而言是比较慢的,如果我们设置过少的线程数,就可能导致 CPU 资源的浪费。而如果我们设置更多的线程数,那么当一部分线程正在等待 IO 的时候,它们此时并不需要 CPU 来计算,那么另外的线程便可以利用 CPU 去执行其他的任务,互不影响,这样的话在任务队列中等待的任务就会减少,可以更好地利用资源。
- 线程的平均工作时间所占比例越高,就需要越少的线程;
- 线程的平均等待时间所占比例越高,就需要越多的线程;
- 针对不同的程序,进行对应的实际测试就可以得到最合适的选择。
线程池怎么实现线程复用的?
Syncronized 锁升级过程:
第一种分类是偏向锁/轻量级锁/重量级锁,这三种锁特指 synchronized 锁的状态,通过在对象头中的 mark word 来表明锁的状态。
- 偏向锁
如果自始至终,对于这把锁都不存在竞争,那么其实就没必要上锁,只需要打个标记就行了,这就是偏向锁的思想。一个对象被初始化后,还没有任何线程来获取它的锁时,那么它就是可偏向的,当有第一个线程来访问它并尝试获取锁的时候,它就将这个线程记录下来,以后如果尝试获取锁的线程正是偏向锁的拥有者,就可以直接获得锁,开销很小,性能最好。
- 轻量级锁
JVM 开发者发现在很多情况下,synchronized 中的代码是被多个线程交替执行的,而不是同时执行的,也就是说并不存在实际的竞争,或者是只有短时间的锁竞争,用 CAS 就可以解决,这种情况下,用完全互斥的重量级锁是没必要的。轻量级锁是指当锁原来是偏向锁的时候,被另一个线程访问,说明存在竞争,那么偏向锁就会升级为轻量级锁,线程会通过自旋的形式尝试获取锁,而不会陷入阻塞。
- 重量级锁
重量级锁是互斥锁,它是利用操作系统的同步机制实现的,所以开销相对比较大。当多个线程直接有实际竞争,且锁竞争时间长的时候,轻量级锁不能满足需求,锁就会膨胀为重量级锁。重量级锁会让其他申请却拿不到锁的线程进入阻塞状态。

你可以发现锁升级的路径:无锁 → 偏向锁 → 轻量级锁 → 重量级锁。
综上所述,偏向锁性能最好,可以避免执行 CAS 操作。而轻量级锁利用自旋和 CAS 避免了重量级锁带来的线程阻塞和唤醒,性能中等。重量级锁则会把获取不到锁的线程阻塞,性能最差。
今日待总结:线程池的复用原理,ES 实现原理,定时任务原理,RPC 原理,HashMap 原理,计算机网络,操作系统,算法,新项目
wait/notify/notifyAll 方法定义在 Object 类中的原因:
广泛的适用性
:
wait/notify/notifyAll方法设计之初就考虑到它们应该能够被所有类型的对象所使用,而不仅仅是线程对象。这是因为在 Java 中,任何对象都可以作为同步锁(synchronized block 的锁对象),而等待(wait)和通知(notify/notifyAll)通常与这些锁对象紧密相关。将这些方法定义在Object类中,允许任何对象都可以作为同步监视器(monitor),从而实现等待/通知机制。
灵活性
:
- 将这些方法置于
Object类还提供了极大的灵活性。它允许开发者根据需要在不同的对象上调用这些同步控制方法,而不仅仅局限于线程对象本身。这种设计允许更复杂的同步和协作机制的实现。
- 将这些方法置于
sleep 方法定义在 Thread 类中的原因:
特定的行为
sleep方法用于让当前线程暂停执行一段指定的时间。这个行为是特定于线程的,即它影响的是调用它的那个线程本身。由于这种特定的线程行为,将sleep方法定义在Thread类中更为合理。
封装性
- 将与线程生命周期和状态控制直接相关的方法(如启动、停止、暂停等)封装在
Thread类中,有助于维护 Java 的封装性。这样的设计使得线程的行为更加清晰和易于管理。
- 将与线程生命周期和状态控制直接相关的方法(如启动、停止、暂停等)封装在
综上所述,wait/notify/notifyAll方法定义在Object类中是因为它们需要与任何可以作为同步锁的对象一起工作,而sleep方法定义在Thread类中则是因为它特定于线程本身的暂停行为。这种设计既保证了灵活性,也保证了封装性和清晰度。
为什么多线程会带来性能问题
那么什么情况下多线程编程会带来性能问题呢?主要有两个方面,一方面是线程调度,另一个方面是线程协作。
调度开销
上下文切换
首先,我们看一下线程调度,在实际开发中,线程数往往是大于 CPU 核心数的,比如 CPU 核心数可能是 8 核、16 核,等等,但线程数可能达到成百上千个。这种情况下,操作系统就会按照一定的调度算法,给每个线程分配时间片,让每个线程都有机会得到运行。而在进行调度时就会引起上下文切换,上下文切换会挂起当前正在执行的线程并保存当前的状态,然后寻找下一处即将恢复执行的代码,唤醒下一个线程,以此类推,反复执行。但上下文切换带来的开销是比较大的,假设我们的任务内容非常短,比如只进行简单的计算,那么就有可能发生我们上下文切换带来的性能开销比执行线程本身内容带来的开销还要大的情况。
缓存失效
不仅上下文切换会带来性能问题,缓存失效也有可能带来性能问题。由于程序有很大概率会再次访问刚才访问过的数据,所以为了加速整个程序的运行,会使用缓存,这样我们在使用相同数据时就可以很快地获取数据。可一旦进行了线程调度,切换到其他线程,CPU 就会去执行不同的代码,原有的缓存就很可能失效了,需要重新缓存新的数据,这也会造成一定的开销,所以线程调度器为了避免频繁地发生上下文切换,通常会给被调度到的线程设置最小的执行时间,也就是只有执行完这段时间之后,才可能进行下一次的调度,由此减少上下文切换的次数。
那么什么情况会导致密集的上下文切换呢?如果程序频繁地竞争锁,或者由于 IO 读写等原因导致频繁阻塞,那么这个程序就可能需要更多的上下文切换,这也就导致了更大的开销,我们应该尽量避免这种情况的发生。
协作开销
除了线程调度之外,线程协作同样也有可能带来性能问题。因为线程之间如果有共享数据,为了避免数据错乱,为了保证线程安全,就有可能禁止编译器和 CPU 对其进行重排序等优化,也可能出于同步的目的,反复把线程工作内存的数据 flush 到主存中,然后再从主内存 refresh 到其他线程的工作内存中,等等。这些问题在单线程中并不存在,但在多线程中为了确保数据的正确性,就不得不采取上述方法,因为线程安全的优先级要比性能优先级更高,这也间接降低了我们的性能。
线程池解决问题思路
我们来总结下如果每个任务都创建一个线程会带来哪些问题:
- 第一点,反复创建线程系统开销比较大,每个线程创建和销毁都需要时间,如果任务比较简单,那么就有可能导致创建和销毁线程消耗的资源比线程执行任务本身消耗的资源还要大。
- 第二点,过多的线程会占用过多的内存等资源,还会带来过多的上下文切换,同时还会导致系统不稳定。
针对上面的两点问题,线程池有两个解决思路。
首先,针对反复创建线程开销大的问题,线程池用一些固定的线程一直保持工作状态并反复执行任务。
其次,针对过多线程占用太多内存资源的问题,解决思路更直接,线程池会根据需要创建线程,控制线程的总数量,避免占用过多内存资源。
使用线程池的好处
使用线程池比手动创建线程主要有三点好处。
- 第一点,线程池可以解决线程生命周期的系统开销问题,同时还可以加快响应速度。因为线程池中的线程是可以复用的,我们只用少量的线程去执行大量的任务,这就大大减小了线程生命周期的开销。而且线程通常不是等接到任务后再临时创建,而是已经创建好时刻准备执行任务,这样就消除了线程创建所带来的延迟,提升了响应速度,增强了用户体验。
- 第二点,线程池可以统筹内存和 CPU 的使用,避免资源使用不当。线程池会根据配置和任务数量灵活地控制线程数量,不够的时候就创建,太多的时候就回收,避免线程过多导致内存溢出,或线程太少导致 CPU 资源浪费,达到了一个完美的平衡。
- 第三点,线程池可以统一管理资源。比如线程池可以统一管理任务队列和线程,可以统一开始或结束任务,比单个线程逐一处理任务要更方便、更易于管理,同时也有利于数据统计,比如我们可以很方便地统计出已经执行过的任务的数量。
拒绝时机
首先,新建线程池时可以指定它的任务拒绝策略,例如:
1 | |
以便在必要的时候按照我们的策略来拒绝任务,那么拒绝任务的时机是什么呢?线程池会在以下两种情况下会拒绝新提交的任务。
- 第一种情况是当我们调用 shutdown 等方法关闭线程池后,即便此时可能线程池内部依然有没执行完的任务正在执行,但是由于线程池已经关闭,此时如果再向线程池内提交任务,就会遭到拒绝。
- 第二种情况是线程池没有能力继续处理新提交的任务,也就是工作已经非常饱和的时候。
拒绝策略
- 第一种拒绝策略是 AbortPolicy,这种拒绝策略在拒绝任务时,会直接抛出一个类型为 RejectedExecutionException 的 RuntimeException,让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
- 第二种拒绝策略是 DiscardPolicy,这种拒绝策略正如它的名字所描述的一样,当新任务被提交后直接被丢弃掉,也不会给你任何的通知,相对而言存在一定的风险,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
- 第三种拒绝策略是 DiscardOldestPolicy,如果线程池没被关闭且没有能力执行,则会丢弃任务队列中的头结点,通常是存活时间最长的任务,这种策略与第二种不同之处在于它丢弃的不是最新提交的,而是队列中存活时间最长的,这样就可以腾出空间给新提交的任务,但同理它也存在一定的数据丢失风险。
- 第四种拒绝策略是 CallerRunsPolicy,相对而言它就比较完善了,当有新任务提交后,如果线程池没被关闭且没有能力执行,则把这个任务交于提交任务的线程执行,也就是谁提交任务,谁就负责执行任务。这样做主要有两点好处。
- 第一点新提交的任务不会被丢弃,这样也就不会造成业务损失。
- 第二点好处是,由于谁提交任务谁就要负责执行任务,这样提交任务的线程就得负责执行任务,而执行任务又是比较耗时的,在这段期间,提交任务的线程被占用,也就不会再提交新的任务,减缓了任务提交的速度,相当于是一个负反馈。在此期间,线程池中的线程也可以充分利用这段时间来执行掉一部分任务,腾出一定的空间,相当于是给了线程池一定的缓冲期。
6 种常见的线程池
在本课时我们主要学习常见的 6 种线程池,并详细讲解 Java 8 新增的 ForkJoinPool 线程池,6 种常见的线程池如下。
- FixedThreadPool
- CachedThreadPool
- ScheduledThreadPool
- SingleThreadExecutor
- SingleThreadScheduledExecutor
- ForkJoinPool
线程池内部结构
线程池的内部结构主要由四部分组成,如图所示。
- 第一部分是线程池管理器,它主要负责管理线程池的创建、销毁、添加任务等管理操作,它是整个线程池的管家。
- 第二部分是工作线程,也就是图中的线程 t0~t9,这些线程勤勤恳恳地从任务队列中获取任务并执行。
- 第三部分是任务队列,作为一种缓冲机制,线程池会把当下没有处理的任务放入任务队列中,由于多线程同时从任务队列中获取任务是并发场景,此时就需要任务队列满足线程安全的要求,所以线程池中任务队列采用 BlockingQueue 来保障线程安全。
- 第四部分是任务,任务要求实现统一的接口,以便工作线程可以处理和执行。
合适的线程数量
综上所述我们就可以得出一个结论:
- 线程的平均工作时间所占比例越高,就需要越少的线程;
- 线程的平均等待时间所占比例越高,就需要越多的线程;
- 针对不同的程序,进行对应的实际测试就可以得到最合适的选择。
定制线程池
所以定制自己的线程池和我们的业务是强相关的。
首先我们需要掌握每个参数的含义,以及常见的选项,然后根据实际需要,比如说并发量、内存大小、是否接受任务被拒绝等一系列因素去定制一个非常适合自己业务的线程池,这样既不会导致内存不足,同时又可以用合适数量的线程来保障任务执行的效率,并在拒绝任务时有所记录方便日后进行追溯。
[16 如何根据实际需要,定制自己的线程池? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/16 如何根据实际需要,定制自己的线程池?.md)
为什么设置非公平锁
为什么要设置非公平策略呢,而且非公平还是 ReentrantLock 的默认策略,如果我们不加以设置的话默认就是非公平的,难道我的这些排队的时间都白白浪费了吗,为什么别人比我有优先权呢?毕竟公平是一种很好的行为,而非公平是一种不好的行为。
让我们考虑一种情况,假设线程 A 持有一把锁,线程 B 请求这把锁,由于线程 A 已经持有这把锁了,所以线程 B 会陷入等待,在等待的时候线程 B 会被挂起,也就是进入阻塞状态,那么当线程 A 释放锁的时候,本该轮到线程 B 苏醒获取锁,但如果此时突然有一个线程 C 插队请求这把锁,那么根据非公平的策略,会把这把锁给线程 C,这是因为唤醒线程 B 是需要很大开销的,很有可能在唤醒之前,线程 C 已经拿到了这把锁并且执行完任务释放了这把锁。相比于等待唤醒线程 B 的漫长过程,插队的行为会让线程 C 本身跳过陷入阻塞的过程,如果在锁代码中执行的内容不多的话,线程 C 就可以很快完成任务,并且在线程 B 被完全唤醒之前,就把这个锁交出去,这样是一个双赢的局面,对于线程 C 而言,不需要等待提高了它的效率,而对于线程 B 而言,它获得锁的时间并没有推迟,因为等它被唤醒的时候,线程 C 早就释放锁了,因为线程 C 的执行速度相比于线程 B 的唤醒速度,是很快的,所以 Java 设计者设计非公平锁,是为了提高整体的运行效率。
综上所述,公平锁就是会按照多个线程申请锁的顺序来获取锁,从而实现公平的特性。非公平锁加锁时不考虑排队等待情况,直接尝试获取锁,所以存在后申请却先获得锁的情况,但由此也提高了整体的效率。
[24 讲一讲公平锁和非公平锁,为什么要“非公平”? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/24 讲一讲公平锁和非公平锁,为什么要“非公平”?.md)
ReentrantReadWriteLock
对于 ReentrantReadWriteLock 而言。
- 插队策略
- 公平策略下,只要队列里有线程已经在排队,就不允许插队。
- 非公平策略下:
- 如果允许读锁插队,那么由于读锁可以同时被多个线程持有,所以可能造成源源不断的后面的线程一直插队成功,导致读锁一直不能完全释放,从而导致写锁一直等待,为了防止“饥饿”,在等待队列的头结点是尝试获取写锁的线程的时候,不允许读锁插队。
- 写锁可以随时插队,因为写锁并不容易插队成功,写锁只有在当前没有任何其他线程持有读锁和写锁的时候,才能插队成功,同时写锁一旦插队失败就会进入等待队列,所以很难造成“饥饿”的情况,允许写锁插队是为了提高效率。
- 升降级策略:只能从写锁降级为读锁,不能从读锁升级为写锁。
[25 读写锁 ReadWriteLock 获取锁有哪些规则? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/25 读写锁 ReadWriteLock 获取锁有哪些规则?.md)
JVM 锁优化
本课时我们主要讲解 JVM 对锁进行了哪些优化呢?
相比于 JDK 1.5,在 JDK 1.6 中 HotSopt 虚拟机对 synchronized 内置锁的性能进行了很多优化,包括自适应的自旋、锁消除、锁粗化、偏向锁、轻量级锁等。有了这些优化措施后,synchronized 锁的性能得到了大幅提高。
[28 JVM 对锁进行了哪些优化? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/28 JVM 对锁进行了哪些优化?.md)
Map 桶超过 8 个转红黑树
[31 为什么 Map 桶中超过 8 个才转为红黑树? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/31 为什么 Map 桶中超过 8 个才转为红黑树?.md)
在图中我们可以看到,有一些槽点是空的,有一些是拉链,有一些是红黑树。
更多的时候我们会关注,为何转为红黑树以及红黑树的一些特点,可是,为什么转化的这个阈值要默认设置为 8 呢?要想知道为什么设置为 8,那首先我们就要知道为什么要转换,因为转换是第一步。
每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。红黑树有和链表不一样的查找性能,由于红黑树有自平衡的特点,可以防止不平衡情况的发生,所以可以始终将查找的时间复杂度控制在 O(log(n))。最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
那为什么不一开始就用红黑树,反而要经历一个转换的过程呢?其实在 JDK 的源码注释中已经对这个问题作了解释:
这段话的意思是:单个 TreeNode 需要占用的空间大约是普通 Node 的两倍,所以只有当包含足够多的 Nodes 时才会转成 TreeNodes,而是否足够多就是由 TREEIFY_THRESHOLD 的值决定的。而当桶中节点数由于移除或者 resize 变少后,又会变回普通的链表的形式,以便节省空间。
通过查看源码可以发现,默认是链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回去,这体现了时间和空间平衡的思想,最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。对于何时应该从链表转化为红黑树,需要确定一个阈值,这个阈值默认为 8,并且在源码中也对选择 8 这个数字做了说明,原文如下:
上面这段话的意思是,如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。
但是,HashMap 决定某一个元素落到哪一个桶里,是和这个对象的 hashCode 有关的,JDK 并不能阻止我们用户实现自己的哈希算法,如果我们故意把哈希算法变得不均匀,例如:
事实上,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低,而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
通常如果 hash 算法正常的话,那么链表的长度也不会很长,那么红黑树也不会带来明显的查询时间上的优势,反而会增加空间负担。所以通常情况下,并没有必要转为红黑树,所以就选择了概率非常小,小于千万分之一概率,也就是长度为 8 的概率,把长度 8 作为转化的默认阈值。
所以如果平时开发中发现 HashMap 或是 ConcurrentHashMap 内部出现了红黑树的结构,这个时候往往就说明我们的哈希算法出了问题,需要留意是不是我们实现了效果不好的 hashCode 方法,并对此进行改进,以便减少冲突。
阻塞队列的特点
阻塞队列区别于其他类型的队列的最主要的特点就是“阻塞”这两个字,所以下面重点介绍阻塞功能:阻塞功能使得生产者和消费者两端的能力得以平衡,当有任何一端速度过快时,阻塞队列便会把过快的速度给降下来。实现阻塞最重要的两个方法是 take 方法和 put 方法。
take 方法
take 方法的功能是获取并移除队列的头结点,通常在队列里有数据的时候是可以正常移除的。可是一旦执行 take 方法的时候,队列里无数据,则阻塞,直到队列里有数据。一旦队列里有数据了,就会立刻解除阻塞状态,并且取到数据。过程如图所示:
put 方法
put 方法插入元素时,如果队列没有满,那就和普通的插入一样是正常的插入,但是如果队列已满,那么就无法继续插入,则阻塞,直到队列里有了空闲空间。如果后续队列有了空闲空间,比如消费者消费了一个元素,那么此时队列就会解除阻塞状态,并把需要添加的数据添加到队列中。过程如图所示:
以上过程中的阻塞和解除阻塞,都是 BlockingQueue 完成的,不需要我们自己处理。
是否有界(容量有多大)
此外,阻塞队列还有一个非常重要的属性,那就是容量的大小,分为有界和无界两种。
无界队列意味着里面可以容纳非常多的元素,例如 LinkedBlockingQueue 的上限是 Integer.MAX_VALUE,约为 2 的 31 次方,是非常大的一个数,可以近似认为是无限容量,因为我们几乎无法把这个容量装满。
但是有的阻塞队列是有界的,例如 ArrayBlockingQueue 如果容量满了,也不会扩容,所以一旦满了就无法再往里放数据了。
以上就是本课时的全部内容,本课时讲解了什么是阻塞队列,首先我们讲解了阻塞队列的作用;然后看了 Java 8 中的并发队列,分为阻塞队列和非阻塞队列,并且在阻塞队列中有 6 种常见的实现;最后我们看了阻塞队列的特点,包括 take 方法、put 方法和是否有界。
阻塞队列常用方法
[35 阻塞队列包含哪些常用的方法?add、offer、put 等方法的区别? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/35 阻塞队列包含哪些常用的方法?add、offer、put 等方法的区别?.md)
以上就是本课时的内容,本课时我们讲解了阻塞队列中常见的方法并且把它们分为了三组,每一组都有各自的特点。第一组的特点是在无法正常执行的情况下抛出异常;第二组的特点是在无法正常执行的情况下不抛出异常,但会用返回值提示运行失败;第三组的特点是在遇到特殊情况时让线程陷入阻塞状态,等到可以运行再继续执行。
我们用表格把上面 8 种方法总结如下:
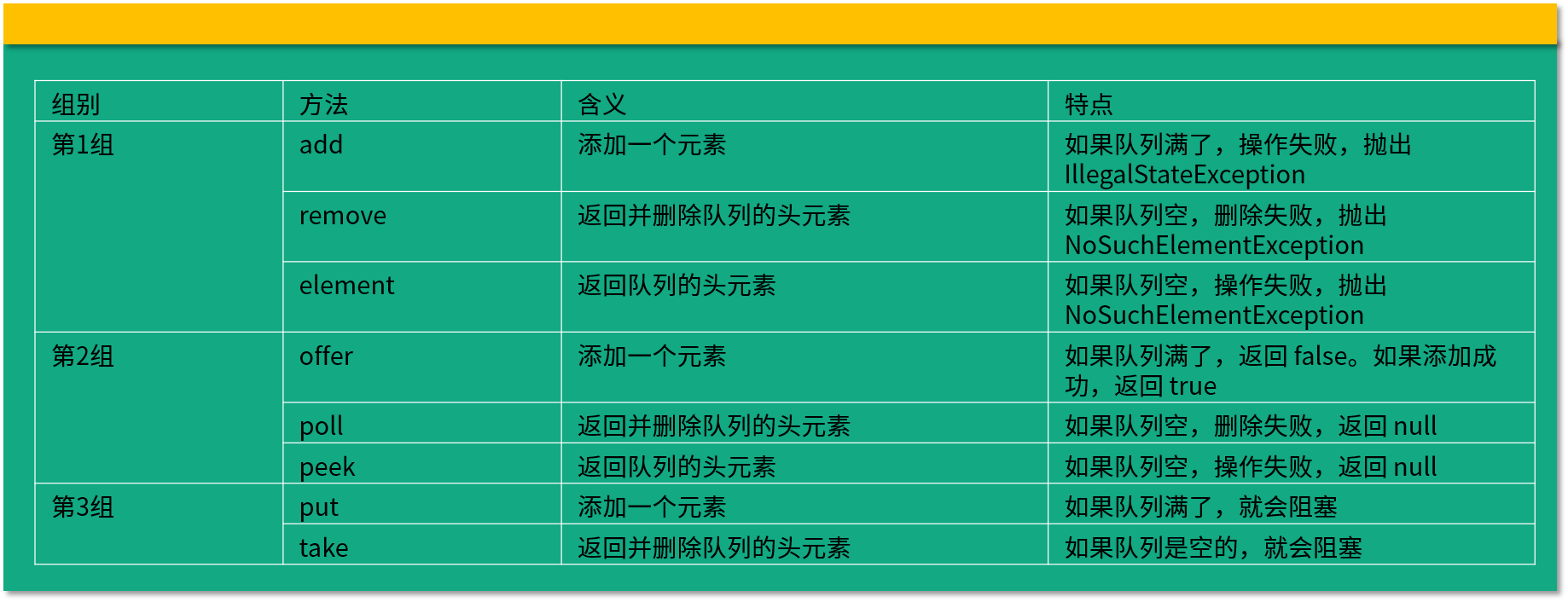 有了这个表格之后,我们就可以非常清晰地理清这 8 个方法之间的关系了,课后你可以仔细对比表格以加深印象。
有了这个表格之后,我们就可以非常清晰地理清这 8 个方法之间的关系了,课后你可以仔细对比表格以加深印象。
[36 有哪几种常见的阻塞队列? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/36 有哪几种常见的阻塞队列?.md)
阻塞/非阻塞队列并发原理
可以看出,这两个方法几乎是一模一样的,所以当时在第 5 课时的时候我们就说过,我们自己用 Condition 实现生产者/消费者模式,实际上其本质就是自己实现了简易版的 BlockingQueue。你可以对比一下这两个 put 方法的实现,这样对 Condition 的理解就会更加深刻。
和 ArrayBlockingQueue 类似,其他各种阻塞队列如 LinkedBlockingQueue、PriorityBlockingQueue、DelayQueue、DelayedWorkQueue 等一系列 BlockingQueue 的内部也是利用了 ReentrantLock 来保证线程安全,只不过细节有差异,比如 LinkedBlockingQueue 的内部有两把锁,分别锁住队列的头和尾,比共用同一把锁的效率更高,不过总体思想都是类似的。
可以看出这里运用了 UNSAFE.compareAndSwapObject 方法来完成 CAS 操作,而 compareAndSwapObject 是一个 native 方法,最终会利用 CPU 的 CAS 指令保证其不可中断。
可以看出,非阻塞队列 ConcurrentLinkedQueue 使用 CAS 非阻塞算法 + 不停重试,来实现线程安全,适合用在不需要阻塞功能,且并发不是特别剧烈的场景。
阻塞队列选取
[38 如何选择适合自己的阻塞队列? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/38 如何选择适合自己的阻塞队列?.md)
下面让我们总结一下经验,通常我们可以从以下 5 个角度考虑,来选择合适的阻塞队列:
- 功能
第 1 个需要考虑的就是功能层面,比如是否需要阻塞队列帮我们排序,如优先级排序、延迟执行等。如果有这个需要,我们就必须选择类似于 PriorityBlockingQueue 之类的有排序能力的阻塞队列。
- 容量
第 2 个需要考虑的是容量,或者说是否有存储的要求,还是只需要“直接传递”。在考虑这一点的时候,我们知道前面介绍的那几种阻塞队列,有的是容量固定的,如 ArrayBlockingQueue;有的默认是容量无限的,如 LinkedBlockingQueue;而有的里面没有任何容量,如 SynchronousQueue;而对于 DelayQueue 而言,它的容量固定就是 Integer.MAX_VALUE。
所以不同阻塞队列的容量是千差万别的,我们需要根据任务数量来推算出合适的容量,从而去选取合适的 BlockingQueue。
- 能否扩容
第 3 个需要考虑的是能否扩容。因为有时我们并不能在初始的时候很好的准确估计队列的大小,因为业务可能有高峰期、低谷期。
如果一开始就固定一个容量,可能无法应对所有的情况,也是不合适的,有可能需要动态扩容。如果我们需要动态扩容的话,那么就不能选择 ArrayBlockingQueue ,因为它的容量在创建时就确定了,无法扩容。相反,PriorityBlockingQueue 即使在指定了初始容量之后,后续如果有需要,也可以自动扩容。
所以我们可以根据是否需要扩容来选取合适的队列。
- 内存结构
第 4 个需要考虑的点就是内存结构。在上一课时我们分析过 ArrayBlockingQueue 的源码,看到了它的内部结构是“数组”的形式。
和它不同的是,LinkedBlockingQueue 的内部是用链表实现的,所以这里就需要我们考虑到,ArrayBlockingQueue 没有链表所需要的“节点”,空间利用率更高。所以如果我们对性能有要求可以从内存的结构角度去考虑这个问题。
- 性能
第 5 点就是从性能的角度去考虑。比如 LinkedBlockingQueue 由于拥有两把锁,它的操作粒度更细,在并发程度高的时候,相对于只有一把锁的 ArrayBlockingQueue 性能会更好。
另外,SynchronousQueue 性能往往优于其他实现,因为它只需要“直接传递”,而不需要存储的过程。如果我们的场景需要直接传递的话,可以优先考虑 SynchronousQueue。
在本课时,我们首先回顾了线程池对于阻塞队列的选取规则,然后又看到了 ArrayBlockingQueue 的特点,接下来我们总结归纳了通常情况下,可以从功能、容量、能否扩容、内存结构和性能这 5 个角度考虑问题,结合业务选取最适合我们的阻塞队列。
总结
最后我们来做一下总结。本课时我们分析了阻塞队列和非阻塞队列的并发安全原理,其中阻塞队列最主要是利用了 ReentrantLock 以及它的 Condition 来实现,而非阻塞队列则是利用 CAS 方法实现线程安全。
原子类和 volatile 的使用场景
那下面我们就来说一下原子类和 volatile 各自的使用场景。
我们可以看出,volatile 和原子类的使用场景是不一样的,如果我们有一个可见性问题,那么可以使用 volatile 关键字,但如果我们的问题是一个组合操作,需要用同步来解决原子性问题的话,那么可以使用原子变量,而不能使用 volatile 关键字。
通常情况下,volatile 可以用来修饰 boolean 类型的标记位,因为对于标记位来讲,直接的赋值操作本身就是具备原子性的,再加上 volatile 保证了可见性,那么就是线程安全的了。
而对于会被多个线程同时操作的计数器 Counter 的场景,这种场景的一个典型特点就是,它不仅仅是一个简单的赋值操作,而是需要先读取当前的值,然后在此基础上进行一定的修改,再把它给赋值回去。这样一来,我们的 volatile 就不足以保证这种情况的线程安全了。我们需要使用原子类来保证线程安全。
原子类和 synchronized
[42 AtomicInteger 和 synchronized 的异同点? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/42 AtomicInteger 和 synchronized 的异同点?.md)
下面我们就对这两种不同的方案进行分析。
第一点,我们来看一下它们背后原理的不同。
在第 21 课时中我们详细分析了 synchronized 背后的 monitor 锁,也就是 synchronized 原理,同步方法和同步代码块的背后原理会有少许差异,但总体思想是一致的:在执行同步代码之前,需要首先获取到 monitor 锁,执行完毕后,再释放锁。
而我们在第 39 课时中介绍了原子类,它保证线程安全的原理是利用了 CAS 操作。从这一点上看,虽然原子类和 synchronized 都能保证线程安全,但是其实现原理是大有不同的。
第二点不同是使用范围的不同。
对于原子类而言,它的使用范围是比较局限的。因为一个原子类仅仅是一个对象,不够灵活。而 synchronized 的使用范围要广泛得多。比如说 synchronized 既可以修饰一个方法,又可以修饰一段代码,相当于可以根据我们的需要,非常灵活地去控制它的应用范围。
所以仅有少量的场景,例如计数器等场景,我们可以使用原子类。而在其他更多的场景下,如果原子类不适用,那么我们就可以考虑用 synchronized 来解决这个问题。
第三个区别是粒度的区别。
原子变量的粒度是比较小的,它可以把竞争范围缩小到变量级别。通常情况下,synchronized 锁的粒度都要大于原子变量的粒度。如果我们只把一行代码用 synchronized 给保护起来的话,有一点杀鸡焉用牛刀的感觉。
第四点是它们性能的区别,同时也是悲观锁和乐观锁的区别。
因为 synchronized 是一种典型的悲观锁,而原子类恰恰相反,它利用的是乐观锁。所以,我们在比较 synchronized 和 AtomicInteger 的时候,其实也就相当于比较了悲观锁和乐观锁的区别。
从性能上来考虑的话,悲观锁的操作相对来讲是比较重量级的。因为 synchronized 在竞争激烈的情况下,会让拿不到锁的线程阻塞,而原子类是永远不会让线程阻塞的。不过,虽然 synchronized 会让线程阻塞,但是这并不代表它的性能就比原子类差。
因为悲观锁的开销是固定的,也是一劳永逸的。随着时间的增加,这种开销并不会线性增长。
而乐观锁虽然在短期内的开销不大,但是随着时间的增加,它的开销也是逐步上涨的。
所以从性能的角度考虑,它们没有一个孰优孰劣的关系,而是要区分具体的使用场景。在竞争非常激烈的情况下,推荐使用 synchronized;而在竞争不激烈的情况下,使用原子类会得到更好的效果。
值得注意的是,synchronized 的性能随着 JDK 的升级,也得到了不断的优化。synchronized 会从无锁升级到偏向锁,再升级到轻量级锁,最后才会升级到让线程阻塞的重量级锁。因此 synchronized 在竞争不激烈的情况下,性能也是不错的,不需要“谈虎色变”。
ThreadLocal 典型使用场景
[44 ThreadLocal 适合用在哪些实际生产的场景中? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/44 ThreadLocal 适合用在哪些实际生产的场景中?.md)
本课时主要介绍 ThreadLocal 适合用在哪些实际生产的场景中。
我们在学习一个工具之前,首先应该知道这个工具的作用,能带来哪些好处,而不是一上来就闷头进入工具的 API、用法等,否则就算我们把某个工具的用法学会了,也不知道应该在什么场景下使用。所以,我们先来看看究竟哪些场景下需要用到 ThreadLocal。
在通常的业务开发中,ThreadLocal 有两种典型的使用场景。
场景 1,ThreadLocal 用作保存每个线程独享的对象,为每个线程都创建一个副本,这样每个线程都可以修改自己所拥有的副本, 而不会影响其他线程的副本,确保了线程安全。
场景 2,ThreadLocal 用作每个线程内需要独立保存信息,以便供其他方法更方便地获取该信息的场景。每个线程获取到的信息可能都是不一样的,前面执行的方法保存了信息后,后续方法可以通过 ThreadLocal 直接获取到,避免了传参,类似于全局变量的概念。
ThreadLocal 解决共享资源问题
这道题的答案很明确——不是,ThreadLocal 并不是用来解决共享资源问题的。虽然 ThreadLocal 确实可以用于解决多线程情况下的线程安全问题,但其资源并不是共享的,而是每个线程独享的。所以这道题其实是有一定陷阱成分在内的。
ThreadLocal 解决线程安全问题的时候,相比于使用“锁”而言,换了一个思路,把资源变成了各线程独享的资源,非常巧妙地避免了同步操作。具体而言,它可以在 initialValue 中 new 出自己线程独享的资源,而多个线程之间,它们所访问的对象本身是不共享的,自然就不存在任何并发问题。这是 ThreadLocal 解决并发问题的最主要思路。
如果我们把放到 ThreadLocal 中的资源用 static 修饰,让它变成一个共享资源的话,那么即便使用了 ThreadLocal,同样也会有线程安全问题。比如我们对第 44 讲中的例子进行改造,如果我们在 SimpleDateFormat 之前加上一个 static 关键字来修饰,并且把这个静态对象放到 ThreadLocal 中去存储的话,代码如下所示:
ThreadLocal 和 synchronized 是什么关系
面试官可能会问:你既然说 ThreadLocal 和 synchronized 它们两个都能解决线程安全问题,那么 ThreadLocal 和 synchronized 是什么关系呢?
我们先说第一种情况。当 ThreadLocal 用于解决线程安全问题的时候,也就是把一个对象给每个线程都生成一份独享的副本的,在这种场景下,ThreadLocal 和 synchronized 都可以理解为是用来保证线程安全的手段。例如,在第 44 讲 SimpleDateFormat 的例子中,我们既使用了 synchronized 来达到目的,也使用了 ThreadLocal 作为实现方案。但是效果和实现原理不同:
- ThreadLocal 是通过让每个线程独享自己的副本,避免了资源的竞争。
- synchronized 主要用于临界资源的分配,在同一时刻限制最多只有一个线程能访问该资源。
相比于 ThreadLocal 而言,synchronized 的效率会更低一些,但是花费的内存也更少。在这种场景下,ThreadLocal 和 synchronized 虽然有不同的效果,不过都可以达到线程安全的目的。
但是对于 ThreadLocal 而言,它还有不同的使用场景。比如当 ThreadLocal 用于让多个类能更方便地拿到我们希望给每个线程独立保存这个信息的场景下时(比如每个线程都会对应一个用户信息,也就是 user 对象),在这种场景下,ThreadLocal 侧重的是避免传参,所以此时 ThreadLocal 和 synchronized 是两个不同维度的工具。
以上就是本课时的内容。
在本课时中,首先介绍了 ThreadLocal 是不是用来解决共享资源的多线程访问的问题的,答案是“不是”,因为对于 ThreadLocal 而言,每个线程中的资源并不共享;然后我们又介绍了 ThreadLocal 和 synchronized 的关系。
什么是内存泄漏
内存泄漏指的是,当某一个对象不再有用的时候,占用的内存却不能被回收,这就叫作内存泄漏。
因为通常情况下,如果一个对象不再有用,那么我们的垃圾回收器 GC,就应该把这部分内存给清理掉。这样的话,就可以让这部分内存后续重新分配到其他的地方去使用;否则,如果对象没有用,但一直不能被回收,这样的垃圾对象如果积累的越来越多,则会导致我们可用的内存越来越少,最后发生内存不够用的 OOM 错误。
下面我们来分析一下,在 ThreadLocal 中这样的内存泄漏是如何发生的。
Callable 和 Runnable 的不同之处
最后总结一下 Callable 和 Runnable 的不同之处:
- 方法名,Callable 规定的执行方法是 call(),而 Runnable 规定的执行方法是 run();
- 返回值,Callable 的任务执行后有返回值,而 Runnable 的任务执行后是没有返回值的;
- 抛出异常,call() 方法可抛出异常,而 run() 方法是不能抛出受检查异常的;
- 和 Callable 配合的有一个 Future 类,通过 Future 可以了解任务执行情况,或者取消任务的执行,还可获取任务执行的结果,这些功能都是 Runnable 做不到的,Callable 的功能要比 Runnable 强大。
以上就是本课时的内容了。首先介绍了 Runnable 的两个缺陷,第一个是没有返回值,第二个是不能抛出受检查异常;然后分析了为什么会有这样的缺陷,以及为什么设计成这样;接下来分析了 Callable 接口,并且把 Callable 接口和 Runnable 接口的区别进行了对比和总结。
[49 Future 的主要功能是什么? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/49 Future 的主要功能是什么?.md)
在这段代码中可以看出,首先创建了一个实现了 Callable 接口的 Task,然后把这个 Task 实例传入到 FutureTask 的构造函数中去,创建了一个 FutureTask 实例,并且把这个实例当作一个 Runnable 放到 new Thread() 中去执行,最后再用 FutureTask 的 get 得到结果,并打印出来。
内存分配的过程是怎样的?
应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。
当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。
缺页中断处理函数会看是否有空闲的物理内存,如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
如果没有空闲的物理内存,那么内核就会开始进行回收内存的工作,回收的方式主要是两种:直接内存回收和后台内存回收。
- 后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
如果直接内存回收后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了 ——触发 OOM (Out of Memory)机制。
OOM Killer 机制会根据算法选择一个占用物理内存较高的进程,然后将其杀死,以便释放内存资源,如果物理内存依然不足,OOM Killer 会继续杀死占用物理内存较高的进程,直到释放足够的内存位置。
CountDownLatch 主要方法介绍
下面介绍一下 CountDownLatch 的主要方法。
(1)构造函数:public CountDownLatch(int count) { };
它的构造函数是传入一个参数,该参数 count 是需要倒数的数值。
**(2)await()**:调用 await() 方法的线程开始等待,直到倒数结束,也就是 count 值为 0 的时候才会继续执行。
**(3)await(long timeout, TimeUnit unit)**:await() 有一个重载的方法,里面会传入超时参数,这个方法的作用和 await() 类似,但是这里可以设置超时时间,如果超时就不再等待了。
**(4)countDown()**:把数值倒数 1,也就是将 count 值减 1,直到减为 0 时,之前等待的线程会被唤起。
[53 CountDownLatch 是如何安排线程执行顺序的? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/53 CountDownLatch 是如何安排线程执行顺序的?.md)
接着来介绍一下 CountDownLatch 的两个典型用法。
用法一:一个线程等待其他多个线程都执行完毕,再继续自己的工作
用法二:多个线程等待某一个线程的信号,同时开始执行
JVM 内存结构 VS Java 内存模型
Java 作为一种面向对象的语言,有很多概念,从名称上看起来比较相似,比如 JVM 内存结构、Java 内存模型,这是两个截然不同的概念,但是很容易混淆。网络上也有不少讲 Java 内存模型的文章,其实写的是 JVM 内存结构。
所以我们就先从整体上概括一下这两者的主要作用:
- JVM 内存结构和 Java 虚拟机的运行时区域有关;
- Java 内存模型和 Java 的并发编程有关。
所以可以看出,这两个概念其实是有很大区别的。下面我们先来简要介绍一下 JVM 内存结构。
JVM 内存结构
我们都知道,Java 代码是要运行在虚拟机上的,而虚拟机在执行 Java 程序的过程中会把所管理的内存划分为若干个不同的数据区域,这些区域都有各自的用途。在《Java 虚拟机规范(Java SE 8)》中描述了 JVM 运行时内存区域结构可分为以下 6 个区。
**堆区(**Heap**)****:**堆是存储类实例和数组的,通常是内存中最大的一块。实例很好理解,比如 new Object() 就会生成一个实例;而数组也是保存在堆上面的,因为在 Java 中,数组也是对象。
**虚拟机栈(**Java Virtual Machine Stacks**)****:**它保存局部变量和部分结果,并在方法调用和返回中起作用。
**方法区(**Method Area**)****:**它存储每个类的结构,例如运行时的常量池、字段和方法数据,以及方法和构造函数的代码,包括用于类初始化以及接口初始化的特殊方法。
**本地方法栈(**Native Method Stacks**)****:**与虚拟机栈基本类似,区别在于虚拟机栈为虚拟机执行的 Java 方法服务,而本地方法栈则是为 Native 方法服务。
**程序计数器(**The PC Register**)****:**是最小的一块内存区域,它的作用通常是保存当前正在执行的 JVM 指令地址。
**运行时常量池****(Run-Time Constant Pool):**是方法区的一部分,包含多种常量,范围从编译时已知的数字到必须在运行时解析的方法和字段引用。
注意,以上是 Java 虚拟机规范,不同的虚拟机实现会各有不同,一般会遵守规范。
这里总结一下,JVM 内存结构是由 Java 虚拟机规范定义的,描述的是在 Java 程序执行过程中,由 JVM 管理的不同数据区域,各个区域有其特定的功能。官方的规范地址请点击这里查看。
从 Java 代码到 CPU 指令
看完了 JVM 内存结构,就让我们回到 Java 内存模型上来。我们都知道,编写的 Java 代码,最终还是要转化为 CPU 指令才能执行的。为了理解 Java 内存模型的作用,我们首先就来回顾一下从 Java 代码到最终执行的 CPU 指令的大致流程:
- 最开始,我们编写的 Java 代码,是 *.java 文件;
- 在编译(包含词法分析、语义分析等步骤)后,在刚才的 .java 文件之外,会多出一个新的 Java 字节码文件(.class);
- JVM 会分析刚才生成的字节码文件(*.class),并根据平台等因素,把字节码文件转化为具体平台上的机器指令;
- 机器指令则可以直接在 CPU 上运行,也就是最终的程序执行。
为什么需要 JMM(Java Memory Model,Java 内存模型)
在更早期的语言中,其实是不存在内存模型的概念的。
所以程序最终执行的效果会依赖于具体的处理器,而不同的处理器的规则又不一样,不同的处理器之间可能差异很大,因此同样的一段代码,可能在处理器 A 上运行正常,而在处理器 B 上运行的结果却不一致。同理,在没有 JMM 之前,不同的 JVM 的实现,也会带来不一样的“翻译”结果。
所以 Java 非常需要一个标准,来让 Java 开发者、编译器工程师和 JVM 工程师能够达成一致。达成一致后,我们就可以很清楚的知道什么样的代码最终可以达到什么样的运行效果,让多线程运行结果可以预期,这个标准就是 JMM,这就是需要 JMM 的原因。
我们本课时将突破 Java 代码的层次,开始往下钻研,研究从 Java 代码到 CPU 指令的这个转化过程要遵守哪些和并发相关的原则和规范,这就是 JMM 的重点内容。如果不加以规范,那么同样的 Java 代码,完全可能产生不一样的执行效果,那是不可接受的,这也违背了 Java “书写一次、到处运行”的特点。
重排序的 3 种情况
下面我们来看一下重排序的 3 种情况。
(1)编译器优化
编译器(包括 JVM、JIT 编译器等)出于优化的目的,例如当前有了数据 a,把对 a 的操作放到一起效率会更高,避免读取 b 后又返回来重新读取 a 的时间开销,此时在编译的过程中会进行一定程度的重排。不过重排序并不意味着可以任意排序,它需要需要保证重排序后,不改变单线程内的语义,否则如果能任意排序的话,程序早就逻辑混乱了。
(2)CPU 重排序
CPU 同样会有优化行为,这里的优化和编译器优化类似,都是通过乱序执行的技术来提高整体的执行效率。所以即使之前编译器不发生重排,CPU 也可能进行重排,我们在开发中,一定要考虑到重排序带来的后果。
(3) 内存的“重排序”
内存系统内不存在真正的重排序,但是内存会带来看上去和重排序一样的效果,所以这里的“重排序”打了双引号。由于内存有缓存的存在,在 JMM 里表现为主存和本地内存,而主存和本地内存的内容可能不一致,所以这也会导致程序表现出乱序的行为。
举个例子,线程 1 修改了 a 的值,但是修改后没有来得及把新结果写回主存或者线程 2 没来得及读到最新的值,所以线程 2 看不到刚才线程 1 对 a 的修改,此时线程 2 看到的 a 还是等于初始值。但是线程 2 却可能看到线程 1 修改 a 之后的代码执行效果,表面上看起来像是发生了重顺序。
能够保证可见性的措施
除了 volatile 关键字可以让变量保证可见性外,synchronized、Lock、并发集合等一系列工具都可以在一定程度上保证可见性,具体保证可见性的时机和手段,我将在第 61 课时 happens-before 原则中详细展开讲解。
synchronized 不仅保证了原子性,还保证了可见性
下面我们再来分析一下之前所使用过的 synchronized 关键字,在理解了可见性问题之后,相信你对 synchronized 的理解会更加深入。
关于 synchronized 这里有一个特别值得说的点,我们之前可能一致认为,使用了 synchronized 之后,它会设立一个临界区,这样在一个线程操作临界区内的数据的时候,另一个线程无法进来同时操作,所以保证了线程安全。
其实这是不全面的,这种说法没有考虑到可见性问题,完整的说法是:synchronized 不仅保证了临界区内最多同时只有一个线程执行操作,同时还保证了在前一个线程释放锁之后,之前所做的所有修改,都能被获得同一个锁的下一个线程所看到,也就是能读取到最新的值。因为如果其他线程看不到之前所做的修改,依然也会发生线程安全问题。
以上就是本课时的内容了。在本课时中,我们首先给出了两个具体案例来介绍什么是可见性问题;然后介绍了解决可见性问题的方法,最常用的就是使用 volatile 关键字;最后我们对 synchronized 的理解从可见性的层面上加深了一步。
CPU 有多级缓存,导致读的数据过期
由于 CPU 的处理速度很快,相比之下,内存的速度就显得很慢,所以为了提高 CPU 的整体运行效率,减少空闲时间,在 CPU 和内存之间会有 cache 层,也就是缓存层的存在。虽然缓存的容量比内存小,但是缓存的速度却比内存的速度要快得多,其中 L1 缓存的速度仅次于寄存器的速度。结构示意图如下所示:
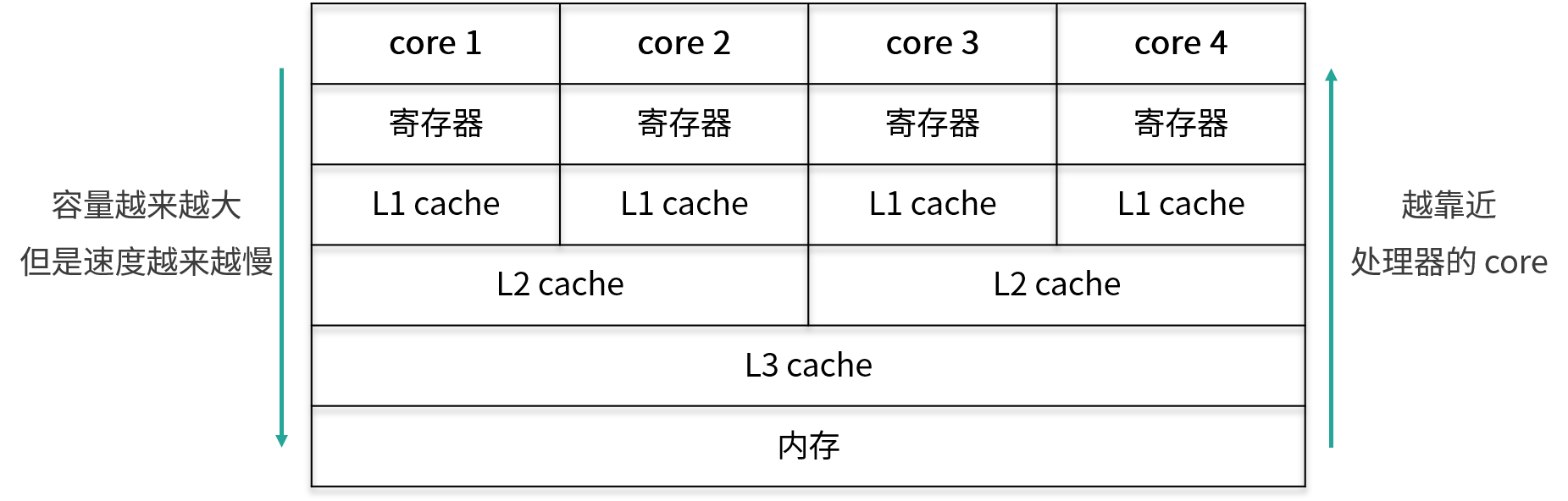
在图中,从下往上分别是内存,L3 缓存、L2 缓存、L1 缓存,寄存器,然后最上层是 CPU 的 4 个核心。从内存,到 L3 缓存,再到 L2 和 L1 缓存,它们距离 CPU 的核心越来越近了,越靠近核心,其容量就越小,但是速度也越快。正是由于缓存层的存在,才让我们的 CPU 能发挥出更好的性能。
其实,线程间对于共享变量的可见性问题,并不是直接由多核引起的,而是由我们刚才讲到的这些 L3 缓存、L2 缓存、L1 缓存,也就是多级缓存引起的:每个核心在获取数据时,都会将数据从内存一层层往上读取,同样,后续对于数据的修改也是先写入到自己的 L1 缓存中,然后等待时机再逐层往下同步,直到最终刷回内存。
假设 core 1 修改了变量 a 的值,并写入到了 core 1 的 L1 缓存里,但是还没来得及继续往下同步,由于 core 1 有它自己的的 L1 缓存,core 4 是无法直接读取 core 1 的 L1 缓存的值的,那么此时对于 core 4 而言,变量 a 的值就不是 core 1 修改后的最新的值,core 4 读取到的值可能是一个过期的值,从而引起多线程时可见性问题的发生。
主内存和工作内存的关系
Java 作为高级语言,屏蔽了 L1 缓存、L2 缓存、L3 缓存,也就是多层缓存的这些底层细节,用 JMM 定义了一套读写数据的规范。
我们不再需要关心 L1 缓存、L2 缓存、L3 缓存等多层缓存的问题,我们只需要关心 JMM 抽象出来的主内存和工作内存的概念。
JMM 有以下规定:
(1)所有的变量都存储在主内存中,同时每个线程拥有自己独立的工作内存,而工作内存中的变量的内容是主内存中该变量的拷贝;
(2)线程不能直接读 / 写主内存中的变量,但可以操作自己工作内存中的变量,然后再同步到主内存中,这样,其他线程就可以看到本次修改;
(3) 主内存是由多个线程所共享的,但线程间不共享各自的工作内存,如果线程间需要通信,则必须借助主内存中转来完成。
volatile 是什么
首先我们就来介绍一下 volatile,它是 Java 中的一个关键字,是一种同步机制。当某个变量是共享变量,且这个变量是被 volatile 修饰的,那么在修改了这个变量的值之后,再读取该变量的值时,可以保证获取到的是修改后的最新的值,而不是过期的值。
相比于 synchronized 或者 Lock,volatile 是更轻量的,因为使用 volatile 不会发生上下文切换等开销很大的情况,不会让线程阻塞。但正是由于它的开销相对比较小,所以它的效果,也就是能力,相对也小一些。
虽然说 volatile 是用来保证线程安全的,但是它做不到像 synchronized 那样的同步保护,volatile 仅在很有限的场景中才能发挥作用,所以下面就让我们来看一下它的适用场景,我们会先给出不适合使用 volatile 的场景,再给出两种适合使用 volatile 的场景。
volatile 的作用
上面我们分析了两种非常典型的用法,那么就来总结一下 volatile 的作用,它一共有两层作用。
第一层的作用是保证可见性。Happens-before 关系中对于 volatile 是这样描述的:对一个 volatile 变量的写操作 happen-before 后面对该变量的读操作。
这就代表了如果变量被 volatile 修饰,那么每次修改之后,接下来在读取这个变量的时候一定能读取到该变量最新的值。
第二层的作用就是禁止重排序。先介绍一下 as-if-serial 语义:不管怎么重排序,(单线程)程序的执行结果不会改变。在满足 as-if-serial 语义的前提下,由于编译器或 CPU 的优化,代码的实际执行顺序可能与我们编写的顺序是不同的,这在单线程的情况下是没问题的,但是一旦引入多线程,这种乱序就可能会导致严重的线程安全问题。用了 volatile 关键字就可以在一定程度上禁止这种重排序。
volatile 和 synchronized 的关系
下面我们就来看一下 volatile 和 synchronized 的关系:
相似性:volatile 可以看作是一个轻量版的 synchronized,比如一个共享变量如果自始至终只被各个线程赋值和读取,而没有其他操作的话,那么就可以用 volatile 来代替 synchronized 或者代替原子变量,足以保证线程安全。实际上,对 volatile 字段的每次读取或写入都类似于“半同步”——读取 volatile 与获取 synchronized 锁有相同的内存语义,而写入 volatile 与释放 synchronized 锁具有相同的语义。
不可代替:但是在更多的情况下,volatile 是不能代替 synchronized 的,volatile 并没有提供原子性和互斥性。
性能方面:volatile 属性的读写操作都是无锁的,正是因为无锁,所以不需要花费时间在获取锁和释放锁上,所以说它是高性能的,比 synchronized 性能更好。
双重检查锁
[63 单例模式的双重检查锁模式为什么必须加 volatile? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/63 单例模式的双重检查锁模式为什么必须加 volatile?.md)
单例模式有多种写法,我们重点介绍一下和 volatile 强相关的双重检查锁模式的写法,代码如下所示:
1 | |
讲到这里就涉及到了一个常见的问题,面试官可能会问你,“为什么要 double-check?去掉任何一次的 check 行不行?”
我们先来看第二次的 check,这时你需要考虑这样一种情况,有两个线程同时调用 getInstance 方法,由于 singleton 是空的 ,因此两个线程都可以通过第一重的 if 判断;然后由于锁机制的存在,会有一个线程先进入同步语句,并进入第二重 if 判断 ,而另外的一个线程就会在外面等待。
不过,当第一个线程执行完 new Singleton() 语句后,就会退出 synchronized 保护的区域,这时如果没有第二重 if (singleton == null) 判断的话,那么第二个线程也会创建一个实例,此时就破坏了单例,这肯定是不行的。
而对于第一个 check 而言,如果去掉它,那么所有线程都会串行执行,效率低下,所以两个 check 都是需要保留的。
在双重检查锁模式中为什么需要使用 volatile 关键字
相信细心的你可能看到了,我们在双重检查锁模式中,给 singleton 这个对象加了 volatile 关键字,那为什么要用 volatile 呢?主要就在于 singleton = new Singleton() ,它并非是一个原子操作,事实上,在 JVM 中上述语句至少做了以下这 3 件事:

- 第一步是给 singleton 分配内存空间;
- 然后第二步开始调用 Singleton 的构造函数等,来初始化 singleton;
- 最后第三步,将 singleton 对象指向分配的内存空间(执行完这步 singleton 就不是 null 了)。
这里需要留意一下 1-2-3 的顺序,因为存在指令重排序的优化,也就是说第 2 步和第 3 步的顺序是不能保证的,最终的执行顺序,可能是 1-2-3,也有可能是 1-3-2。
如果是 1-3-2,那么在第 3 步执行完以后,singleton 就不是 null 了,可是这时第 2 步并没有执行,singleton 对象未完成初始化,它的属性的值可能不是我们所预期的值。假设此时线程 2 进入 getInstance 方法,由于 singleton 已经不是 null 了,所以会通过第一重检查并直接返回,但其实这时的 singleton 并没有完成初始化,所以使用这个实例的时候会报错,
CAS
[65 CAS 和乐观锁的关系,什么时候会用到 CAS? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/65 CAS 和乐观锁的关系,什么时候会用到 CAS?.md)
在本课时中,我们讲解了 CAS 的应用场景。在并发容器、数据库以及原子类中都有很多和 CAS 相关的代码,所以 CAS 有着广泛的应用场景,你需要清楚的了解什么情况下会用到 CAS。
[66 CAS 有什么缺点? (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Java 并发编程 78 讲-完/66 CAS 有什么缺点?.md)
下面我们进行总结,本课时介绍了 CAS 的三个缺点,分别是 ABA 问题、自旋时间过长以及线程安全的范围不能灵活控制。我们了解了它的缺点之后,在进行技术选型的时候就可以有的放矢了。
发生死锁的 4 个必要条件
要想发生死锁有 4 个缺一不可的必要条件,我们一个个来看:
- 第 1 个叫互斥条件,它的意思是每个资源每次只能被一个线程(或进程,下同)使用,为什么资源不能同时被多个线程或进程使用呢?这是因为如果每个人都可以拿到想要的资源,那就不需要等待,所以是不可能发生死锁的。
- 第 2 个是请求与保持条件,它是指当一个线程因请求资源而阻塞时,则需对已获得的资源保持不放。如果在请求资源时阻塞了,并且会自动释放手中资源(例如锁)的话,那别人自然就能拿到我刚才释放的资源,也就不会形成死锁。
- 第 3 个是不剥夺条件,它是指线程已获得的资源,在未使用完之前,不会被强行剥夺。比如我们在上一课时中介绍的数据库的例子,它就有可能去强行剥夺某一个事务所持有的资源,这样就不会发生死锁了。所以要想发生死锁,必须满足不剥夺条件,也就是说当现在的线程获得了某一个资源后,别人就不能来剥夺这个资源,这才有可能形成死锁。
- 第 4 个是循环等待条件,只有若干线程之间形成一种头尾相接的循环等待资源关系时,才有可能形成死锁,比如在两个线程之间,这种“循环等待”就意味着它们互相持有对方所需的资源、互相等待;而在三个或更多线程中,则需要形成环路,例如依次请求下一个线程已持有的资源等。
ES
创建索引的过程:
- 准备待索引的原文档,数据来源可能是文件、数据库或网络
- 对文档的内容进行分词组件处理,形成一系列的 Term
- 索引组件对文档和 Term 处理,形成字典和倒排表
搜索索引的过程:
- 对查询语句进行分词处理,形成一系列 Term
- 根据倒排索引表查找出包含 Term 的文档,并进行合并形成符合结果的文档集
- 比对查询语句与各个文档相关性得分,并按照得分高低返回
面经总结
一
- 自我介绍及项目中的技术问题和优化
自我介绍:
我是一名具有多年经验的 Java 开发工程师,专注于后端开发,对 Java 生态系统中的技术和框架有深入的了解。
项目中的技术问题和优化:
在最近的项目中,我们遇到了系统在高并发场景下性能下降的问题。经过分析,发现是由于数据库访问过于频繁导致的。为了解决这个问题,我引入了缓存机制,使用 Redis 缓存热点数据,减少了数据库访问次数,从而提升了系统性能。
此外,我还对系统中的某些算法进行了优化,比如使用了更高效的数据结构和算法,减少了计算复杂度,提高了处理速度。
- ArrayList 和LinkedList的介绍及优雅创建 ArrayList
ArrayList:
ArrayList 是基于动态数组实现的 List 接口,支持随机访问元素,但在插入和删除元素时可能需要移动其他元素,因此效率较低。
LinkedList:
LinkedList 是基于链表实现的 List 接口,插入和删除元素时效率较高,但访问元素时需要从头或尾开始遍历,因此随机访问效率较低。
优雅创建 ArrayList:
在创建 ArrayList 时,如果预先知道要存储的元素数量,可以通过构造函数指定初始容量,以避免多次扩容带来的性能开销。例如:ArrayList<String> list = new ArrayList<>(10);
- HashMap 底层为何进化成红黑树及红黑树关键点
进化成红黑树的原因:
当 HashMap 中的某个桶(bucket)的链表长度过长时,查找效率会降低。为了解决这个问题,HashMap 在 JDK 1.8 中引入了红黑树来优化性能。当红黑树的节点数少于一定数量时,会退化为链表,以保持简单性。
红黑树关键点:
红黑树是一种自平衡的二叉搜索树,它满足以下五个性质:
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色。
- 所有叶子节点(NIL 或空节点)是黑色。
- 如果一个节点是红色的,则它的两个子节点都是黑色的。
- 对于每个节点,从该节点到其所有后代叶子节点的简单路径上,均包含相同数目的黑色节点。
- HashMap 解决哈希冲突的方式
HashMap 解决哈希冲突的方式主要有两种:
- 拉链法:将哈希值相同的元素存储在同一个桶的链表中。
- 红黑树法(在 JDK 1.8 及以后):当某个桶的链表长度过长时,会转换为红黑树来存储元素,以提高查找效率。
- Java 中哪里用到了开放定址法
在 Java 中,ThreadLocal并没有直接使用开放定址法来解决哈希冲突。ThreadLocal 内部使用了一个简单的哈希表来存储线程局部变量,但具体的冲突解决策略并不是开放定址法。通常,ThreadLocal 的哈希表大小是固定的,并且每个线程都有一个独立的 ThreadLocalMap 实例,因此哈希冲突的情况相对较少。
- ThreadLocal 底层实现原理及并发解决方式
ThreadLocal 底层实现原理:
ThreadLocal 为每个线程提供其自己的变量副本。每个线程在第一次访问某个 ThreadLocal 变量时,ThreadLocal 通过调用其 setInitialValue()方法为该线程创建变量副本,并在 ThreadLocalMap 中以线程为键保存。后续对该变量的访问或修改都是基于线程自己的副本进行的,因此不会影响其他线程。
并发解决方式:
ThreadLocal 通过为每个线程提供独立的变量副本来解决并发问题。由于每个线程都有自己的变量副本,因此不存在多线程间的数据竞争和同步问题。
- ThreadLocal 使用产生的问题、原因及解决方案
产生的问题:
- 内存泄漏:由于 ThreadLocalMap 的生命周期与线程的生命周期相同,如果线程长时间运行而不结束,那么 ThreadLocalMap 中存储的键值对(包括 ThreadLocal 的弱引用和变量的强引用)也无法被垃圾回收,从而导致内存泄漏。
原因:
- ThreadLocalMap 使用 ThreadLocal 的弱引用作为键,而值是强引用。当 ThreadLocal 不再被引用时,由于它是弱引用,可以被垃圾回收。但是,如果 ThreadLocalMap 不被清理,那么它仍然持有值的强引用,导致内存泄漏。
解决方案:
- 在使用完 ThreadLocal 后,显式调用其 remove()方法,从当前线程的 ThreadLocalMap 中移除对应的条目。
- 设计合理的线程池管理策略,避免线程长时间运行。
- 手动实现 Redis 分布式锁
实现 Redis 分布式锁通常涉及以下步骤:
- 使用 Redis 的 SETNX 命令尝试设置一个锁键,并设置过期时间。
- 如果设置成功,则获取到锁,执行临界区代码。
- 执行完临界区代码后,删除锁键。
- 如果设置失败(即锁已被其他客户端持有),则等待或重试。
在实现过程中,需要注意以下几点:
- 锁的粒度:锁的粒度应该尽可能小,以减少锁竞争。
- 锁的过期时间:设置合理的过期时间,避免锁因客户端崩溃或网络问题而长时间无法释放。
- 锁的续期:如果临界区代码执行时间较长,可能需要考虑锁的续期,以避免过期后被其他客户端误抢。
- 避免死锁:确保在异常情况下能够释放锁,避免死锁。
- 实现 Redis 分布式锁时加锁和释放锁需注意的事项
加锁时需注意:
- 设置锁的键值时,应使用唯一标识(如 UUID)作为锁的值,以便于识别锁的持有者。
- 设置锁的过期时间,确保锁不会因客户端异常而长时间持有。
- 考虑使用 Redis 的事务或 Lua 脚本来保证加锁操作的原子性。
释放锁时需注意:
- 在删除锁键之前,应验证当前客户端是否确实持有该锁(即锁的值是否与客户端设置的唯一标识匹配)。
- 仅当客户端确实持有锁时,才应删除锁键,以避免误删其他客户端的锁。
- 考虑使用 Redis 的事务或 Lua 脚本来保证释放锁操作的原子性。
- Redis 淘汰策略中的 LRU 和 LFU,问题及 LFU 后续版本的改进
LRU(Least Recently Used):
LRU 算法淘汰最久未使用的数据。但问题在于,它无法很好地处理“冷数据”突然变为“热数据”的情况。即使这些数据最近被访问过,但由于它们之前长时间未被访问,仍可能被错误地淘汰。
LFU(Least Frequently Used):
LFU 算法根据数据的访问频率来淘汰数据。但它也有问题:一旦某个数据变为热数据,即使之后访问频率降低,它也可能因为之前的高访问频率而长时间留在缓存中。
LFU 后续版本的改进:
为了解决 LFU 的上述问题,后续版本引入了降频机制。降频机制的基本思想是:对于长时间未被访问但访问频率仍然很高的数据,逐渐降低其访问频率计数,使其更容易被淘汰。这样既能保证热数据在缓存中的留存,又能避免冷数据被错误地保留。具体实现时,可以通过为每个数据的访问频率计数设置一个衰减因子或时间窗口来实现降频。
- @SpringApplication 包含的注解及启动流程
@SpringApplication是 Spring Boot 的核心注解,它包含了@SpringBootConfiguration、@EnableAutoConfiguration和@ComponentScan等注解。
@SpringBootConfiguration:声明当前类是配置类,允许使用@Bean注解定义 bean。@EnableAutoConfiguration:根据项目的依赖关系,自动配置 Spring Boot 项目。@ComponentScan:让 Spring 扫描到 Configuration 类并把它加入到程序上下文。
启动流程大致如下:
- 创建 SpringApplication 对象,进行初始化设置。
- 运行 SpringApplication 的 run 方法,执行 Spring 应用的启动流程。
- 创建 Spring 容器,加载并注册配置类。
- 自动配置,根据项目的依赖关系,自动加载和配置相关的 bean。
- 扫描并加载其他组件。
- 运行已注册的 CommandLineRunner。
- Arrays.asList()的注意事项
Arrays.asList()方法返回的是一个固定大小的列表,它不支持增加或删除元素。如果尝试修改列表的大小,会抛出UnsupportedOperationException。此外,返回的列表在结构上与原始数组是紧密关联的,修改原数组的内容也会影响到列表。
- 用 for 循环时如何删除元素
在 for 循环中直接删除元素可能会导致意外的行为或错误,因为删除元素会改变集合的大小,从而影响到循环的迭代。建议使用迭代器(Iterator)来删除元素,或者在删除元素时重新构建一个新的集合。
- synchronized 锁升级过程及锁状态
synchronized 锁在 Java 中主要有四种状态:无锁状态、偏向锁、轻量级锁和重量级锁。锁升级的过程大致是:当线程访问同步块并获取锁时,首先尝试偏向锁;如果失败,则升级为轻量级锁;若轻量级锁竞争失败,则升级为重量级锁。
- 观察者模式及设计模式的七大原则
观察者模式是一种行为设计模式,它定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。当主题对象状态发生变化时,它的所有依赖者(观察者)都会收到通知并自动更新。
设计模式的七大原则包括:
- 单一职责原则:一个类应该只有一个引起变化的原因。
- 开放封闭原则:软件实体(类、模块、函数等)应该是可扩展的,但是不可修改。
- 里氏替换原则:子类必须能够替换其基类。
- 接口隔离原则:使用多个专门的接口,而不使用单一的总接口,客户端不应该依赖它不需要的接口。
- 依赖倒置原则:要依赖于抽象,不要依赖于具体。
- 迪米特法则(最少知道原则):一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立。
- 合成复用原则:尽量使用合成/聚合的方式,而不是使用继承。
- 解决慢 SQL 问题
解决慢 SQL 问题通常涉及以下步骤:
- 使用 SQL 执行计划分析查询。
- 优化索引,确保查询能够高效利用索引。
- 避免在查询中使用 SELECT *,只选择需要的字段。
- 减少 JOIN 操作或优化 JOIN 条件。
- 避免在 WHERE 子句中使用非 SARGable 函数。
- 考虑对数据库进行分区或分片。
- 监控数据库性能,定期审查和调整 SQL 语句。
- 分布式限流及令牌桶算法
分布式限流是为了防止系统因流量过载而崩溃的一种措施。令牌桶算法是其中一种常见的限流算法。
令牌桶算法中,有一个固定容量的令牌桶,以一定的速率往桶里添加令牌。当请求到达时,尝试从桶中取出一个令牌,如果取到令牌则允许请求通过,否则拒绝请求或进行限流处理。这种方式能够平滑地处理突发流量。
- 分布式锁的实现方式
分布式锁的实现方式有多种,包括但不限于:
- 基于数据库实现,如使用数据库的排他锁。
- 基于 Redis 实现,利用 Redis 的 setnx 命令或 RedLock 算法。
- 基于 Zookeeper 实现,利用 Zookeeper 的临时顺序节点和 watch 机制。
- 线程池的核心参数及拒绝策略
线程池的核心参数通常包括:
- corePoolSize:核心线程数,即使线程处于空闲状态,也不会被销毁,除非设置了 allowCoreThreadTimeOut。
- maximumPoolSize:线程池允许的最大线程数。
- keepAliveTime:线程空闲时间,当线程数大于核心线程数时,此为终止前多余的空闲线程等待新任务的最长时间。
- workQueue:用于存放待执行的任务的阻塞队列。
拒绝策略有四种:
- AbortPolicy:直接抛出 RejectedExecutionException 异常。
- CallerRunsPolicy:用调用者所在的线程来执行任务。
- DiscardOldestPolicy:丢弃阻塞队列中等待最久的任务,然后重新尝试执行任务。
- DiscardPolicy:直接丢弃任务,不处理。
JVM 如何判断对象存活
JVM 通过垃圾回收器来判断对象是否存活。主要使用两种算法:引用计数法和可达性分析。现代 JVM 主要使用可达性分析算法。
可达性分析的基本思路是:从一系列称为“GC Roots”的对象开始向下搜索,搜索走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是不可用的。
在 Java 中,可作为 GC Roots 的对象包括:
- 虚拟机栈中引用的对象,如方法中的局部变量。
- 方法区中类静态属性引用的对象。
- JNI(Java Native Interface)中引用的对象。
- 本地方法栈中 JNI 引用的对象。
当进行垃圾回收时,JVM 会遍历这些 GC Roots,然后递归地搜索它们所引用的对象,标记为存活。未被标记的对象则被认为是不可达的,即垃圾对象,可以被回收。
这些面试题涵盖了从基础概念到高级技术的多个方面,需要一定的专业知识才能准确回答。希望以上的回答能够帮助到你,并为你的面试提供有益的参考。
当 Java8 发布时,引入了一系列重大的新特性和改进,其中一些最突出的包括:
1)Lambda 表达式:Lambda 表达式是一种更简洁、更易读的语法,使得函数式编程在 Java 中变得更加方便。它们可以帮助简化集合操作,使代码更具表现力和可读性。
2)Stream API:Stream AP!提供了一种新的抽象,用于处理集合数据。它允许开发人员以声明性的方式对数据进行过滤、映射、排序等操作,从而简化了并行处理和集合操作。 3)新的日期和时间 API:Java8 引入了全新的日期和时间 API,位于 java.time 包中。这个 API 解决了 1 日 API 中一些设计缺陷和线程安全问题,提供了更清晰、更易用的方式来处理日期和时间。 4)默认方法:接口中引入了默认方法,允许在接口中提供默认的方法实现。这使得接口可以更灵活地进行演化,而不会破坏现有的实现。 5)方法引用:方法引用是一种简化 Lambda 表达式的语法,使代码更加简洁易读。它提供了一种直接引用现有方法的方式,而不是为了传递给 Lambda 表达式而编写额外的代码。 6)重复注解:Java8 允许在同一类型或方法上使用多个相同的注解,这使得代码更加整洁和可读。
7)optional 类:Optional 类是一种用于处理可能为 nu 的值的容器类。它提供了一种优雅的方式来避免空指针异常,并鼓励开发人员更加 defensice 的编程风格。
二
好的,我会按照您提供的问题进行逐一解答:
- MySQL 索引与事务
MySQL 索引:
- 索引是数据库表中一列或多列的值进行排序的一种数据结构,其作用是加快数据的检索速度。
- 常见的索引类型有:B-Tree 索引、哈希索引、全文索引等。
- 在创建索引时,需要权衡查询速度与索引维护(如插入、更新、删除操作)的开销。
- 不恰当的索引可能导致性能下降,因此需要根据实际查询需求来创建和优化索引。
MySQL 事务:
- 事务是一系列数据库操作的逻辑单元,这些操作要么全部执行,要么全部不执行。
- 事务具有 ACID 四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
- MySQL 支持事务的存储引擎主要是 InnoDB。
- 在使用事务时,需要注意并发控制,如使用锁来避免脏读、不可重复读和幻读等问题。
- Redis 底层数据结构,Redis 过期策略
Redis 底层数据结构:
- Redis 主要使用了简单动态字符串(SDS)、双端链表、字典、跳跃表、整数集合等数据结构来实现其高效的数据存储和访问。
- 这些数据结构在 Redis 的不同功能中得到了广泛应用,如字符串、列表、集合、有序集合等数据类型。
Redis 过期策略:
- Redis 为每个键设置了过期时间,当键过期时,Redis 会根据过期策略来删除这些键。
- 过期策略主要有两种:惰性删除和定期删除。
- 惰性删除:在访问一个键时,检查该键是否过期,如果过期则删除它。
- 定期删除:Redis 每隔一段时间会随机检查一部分键的过期时间,并删除其中的过期键。
- 此外,Redis 还提供了
FLUSHDB和FLUSHALL命令来主动删除所有键。
- MA 事务消息如何保证消息不丢失
关于 MA 事务消息,我假设您是指某种分布式事务中的消息保证机制。在分布式系统中,确保消息不丢失通常涉及以下策略:
- 消息持久化:确保消息在发送前和发送后都被持久化存储,以防止在故障时丢失。
- 确认机制:接收方在成功处理消息后发送确认给发送方,发送方在收到确认前会重试发送消息。
- 事务日志:记录所有发送和接收的消息,以便在出现问题时可以恢复或重试。
- 重试策略:对于发送失败或未确认的消息,实施合理的重试策略。
- 监控与告警:对消息发送、接收和确认过程进行监控,并在出现异常时及时告警。
- 分布式事务,CAP
分布式事务:
- 在分布式系统中,涉及多个服务或数据库的事务称为分布式事务。
- 分布式事务需要确保跨多个组件的数据一致性和完整性。
- 实现分布式事务的方法包括两阶段提交(2PC)、三阶段提交(3PC)、分布式事务框架(如 Seata)等。
CAP 定理:
- CAP 定理指出,一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个基本需求。
- 在设计分布式系统时,需要根据实际需求权衡这三个属性。
- 大多数分布式系统会选择牺牲一致性(CP)或可用性(AP)来满足分区容错性。
- Spring 循环依赖
Spring 中的循环依赖主要发生在两个或多个 bean 相互依赖对方,形成一个闭环。Spring 容器在初始化这些 bean 时,会遇到无法解析依赖的问题。
Spring 主要使用三级缓存来解决单例模式下的循环依赖问题:
- 一级缓存:singletonObjects,用于存放已经完全初始化好的 bean 实例。
- 二级缓存:earlySingletonObjects,用于存放提前暴露出来的、尚未完成属性填充的 bean 实例(但已经完成了实例化)。
- 三级缓存:singletonFactories,用于存放 bean 的 ObjectFactory 对象,通过这个 ObjectFactory 可以获取到 bean 的早期引用(即尚未完成属性填充的对象)。
当 Spring 检测到循环依赖时,它会利用这些缓存来提前暴露尚未完全初始化的 bean,从而解决循环依赖问题。但需要注意的是,循环依赖并不是一个好的设计实践,应该尽量避免。如果确实存在循环依赖,应该重新审视设计,看是否有更好的解决方案。
三
针对您提出的这些问题,我将逐一进行回答:
- 项目中的难点及解决方案:
- 难点:可能包括性能瓶颈、复杂的业务逻辑、系统稳定性等。
- 解决方案:性能瓶颈可以通过优化算法、使用缓存、分布式部署等方式解决;复杂的业务逻辑可以通过拆分模块、引入中间件、使用设计模式等方式简化;系统稳定性可以通过监控告警、熔断降级、冗余备份等手段提高。
- 数据迁移和流量切换:
- 数据迁移:可以使用数据同步工具或编写脚本进行数据迁移,确保数据的一致性和完整性。迁移前应进行充分的测试,并在低峰时段进行迁移操作。
- 流量切换:可以通过灰度发布、蓝绿部署或 A/B 测试等方式逐步切换流量,确保新系统或新功能上线后的稳定性和可靠性。
- 在项目中负责的内容:
这可能包括但不限于需求分析、系统设计、编码实现、测试部署、系统维护等。具体负责的内容取决于项目的规模、团队分工以及个人的能力和职责。 - 配置中心的设计和大文件传递:
- 配置中心设计:可以基于分布式系统实现,使用数据库或分布式缓存存储配置信息,提供 API 供其他服务获取配置。同时,应支持配置版本控制、动态刷新等功能。
- 大文件传递:可以使用文件传输协议(如 FTP、SFTP)或分布式文件系统(如 HDFS)进行大文件传递。对于特别大的文件,可以考虑分块传输或压缩传输。
- 系统可靠性和多主节点数据一致性:
- 系统可靠性:可以通过冗余备份、负载均衡、容错处理等方式提高系统可靠性。
- 多主节点数据一致性:可以使用分布式一致性协议(如 Raft、Paxos)来确保多主节点之间的数据一致性。这些协议通过选举主节点、日志复制、安全性校验等手段确保数据的最终一致性。
- MQ 如何保证数据不丢失:
- 确保 MQ 的持久化配置正确,消息被写入磁盘。
- 使用确认机制(如 ACK),确保消息被消费者成功处理后再删除。
- 监控 MQ 的运行状态,及时处理异常情况。
- ES 查询快的原因:
Elasticsearch 查询快主要得益于其倒排索引、分布式架构、优化查询算法等特性。倒排索引可以快速定位到包含特定关键词的文档;分布式架构可以并行处理查询请求;优化查询算法可以减少不必要的计算和数据传输。 - Redis 的数据结构和 ZSet:
Redis 支持多种数据结构,包括字符串(string)、哈希(hash)、列表(list)、集合(set)和有序集合(sorted set,即 ZSet)。ZSet 是有序集合,每个元素都会关联一个 double 类型的分数,Redis 正是通过分数来为集合中的元素进行从小到大的排序。 - Redis 的高可用实现方式:
Redis 的高可用可以通过主从复制、哨兵模式(Sentinel)或集群模式(Cluster)实现。主从复制可以实现数据的备份和读写分离;哨兵模式可以自动监测主节点的故障并进行故障转移;集群模式可以实现数据的分片存储和水平扩展。 - Redis 的淘汰策略:
当 Redis 内存使用达到预设的最大值时,Redis 会触发淘汰策略,以释放内存空间。常见的淘汰策略包括:根据键值对的过期时间进行淘汰、随机淘汰、根据键值对的访问频率进行淘汰等。 - 事务请求第三方接口和保存数据库的一致性:
可以使用分布式事务或两阶段提交(2PC)等机制来确保事务的一致性。对于长事务问题,可以考虑拆分事务、使用补偿机制或引入消息队列等方式进行处理。 - Spring 的 IOC 理解和循环依赖的解决:
Spring 的 IOC(控制反转)是一种设计思想,通过 Spring 容器来管理对象的生命周期和依赖关系,降低代码之间的耦合度。循环依赖问题在 Spring 中通常通过构造器注入和 setter 注入的不同处理方式来解决。构造器注入由于是在对象创建时就确定依赖关系,因此无法解决循环依赖问题;而 setter 注入则是在对象创建后通过 setter 方法设置依赖关系,可以通过代理对象等方式解决循环依赖问题。
这些只是一些基本的解答,每个问题实际上都可以深入探讨和扩展。如果您对某个问题有更深入或具体的疑问,欢迎继续提问。
四
Java 异常体系
Java 异常体系是 Java 用来处理程序中可能发生的错误或异常情况的一种机制。异常体系主要分为两大类:Error和Exception。
Error:表示系统级的错误,通常是 Java 虚拟机无法处理的严重问题,如OutOfMemoryError。```
Exception1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
:表示程序需要捕获或声明的异常,是程序可以处理的。它又分为两类:
- `RuntimeException`:运行时异常,通常是由程序逻辑错误导致的,如`NullPointerException`、`ArrayIndexOutOfBoundsException`等。这类异常可以不使用`try-catch`语句捕获,但通常建议捕获以便更好地处理或记录。
- `Checked Exception`:非运行时异常,这类异常在编译时期就必须处理,否则编译不通过。如`IOException`、`SQLException`等。
synchronized 关键字的用法及原理
`synchronized`是 Java 中的一个关键字,用于保证多线程环境下的代码块或方法在同一时刻只能被一个线程访问,实现线程同步。
用法:
1. 修饰实例方法:对整个对象加锁。
2. 修饰静态方法:对类对象加锁,即所有实例共享一把锁。
3. 修饰代码块:指定加锁对象,对给定对象加锁。
原理:
`synchronized`关键字在 JVM 层面通过对象监视器(monitor)实现同步。每个对象都有一个监视器锁,当线程进入`synchronized`方法或代码块时,会尝试获取对象的监视器锁,成功则进入同步代码块,执行完毕后释放锁;失败则阻塞等待,直到获取到锁为止。
**String 对象不可变的原因**
String 对象不可变的原因主要有以下几点:
1. **安全性**:字符串常量池中的字符串是不可变的,这样可以确保字符串在共享时不会被意外修改,提高了程序的安全性。
2. **效率**:字符串拼接时,如果 String 是可变的,每次拼接都需要创建新的对象,效率低下。而不可变的 String 可以利用字符串常量池进行缓存,提高了效率。
3. **哈希码**:由于 String 是不可变的,其哈希码在创建时就已经确定,并且在对象生命周期内保持不变,这对于哈希表等数据结构的实现非常有利。
**StringBuffer、StringBuilder 的区别**
`StringBuffer`和`StringBuilder`都是可变字符串,它们的主要区别在于线程安全性:
- `StringBuffer`是线程安全的,其方法都是同步的,因此适用于多线程环境,但性能相对较低。
- `StringBuilder`是线程不安全的,其方法没有同步,因此适用于单线程环境,性能较高。在单线程环境下,推荐使用`StringBuilder`以提高性能。
**熟悉的设计模式**
设计模式是解决在软件设计中经常遇到的一类问题的最佳实践。常见的设计模式包括:单例模式、工厂模式、观察者模式、原型模式、建造者模式、适配器模式、桥接模式、组合模式、装饰器模式、外观模式、享元模式、代理模式、模板方法模式、迭代器模式、状态模式、策略模式、职责链模式、访问者模式等。
**如何实现单例模式**
单例模式确保一个类仅有一个实例,并提供一个全局访问点。以下是实现单例模式的几种常见方法:
1. **饿汉式**:类加载时就完成初始化,线程安全。
```java
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return instance;
}
}
- 懒汉式(线程不安全):延迟加载,首次使用时才进行初始化。
1 | |
- 懒汉式(线程安全,同步方法):使用
synchronized关键字确保线程安全。
1 | |
- 双重检查锁定(DCL):减少同步开销,但在 JDK 1.5 以前的版本中可能存在单例初始化问题。
1 | |
五
这些问题涉及到了计算机网络、数据结构与算法、数据库和分布式系统等多个领域。下面我将逐一进行回答:
TCP 与 UDP 的区别
:
- TCP(传输控制协议)是面向连接的、可靠的、字节流的协议。它提供流量控制、错误检测和重传机制,确保数据按序到达。
- UDP(用户数据报协议)是无连接的、不可靠的、数据报协议。它不保证数据包的顺序、可靠性或完整性,但传输速度快,常用于实时通信或流媒体。
死锁的产生及解决方法
:
- 死锁发生在两个或更多进程因争夺系统资源而相互等待的现象,若无外力作用,它们都将无法向前推进。
- 解决方法包括:预防死锁(通过资源有序分配等方法避免死锁的发生)、避免死锁(通过银行家算法等确保系统始终处于安全状态)、检测与解除死锁(通过检测机制发现死锁,并采取资源剥夺或撤销进程等方法解除死锁)。
什么时候用数组,什么时候用链表
:
- 数组适用于存储固定大小的数据集,且数据访问频繁。数组在内存中是连续的,因此通过索引访问数据速度快。
- 链表适用于存储动态变化的数据集,且插入和删除操作频繁。链表在内存中不是连续的,通过指针或引用连接各个节点,因此插入和删除操作相对灵活。
红黑树的定义
:
- 红黑树是一种自平衡的二叉查找树,它满足以下五个性质:每个节点要么是红色,要么是黑色;根节点是黑色;所有叶子都是黑色(叶子是 NIL 或空节点);如果一个节点是红色的,则它的两个子节点都是黑色的;对于每个节点,从该节点到其所有后代叶子节点的简单路径上,均包含相同数目的黑色节点。
HashMap
:
- HashMap是 Java 中的一个哈希表实现,它允许存储键值对。HashMap 基于哈希算法存储数据,提供常数时间复杂度的插入和查找操作。HashMap 内部使用数组和链表(或红黑树)来存储数据,当链表长度超过一定阈值时,会转换为红黑树以优化性能。
POST 和 GET 的区别
:
- GET用于请求数据,它将参数附加在 URL 中,大小有限制,且不适合传输敏感信息。GET 请求可以被缓存、书签保存和无限次重放。
- POST用于提交数据,它将参数放在请求体中,大小没有限制,适合传输大量或敏感数据。POST 请求不会被缓存,也不会出现在浏览器的历史记录中。
MySQL 索引
:
- 索引是 MySQL 中用于提高查询性能的一种数据结构。它类似于书籍的目录,可以快速定位到数据库表中的特定数据。常见的索引类型有 B-Tree 索引、哈希索引、全文索引等。
什么情况索引会失效
:
- 索引失效通常发生在以下情况:查询条件中使用函数或表达式;查询中未使用到索引列;查询中使用不等于(<>)或 NOT IN 等操作符;数据类型不匹配导致隐式转换;使用 LIKE 查询时以通配符开头;OR 连接的条件列不是同一个索引等。
事务
:
- 事务是数据库操作的一个逻辑单位,它包含了一系列对数据库的读/写操作。这些操作要么全部成功,要么全部失败,从而保证数据的完整性和一致性。事务具有 ACID 四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
事务实现方法
:
- 事务的实现通常依赖于数据库的支持。在 SQL 中,事务可以通过 BEGIN TRANSACTION 开始,通过 COMMIT 提交,通过 ROLLBACK 回滚。此外,许多编程语言和框架也提供了对事务的支持,如 Java 的 JDBC、Spring 框架等。
JWT(JSON Web Token)
:
- JWT是一种开放标准(RFC 7519)定义的方法,用于在双方之间安全地传输信息。这些信息可以被验证和信任,因为它们是数字签名的。JWT 可以使用 HMAC 算法或者使用 RSA 或 ECDSA 的公钥/私钥对进行签名。JWT 由三部分组成:头部(Header)、负载(Payload)和签名(Signature)。JWT 通常用于身份验证和信息交换,因为它们可以包含所需的所有信息,并且可以在服务器之间安全地传输。
这些只是对这些概念的简要概述。每个主题都有更深入的细节和特定的应用场景,需要根据具体需求进行学习和应用。
六
好的,下面是对您提出的问题的详细回答:
- 索引:
索引是数据库表中一个或多个字段的排序列表,用于加速数据的检索速度。常见的索引类型包括主键索引、唯一索引、普通索引等。索引能够显著提高查询性能,但也会占用额外的存储空间,并可能增加插入、删除和更新操作的开销。 - 索引使用的注意事项:
- 避免过度索引,因为每个索引都需要维护,会占用存储空间并降低写操作的性能。
- 选择最常用作查询条件的字段建立索引。
- 考虑索引的选择性,即索引中不同值的比例,高选择性的索引通常更有效。
- 对于联合索引,要注意字段的顺序,因为索引是按照字段顺序进行排序的。
- 定期维护索引,例如重建或重新组织索引,以保持其性能。
- 索引使用的数据结构:
大多数数据库系统使用 B+树或其变种作为索引的数据结构。B+树是一种平衡的多路搜索树,能够保持数据的有序性,并且具有良好的查询性能。 - 为什么是 B+树:
- B+树能够保持数据的有序性,这对于范围查询非常有利。
- B+树的非叶子节点不存储数据,只存储关键字和子节点的指针,这使得 B+树能够比 B 树存储更多的关键字,降低树的高度,减少查询时的磁盘 I/O 次数。
- B+树的叶子节点之间通过指针相连,方便进行范围查询。
- 联合索引在非叶子节点是原子性的吗:
联合索引在非叶子节点不是原子性的。联合索引的每个字段在树的不同层级上可能作为索引的一部分,但在非叶子节点上不会存储完整的记录或数据行。非叶子节点只存储索引关键字和指向下一级节点的指针。 - 走索引范围查询的原理和全流程:
范围查询利用索引的有序性,通过遍历索引树来找到满足条件的记录。首先,根据查询条件的起始值,在索引树中定位到起始节点;然后,沿着索引树的路径向下遍历,直到找到所有满足条件的叶子节点;最后,返回这些叶子节点对应的记录。 - 创建不可改变的集合:
在 Java 中,可以使用Collections.unmodifiableCollection方法将一个已存在的集合转换为不可修改的集合。这个不可修改的集合在试图修改时会抛出UnsupportedOperationException。 - 创建不可被修改的对象:
创建不可被修改的对象通常涉及将对象的所有字段都设置为final,并确保没有提供修改这些字段的方法。此外,对于集合类型的字段,可以使用不可修改的集合来确保它们的内容也不会被修改。 - HashMap 的底层:
HashMap 的底层实现主要基于数组和链表(在 Java 8 及以后版本中,当链表长度达到一定阈值时,会转换为红黑树)。HashMap 通过哈希函数将键(key)映射到数组的某个索引位置,如果该位置已经存在元素,则通过链表或红黑树解决冲突。 - 为什么用红黑树:
HashMap 在链表长度过长时转换为红黑树是为了优化性能。红黑树是一种自平衡的二叉搜索树,能够在动态插入和删除操作中保持相对平衡,从而确保查询、插入和删除操作的时间复杂度接近 O(log n)。这有助于避免在链表过长时导致的性能下降。 - Spring Boot 自动装配与反射的关系:
Spring Boot 的自动装配功能在很大程度上依赖于 Java 反射机制。通过反射,Spring 容器能够在运行时动态地创建对象、调用方法、访问字段等。自动装配则是 Spring 框架根据配置文件或注解自动创建和装配 bean 的过程。在这个过程中,Spring 利用反射来实例化 bean、注入依赖等。 - AOP 动态代理的原理:
AOP(面向切面编程)通过动态代理技术实现。在 Java 中,动态代理主要有两种实现方式:基于接口的 JDK 动态代理和基于类的 CGLIB 动态代理。JDK 动态代理利用反射机制在运行时动态生成代理类,代理类实现与目标对象相同的接口,并拦截对目标对象方法的调用。CGLIB 则通过继承目标类来创建代理子类,并覆盖目标方法以实现代理逻辑。 - G1 回收器的原理:
G1(Garbage-First)回收器是 Java 虚拟机(JVM)中的一种垃圾回收器,旨在提供可预测的停顿时间,同时保持较高的吞吐量。G1 将堆内存划分为多个大小相等的区域(Region),并优先回收垃圾最多的区域。它采用了一种标记-复制-清理的算法,通过跟踪对象的引用关系来标记存活对象,并将存活对象复制到新的区域中,然后清理旧区域中的垃圾。G1 还通过优先回收垃圾最多的区域来优化性能,减少全堆扫描的开销。
七
- 红黑树的特征以及 HashMap 选择红黑树的原因:
红黑树是一种自平衡的二叉搜索树,它满足以下五个特性:
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色。
- 所有叶子节点(NIL 或空节点)是黑色。
- 如果一个节点是红色,则它的两个子节点都是黑色。
- 对于每个节点,从该节点到其所有后代叶子节点的简单路径上,均包含相同数目的黑色节点。
HashMap 选择红黑树作为链表过长时的替代结构,主要是因为红黑树在查找、插入和删除操作上的时间复杂度都是 O(log n),相较于链表(O(n))有更好的性能。当 HashMap 中的桶(bucket)链表长度超过一定阈值时,将其转换为红黑树可以显著提高性能。然而,当树的大小小于某个阈值时,为了避免树的维护开销,它会退化为链表。
- 线程安全的集合:
Java 中线程安全的集合主要包括:
VectorHashtableCollections工具类中的同步包装方法(如Collections.synchronizedList)包装后的集合ConcurrentHashMap(适用于高并发场景)CopyOnWriteArrayList(读多写少的场景)
这些集合通过内部同步机制或特殊的并发控制策略来保证线程安全。
- Spring AOP 与 AspectJ 的区别:
Spring AOP 和 AspectJ 都提供了面向切面编程(AOP)的功能,但它们之间存在一些区别:
- Spring AOP 是基于代理的,它只能拦截通过 Spring 容器管理的 bean 之间的方法调用。而 AspectJ 则是一个完整的 AOP 框架,它提供了编译时和加载时的织入,能够拦截任何方法调用,不仅仅是 Spring 容器管理的 bean。
- Spring AOP 支持的通知类型较少,而 AspectJ 支持更丰富的通知类型,如环绕通知等。
- AspectJ 的功能更为强大,但使用起来也相对复杂一些。Spring AOP 则更加轻量级和易于集成到 Spring 应用中。
- Spring 中 AOP 的 JDK 动态代理与 CGLIB 代理的区别及替代方案:
JDK 动态代理是基于接口的代理,它要求被代理的对象必须实现一个或多个接口。而 CGLIB 代理是基于类的代理,通过继承目标类来创建代理对象,因此目标类不能是 final 类。
如果不用 JDK 动态代理和 CGLIB 代理,还可以使用 AspectJ 来实现 AOP。AspectJ 提供了更为强大的 AOP 功能,包括编译时和加载时的织入。
- JVM 如何与操作系统交互:
JVM 通过 JNI(Java Native Interface)与本地方法库进行交互,从而可以调用操作系统提供的本地方法。此外,JVM 还通过文件系统、网络、进程间通信(如管道、信号、共享内存等)与操作系统进行交互。例如,JVM 加载类文件时需要访问文件系统;JVM 中的线程实际上是操作系统中的线程或进程,因此线程的管理和调度也涉及到与操作系统的交互。
- HTTP 协议简介:
HTTP(Hypertext Transfer Protocol)是一种应用层协议,用于在 Web 浏览器和服务器之间传输超文本。它基于请求-响应模型,客户端(如浏览器)发送请求到服务器,服务器处理请求并返回响应。HTTP 协议是无状态的,即服务器不会记住之前与客户端的交互信息。HTTP/1.1 版本中引入了持久连接(keep-alive)和管道化(pipelining)等特性来提高性能。此外,还有 HTTP/2 版本,它进一步通过多路复用、头部压缩等技术优化了性能。
- 进程间通信(IPC):
进程间通信(IPC)是指在不同进程之间传递信息或数据的方式。常见的 IPC 机制包括:
- 管道(Pipe):用于父子进程之间的通信。
- 消息队列(Message Queue):允许进程之间通过发送和接收消息来进行通信。
- 共享内存(Shared Memory):允许多个进程访问同一块内存区域,从而实现数据的共享和通信。
- 信号量(Semaphore):用于同步和互斥,确保多个进程对共享资源的正确访问。
- 套接字(Socket):用于不同主机之间的进程通信,是网络编程的基础。
- 用 Redis 实现分布式事务:
Redis 本身不支持传统的 ACID 事务,但可以通过一些策略来实现分布式事务的效果。一种常见的方法是使用 Redis 的事务(MULTI/EXEC)和 Lua 脚本,结合 watch 机制来检测键的变化。另外,还可以利用 Redis 的发布订阅功能来协调多个客户端的操作,实现分布式事务的提交或回滚。在实际应用中,可能还需要结合业务逻辑和补偿机制来确保事务的完整性和一致性。
- Web 请求过程:
Web 请求过程通常涉及以下步骤:
- 用户输入 URL:用户在浏览器的地址栏中输入一个网址(URL)。
- DNS 解析:浏览器向 DNS 服务器发出请求,将输入的域名解析为对应的 IP 地址。
- 建立 TCP 连接:浏览器通过 TCP 协议与服务器建立连接。如果是 HTTPS 协议,则还需进行 SSL/TLS 握手,以建立加密的通信通道。
- 发送 HTTP 请求:浏览器根据用户在地址栏中输入的 URL,或者通过表单、AJAX 等方式,构建 HTTP 请求,并通过 TCP 连接发送给服务器。
- 服务器处理请求:服务器接收到 HTTP 请求后,根据请求的 URL 和 HTTP 方法(如 GET、POST 等),找到对应的处理程序或资源,并进行相应的处理。这可能涉及读取数据库、执行业务逻辑、生成动态页面等。
- 发送 HTTP 响应:服务器处理完请求后,生成 HTTP 响应,并通过 TCP 连接发送回浏览器。响应中包含状态码(如 200 表示成功,404 表示未找到资源等)、响应头和响应体(如 HTML 页面、JSON 数据等)。
- 浏览器解析渲染:浏览器接收到 HTTP 响应后,解析响应头和内容,并根据需要加载相关的资源(如 CSS、JavaScript、图片等)。然后,浏览器引擎将 HTML 内容渲染成用户可以看到的页面。
- 断开 TCP 连接:在数据传输完成后,浏览器和服务器通常会断开 TCP 连接。如果是 HTTP/1.1 中的持久连接(keep-alive),连接可能会保持一段时间以便复用,但在一段时间后或双方同意的情况下,连接仍会被关闭。
整个 Web 请求过程中,还可能涉及缓存机制、重定向、负载均衡、代理服务器等技术或组件,这些都会影响请求的处理和响应的速度。同时,安全性也是 Web 请求过程中需要考虑的重要因素,包括 HTTPS 加密、防止跨站脚本攻击(XSS)、跨站请求伪造(CSRF)等安全措施的应用。
八
好的,我会一一回答你的问题。
- 项目介绍
项目介绍通常包括项目的背景、目标、主要功能、技术栈、面临的挑战以及解决方案等。具体的内容会根据实际项目的不同而有所差异。例如,一个电商项目可能会介绍其如何实现商品展示、购物车管理、订单处理等功能,以及使用了哪些技术栈(如 Spring Boot、MySQL、Redis 等)来构建这个项目。
- MQ(消息队列)如何保证数据不丢失,消息消费失败了怎么办,消费者数量怎么设计
数据不丢失
:
- 使用持久化存储:确保消息队列将数据持久化到磁盘或其他可靠存储中。
- 确认机制:生产者发送消息后,等待消息队列的确认;消费者消费消息后,也发送确认消息给队列。
- 备份和恢复:定期备份消息队列数据,以便在出现问题时可以恢复。
消息消费失败
:
- 重试机制:消费者消费失败时,可以设定重试次数和重试间隔。
- 死信队列:将多次重试仍失败的消息发送到死信队列,由专门的程序或人工处理。
- 延迟队列:对于需要延迟处理的消息,可以使用延迟队列。
消费者数量设计
:
- 根据业务需求和系统性能来设计。
- 考虑消息的处理速度、系统的负载能力、消息的实时性等因素。
- 可以动态调整消费者数量以应对流量变化。
- ES(Elasticsearch)的特性、分词、倒排、排序
- 特性:
- 分布式搜索引擎。
- 实时分析。
- 近实时的搜索和分析。
- 全文搜索。
- 结构化搜索。
- 分词:将文本切分为单个的词或词组,以便进行索引和搜索。
- 倒排索引:Elasticsearch 的核心数据结构,用于快速查找包含特定词的文档。
- 排序:Elasticsearch 支持多种排序方式,如按字段值排序、按距离排序等。
- MySQL 相关
- 索引覆盖:查询只需要通过索引就可以获取到数据,无需回表到数据行。
- 联合索引:多个字段组合在一起的索引,使用时需遵循最左前缀原则。
- 回表:当查询的字段不是索引的全部时,需要回到数据行中获取剩余字段的值。
- 查看索引使用情况:可以通过
EXPLAIN命令查看查询是否使用了索引,以及使用了哪个索引。 - 索引失效:如使用函数、隐式类型转换等都可能导致索引失效。
- **四大特性(ACID)**:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
- 线程池
- 拒绝策略:
- AbortPolicy:直接抛出异常。
- CallerRunsPolicy:调用者运行任务,即让提交任务的线程自己执行该任务。
- DiscardOldestPolicy:丢弃队列中等待最久的任务,然后重新尝试执行任务。
- DiscardPolicy:直接丢弃任务,不做任何处理。
- CallerRunsPolicy 详解:当线程池队列已满,且线程池中的线程数量也达到最大值时,如果继续提交任务,就会使用 CallerRunsPolicy 策略。这时,提交任务的线程会自己执行该任务,而不是将任务丢弃或抛出异常。这样可以确保任务不会被丢失,但也可能导致提交任务的线程被阻塞,从而影响系统的性能。
- 线程创建方式:
- 继承 Thread 类并重写 run 方法。
- 实现 Runnable 接口并重写 run 方法。
- 实现 Callable 接口并重写 call 方法(可以返回结果并抛出异常)。
- 使用线程池(如 ExecutorService)。
- ThreadLocal
- ThreadLocal:提供线程内的局部变量。每个线程都有自己独立的变量副本,不会和其他线程的变量互相干扰。
- 用途:常用于保存线程上下文信息,如数据库连接、用户信息等。
- 注意事项:使用完毕后要及时清理 ThreadLocal 中的变量,避免内存泄漏。
希望这些回答能帮到你!如果你有其他问题或需要更详细的解释,请随时告诉我。
电子名片项目回答思路
1. EasyExcel 实现数据导入与导出
问题:系统需要快速、高效地将大量在职员工列表和财务税收数据导入到数据库中,同时还能快速导出这些数据。
解决方案
选择 EasyExcel:我们选择 EasyExcel 库来处理 Excel 文件。它相较于传统的 Apache POI 有更高的性能,特别是在处理大文件时,内存占用非常小。
监听器机制:在使用 EasyExcel 导入数据时,我们可以通过监听器来监听每一行数据的读取,并在此过程中对数据进行校验或者处理,比如确保数据格式正确。
导入实现
- 首先定义一个 Java 类来表示每一行的数据,比如员工信息(姓名、工号、职位等)。
- 然后,使用 EasyExcel 提供的
read方法去读取 Excel 文件,并通过监听器处理每一行的员工数据,将其保存到数据库中。
导出实现
- 导出时,通过 EasyExcel 的
write方法,将数据库中的员工列表或财务数据转化为 Excel 文件并输出。
- 导出时,通过 EasyExcel 的
- 通俗理解:EasyExcel 就像是一个效率极高的“导入导出助手”,能轻松帮你处理成千上万条数据,并且它操作起来又快又不占内存。
2. 消息列表展示与审核机制
问题:系统需要展示消息列表,并标记消息的状态(如已读、未读、待处理等),并且需要对消息内容进行审核。
解决方案
消息状态管理:为了实现消息的状态标记,我们可以在数据库的消息表中增加一个状态字段,比如
status,用来记录每条消息的状态。前端展示:当用户请求消息列表时,后端会根据消息状态字段,返回已读、未读、待处理等不同状态的消息,并在前端展示不同的标记。
身份校验与审核
- 每次发送消息前,系统会先校验发送者的身份,确保只有合法用户才能发送消息。
通过后台的审核机制,自动或手动审核消息内容,检测是否含有敏感词。审核结果会实时通过 WebSocket 推送给发送者。
通俗理解:系统就像一个邮箱,不仅能自动帮你标记消息是否已读、未读,还会检查你发送的消息是否合法,确保消息内容合规。
3. 二维码邀请与分享机制
问题:需要生成二维码,帮助企业员工邀请新入职员工加入部门,并记录每次邀请的情况。
解决方案
生成二维码:当员工发出邀请时,系统会生成一个包含邀请链接的二维码。这可以通过 ZXing 或 QRCode 这样的库来实现。
邀请链接与分享海报
- 邀请链接会携带必要的参数,如邀请人的 ID、部门信息等。当新员工扫码后,会根据这些参数进行处理,引导新员工完成注册流程并加入相应的部门。
- 同时,生成的二维码可以嵌入到海报中,通过分享海报让更多人扫码加入。
记录邀请情况:每次扫码注册成功后,系统会在数据库中记录邀请信息,并更新对应部门的员工信息。
- 通俗理解:二维码就像是员工的“邀请函”,发给新员工扫码后,系统会帮他们自动注册并加入到对应的部门。
4. 代码自动生成工具
问题:开发过程中频繁需要编写数据库的增删改查(CRUD)代码,为了提高开发效率,自动生成代码非常重要。
解决方案
代码生成器:使用 MyBatis-Plus 这类 ORM 框架的代码生成器,可以根据数据库的表结构,自动生成对应的 Java 代码,比如增删改查的接口、服务类等。
配置模板:通过模板引擎(如 Freemarker),我们可以定义一个标准的代码结构,然后将数据库表的字段信息动态填充到这些模板中,生成实际的代码文件。
自动生成代码流程
- 开发人员只需要输入数据库表的名称,生成器会自动生成相应的 Controller、Service、Mapper 层代码。
- 通俗理解:就像有一个“代码生成机器”,只要输入数据库表的信息,它就能自动生成大量代码,不用你每次都手动写 CRUD 操作。
5. Java 8 Stream API 优化集合处理
问题:在处理复杂的集合数据时,比如为企业列表关联已加入的员工信息,使用传统的循环方式处理代码会比较繁琐和低效。
解决方案
- Stream API:Java 8 引入的 Stream API 提供了处理集合的高级功能,比如过滤、排序、映射等操作,代码更加简洁,效率也更高。
- Lambda 表达式:结合 Stream API 使用 Lambda 表达式,可以更简洁地编写代码,实现集合操作的链式调用,比如
stream().filter().map().collect()。 - 并行流处理:当需要处理大量数据时,可以使用
parallelStream()来并行处理,提高性能。
- 通俗理解:Stream API 就像是一条流水线,可以自动帮你过滤、筛选和处理集合数据,大大减少了手动编写的代码,并且能并行处理,速度更快。
6. SQL 优化与库表管理
问题:需要优化企业名片和通讯录的查询性能,特别是处理大规模数据时,查询效率很重要。
解决方案
- 索引优化:为常用的查询字段(如员工 ID、部门 ID)添加数据库索引,减少查询时的全表扫描。
- 查询优化:在查询 SQL 时避免使用
SELECT *,只查询需要的字段,同时控制分页查询,避免一次性返回过多数据。 - 表结构设计:在设计数据库表时,遵循 数据库规范化 原则,减少数据冗余,同时合理设计表与表之间的外键关联,确保数据一致性。
- 通俗理解:就像你在图书馆查书,提前为书籍创建分类索引,能让你更快找到目标书籍,而不是每次都从头翻到尾。
7. Git 版本管理与禅道 Bug 跟踪
问题:在多人协作开发中,如何有效管理项目的代码版本和 Bug 修复进度,保证项目的有序推进。
解决方案
Git 版本管理
- 分支管理:开发时使用不同的分支,比如
master(主分支)、develop(开发分支)、feature(功能分支)来隔离不同阶段的开发代码,防止冲突。 - 冲突解决:多人协作时,如果不同分支的代码发生冲突,Git 会提示你手动解决冲突,然后合并到主分支。
- 分支管理:开发时使用不同的分支,比如
禅道 Bug 跟踪
- 在禅道中提交 Bug,并指派给相关开发人员处理。开发人员修复后,会提交相关说明,等待测试人员验收。
每个 Bug 的状态(如待解决、已解决、待验收等)都能在禅道中清晰地追踪。
通俗理解:Git 就像是项目的“时间机器”,随时可以回到过去的代码版本,而禅道就是一张问题清单,帮你记录并跟踪每一个 Bug 的状态。
1. EasyExcel 实现数据导入与导出
问题背景:
在系统中,存在大量员工数据(如在职员工信息、财务税收数据等),这些数据需要高效地导入到数据库,并且系统还需要支持快速将这些数据导出为 Excel 文件,供外部使用。传统的 Apache POI 库在处理大文件时内存消耗较高,因此选择了性能更优的 EasyExcel 来进行数据处理。
技术选型:EasyExcel
EasyExcel 是阿里巴巴开源的一款 Excel 读写库,相比 Apache POI 具有以下优势:
- 性能更优:EasyExcel 内部使用流式读取与写入,处理大文件时占用内存非常少,能处理百万级的数据。
- 简化代码:EasyExcel 提供了简洁的 API,能轻松实现复杂的 Excel 读写操作。
- 监听器机制:它通过 Listener 机制,在读取 Excel 时可以一行一行地处理数据,避免一次性读取整个文件占用大量内存。
详细解决方案:
1. 数据导入(Read)
我们需要将 Excel 文件中的员工数据导入到数据库中,操作流程如下:
定义数据模型:
先定义一个对应 Excel 每一行的 Java 类。例如:
1
2
3
4
5
6
7public class Employee {
private String name;
private String employeeId;
private String department;
private BigDecimal salary;
// getters and setters
}这个类的每一个字段代表 Excel 文件中的一列数据。
编写监听器处理数据:
EasyExcel 通过自定义的 Listener 来监听每一行数据的读取和处理。
编写一个继承
AnalysisEventListener<T>的类,实现invoke()方法,这个方法会被逐行调用,在这里可以对每一行数据进行校验和保存到数据库。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class EmployeeDataListener extends AnalysisEventListener<Employee> {
private EmployeeService employeeService;
public EmployeeDataListener(EmployeeService employeeService) {
this.employeeService = employeeService;
}
@Override
public void invoke(Employee employee, AnalysisContext context) {
// 数据校验逻辑
if (isValid(employee)) {
employeeService.save(employee); // 保存到数据库
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
System.out.println("所有数据解析完成!");
}
}
读取 Excel 文件:
使用
EasyExcel.read()方法读取 Excel 文件,指定文件路径、Java 类和监听器。1
EasyExcel.read(filePath, Employee.class, new EmployeeDataListener(employeeService)).sheet().doRead();EasyExcel 会自动处理 Excel 文件的行列数据,并将其映射到
Employee对象上,然后调用监听器中的invoke()方法进行处理。
2. 数据导出(Write)
导出功能的目的是将数据库中的数据转换为 Excel 文件,流程如下:
准备数据:
从数据库中查询员工列表数据,转换成 List 对象,供 EasyExcel 使用。
1
List<Employee> employees = employeeService.getAllEmployees();
生成 Excel 文件:
使用
EasyExcel.write()方法将数据写入 Excel 文件。1
EasyExcel.write(filePath, Employee.class).sheet("员工信息").doWrite(employees);这会将 List 中的每一个
Employee对象转换成 Excel 的一行数据,并将它们写入到指定的文件中。
关键技术点:
- 流式处理:EasyExcel 采用流式处理机制,能够以低内存占用读取和写入大文件,尤其适合大规模数据的导入导出。
- Listener 机制:通过监听器可以逐行处理 Excel 数据,避免一次性加载大量数据造成内存溢出,并且可以在读取过程中对每行数据进行校验和逻辑处理。
- 快速导出:EasyExcel 提供了简洁的
write()方法,直接将数据写入到 Excel 文件,并支持自定义列名、样式等,方便进行批量数据导出。
示例代码总结:
- 数据导入:
- 通过监听器逐行读取 Excel 数据,并根据业务规则进行数据校验和保存。
- 数据导出:
- 从数据库中查询员工数据,通过
write()方法生成 Excel 文件,并返回给前端或直接下载。
- 从数据库中查询员工数据,通过
通俗理解:
EasyExcel 就像是 Excel 文件的“超级速递员”——当我们需要导入成千上万条数据时,它可以一行一行地将数据快速搬运到数据库中,不会因为文件太大而“卡住”。导出时,它也能迅速地将数据从数据库打包成 Excel 文件,速度快、效率高,而且占用内存很少,非常适合处理大规模的数据。
总结:
EasyExcel 是一个非常轻量且高效的 Excel 处理工具,通过其 Listener 机制,系统可以在导入过程中进行数据校验和处理,同时在导出时以极高的性能生成 Excel 文件。这样大大简化了开发工作,并且提升了系统在处理大数据量时的效率和稳定性。
2. 消息列表展示与审核机制
问题背景:
系统需要展示用户的消息列表,并对每条消息进行状态标记(如已读、未读、待处理等)。同时,为了保证消息内容的合法性和安全性,系统需要在用户发送消息时进行身份校验,并通过审核机制过滤不良内容。
详细解决方案:
1. 消息状态管理
为了标记消息的状态,系统可以在数据库的消息表中为每条消息增加一个
status字段,用于记录消息的当前状态,如:- 未读(未查看的消息)
- 已读(用户已查看的消息)
- 待处理(需要处理的消息,如审核中的消息)
- 已处理(消息处理完毕或审核通过)
数据库表结构设计:
1
2
3
4
5
6
7
8
9CREATE TABLE messages (
id INT PRIMARY KEY AUTO_INCREMENT,
sender_id INT, -- 发送者的用户 ID
receiver_id INT, -- 接收者的用户 ID
content TEXT, -- 消息内容
status VARCHAR(20), -- 消息状态:未读、已读、待处理等
created_at TIMESTAMP, -- 消息创建时间
updated_at TIMESTAMP -- 消息状态更新时间
);2. 消息状态更新与前端展示
后端处理:
当用户发送消息时,后端会自动为这条消息设置初始状态为“未读”或“待处理”,并存储在数据库中。前端展示:
前端通过调用消息列表 API 获取用户的所有消息记录,后端会根据每条消息的status字段返回对应的状态。前端可以根据状态显示不同的 UI 标记,比如:- 未读消息:显示不同的颜色或者加粗文字。
- 已读消息:显示为普通文字。
- 待处理消息:可以标记为需要用户操作或等待审核结果。
状态更新:
当用户点击某条消息后,前端会发送请求通知后端更新消息状态为“已读”。后端会接收请求并更新消息状态:1
2
3UPDATE messages
SET status = '已读', updated_at = NOW()
WHERE id = :messageId;
3. 身份校验与审核机制
身份校验:
在用户发送消息前,后端需要校验发送者的身份,确保发送者是合法用户。可以通过 JWT 或 Session 检查用户的登录状态,确保只有合法的、经过认证的用户才能发送消息。- 当用户发送请求时,后端会检查用户的身份令牌(如 JWT),通过验证后允许继续发送消息。
- 如果身份校验失败,系统会返回错误提示,阻止消息发送。
消息审核机制:
消息发送后,系统会对消息内容进行自动或人工审核,以防止敏感或违规信息传播。审核机制分为以下几个步骤:自动审核:
系统可以配置一个敏感词库,使用算法或正则表达式对消息内容进行快速检查。比如:1
2
3
4
5
6
7String content = message.getContent();
if (containsSensitiveWords(content)) {
message.setStatus("待处理");
notifyUser(message.getSenderId(), "消息内容含有敏感词,正在审核中...");
} else {
message.setStatus("已读");
}手动审核:
对于一些自动审核未能判定的内容,系统可以将其标记为“待处理”,并推送给管理员进行人工审核。管理员通过后台审核消息后,可以手动更改消息状态为“通过”或“拒绝”,并反馈给用户。审核结果实时推送:
审核通过或拒绝的结果可以通过 WebSocket 实时推送给发送者。WebSocket 是一种能够进行双向通信的协议,确保审核结果能在第一时间通知到用户。前端可以监听审核结果的推送事件,并更新 UI,通知用户审核结果。
4. 通俗理解
- 消息状态管理: 系统像一个智能邮箱,每条消息都会根据其状态进行标记,比如已读、未读或需要处理。这样用户一眼就能知道哪些消息已经看过,哪些还需要处理。
- 身份校验与审核机制: 系统不仅会验证发送消息的用户是否合法,还会自动审查消息内容,确保没有违规或敏感信息。如果发现有问题,消息会被标记为“待处理”并进入审核环节,最终通过或拒绝的结果会及时通知用户。
实现流程总结
消息状态更新与展示:
- 用户发送消息后,消息初始状态为“未读”或“待处理”。
- 用户查看消息时,系统自动将其状态更新为“已读”。
- 消息列表根据状态不同,在前端展示时会有不同的标记,帮助用户区分处理状态。
身份校验与审核:
- 系统在用户发送消息前,先校验用户身份,确保合法用户才能发送消息。
- 发送后,系统通过自动审核(敏感词检查)和手动审核,过滤违规信息,审核结果会通过 WebSocket 实时推送给用户。
通俗理解总结:
系统就像一个智能邮箱和安全审查员,不仅能自动帮你标记哪些消息已经读过、哪些需要处理,还会对你发送的每条消息进行“身份验证”和“内容检查”。如果消息中有问题,它会通知你正在审核中,审核通过后还会第一时间告诉你结果。
3. 二维码邀请与分享机制
问题背景:
企业员工需要方便地邀请新入职员工加入部门,并且公司需要追踪每次邀请的记录,以便分析和管理。为此,系统需要生成一个二维码,供新员工扫码注册,同时确保邀请信息(如邀请人、部门信息等)被正确记录和处理。
解决方案:
1. 生成二维码
当员工发送邀请时,系统需要生成一个二维码,其中包含一个携带邀请参数的链接。这个过程可以通过使用 ZXing 或 QRCode 这样的库来生成二维码。
生成二维码的步骤:
生成邀请链接:系统会为每次邀请生成一个唯一的链接,其中包含重要的参数信息,例如邀请者的 ID、部门 ID、邀请时间等。这些参数将用于后续新员工扫码时处理。
- 示例链接格式:
1
https://company.com/register?inviterId=123&departmentId=456&inviteTime=2023-09-01
- 示例链接格式:
二维码生成:系统会使用 ZXing 或 QRCode 库生成一个二维码,二维码中嵌入上面的邀请链接。生成的二维码可以作为图片直接供前端展示或下载。
生成二维码的代码示例(基于 ZXing):
1
2
3
4String inviteLink = "https://company.com/register?inviterId=123&departmentId=456";
BitMatrix bitMatrix = new QRCodeWriter().encode(inviteLink, BarcodeFormat.QR_CODE, width, height);
Path path = FileSystems.getDefault().getPath("inviteQRCode.png");
MatrixToImageWriter.writeToPath(bitMatrix, "PNG", path);
2. 邀请链接与分享海报
生成二维码后,系统不仅可以直接提供二维码图片,还可以将二维码嵌入到一个 邀请海报 中,增强视觉效果,并通过各种社交平台进行分享。
邀请链接:
- 当新员工扫码后,系统会解析二维码中的链接参数。通过参数,后端能够知道是由哪位员工发出的邀请以及哪个部门的邀请。
- 新员工通过扫码进入注册页面,完成注册并加入到对应的部门。注册成功后,系统会根据邀请者的 ID 和部门 ID 将新员工与该部门关联起来。
分享海报:
- 邀请海报可以通过 HTML5 Canvas 或类似的工具生成。它通常包括公司的 logo、宣传口号、二维码等,员工可以通过海报邀请新同事加入。
- 海报生成示例思路:
- 创建一个基础海报模板,包含公司品牌、宣传标语等元素。
- 生成的二维码嵌入到海报的指定位置。
- 允许员工通过微信、企业微信等社交平台进行分享,吸引新员工扫码加入。
3. 记录邀请情况
为了追踪每次邀请和扫码的情况,系统需要记录每一次扫码和注册的行为。特别是要记录下:
- 邀请人 ID:谁发出了邀请。
- 被邀请人 ID:新入职员工的身份。
- 扫码时间:新员工扫码的时间。
- 邀请结果:新员工是否成功注册并加入部门。
数据库记录的表结构可以设计如下:
1
2
3
4
5
6
7
8
9CREATE TABLE invite_logs (
id INT PRIMARY KEY AUTO_INCREMENT,
inviter_id INT, -- 邀请人的用户 ID
invitee_id INT, -- 被邀请人的用户 ID
department_id INT, -- 邀请涉及的部门
invite_time TIMESTAMP, -- 邀请发出时间
register_time TIMESTAMP, -- 被邀请人注册时间
status VARCHAR(20) -- 邀请状态:已扫码、已注册、已加入部门
);当新员工成功注册并加入部门时,系统会更新
invite_logs表中的记录,将邀请状态更新为“已注册”或“已加入部门”。这可以帮助企业更好地分析每次邀请的效果,并优化邀请策略。4. 通俗理解
二维码邀请:可以把二维码想象成员工发给新员工的“数字邀请函”。新员工只需要用手机扫一扫,系统就会自动帮他们注册,并加入到对应的部门。系统会根据扫码时附带的信息(比如谁邀请了他们)自动处理这些信息。
分享海报:海报类似于一个公司宣传的广告牌,上面不仅有公司的标志、宣传语,还有二维码。新员工只要扫海报上的二维码,就可以直接进入注册流程,非常方便。
邀请记录:每次邀请都会被系统自动记录,这样企业就能清楚知道是谁邀请了新员工、什么时候扫码、注册是否成功,方便追踪和统计这些数据。
实现流程总结
生成二维码:
- 系统生成一个包含邀请链接的二维码,链接中包含邀请者的身份信息和部门信息。
- 通过 ZXing 或 QRCode 库生成二维码图片,并将其展示给员工进行分享。
邀请链接与海报分享:
- 新员工扫码后,系统解析二维码中的邀请链接,自动引导他们注册并加入相应的部门。
- 生成二维码海报,帮助员工通过视觉效果更好地进行邀请和分享。
记录邀请与结果:
- 系统记录每次邀请的情况,包括邀请人、被邀请人、扫码时间和注册结果,帮助公司进行数据追踪和分析。
通俗理解总结
二维码就是员工发给新人的“邀请函”,新人扫描后,系统会自动引导他们注册并加入部门。而每次扫码注册的情况,系统会自动记录,帮助企业了解每次邀请是否成功。这套机制不仅让邀请变得方便,还能清晰追踪每次邀请的效果。
4. 代码自动生成工具
问题背景:
在开发过程中,尤其是涉及数据库操作的场景,开发人员往往需要为每个数据表手动编写增删改查(CRUD)的代码。随着表数量的增加,手动编写这些重复代码不仅浪费时间,而且容易出错。因此,我们需要一种自动生成这些代码的工具,以提高开发效率并减少人工操作。
解决方案:
1. 使用代码生成器
MyBatis-Plus 是一种非常流行的 ORM 框架,它提供了一个强大的代码生成器,可以根据数据库表的结构自动生成 Java 类。通过这种方式,开发人员可以省去大量重复的工作,专注于业务逻辑的开发。
主要自动生成的内容包括:
- Controller:负责接收前端请求并调用后端服务。
- Service:实现业务逻辑。
- Mapper(DAO):负责数据库的增删改查操作。
- 实体类(Entity):对应数据库中的表结构,包含表的字段作为类的属性。
通过代码生成器,框架会自动将数据库表与上述这些层的代码关联起来,开发人员只需少量修改或直接使用。
2. 配置模板
为了让生成的代码结构符合项目的开发规范,我们可以通过模板引擎(如 Freemarker 或 Velocity)自定义生成的代码模板。
模板的作用:
- 在代码生成之前,开发人员可以先编写一个基础模板,定义好每一层(Controller、Service、Mapper 等)的结构和代码样式。
- 在生成时,工具会根据数据库表的字段信息,将这些信息填充到模板中,生成具体的代码。
例如,生成的
Controller模板可能包含标准的 RESTful 风格的接口,如getById、create、update和delete,这些方法通过表的字段自动生成。3. 自动生成代码的具体流程
生成流程的步骤:
配置数据库连接: 代码生成工具需要与数据库连接,以读取表结构信息。开发人员需要提供数据库的连接信息,如数据库 URL、用户名、密码等。
选择表或表集合: 开发人员选择需要生成代码的数据库表,生成器会根据表的结构自动分析出字段、主键等信息。
自定义生成配置: 通过模板引擎,可以自定义生成代码的目录结构、类命名方式等。如果不需要自定义配置,可以使用默认模板。
自动生成代码: 工具会根据表结构生成以下内容:
- 实体类(Entity): 将表中的字段映射为类的属性。
- Mapper(DAO): 自动生成增删改查操作方法。
- Service 和 ServiceImpl: 生成包含业务逻辑的服务层。
- Controller: 生成用于接收 HTTP 请求的控制器。
集成与调整: 自动生成的代码会放入项目的对应文件夹中。开发人员可以直接使用这些代码,或根据具体业务需求稍作修改。
示例:通过 MyBatis-Plus 的代码生成器,只需执行如下几步,便可以生成 CRUD 代码:
1
2
3
4
5AutoGenerator generator = new AutoGenerator();
generator.setDataSource(new DataSourceConfig.Builder(url, username, password).build());
generator.setPackageInfo(new PackageConfig.Builder().parent("com.example.project").build());
generator.setStrategy(new StrategyConfig.Builder().addInclude("employee").build());
generator.execute();4. 通俗理解
你可以把代码生成工具想象成一个“代码生成机器”。平时你要为每张数据库表写很多重复的代码,比如“查询某条记录”“更新某条记录”“删除某条记录”等等。这个工具就像是一个自动化的流水线,你只需要告诉它:这是一张叫“员工表”的数据库表,它里面有“姓名”“职位”“工号”等字段。接下来,机器就会为你自动生成所有的增删改查代码,你不需要手动去写。
5. 实现流程总结
- 选择数据库表:指定需要生成代码的表,比如
employee表。 - 配置代码模板:通过 Freemarker 等模板引擎定义代码样式和结构。
- 自动生成代码:MyBatis-Plus 的代码生成器根据表结构生成实体类、DAO 层、Service 层、Controller 等。
- 调整与使用:生成的代码大部分可以直接使用,开发人员只需根据业务需要进行少量修改。
6. 涉及的关键技术
- MyBatis-Plus:一款用于简化 MyBatis 操作的 ORM 框架,它提供了代码生成器的功能。
- Freemarker/Velocity:模板引擎,用于自定义生成的代码结构和格式。
- JDBC:通过 JDBC 读取数据库表结构,获取字段信息以生成代码。
通俗理解总结
代码自动生成工具就像是一个 自动化工厂,只要你给它提供原材料(数据库表),它就能按照事先设计好的模具(代码模板),生产出一套完整的代码。这大大减少了开发人员的重复劳动,让大家可以更多地专注于解决复杂的业务问题,而不是手动编写大量重复的代码。
5. Java 8 Stream API 优化集合处理
问题背景:
在 Java 开发中,处理集合数据(如
List、Set等)是常见的任务。对于复杂的数据处理场景,例如为企业列表关联员工信息,传统的做法通常是使用for循环。这种方式代码繁琐且不易维护,尤其是嵌套循环的情况下,效率和可读性都会降低。解决方案:使用 Java 8 Stream API
1. 引入 Stream API
Java 8 的 Stream API 提供了对集合数据进行高效、声明式处理的方法。Stream API 可以看作是一条“数据流”,你可以在这个流上进行各种操作,如过滤、转换、收集等。其优势在于可以通过链式操作简化代码,并提供并行处理的能力。
主要功能包括:
- 过滤数据(filter): 按照条件筛选符合要求的元素。
- 映射数据(map): 将集合中的每个元素转换为其他形式。
- 排序(sorted): 对集合中的元素进行排序。
- 收集结果(collect): 将处理后的数据转换为集合或其他结果形式。
2. 使用 Lambda 表达式
Stream API 与 Java 8 的 Lambda 表达式结合,可以使代码更加简洁和表达力强。通过 Lambda 表达式,你可以在方法中直接定义需要执行的逻辑,避免了使用匿名类或冗长的代码。
示例:
假设我们有一个企业列表和员工列表的需求,任务是将企业列表中的每个企业与对应的员工信息关联起来。传统的做法:
1
2
3
4
5
6
7
8
9for (Company company : companyList) {
List<Employee> employees = new ArrayList<>();
for (Employee employee : employeeList) {
if (employee.getCompanyId().equals(company.getId())) {
employees.add(employee);
}
}
company.setEmployees(employees);
}这种方式虽然能实现目标,但代码显得繁琐,尤其是当处理逻辑更加复杂时,可读性会变得很差。
3. Stream API 的实现方式
Stream API 可以通过简单的链式调用来优化以上逻辑,简化代码,使得业务处理逻辑更加直观。
使用 Stream API 的方式:
1
2
3
4
5
6companyList.forEach(company -> {
List<Employee> employees = employeeList.stream()
.filter(employee -> employee.getCompanyId().equals(company.getId()))
.collect(Collectors.toList());
company.setEmployees(employees);
});优化的关键点:
- **stream()**:将
employeeList转化为一个流。 - **filter()**:使用 Lambda 表达式对员工列表进行过滤,只保留符合公司 ID 的员工。
- **collect()**:将过滤后的员工流重新收集为列表,并赋值给企业对象。
相比传统的
for循环,这样的代码更简洁、结构更清晰,易于维护和扩展。4. 并行流处理(ParallelStream)
在处理大量数据时,使用 parallelStream() 可以将流并行化处理,从而提升性能。并行流利用了多线程的优势,在多核 CPU 环境下处理速度会显著提升。
示例:并行处理企业关联员工信息:
1
2
3
4
5
6companyList.parallelStream().forEach(company -> {
List<Employee> employees = employeeList.stream()
.filter(employee -> employee.getCompanyId().equals(company.getId()))
.collect(Collectors.toList());
company.setEmployees(employees);
});通过并行流处理,企业列表的每个公司可以同时进行员工关联,极大提高了处理效率。
5. 使用 Stream API 进行复杂操作
Stream API 不仅能简化数据的基本处理,还可以处理更加复杂的操作,比如数据分组、汇总等。
示例:根据公司 ID 对员工进行分组:
1
2Map<Long, List<Employee>> employeesByCompany = employeeList.stream()
.collect(Collectors.groupingBy(Employee::getCompanyId));这段代码使用
groupingBy操作,将员工列表按公司 ID 进行分组,并返回一个Map<Long, List<Employee>>,键是公司 ID,值是该公司对应的员工列表。6. 通俗理解:Stream API 的作用
你可以把 Stream API 想象成一个“数据处理流水线”。你将数据(比如员工列表)输入到流水线,然后可以在这条流水线上做各种操作,比如筛选出你想要的员工(filter),将某些字段转换为其他形式(map),最后把结果收集起来(collect)。这些操作可以一个接一个地组合起来,就像工厂流水线上的产品加工一样。
7. 涉及的关键技术
- Stream API:用于对集合进行声明式、链式的操作。
- Lambda 表达式:简化函数定义,使代码更加简洁和易读。
- Collectors:用于将处理后的流数据重新收集为列表、Map 等集合。
- **parallelStream()**:并行处理集合,提高处理效率。
总结:Java 8 Stream API 优化的思路
- 简化代码结构:通过 Stream API 的链式调用和 Lambda 表达式,集合处理变得更加简洁,避免了繁琐的循环代码。
- 提升性能:对于大规模数据处理,使用
parallelStream()进行并行化处理,充分利用多核 CPU 提升性能。 - 增强可读性:相比传统的
for循环,Stream API 提供了更清晰的操作逻辑和结构,代码更加易于理解和维护。
Stream API 就像一个高度自动化的“数据加工流水线”,你可以通过简单的操作指令让它自动完成数据的筛选、转换和汇总,而且如果数据量大,它还可以多线程并行工作,效率更高。
6. SQL 优化与库表管理
问题背景:
当系统处理大规模的数据时,比如企业名片和通讯录数据,如果查询效率低,会导致页面加载缓慢,甚至造成用户体验不佳。因此,提升数据库查询性能是优化项目的关键任务。
解决方案:
1. 索引优化
什么是索引?
数据库中的索引就像一本书的目录。它是根据常用查询字段(如员工 ID、部门 ID)提前生成的索引表,使得数据库能在查询时快速定位数据,而不必逐行扫描整个表。如何优化索引?
- 为常用字段添加索引:例如,如果你的查询经常是按员工 ID 或部门 ID 来检索数据,那么为这些字段建立索引将大大提高查询速度。添加索引后,数据库不需要逐行检查所有记录,而是通过索引快速定位符合条件的数据。
注意:
- 不要为每个字段都建立索引,因为索引本身也会占用空间,更新数据时会增加系统开销。合理选择常用的、查询频繁的字段进行索引优化。
索引优化举例:
假设我们有一个通讯录查询接口,通常需要根据employeeId查询某个员工的信息。在数据库表中为employeeId字段添加索引:1
CREATE INDEX idx_employee_id ON employee_table(employeeId);这样,每次通过
employeeId查询员工信息时,数据库会快速通过索引定位,而不是进行全表扫描。2. 查询优化
1. 避免使用
SELECT *:
在 SQL 查询中,使用SELECT *会返回表中的所有列,尤其是当表的字段很多时,可能会导致大量无用数据的传输。更好的方式是只查询需要的字段。示例:
假设我们只需要员工的姓名和联系电话,而不是整条记录的数据:1
SELECT name, phone_number FROM employee_table WHERE departmentId = 123;这样可以减少数据传输量,提升查询效率。
2. 分页查询:
在处理大规模数据时,一次性查询并返回所有数据会导致性能下降。因此,使用分页查询可以避免内存占用过大和网络传输过慢的问题。分页查询示例:
1
SELECT name, phone_number FROM employee_table WHERE departmentId = 123 LIMIT 10 OFFSET 0;LIMIT控制每次返回的条目数,OFFSET表示从第几条记录开始。这种方式可以让你一次只返回少量数据,提升查询性能和用户体验。3. 表结构设计优化
1. 遵循数据库规范化原则:
数据库的规范化设计可以减少数据冗余,避免重复存储相同的信息,同时还能保持数据的一致性。常见的数据库规范化规则:
- 第一范式(1NF):每个字段都必须是不可分割的原子值。比如不要在一个字段中存储多个电话号码,而是使用多个独立字段来存储。
- 第二范式(2NF):非主键字段必须完全依赖于主键,而不是部分依赖。避免将与主键无关的信息存储在一起。
- 第三范式(3NF):消除字段间的传递依赖。例如,如果部门经理的名字是根据部门 ID 决定的,不应该存储在员工表中,而应该独立存储在部门表中。
通过这种规范化设计,表结构更清晰,数据的管理和维护也变得更加容易。
2. 外键与关联表设计:
在数据库表之间设计外键,可以确保数据的一致性和完整性。比如,企业表和员工表之间可以通过companyId建立外键关联,确保每个员工都对应一个合法的企业。外键设计示例:
1
2
3
4
5
6CREATE TABLE employee_table (
employeeId INT PRIMARY KEY,
name VARCHAR(100),
companyId INT,
FOREIGN KEY (companyId) REFERENCES company_table(companyId)
);这样,当我们在
employee_table表中插入员工时,数据库会自动检查companyId是否在company_table中存在,确保数据一致性。4. SQL 查询优化策略
1. 使用
JOIN代替子查询:
在处理复杂查询时,尽量避免使用子查询,因为子查询可能会导致性能下降。通过JOIN连接表可以更高效地查询关联数据。示例:
假设我们需要查询员工所在的公司名称:1
2
3SELECT e.name, c.company_name
FROM employee_table e
JOIN company_table c ON e.companyId = c.companyId;这种
JOIN操作比子查询更高效,尤其是在大规模数据处理时,性能优势更加明显。2. 使用缓存(如 Redis):
对于一些频繁查询但不经常更新的数据,我们可以使用缓存(如 Redis)来减轻数据库压力。缓存机制能够将查询结果暂时存储在内存中,下次查询时直接从缓存中获取,避免重复查询数据库。5. 通俗理解:索引和查询优化的作用
你可以把数据库查询比作在一个大型图书馆中找书。假设图书馆里有成千上万本书,如果没有目录或分类(索引),你就得一排一排地翻阅,效率非常低。而通过提前为书籍做好分类索引,查找速度就能大大提升。
同样的道理,在数据库中,如果没有索引,查询数据时就需要逐行扫描整个表。而索引则像一个分类目录,帮助你快速找到想要的数据。分页查询则像是一次只拿一部分数据,避免一次性处理过多数据导致拥堵。
6. 涉及的关键技术:
- 索引:提升查询效率,避免全表扫描。
- 分页查询:控制返回的数据量,避免一次性返回过多数据。
- 规范化设计:确保数据库结构清晰,减少冗余,保证数据一致性。
- JOIN 查询:更高效地处理多表关联,减少子查询的使用。
- 缓存:通过 Redis 等工具,减少频繁查询数据库的压力,提升整体系统性能。
总结:SQL 优化与库表管理的思路
- 索引优化:为常用的查询字段建立索引,加快查询速度。
- 查询优化:使用精简的 SQL 语句,避免
SELECT *,并采用分页查询的方式处理大规模数据。 - 表结构设计:遵循规范化设计原则,确保数据库表结构合理,避免数据冗余和不一致性。
- 合理使用外键和关联表:确保数据之间的关系清晰,保持数据完整性。
- 缓存机制:对于频繁查询的静态数据,使用缓存来减轻数据库的压力。
通过这些优化手段,你的系统查询就像在有目录的大图书馆里找书,迅速准确而且不费力!
7. Git 版本管理与禅道 Bug 跟踪
问题背景:
在多人协作的开发环境中,如何有效管理项目的代码版本和 Bug 修复进度是项目顺利推进的关键。项目开发过程中会有多人同时对代码进行修改,如果没有规范的代码管理和 Bug 跟踪机制,可能会导致代码冲突、功能错乱,甚至遗漏问题。解决这些问题的核心工具是 Git 版本管理 和 禅道 Bug 跟踪系统。
解决方案:
1. Git 版本管理
Git 是分布式的版本控制系统,可以帮助团队有效管理项目中的代码版本,并支持多人协作开发。使用 Git,团队可以追踪每个代码修改的来源、内容和原因,随时回溯到某个历史版本,同时可以防止不同开发人员的代码冲突。
1.1 分支管理
什么是分支?
分支就是代码的不同开发线,比如主线开发一条,功能开发另一条。在 Git 中,使用分支可以把不同的功能开发隔离开,避免不同开发人员之间的代码互相影响。
- 主分支(
master或main):保存的是已经上线或稳定的代码,通常不会直接在这个分支上开发,而是通过合并(merge)功能分支(feature branch)来维护。 - 开发分支(
develop):是开发的主分支,平时的代码开发都会在这个分支上进行。所有的功能开发完成后,代码会从develop分支合并到master分支。 - 功能分支(
feature/XXX):为每个独立的功能或任务创建单独的分支,这样每个开发人员可以在自己的功能分支上工作,不会影响其他人的工作。 - 修复分支(
bugfix/XXX):当需要修复 Bug 时,可以从develop分支创建一个专门的 Bug 修复分支,修复完成后再合并回develop。
通俗理解:分支就像在工地上,开发人员各自负责不同的房间,最后把所有房间都装好后,才整体交给客户。这样每个人都可以独立工作,不用担心互相干扰。
1.2 冲突解决
为什么会有冲突?
当两个或多个开发人员同时修改了同一个文件的同一个部分时,Git 无法自动决定哪一个修改是正确的,这时就会发生代码冲突。
如何解决冲突?
- Git 提示:当你尝试合并代码时,如果发生冲突,Git 会提示冲突文件的具体位置,开发人员需要手动检查每个冲突点,并决定保留哪一部分的修改,或者手动进行调整。
- 手动解决:开发人员打开冲突文件后,Git 会标记出冲突的地方,你需要阅读冲突内容,选择正确的代码进行保留,然后提交(commit)解决后的代码。
通俗理解:想象两个人同时在同一份文档上做了修改,当他们都把修改交回时,系统不知道该保留谁的修改,所以需要手动检查并合并修改。
1.3 版本回溯与历史记录
版本回溯:
Git 能记录每一次代码提交,开发人员可以在任何时候回退到之前的某个版本。这意味着如果在新功能开发过程中遇到问题,可以快速还原到之前的稳定版本。
历史记录:
每一次代码提交都会有一条日志,记录修改内容、提交人和提交时间,帮助团队了解每次修改的背景。通过 git log 可以查看历史提交记录。
2. 禅道 Bug 跟踪
禅道是一款项目管理和 Bug 跟踪系统,能够帮助团队有效管理 Bug 和任务的进度,确保问题被及时修复并验收。
2.1 Bug 提交与分配
提交 Bug:
当测试人员或用户发现问题时,会在禅道中提交 Bug,并详细描述问题的情况,比如错误信息、重现步骤等。
Bug 分配:
项目经理会将 Bug 分配给相关开发人员进行修复,禅道会自动通知被分配任务的开发人员,明确每个人的任务。
通俗理解:就像问题清单,每当发现一个新问题,测试人员就会将其记录下来,并指派给合适的开发人员去修复。
2.2 Bug 修复与状态跟踪
Bug 修复:
开发人员在接收到任务后,进入自己的功能分支或 Bug 修复分支,按照禅道中记录的 Bug 描述进行修复,完成后提交到 Git 中。
Bug 状态跟踪:
每个 Bug 都有不同的状态(待解决、已解决、待验收、关闭等)。当开发人员修复完成后,会将 Bug 状态更新为“已解决”,并附上修复说明。之后,测试人员会进行回归测试,确认问题是否解决。如果 Bug 修复成功,状态会变为“关闭”,如果没有修复彻底,状态会返回“待解决”。
通俗理解:禅道就像一个问题追踪器,记录每个 Bug 的状态,从发现、修复到最后的验收,确保问题不会被忽略或遗忘。
2.3 任务协作与进度管理
任务协作:
在禅道中,每个开发任务和 Bug 都可以指派给不同的团队成员,帮助团队合理分配工作,防止任务重叠或遗漏。
进度管理:
通过禅道的看板和报表功能,项目经理可以实时查看任务的进展情况,包括哪些 Bug 还未解决、哪些已经解决,帮助团队跟踪项目整体进度。
通俗理解:Git 与禅道的协作
- Git 是代码的“时间机器”:它记录每一次修改,允许开发人员随时回到之前的任何一个版本,查看是谁、在什么时候做了什么修改。而且,通过分支管理,开发人员可以在各自的分支上独立工作,避免冲突,最终将代码合并到主线中。
- 禅道是问题的“跟踪清单”:每个 Bug 的发现、指派、修复、测试和验收都在禅道中详细记录,确保每个问题都有一个清晰的解决路径,并且不会被遗漏。
涉及的关键技术:
Git 版本控制系统:
- 分支管理:通过不同的分支隔离开发任务,提升协作效率。
- 冲突解决:手动合并代码冲突,确保代码正确无误。
- 版本回溯:支持随时回退到历史版本,确保代码的稳定性。
禅道 Bug 跟踪系统:
- Bug 提交与指派:跟踪 Bug 发现和修复的全过程,分配给相应的开发人员。
- 状态管理:通过 Bug 状态追踪任务进展,确保问题及时解决。
- 进度监控:项目经理可以实时查看项目的任务完成情况,确保按时交付。
总结:Git 与禅道的协同工作方式
通过 Git 的版本管理,开发人员可以有效地在不同分支上并行开发,避免代码冲突,并在遇到问题时回退到历史版本。而禅道系统帮助团队更好地跟踪 Bug 和任务进度,确保每个 Bug 都能被及时发现、修复和验收。两者结合,使得项目开发流程更加清晰高效。
2024 年 9 月 23 日
API 项目回答思路
1. 定制 SpringBoot 初始化模板
解决方案与实现思路:
- 全局请求响应拦截:你可以通过
HandlerInterceptor或Filter来处理所有进入系统的请求和响应。在实现上,HandlerInterceptor会在请求的每个阶段(如处理前、处理后、完成时)执行自定义逻辑。常用于日志记录、权限检查、统计请求数据等。比如,记录每个请求的耗时:- 实现
HandlerInterceptor,重写preHandle()方法获取请求开始时间,afterCompletion()记录结束时间并打印日志。
- 实现
- 全局异常处理:全局异常处理则通过
@ControllerAdvice和@ExceptionHandler进行。这样,所有的异常都可以集中在一个地方处理,避免在代码中到处写try-catch。比如:当接口出错时,统一返回一段格式化的 JSON 错误信息。 - Swagger + Knife4j:通过集成
Swagger和Knife4j,你能为所有的 API 自动生成在线文档。开发者无需手动编写文档,Swagger 根据代码中的注解自动生成接口说明。Knife4j是 Swagger 的扩展,提供了更好用的界面和功能,比如接口调试。 - 跨域支持:通过
@CrossOrigin或实现CorsFilter,你可以允许前端(比如用 React.js 开发的部分)跨域请求后端服务。这能确保浏览器不会因为前后端分离而阻止请求。 - 多环境配置:通过
application.yml文件,你可以为不同环境(如开发、测试、生产)设置不同的配置。用@Profile注解来区分不同环境的 Bean 加载,比如开发环境用调试工具,而生产环境禁用调试工具。
关键技术:HandlerInterceptor、@ControllerAdvice、Swagger + Knife4j、CORS(跨域资源共享)、application.yml。
2. 自主设计多样化接口服务
解决方案与实现思路:
- 随机壁纸接口:首先,你可以在数据库(MySQL)中存储多张壁纸的链接,接口调用时随机返回一个。最简单的实现是使用 SQL 查询语句
SELECT * FROM wallpapers ORDER BY RAND() LIMIT 1;,它会从壁纸表中随机挑选一条记录返回给用户。你也可以通过外部的 API 获取随机壁纸并转发给前端。 - 随机生成诗词接口:类似于随机壁纸,随机诗词也可以预先存储在数据库中,调用时使用随机查询语句返回。如果你希望更复杂的效果,比如生成定制化的诗词,你可以使用第三方的 AI 接口,生成符合特定格式或风格的诗句。
- 接口文档生成:通过 Swagger 和
@Api注解为这些接口生成 API 文档,用户可以在前端直接查看接口的请求参数和返回结果,方便调用。这样,开发者不需要查阅代码即可理解接口的功能。
关键技术:MySQL 随机查询、Spring Boot RESTful API、Swagger 自动生成文档。
3. 使用 Spring Cloud Gateway 实现微服务网关
解决方案与实现思路:
- 网关架构:Spring Cloud Gateway 是微服务架构的网关层,它负责处理所有外部流量,并将请求转发到不同的服务。你可以通过
Route配置来设置不同的路径对应不同的服务。 - 请求过滤和转发:你可以使用 Spring Cloud Gateway 内置的过滤器进行请求的预处理,比如校验请求头、检查身份验证等。通过路由规则将不同的 API 请求转发到后端的具体服务。
- 统一认证授权:为了保证每个请求的合法性,你可以在网关层引入 JWT(JSON Web Token)或者 API 签名认证机制。在网关处解析并验证这些信息,只有经过验证的请求才能通过,未授权请求会被直接拦截。
- 限流和熔断:通过 Resilience4j 或 Spring Cloud Gateway 自带的限流功能,你可以限制某个 IP 或用户在特定时间内的请求数量,防止接口被恶意调用。熔断则可以在某个服务不稳定时,自动中断请求,保护整体系统不受影响。
关键技术:Spring Cloud Gateway、JWT、Resilience4j(限流与熔断)、自定义过滤器。
4. 自主实现 API 签名认证
解决方案与实现思路:
- 密钥对生成:为每个用户分配一个唯一的
accessKey和secretKey。这两个值会在用户注册时生成并保存在数据库中,secretKey经过加密存储以确保安全。 - 请求签名生成:当客户端发起 API 请求时,客户端需要将请求参数(如时间戳、
accessKey等)按照字典序进行排序,并使用secretKey通过 SHA256 算法生成一个签名。这个签名将附带在请求中。 - 服务端验证签名:服务端接收请求后,利用相同的参数和
secretKey重新计算签名,验证它是否与客户端传来的签名一致。这样可以保证请求的合法性和完整性,防止被篡改。 - 防止重放攻击:在每个请求中加入时间戳,服务端可以验证请求的时间与当前服务器时间是否相差过大,确保不会有重复或过期的请求被恶意重发。
关键技术:SHA256 加密算法、Spring MVC 拦截器、时间戳校验。
5. 使用 Maven 聚合工程和 Nacos 实现微服务架构
解决方案与实现思路:
- Maven 聚合工程:通过创建一个 Maven 父工程(
pom.xml),你可以定义公共的依赖和插件配置。将项目拆分成多个子模块(例如用户服务、订单服务等),每个模块是一个独立的 Spring Boot 应用。这种方式能让你按照业务功能将代码拆分,并实现模块化开发。 - Nacos 注册中心:每个微服务启动时,会将自身的实例信息(如 IP、端口、服务名称等)注册到 Nacos 中。Nacos 作为注册中心,负责管理和分发服务实例,其他服务可以通过 Nacos 进行服务发现,找到目标服务并进行调用。
- 多环境配置:通过 Nacos 的配置中心功能,集中管理各微服务的配置信息。每个服务启动时,会从 Nacos 中获取对应环境的配置,确保配置的一致性和灵活性。
关键技术:Maven 聚合工程、Nacos 注册与配置中心、微服务架构拆分。
6. 使用 Dubbo RPC 框架优化公共服务
解决方案与实现思路:
- 服务抽取:你可以将一些通用的业务逻辑(如鉴权、日志、流量统计等)抽取出来作为独立的服务,通过 Dubbo 提供这些服务。这样,其他微服务就可以通过远程调用 Dubbo 提供的公共服务,避免重复开发。
- Dubbo 的服务调用:通过 Dubbo 的服务注册与消费机制,服务端将公共服务注册到 Nacos,客户端(其他微服务)可以通过 Dubbo 的 API 实现跨服务调用。这种方式比 HTTP 调用更高效,特别是对于高频次的内部服务调用。
- 解耦和负载均衡:通过 Dubbo,你可以让服务之间完全解耦,同时,Dubbo 提供多种负载均衡策略(如轮询、随机、加权等),确保多个实例间的请求均衡分布,提升系统的稳定性和扩展性。
关键技术:Dubbo RPC 框架、Nacos 注册中心、公共服务抽象、负载均衡策略。
7. 应用 Spring Boot 自动配置机制,自主设计客户端 SDK
解决方案与实现思路:
- 自动配置机制:通过 Spring Boot 的自动配置功能(
@EnableAutoConfiguration和@ConfigurationProperties),你可以开发一套 SDK。这个 SDK 可以自动加载必要的配置,比如 API 地址、密钥等,使开发者接入你的平台变得非常简单。 - 封装 API 调用逻辑:在 SDK 中封装好所有 API 调用的逻辑,比如 HTTP 请求、签名生成、错误处理等。开发者只需调用 SDK 中的几个方法,无需关心底层细节。
- 统一错误处理:SDK 内部可以对所有可能的错误进行统一捕获和处理,开发者只需关注业务逻辑
1. 定制 SpringBoot 初始化模板
1.1 全局请求响应拦截
实现思路:
全局请求和响应拦截主要是为了在所有的请求到达业务逻辑之前,或者响应返回客户端之前进行一些通用的处理操作,比如日志记录、权限验证等。
实现方法:
HandlerInterceptor实现:使用HandlerInterceptor是 Spring 中比较常见的做法。你可以实现一个自定义的拦截器,通过preHandle()方法在请求进入控制器之前执行逻辑,postHandle()在返回结果之前处理响应,afterCompletion()处理最终的清理工作(如记录日志等)。- **
preHandle()**:可以在这里进行身份验证、权限校验、记录请求信息(如 URL、参数等)。 - **
postHandle()**:在控制器处理完后返回响应之前,做一些响应数据的加工,或记录执行时间。 - **
afterCompletion()**:请求处理完成后,做最终的资源清理或日志记录。
- **
1 | |
- 注册拦截器:拦截器定义好后需要在
WebMvcConfigurer中注册,确保它生效。
1 | |
关键技术:Spring HandlerInterceptor、Spring WebMvcConfigurer。
1.2 全局异常处理
实现思路:
全局异常处理的目的是将应用中的所有异常集中管理,保证在接口发生错误时,返回一个统一的、易于理解的错误响应,而不是让错误信息直接暴露给用户。
实现方法:
@ControllerAdvice和@ExceptionHandler实现:
使用@ControllerAdvice结合@ExceptionHandler注解,可以捕获全局的异常,并返回统一的错误信息。比如,当系统遇到空指针异常或自定义的业务异常时,返回一个格式化的 JSON 响应,包含错误码和错误信息。
1 | |
这样,无论应用程序在哪个地方发生异常,都会统一返回一个结构化的错误响应,而不会抛出未经处理的原始异常。
关键技术:@ControllerAdvice、@ExceptionHandler。
1.3 Swagger + Knife4j 接口文档生成
实现思路:
在开发中,接口文档对于前后端合作至关重要。通过 Swagger 自动生成接口文档,开发者无需手动编写,节省了大量的时间和精力。而 Knife4j 是 Swagger 的增强版,提供了更友好的 UI 和接口调试工具。
实现方法:
- 引入 Swagger 和 Knife4j 依赖:
在pom.xml中添加 Swagger 相关依赖。
1 | |
- 配置 Swagger:
创建 Swagger 配置类来初始化 API 文档。
1 | |
- 接口注解:
使用@ApiOperation、@ApiParam等注解描述接口和参数,这样 Swagger 就能自动生成这些接口的说明。
1 | |
这样,所有的接口就会自动出现在 Swagger UI 页面中,供开发者测试和查看文档。
关键技术:Swagger、Knife4j、@ApiOperation 注解。
1.4 跨域支持
实现思路:
在前后端分离的项目中,通常会遇到浏览器的跨域问题。跨域是指浏览器限制从一个域名访问另一个域名的资源。为了允许前端通过不同域名访问后端 API,我们需要启用跨域请求支持。
实现方法:
- 使用
@CrossOrigin注解:
可以在每个控制器或者全局配置中启用跨域。对于简单项目,可以直接在控制器方法上添加@CrossOrigin注解,允许特定的域名访问这个接口。
1 | |
- 全局跨域配置:
如果要对所有的请求支持跨域,可以通过全局CorsFilter进行配置,允许特定的跨域请求。
1 | |
这样,无论从哪个域名发起的请求,只要符合跨域策略的条件,后端都能正常响应。
关键技术:@CrossOrigin 注解、CorsFilter。
1.5 多环境配置
实现思路:
在项目的开发过程中,通常会涉及多个环境,比如开发环境、测试环境、生产环境。每个环境有不同的数据库连接、日志级别、第三方服务配置等。通过 Spring Boot 的多环境配置功能,可以根据当前运行的环境自动加载对应的配置文件。
实现方法:
- 配置文件管理:
Spring Boot 使用application-{profile}.yml来支持多环境配置。你可以为每个环境创建一个配置文件,比如application-dev.yml(开发环境)、application-prod.yml(生产环境)等。
1 | |
1 | |
- 环境激活:
通过命令行参数或在application.yml中指定spring.profiles.active来选择当前的运行环境。
1 | |
- 代码中的环境区分:
你还可以使用 `@Profile
` 注解区分某些 Bean 只在特定环境下加载,比如开发环境使用的调试工具在生产环境禁用。
1 | |
关键技术:Spring application.yml 多环境配置、@Profile 注解。
总结
通过这个定制的 Spring Boot 初始化模板,你可以快速启动项目并具备一系列基础功能,包括全局请求响应拦截、异常处理、跨域支持、自动生成接口文档以及多环境配置。这些功能不仅提升了项目的可维护性和可扩展性,还能在开发阶段节省大量的重复工作。
好的!现在我将针对第二个亮点 “使用 Spring Cloud Gateway 实现微服务网关” 的解决方案和思路进行详细的表述,并且会让你对它的实现方式有一个全面、通俗易懂的理解。
2. 使用 Spring Cloud Gateway 实现微服务网关
在微服务架构中,网关起到了至关重要的作用。它是所有外部请求进入微服务系统的唯一入口,可以进行请求过滤、负载均衡、鉴权、限流等操作,保证系统的稳定性和安全性。Spring Cloud Gateway 是一个高度定制化、轻量级且功能强大的微服务网关解决方案。
2.1 实现思路
在你的项目中,Spring Cloud Gateway 主要用来处理以下几项任务:
- 请求过滤和转发:将外部请求路由到不同的微服务。
- 统一认证授权:确保每个请求都经过认证和授权。
- 请求限制(限流):防止大量无效请求对系统造成冲击,保护后端服务。
2.2 实现方法
1. 引入 Spring Cloud Gateway
首先,在项目的 pom.xml 中引入 Spring Cloud Gateway 相关依赖:
1 | |
这会让 Spring Cloud Gateway 提供的核心功能在你的应用中生效。
2. 配置路由转发
路由是网关的核心功能,所有外部请求都会通过网关路由到不同的微服务。可以通过配置文件或 Java 代码的方式实现路由。
- 通过配置文件(YAML 格式):
在application.yml中配置路由规则,将特定的请求转发到目标服务。例如:
1 | |
在这里,lb://USER-SERVICE 表示基于负载均衡的服务调用,所有 /user/** 的请求会被转发到 USER-SERVICE 微服务。
- 通过 Java 代码配置路由:
如果你更喜欢编程的方式,可以通过RouteLocator来定义路由:
1 | |
无论是通过配置文件还是代码,这些路由都能够确保请求被正确转发到目标服务,并且支持动态调整。
3. 统一认证授权
为了确保每个请求都是合法的,通常会在网关层实现认证和授权逻辑。你可以通过 全局过滤器 来对每一个请求进行认证检查。
- 定义全局认证过滤器:
自定义过滤器可以检查请求头中的认证信息(如 JWT token)。如果认证失败,直接在网关层拒绝请求,而不用让它传递到后端微服务。
1 | |
通过这种方式,网关可以确保所有请求都经过授权检查,未经授权的请求会被拦截,保证系统的安全性。
4. 实现限流(请求限制)
为了防止系统被恶意请求压垮,网关层通常会实现限流机制,限制每个用户每秒允许发出的请求数。Spring Cloud Gateway 提供了内置的 限流过滤器。
- 配置限流过滤器:
在application.yml中,可以通过配置来实现限流功能:
1 | |
- Key Resolver 定义:
可以通过自定义KeyResolver来决定限流的粒度,常见的方式是根据 IP 或用户 ID 限流:
1 | |
这样,每个 IP 每秒只能发起 10 个请求,多出的请求会被网关层拒绝处理,防止对后端服务造成压力。
5. 集成负载均衡
Spring Cloud Gateway 与 Spring Cloud LoadBalancer 无缝集成,可以通过服务名 lb://service-name 自动实现负载均衡。请求会被均匀分配到后端多个实例,从而提升服务的可用性和扩展性。
负载均衡可以通过配置或代码方式启用。比如:
1 | |
lb://USER-SERVICE 这一行指示 Spring Cloud Gateway 使用内置的负载均衡器,将请求路由到 USER-SERVICE 的不同实例。
2.3 关键技术
在整个过程中,主要涉及到以下技术:
- Spring Cloud Gateway:实现微服务网关的核心组件,用于路由转发、过滤请求、认证授权等。
- Spring Cloud LoadBalancer:提供基于服务名的负载均衡能力,确保请求能够均匀分布到不同的微服务实例。
- Redis:用于限流的分布式存储,实现限流计数等功能。
- JWT(JSON Web Token):通常用来进行用户身份认证,放在请求头中由网关进行校验。
- Predicate 和 Filter:在 Gateway 中,Predicate 用来定义请求的路由条件,Filter 用来对请求做额外处理,比如修改请求头、进行认证、限流等。
总结
通过 Spring Cloud Gateway,你能够实现功能强大的微服务网关,承担外部请求的路由、认证、授权以及限流等功能。这不仅提升了系统的安全性和可扩展性,还使得服务之间的调用更加灵活和高效。在这个过程中,通过合理的路由配置、过滤器的使用以及限流策略的实施,你能有效保证微服务架构的健壮性和稳定性。
这个实现方式不仅让系统在高并发场景下更加稳定,还为未来的扩展提供了极大的灵活性。
好的!现在我来详细阐述针对第三个亮点 “自主实现 API 签名认证” 的解决方案、思路和关键技术,确保你对这个实现过程有清晰且全面的理解。
3. 自主实现 API 签名认证
API 签名认证的目的是确保每个 API 请求的合法性和数据完整性。通过为每个注册用户分配唯一的密钥对(accessKey 和 secretKey),客户端每次请求时都会基于 secretKey 生成签名,而服务端则根据相同的规则进行验证,从而确保请求没有被篡改且来源可信。
3.1 实现思路
用户注册时分配密钥对:每个用户在注册时,系统会为其分配一个 accessKey 和 secretKey。
accessKey作为用户的唯一标识,而secretKey是用户和服务器之间共享的加密密钥,不会暴露给外部。客户端请求时生成签名:每次客户端发起 API 请求时,都会基于请求的参数、时间戳和
secretKey生成一个数字签名,并将accessKey和签名一起发送到服务器。服务端验证签名:服务端根据接收到的请求参数和存储的
secretKey生成一个新的签名,和客户端的签名对比。如果两者一致,则验证通过,说明请求合法且未被篡改。
3.2 实现步骤
1. 生成密钥对
在用户注册时,系统会为每个用户生成一对密钥,分别是 accessKey 和 secretKey。这些密钥可以使用随机数生成器创建,并将 secretKey 安全地存储在数据库中。
1 | |
生成的 accessKey 用来标识用户,而 secretKey 仅存储在服务端,用于签名和验证,不应泄露给外部。
2. 客户端请求签名生成
每次客户端发起请求时,需要生成一个签名。签名的生成过程通常包含:
- 将请求的 参数、时间戳 和 secretKey 结合在一起。
- 通过哈希算法(如 SHA-256)计算哈希值,作为签名。
签名生成公式通常为:
1 | |
示例代码:
1 | |
客户端生成签名后,会将 accessKey、timestamp 和 signature 作为请求的一部分发送到服务器。
1 | |
3. 服务端验证签名
服务端接收到请求后,会根据 accessKey 查询对应的 secretKey,再利用相同的算法生成一个签名。然后将生成的签名和请求中的签名进行比对,判断请求的合法性。
- 获取 accessKey 和 signature:
1 | |
- 查询用户对应的 secretKey:
服务端通过accessKey从数据库中查询该用户的secretKey。
1 | |
- 生成服务端签名并比对:
1 | |
如果签名一致,说明请求是合法的,未被篡改,服务端就可以继续处理请求。
3.3 签名验证中的常见问题和解决方案
1. 防止重放攻击
即使签名保证了请求的完整性,但仍可能有人拦截并重放请求。因此,加入时间戳机制是非常必要的。每个请求都应该附带一个 timestamp,服务端验证时检查请求是否在规定时间内(比如 5 分钟),如果时间超出,则拒绝处理。
1 | |
2. 参数顺序问题
在生成签名时,客户端和服务端必须确保对请求参数按 字典序 排序。这是为了避免因为参数顺序不同导致签名不一致。
3. 加强 secretKey 安全性
secretKey应该存储在加密的数据库字段中。- 建议使用安全的 HMAC (Hashed Message Authentication Code) 算法代替简单的 SHA-256。
- 定期更新用户的密钥对,并提供密钥轮换机制。
3.4 关键技术
- SHA-256 加密算法:用于生成请求签名,确保签名的不可逆性。
- HMAC(哈希消息认证码):可以加强签名验证,防止密钥泄露风险。
- 时间戳机制:防止请求重放攻击,确保请求时效性。
- UUID:用于生成唯一的
accessKey和secretKey,保证每个用户的密钥对不同。 - Base64 编码:有时候用于处理密钥或签名的编码,确保传输的安全性和一致性。
总结
通过自主实现的 API 签名认证机制,你可以确保 API 请求的合法性、来源的可信度以及数据的完整性。系统为每个用户分配一对唯一的 accessKey 和 secretKey,在客户端请求时利用 secretKey 生成签名,服务端进行校验。
这个机制可以有效防止数据篡改、伪造请求等攻击,同时通过时间戳机制防止重放攻击,增强了接口的安全性。整个流程简单、高效且安全,可以为平台用户提供良好的 API 体验,同时保证系统的安全性。
好的!现在我来详细阐述针对第四个亮点 “使用 Dubbo 和 OpenFeign 实现微服务间调用,在网关模块中实现服务间调用” 的解决方案、思路以及关键技术。这部分是微服务架构中非常关键的一环,关系到服务的拆分和调用如何高效、稳定地实现。
4. Dubbo 与 OpenFeign 实现微服务调用,并在网关模块中实现服务间调用
在微服务架构中,服务被拆分成独立的模块,它们之间需要通过网络进行通信。为了保证通信的高效性和灵活性,我们可以选择不同的远程调用框架来实现服务之间的调用。在这个项目中,使用了 Dubbo 和 OpenFeign 来处理不同场景下的服务调用需求,并通过 Spring Cloud Gateway 来统一管理和转发外部请求。
4.1 实现思路
Dubbo 用于高性能、内网的服务间调用:
- Dubbo 是一个高性能的 RPC 框架,适合在内网中使用,具有轻量级、低延迟、异步调用等特性,特别适合高并发场景。
- 在微服务拆分后,一些频繁调用的基础服务,如用户鉴权、数据校验等,使用 Dubbo 可以保证服务间调用的效率。
OpenFeign 用于简化 HTTP 调用:
- OpenFeign 是 Spring Cloud 提供的声明式 HTTP 客户端,适合对外部 RESTful 服务的调用。
- 使用 OpenFeign,开发者无需手动编写 HTTP 请求,只需通过接口声明和注解即可调用远程服务,简化开发工作,增强可读性。
Spring Cloud Gateway 实现外部请求的统一网关:
- Spring Cloud Gateway 是整个架构的流量入口,负责处理外部客户端请求。它可以根据路由规则转发请求到对应的微服务,同时进行认证、限流、熔断等处理,保证请求的安全性和服务的稳定性。
4.2 实现步骤
1. 使用 Dubbo 实现高效 RPC 调用
Dubbo 是一个基于 RPC(Remote Procedure Call)的分布式服务框架,通过它可以让服务之间直接调用彼此的接口,就像本地调用一样。其核心特性是高性能、可扩展和支持多种协议。
关键步骤:
- 服务提供者(Provider):提供具体的服务逻辑。
- 服务消费者(Consumer):通过 Dubbo 远程调用服务提供者的接口。
1.1 引入 Dubbo 依赖和配置
在 pom.xml 中引入 Dubbo 的相关依赖。
1 | |
配置 Dubbo 的注册中心(通常是使用 Nacos 来注册服务)。
1 | |
1.2 实现 Dubbo 服务提供者
在服务提供者端,编写服务接口和实现类,并通过注解 @Service 来暴露服务。
1 | |
1.3 实现 Dubbo 服务消费者
在服务消费者端,通过 @DubboReference 注解远程调用服务提供者的方法。
1 | |
通过这种方式,Dubbo 可以让两个服务之间的调用变得像本地方法调用一样简单,并且支持负载均衡、集群等高级特性。
2. 使用 OpenFeign 实现声明式 HTTP 调用
OpenFeign 是 Spring Cloud 中一个非常常用的 HTTP 客户端,适合处理外部服务的调用。它通过注解实现远程 HTTP 服务调用,省去了编写繁琐的请求代码,让开发者只需专注于接口设计。
关键步骤:
2.1 引入 Feign 依赖
在 pom.xml 中引入 Feign 的依赖。
1 | |
2.2 开启 Feign 功能
在主类中通过 @EnableFeignClients 注解开启 Feign 客户端功能。
1 | |
2.3 声明 Feign 客户端
通过接口的方式声明远程服务,使用 @FeignClient 注解指定要调用的服务名称和路径。
1 | |
2.4 调用 Feign 客户端
在业务层调用 Feign 客户端方法,发起 HTTP 请求。
1 | |
通过 Feign,可以非常方便地调用 RESTful API,并且 Feign 还支持负载均衡、熔断等功能。
3. Spring Cloud Gateway 实现统一网关
Spring Cloud Gateway 是一个 API 网关,用来处理外部请求,并将请求转发到内部的微服务。它不仅能做路由,还可以做权限校验、限流、负载均衡等操作,是微服务架构中非常重要的一环。
关键步骤:
3.1 引入 Spring Cloud Gateway 依赖
在 pom.xml 中加入 Spring Cloud Gateway 依赖。
1 | |
3.2 配置网关路由
通过 application.yml 配置路由规则,将不同的请求路由到不同的微服务。
1 | |
3.3 处理安全和认证
在网关层面可以添加过滤器,来统一处理请求的认证和权限验证。比如可以使用 JWT 过滤器来检查用户的身份认证。
1 | |
通过 Spring Cloud Gateway,所有外部请求都先经过网关,这样不仅提高了系统的安全性,还可以集中处理认证、限流和熔断等策略。
4.3 关键技术
- Dubbo:高性能的 RPC 框架,适合在内网环境中进行高并发的服务间调用。
- OpenFeign:用于简化 HTTP 调用的声明式客户端,适合 RESTful API 调用。
- Spring Cloud Gateway:微服务架构中的流量入口,统一处理外部请求的路由、认证、限流等功能。
- Nacos:作为注册中心,负责管理服务的动态注册和发现,使 Dubbo 和 OpenFeign 能够自动发现服务位置。
- 负载均衡与熔断机制:Dubbo 和 OpenFeign 都支持服务间的负载均衡和熔断,保证高可用性。
好的!现在我们来详细讨论第五个问题的解决方案和思路,尤其是如何利用 Maven 聚合工程 和 Nacos 注册中心,将一个原本的单体应用拆分为多个独立的微服务模块,最终实现微服务架构的转型。
5. 利用 Maven 聚合工程和 Nacos 注册中心实现模块拆分,完成微服务架构转型
在这个项目中,原本是一个单体应用,所有的业务逻辑、服务、数据存储都在同一个项目里。这种单体结构随着业务规模的扩大,会逐渐变得难以维护和扩展。为了解决这些问题,采用了 微服务架构,将应用拆分成多个独立的服务模块,并通过 Nacos 作为注册中心来管理服务的动态注册和发现。
5.1 实现思路
Maven 聚合工程 用于管理项目的多模块结构,将应用拆分为多个独立的微服务模块。
- 每个模块都是一个独立的 Spring Boot 应用,专注于一个单一职责或业务逻辑,便于维护和扩展。
- 父工程统一管理依赖和配置,保证多个模块之间的一致性。
Nacos 注册中心 用于服务发现和管理。
- 每个服务在启动时向 Nacos 注册自己的信息,其他服务可以通过 Nacos 获取服务的地址,从而实现服务之间的动态调用。
- Nacos 还能提供配置管理功能,集中管理多个微服务的配置文件,简化多环境配置。
5.2 实现步骤
1. 使用 Maven 聚合工程进行模块拆分
Maven 聚合工程 是一种多模块项目管理的方式。父工程(parent project)可以统一管理依赖、插件、配置等,而子模块则是具体的微服务。通过这种方式,可以有效解决微服务项目中依赖管理混乱和代码重复的问题。
1.1 创建父工程
在项目根目录下创建一个 Maven 父工程 pom.xml,作为所有子模块的统一管理者。
1 | |
1.2 创建子模块
在父工程下创建各个微服务模块,比如 user-service、order-service、gateway 等,每个子模块都是一个独立的 Spring Boot 应用。
- user-service:负责用户相关的业务逻辑(用户注册、登录、鉴权等)。
- order-service:处理订单相关的操作(订单创建、支付、查询等)。
- gateway:作为 API 网关,负责请求的统一入口。
在每个子模块的 pom.xml 文件中,继承父工程的配置:
1 | |
这样,父工程可以集中管理依赖和插件,每个子模块只需专注于自己的业务逻辑,从而减少配置的重复性和复杂性。
1.3 独立启动与运行
每个子模块都是一个独立的 Spring Boot 项目,可以单独启动。由于每个模块都运行在不同的端口或服务地址上,它们之间的通信是通过 RPC 或 HTTP 进行的。
2. 使用 Nacos 作为注册中心和配置中心
在微服务架构中,服务之间需要能够动态地发现和调用彼此。Nacos 是一个服务发现和配置管理平台,可以简化这一过程。
2.1 Nacos 注册中心的引入
在每个子模块中引入 Nacos 客户端的依赖。
1 | |
2.2 配置 Nacos 服务发现
在每个微服务模块的 application.yml 中,配置 Nacos 作为注册中心。启动时,服务会自动向 Nacos 注册,并提供服务名称和地址信息,其他服务可以通过 Nacos 获取这些信息来进行调用。
1 | |
2.3 服务发现与调用
在服务消费者端,使用 Spring Cloud 的 @LoadBalanced 注解和 RestTemplate 或者 OpenFeign 来实现服务调用。
例如,通过 Feign 客户端调用 user-service:
1 | |
这样,服务消费者无需关心 user-service 的具体地址,Nacos 会动态分配服务实例并进行负载均衡。
3. 微服务配置管理
Nacos 除了提供服务发现功能外,还可以作为配置中心来集中管理微服务的配置文件。在大型项目中,每个微服务往往需要不同的配置,特别是在多环境部署的场景下(比如开发、测试、生产环境),配置管理变得十分复杂。Nacos 可以帮助我们在不同环境中集中管理这些配置。
3.1 使用 Nacos 管理配置
在 Nacos 管理控制台中,可以为每个微服务定义配置文件,并按不同的环境进行管理。例如,针对 user-service 的配置文件可以放在 Nacos 中,而不再需要放在项目的 application.yml 里。
3.2 动态刷新配置
通过 spring-cloud-starter-alibaba-nacos-config,Nacos 可以实现配置的动态刷新。也就是说,当我们在 Nacos 控制台更新了配置项后,微服务可以自动感知到这些变化并实时应用,无需重启服务。
1 | |
然后在代码中使用 @Value 注解注入配置,配置变动时自动刷新:
1 | |
5.3 关键技术
- Maven 聚合工程:通过父工程和子模块的结构,将微服务项目划分为多个独立模块,便于依赖管理和模块化开发。
- Nacos 注册中心:负责服务的注册与发现,帮助微服务在启动时自动将自身信息注册到中心,其他服务可以通过它动态调用,简化了服务管理。
- Nacos 配置中心:集中化管理多个服务的配置,支持配置的动态刷新,极大简化了多环境下的配置管理。
5.4 优点
- 模块化架构:通过 Maven 聚合工程,每个微服务都有独立的业务逻辑,模块之间松耦合,维护更加方便。
- 服务动态发现:Nacos 实现了服务的自动注册和发现,
好的!现在我们来详细讨论第六个问题的解决方案和思路,即 如何使用 Sentinel 实现微服务的限流、熔断与降级。这一部分是微服务架构中至关重要的一环,能够帮助系统在高并发、异常情况下保持稳定性,提升系统的健壮性。
6. 使用 Sentinel 实现微服务的限流、熔断与降级
在微服务架构下,每个服务都是独立运行的,但也有可能产生某些服务因为高并发或者异常情况而不可用,影响整个系统的稳定性。为了解决这个问题,Sentinel 提供了一套完整的流量控制、熔断和降级机制,帮助微服务在高压力和故障场景下保持稳定。
6.1 实现思路
- 限流:当某个微服务的请求量达到某个阈值时,通过 Sentinel 限制请求,避免系统被瞬时流量压垮。
- 熔断:当某个微服务出现长时间故障或响应时间过长时,触发熔断机制,停止调用该服务一段时间,给系统时间进行恢复。
- 降级:当某些服务不可用时,提供降级处理逻辑,例如返回默认值或提示“服务不可用”,而不是直接导致系统崩溃。
通过 Sentinel,这些策略可以灵活配置和自动应用,从而保障微服务架构下的服务稳定性。
6.2 实现步骤
1. 引入 Sentinel 依赖
首先需要在各个微服务模块中引入 Sentinel 的依赖。Sentinel 可以与 Spring Cloud 生态无缝集成。
1 | |
2. 配置 Sentinel
在各个微服务的配置文件 application.yml 中,启用 Sentinel 并配置必要的参数,例如连接 Nacos 作为配置和监控中心。
1 | |
同时,在 Nacos 中可以通过配置中心集中管理 Sentinel 的限流、熔断规则。
3. 实现限流功能
限流 是指当某个服务的请求量超过预设的阈值时,Sentinel 会限制更多的请求进入该服务,以保护系统。
3.1 定义限流规则
在 Sentinel 中,可以基于 QPS(每秒查询数)来限制流量。当某个服务的 QPS 超过预设的阈值时,Sentinel 会自动拒绝更多请求。
1 | |
在这个例子中,当 getUserById 方法的请求量超出阈值时,Sentinel 会触发限流,返回一个默认的用户对象,而不会让系统崩溃。
3.2 动态调整限流规则
Sentinel 可以与控制台集成,允许我们在运行时通过 Sentinel 控制台动态调整限流策略。控制台支持实时监控流量并根据实际需求调整限流阈值,而不需要重启服务。
4. 实现熔断功能
熔断 机制可以让服务在发生连续性错误时,短暂停止对某个不稳定服务的调用,避免连锁反应导致整个系统崩溃。熔断与限流的不同之处在于,熔断通常基于服务的响应时间、失败率等条件触发。
4.1 配置熔断规则
Sentinel 支持基于 错误率 或 响应时间 来触发熔断。比如,当某个服务的响应时间过长时,可以触发熔断,停止调用该服务一段时间。
1 | |
当 getOrderById 方法的响应时间超出一定范围或错误率达到一定阈值时,Sentinel 会触发熔断,停止调用该方法,并执行 fallbackHandler 逻辑。
4.2 熔断恢复
Sentinel 会在熔断触发后的一段时间内自动尝试恢复调用。如果服务恢复正常,熔断器会自动关闭,恢复对服务的调用。
5. 实现降级功能
降级 机制可以在服务响应变慢或不可用时,提供一种降级处理逻辑,确保用户不至于看到系统崩溃的情况。常见的降级策略包括返回默认数据或提示用户“服务暂不可用”。
5.1 基于慢调用的降级
Sentinel 可以基于慢调用来触发降级。例如,如果某个服务的平均响应时间超过某个阈值,Sentinel 会自动返回降级的响应,而不是让用户等待过长时间。
1 | |
在这个例子中,当 getProductDetails 方法的响应时间过长时,Sentinel 会执行 productFallback 方法,返回一个默认的产品信息。
6. 集成 Sentinel 控制台进行监控和管理
Sentinel 提供了一个可视化的控制台,用于监控各个微服务的流量、熔断情况和限流指标。通过控制台,可以直观地看到各个服务的运行状态,并在发生异常时及时调整规则。
6.1 安装和启动 Sentinel 控制台
可以下载并启动 Sentinel 控制台,然后在控制台中查看各个微服务的实时流量、限流和熔断情况。
1 | |
启动后可以通过 http://localhost:8719 访问控制台,查看微服务的运行情况,并进行流量规则的动态调整。
6.2 监控服务运行状态
通过控制台,我们可以实时查看以下信息:
- 每个微服务的 QPS(每秒查询数)
- 每个服务的熔断情况
- 限流和降级的触发频率
这些信息可以帮助我们优化系统的性能,确保在高并发或故障情况下依然能稳定运行。
6.3 关键技术
- Sentinel:阿里巴巴开源的流量控制组件,支持服务的限流、熔断、降级等功能,能够保证微服务的高可用性。
- 限流策略:通过配置流量阈值,限制请求量,以避免系统被瞬时流量压垮。
- 熔断机制:当服务响应变慢或出错时,自动停止对该服务的调用,避免故障蔓延。
- 降级处理:提供服务不可用时的默认处理逻辑,保证用户不会直接看到错误。
- 控制台监控:通过可视化控制台,实时监控流量情况,动态调整限流和熔断规则。
6.4 优点
- 增强系统稳定性:通过限流、熔断和降级策略,系统可以在高并发和故障情况下依然保持稳定,避免连锁反应导致系统崩溃。
- 动态调整规则:Sentinel 提供了控制台和 API,可以在运行时动态调整流量控制策略,无需重启服务,极大提高了灵活性。
- 降低开发复杂性:开发者只需专注于业务逻辑,限流、熔断等
逻辑可以通过配置和注解轻松实现,减少了大量的手工代码编写工作。
通过使用 Sentinel,我们不仅能确保服务在高并发和故障情况下保持可用,还可以根据实际业务需求灵活调整系统的流量控制策略。这套方案能够显著提升微服务架构下系统的稳定性和健壮性。
好的!现在我们来详细讲解第七个问题的解决方案和思路,即 如何利用 Spring Boot 自动配置机制,自主设计客户端 SDK。通过这套机制,我们可以为平台用户提供一套便捷的客户端 SDK,简化接入平台 API 的流程。以下是实现的具体步骤和关键技术。
7. 应用 Spring Boot 自动配置机制,自主设计客户端 SDK
这个 SDK 的核心目的是让开发者通过简单的配置和方法调用,就能使用 MryAPI 平台提供的各种 API 服务。我们将利用 Spring Boot 自动配置机制 来实现 SDK 的初始化配置,并且通过封装 API 调用,简化接入逻辑,使开发者可以快速集成和使用。
7.1 实现思路
Spring Boot 自动配置:利用 Spring Boot 的自动配置机制,让 SDK 自动加载必要的配置,无需开发者繁琐设置。通过
@EnableAutoConfiguration和@ConfigurationProperties自动完成配置项的绑定和加载。封装 API 调用:在 SDK 中封装好所有与平台 API 对接的逻辑,提供简单的接口给开发者调用,减少他们手动编写 HTTP 请求的繁琐操作。
统一错误处理与日志记录:SDK 内部实现全局的错误处理与日志记录,开发者可以通过这些机制快速捕获错误并进行排查。
7.2 实现步骤
1. 创建 Maven 项目并打包 SDK
首先,我们需要将这个 SDK 项目创建为一个 Maven 项目,因为 Maven 提供了依赖管理和打包发布功能。我们可以通过 mvn clean install 来生成 SDK jar 包,供其他项目引入。
在 pom.xml 中,定义 SDK 的基础依赖,比如 Spring Boot 和用于 API 调用的 HTTP 客户端工具(如 RestTemplate 或 HttpClient):
1 | |
2. 使用 Spring Boot 自动配置
Spring Boot 的自动配置机制是通过 @EnableAutoConfiguration 和 @ConfigurationProperties 实现的。我们可以将 SDK 的配置通过 application.yml 或 application.properties 文件进行加载,并自动绑定到一个 Java 类中。
2.1 定义配置属性类
我们首先需要创建一个配置类,用于绑定开发者在 application.yml 中填写的 SDK 配置项,比如 API 访问地址、密钥等。
1 | |
在这个类中,我们使用 @ConfigurationProperties 注解将配置项与类属性绑定。这样,当开发者在项目中设置了 mryapi.client.baseUrl、mryapi.client.accessKey、mryapi.client.secretKey 等参数后,Spring Boot 会自动将这些值加载到 MryApiClientProperties 中。
2.2 配置自动装配类
接下来,我们创建一个自动装配类,用于在开发者的项目中自动装配我们的 SDK:
1 | |
通过 @EnableConfigurationProperties 注解,我们把 MryApiClientProperties 自动加载到 Spring 容器中,并通过 @Bean 创建一个 MryApiClient 客户端实例供开发者调用。
3. 封装 API 调用逻辑
为了让开发者能轻松调用平台的 API,我们需要将复杂的 HTTP 请求封装到 SDK 中,开发者只需调用接口而不必关心底层细节。
3.1 创建 API 客户端类
1 | |
在这个 MryApiClient 类中,我们封装了 API 调用逻辑,如随机壁纸的获取。我们使用 RestTemplate 发起 HTTP 请求,并在请求头中加入认证信息(例如通过 accessKey 和 secretKey 生成的签名)。开发者无需关心 HTTP 请求的具体细节,只需调用 getRandomWallpaper() 方法即可。
3.2 提供更多 API
我们可以将平台的所有 API 都封装在这个 MryApiClient 类中,开发者只需调用相应的方法即可。例如,可以添加获取随机诗词、上传文件等接口:
1 | |
4. 统一错误处理和日志记录
为了帮助开发者快速排查问题,我们需要在 SDK 中实现统一的错误处理和日志记录功能。
4.1 错误处理
在 API 调用的过程中,可能会遇到网络问题或服务器返回错误信息。在 SDK 中,我们可以捕获这些异常并抛出自定义的错误,以便开发者能够处理。
1 | |
4.2 日志记录
我们可以在每次 API 调用时记录请求日志,帮助开发者在出现问题时定位。
1 | |
这样,开发者就可以通过日志了解每次 API 调用的请求和响应细节。
5. 发布 SDK
最后,我们可以将 SDK 打包发布到 Maven 中央仓库或私有仓库,供开发者通过 pom.xml 引入并使用。
1 | |
通过这种方式,开发者只需要在他们的项目中添加 Maven 依赖即可使用我们封装的 SDK。
7.3 关键技术
- Spring Boot 自动配置:通过
@EnableAutoConfiguration和@ConfigurationProperties实现自动加载配置,减少开发者的手动配置步骤。 - Maven 打包发布:通过 Maven 将 SDK 打包为 jar 文件,供开发者下载和集成到他们的项目中。
- API 调用封装:通过封装 HTTP 请求逻辑,让开发者只需简单调用方法即可访问 API 服务。
- 统一错误处理与日志记录:在 SDK 内部统一处理异常并记录日志,方便开发者排查问题。
7.4 优点
- 简化接入流程:通过 Spring Boot 自动配置机制和 API 封装,开发者只需要少量的配置,就能快速集成和使用平台提供的 API。复杂的配置和请求处理逻辑都由 SDK 内部完成,开发者可以通过简单的接口调用来完成复杂的任务。
- 降低开发者工作量:开发者无需处理繁琐的 HTTP 请求、签名生成、异常处理等低层次细节。SDK 提供了高层次的 API 调用封装,降低了出错概率,并提升了开发效率。
- 增强可维护性:通过统一的错误处理和日志记录机制,开发者能够更快地定位问题。异常信息和日志的集中管理使得排查和调试问题更加方便,提升了项目的可维护性。
- 灵活性高:开发者仍然可以通过简单的配置参数修改 API 基础设置(如 baseUrl、accessKey 和 secretKey)。自动配置机制让 SDK 适应不同的使用场景,具备较高的灵活性。
- 可扩展性强:通过封装 API 调用,后续如果平台增加了新的功能或 API,SDK 也可以通过扩展现有的类和方法来支持新功能,保证开发者可以轻松使用平台的新特性。
- 标准化集成:Maven 项目结构及依赖管理让开发者可以通过标准的方式引用 SDK,方便团队协作、持续集成(CI/CD),并支持自动化构建和发布流程。
通过这些思路和技术实现,这个 SDK 设计将让开发者以最小的配置和学习成本快速使用 MryAPI 提供的各类服务,并且在遇到问题时,能够方便地调试和解决,极大提升了开发体验。
好的!现在我们来详细讲解 如何自主设计多样化接口服务(如随机壁纸、随机生成诗词)。这部分不仅涉及到数据的随机获取,还包括使用外部 API,确保这些接口能够为用户提供丰富且多样的功能。
8. 自主设计多样化接口服务(如随机壁纸、诗词生成)
8.1 随机壁纸服务
实现方式:
从数据库预存壁纸链接:我们可以在 MySQL 数据库中存储一些预先收集的壁纸 URL,然后通过 SQL 查询从这些数据中随机选取一个返回给用户。这是最简单的方式,因为所有数据都已经掌握在我们手中,查询速度也较快。
- SQL 查询随机壁纸的方式:
1
SELECT * FROM wallpapers ORDER BY RAND() LIMIT 1;
这个查询会随机从
wallpapers表中选取一张图片,并返回给前端用户。ORDER BY RAND()通过随机排序机制,每次都会返回不同的结果。- SQL 查询随机壁纸的方式:
调用第三方壁纸 API:如果我们不想自行维护一套壁纸数据库,可以直接调用第三方的壁纸服务 API。很多服务提供商可以返回壁纸资源,通过 Java 的随机数生成算法,从第三方 API 返回的壁纸集合中挑选一张。
示例:
通过 HTTP 请求调用一个壁纸 API,获取一个壁纸列表:1
2
3
4
5
6
7
8
9RestTemplate restTemplate = new RestTemplate();
String url = "https://example.com/api/wallpapers";
WallpaperResponse response = restTemplate.getForObject(url, WallpaperResponse.class);
// 从返回的壁纸列表中随机选取一张
List<String> wallpapers = response.getWallpapers();
int randomIndex = new Random().nextInt(wallpapers.size());
String randomWallpaper = wallpapers.get(randomIndex);
return randomWallpaper;
涉及技术:
- MySQL 随机查询:我们可以使用
ORDER BY RAND()来从数据库中随机选取记录,这是一个高效的方式来实现随机性。 - Java 随机数生成:在调用第三方 API 时,使用
java.util.Random类生成随机数,从而实现随机选择壁纸的逻辑。 - 第三方 API 调用:使用
RestTemplate或HttpClient等工具进行 HTTP 请求调用外部壁纸服务。
8.2 随机生成诗词服务
实现方式:
从数据库中随机选择诗词:我们可以建立一个包含经典诗词的 MySQL 数据库,类似于上面随机壁纸的方式,从数据库中随机选取一条诗词记录返回给用户。
- 随机选择诗词的 SQL 查询:
1
SELECT * FROM poems ORDER BY RAND() LIMIT 1;
这个查询可以返回一首随机的诗词,用户每次调用接口都会看到不同的内容。诗词表可以包含多个字段,如诗词内容、作者、朝代等信息,用户可以根据需要进行自定义显示。
- 随机选择诗词的 SQL 查询:
调用第三方 AI 生成诗词 API:如果我们想提供更加个性化的内容,可以集成一些第三方服务,使用 AI 来生成诗词。许多 AI 模型可以根据用户输入的关键词或风格,生成符合需求的诗词内容。
示例:
1
2
3
4
5
6
7String apiUrl = "https://example.com/api/generate-poem";
Map<String, String> params = new HashMap<>();
params.put("theme", "nature");
RestTemplate restTemplate = new RestTemplate();
String poem = restTemplate.postForObject(apiUrl, params, String.class);
return poem;
通过调用这个 API,生成的诗词可以基于用户输入的主题或风格,提供定制化的内容。
涉及技术:
- MySQL 随机查询:同样地,通过
ORDER BY RAND()来从数据库中随机选取一首诗词。 - AI 生成诗词的第三方 API 调用:我们可以使用
RestTemplate或HttpClient来与第三方 AI 服务交互,实现自动生成诗词的功能。
8.3 接口文档生成
为了让开发者快速理解并使用这些 API,我们可以使用 Swagger 自动生成接口文档。Swagger 可以通过注解的方式,自动生成清晰的 API 文档,包含接口请求参数、响应数据结构、错误码说明等。
实现方式:
添加 Swagger 依赖:
在pom.xml中引入 Swagger 相关依赖,例如swagger-ui和springfox-swagger2,以生成和展示 API 文档。1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>配置 Swagger:
在 Spring Boot 项目中创建配置类启用 Swagger。1
2
3
4
5
6
7
8
9
10
11
12@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2)
.select()
.apis(RequestHandlerSelectors.any())
.paths(PathSelectors.any())
.build();
}
}通过注解配置 API 文档:
对每个 API 进行注解,使其在 Swagger 文档中展示。示例:
1
2
3
4
5
6
7
8
9
10
11@RestController
@RequestMapping("/api/wallpaper")
public class WallpaperController {
@ApiOperation(value = "获取随机壁纸", notes = "从数据库或第三方 API 获取一张随机壁纸")
@GetMapping("/random")
public String getRandomWallpaper() {
// 随机壁纸逻辑
return wallpaperService.getRandomWallpaper();
}
}
通过
@ApiOperation注解,我们可以为每个接口提供详细的描述,开发者可以通过 Swagger UI 界面看到所有 API 的信息,并进行接口测试。
涉及技术:
- Swagger 注解:使用
@ApiOperation等注解为接口提供详细描述,便于开发者了解接口的用途、参数和响应结构。 - Swagger 自动生成文档:Swagger 会根据注解自动生成可交互的 API 文档,开发者可以通过浏览器访问
/swagger-ui.html查看和测试接口。
总结
随机壁纸服务:我们可以通过两种方式实现——要么从数据库中随机查询壁纸链接,要么调用第三方 API 获取壁纸。具体实现时可以根据需求选择合适的方案,MySQL 随机查询和 Java 的随机数生成算法是关键技术。
随机生成诗词:同样可以从本地数据库中查询已有的诗词,也可以通过调用第三方 API 实现 AI 自动生成诗词,具体方案取决于业务需求。
接口文档生成:利用 Swagger,可以快速生成带有说明的 API 文档,开发者不仅能够快速了解接口,还可以在文档中直接进行接口测试,提升了开发效率。
通过以上这些技术和实现方式,你可以为用户提供多样化的服务,并确保开发者能够快速上手和使用这些 API。
Search 项目回答思路
好的!接下来我将根据你提供的七个亮点,将每个业务的实现方案和思路用通俗易懂的方式讲解,保证每一点都逻辑清晰,便于理解。
1. Spring AOP 切面编程和自定义注解进行权限校验与日志管理
解决方案:
- 问题:项目中需要对一些核心业务逻辑(如权限校验、日志管理等)进行统一处理,不能每次都手动编写这些重复代码。
- 思路:通过 Spring AOP(面向切面编程),你可以定义一个“切面”,在方法执行前或执行后进行统一处理。使用 自定义注解,可以灵活地标记哪些方法需要执行这些操作。
实现步骤:
- 定义注解:创建注解,如
@CheckPermission,可以通过注解标记某些方法需要进行权限校验。 - 编写 AOP 切面:用
@Aspect定义一个切面,拦截标注了@CheckPermission的方法。然后在方法执行前后插入权限校验逻辑,以及记录日志。 - 日志管理:在切面里统一记录每个方法的执行情况,简化了手动添加日志的过程。
通俗理解:你可以把 AOP 理解成“全局监听器”,它可以在你不修改业务代码的情况下,在每次方法执行时做额外的工作(比如权限验证、日志记录)。而自定义注解就像是“贴标签”,帮你标明哪些方法需要这个额外的工作。
2. 使用 JWT 替代 Session 进行用户身份认证
解决方案:
- 问题:传统的 Session 机制需要服务器存储用户的会话信息,随着用户增多,服务器负载变大。
- 思路:通过 JWT(JSON Web Token),不再依赖服务器保存会话信息。登录时生成一个 JWT,用户每次请求都携带这个令牌,服务器通过验证令牌的有效性来确认用户身份。
实现步骤:
- 用户登录时生成 JWT:当用户登录时,服务器会生成一个包含用户信息的 JWT,返回给客户端。JWT 使用加密算法进行签名,防止篡改。
- 客户端存储 JWT:客户端(比如浏览器或移动应用)保存这个 JWT,并在每次请求时通过 HTTP 请求头携带它。
- 服务器验证 JWT:每次收到请求时,服务器会解析并验证 JWT 的合法性,如果通过验证,则允许继续访问。
通俗理解:JWT 就像是用户的“通行证”,里面记录了用户的信息。服务器通过验证这个通行证是否被篡改或过期来确认用户身份,不用再为每个用户维护一份会话记录。
3. 定时任务获取热榜并抓取博文数据
解决方案:
- 问题:需要定时从外部获取博文 ID,并爬取详细内容,存入自己的数据库。
- 思路:通过 Spring 定时任务 配置抓取频率,使用 Jsoup 库爬取外部网页,解析并提取所需的博文数据。
实现步骤:
- 设置定时任务:使用
@Scheduled注解定义定时任务,定期从某个外部 API 或网站获取热榜的博文 ID 列表。 - 爬取详细内容:使用 Jsoup 连接到每个博文的网页,抓取详细内容。
- 解析并存储数据:使用 CSS Selector 提取网页中的特定内容(比如博文标题、正文等),然后将这些数据存入自己的数据库。
通俗理解:你可以把定时任务比作“闹钟”,每到一定时间,它就自动去外部抓取最新的博文数据。抓取过程就像你用浏览器访问网页并复制里面的内容,但程序会自动提取有用的信息并保存。
4. Elastic Stack 搜索特性(关键词高亮、搜索建议、热门话题分析)
解决方案:
- 问题:需要实现高级搜索功能,如关键词高亮、自动搜索建议和热门话题分析。
- 思路:使用 Elasticsearch 提供的搜索功能,借助其强大的查询 DSL(领域特定语言),来实现这些特性。
实现步骤:
- 关键词高亮:在用户搜索时,通过 Elasticsearch 的高亮功能,将搜索到的关键词用 HTML 标签包裹起来,返回给前端显示。
- 搜索建议:使用 Elasticsearch 的
Completion Suggester功能,根据用户输入的前缀,实时给出相关的搜索建议。 - 热门话题分析:通过 Elasticsearch 的聚合查询,统计出用户搜索次数最多的关键词或话题。
通俗理解:Elasticsearch 就像一个非常强大的搜索引擎,它不仅能快速帮你找到内容,还能高亮显示匹配的部分、提供智能搜索建议,并且还能帮你分析哪些话题最受欢迎。
5. 适配器模式与门面模式实现聚合搜索
解决方案:
- 问题:系统需要从多个不同的数据源(如数据库、ES、第三方 API)进行搜索,并将结果统一返回给用户。
- 思路:使用 适配器模式 把不同的数据源封装为统一的接口,并通过 门面模式 提供一个简单的入口,前端只需调用一个接口即可实现多个数据源的聚合搜索。
实现步骤:
- 适配器模式:为每个搜索源(如 MySQL、Elasticsearch、第三方 API)创建一个适配器,统一实现
search()方法。这样调用方不用关心背后的实现细节。 - 门面模式:通过一个门面类(
SearchFacade),调用所有搜索源的search()方法,合并所有搜索结果,并返回给前端。
通俗理解:适配器模式就像是把各种不同插头的电器(搜索源)都转换成相同的插头(统一接口),而门面模式则像是一个“总开关”,你只需要按一下这个开关,它会帮你控制所有电器(搜索源)。
6. Logstash 实现数据同步
解决方案:
- 问题:需要定时将 MySQL 数据同步到 Elasticsearch,保证搜索数据的实时性。
- 思路:通过 Logstash 配置管道,将 MySQL 中的变更数据自动同步到 Elasticsearch,使用 JDBC 插件 读取 MySQL 数据,使用 Elasticsearch 插件 写入到 ES。
实现步骤:
- 设置 Logstash 管道:定义 Logstash 的输入(input)为 MySQL 数据源,输出(output)为 Elasticsearch。
- 使用 JDBC 插件:配置 JDBC 插件连接 MySQL,定时查询数据表的变更记录。
- 输出到 Elasticsearch:使用 Elasticsearch 插件,将从 MySQL 获取到的数据插入到 Elasticsearch 中,保证搜索引擎的数据是最新的。
通俗理解:Logstash 就像是一条流水线,它定期从 MySQL(数据仓库)取货,然后自动送到 Elasticsearch(搜索仓库)进行加工,这样你可以始终搜索到最新的数据。
7. 使用 Jsoup 和 CompletableFuture 实现异步数据抓取与批量插入
解决方案:
- 问题:需要高效抓取和处理大量网页数据,并批量插入到数据库中。
- 思路:使用 Jsoup 库抓取外部网站内容,通过 CompletableFuture 实现异步处理,减少抓取和批量插入数据库的等待时间,提升性能。
实现步骤:
- 网页抓取:使用 Jsoup 连接并抓取网页内容,解析 HTML,提取所需的数据信息。
- 异步抓取与处理:使用
CompletableFuture.runAsync()进行异步抓取和数据处理,允许多个任务并行执行,避免单线程的性能瓶颈。 - 批量插入:在数据抓取完成后,将数据进行批量插入到数据库中,减少每次插入的数据库连接开销。
通俗理解:Jsoup 就像是一个爬虫,帮你从外部网站抓取数据,而 CompletableFuture 就像是并行的快递员,多个快递员同时抓取数据并送到数据库,这样大大提高了处理速度。
总结:
这七个亮点结合了多种技术和设计模式,分别解决了权限校验、身份认证、数据抓取、搜索优化和性能提升等问题。每个解决方案都注重系统的扩展性、效率和代码的简洁性,让你的项目在技术架
好的,下面我将更加完整地阐述如何使用 Spring AOP 和 自定义注解 来实现权限校验与日志管理,用通俗易懂的方式展开分析,并介绍涉及的关键技术。
一
问题描述:
在项目中,许多核心功能需要统一进行权限校验,并在业务操作时记录日志。这些操作属于横切关注点,应该独立于业务逻辑,以避免代码冗余和复杂性。因此,直接在业务代码里每次都手动编写权限验证和日志代码既麻烦又容易出错。
思路:
借助 Spring AOP(Aspect-Oriented Programming,面向切面编程),你可以将权限校验和日志管理等横切关注点从业务代码中解耦出来。通过 自定义注解,灵活地标注需要这些操作的地方。AOP 的“切面”相当于一个拦截器,在目标方法执行之前或之后,统一做一些额外处理(例如权限校验、日志记录等),简化了开发过程。
实现步骤:
1. 自定义注解
首先,定义一个简单的注解,标记哪些方法需要做权限校验。例如:
1 | |
这个 @CheckPermission 注解可以用在需要进行权限校验的方法上,比如在一些关键的业务接口方法中。
2. 定义 AOP 切面
AOP 切面是核心,它会捕获标注了 @CheckPermission 的方法,在执行前后做权限验证和日志记录。代码示例如下:
1 | |
@Before:在目标方法执行前进行权限校验。如果用户权限不足,则抛出异常阻止方法执行。@AfterReturning:在目标方法执行成功后,记录一条日志,说明操作成功。
3. 日志管理
切面中的日志管理可以进一步优化,确保所有需要记录的操作都自动生成日志。你可以根据需求扩展日志信息,比如加入用户 ID、时间戳等。这些操作都可以通过切面来处理,减少业务代码中的手动记录。
4. 将注解应用到业务方法中
有了注解和切面之后,你只需要在特定方法上加上这个注解即可。例如:
1 | |
当这个 deleteArticle 方法被调用时,AOP 会自动拦截,先进行权限校验,再根据结果决定是否执行方法。整个过程不需要在方法内部添加额外的权限检查逻辑。
涉及的关键技术:
Spring AOP(Aspect-Oriented Programming):它是一种面向切面的编程方式,允许你在不修改核心业务逻辑的情况下插入一些额外操作,比如权限校验、日志记录等。通过 AOP,你可以在方法执行的不同阶段(如执行前、执行后、抛出异常时)进行额外操作。
@Aspect:定义切面类,标记哪些方法需要插入操作。@Before、@AfterReturning:定义方法拦截时机,分别是在方法执行前和执行成功后触发。
自定义注解:通过创建自定义注解,灵活地标注需要额外处理的方法,比如
@CheckPermission注解用来标记需要权限验证的方法。注解就像是给方法“贴标签”,AOP 切面可以根据这个标签决定是否要进行权限检查。反射机制:AOP 切面通过反射机制动态获取方法上的注解信息,然后根据注解的内容执行相应的权限验证和日志操作。
Spring IoC 容器:通过 Spring 容器管理切面类,确保 AOP 功能能够正确注入到你的项目中,自动拦截标记了注解的方法。
通俗理解:
你可以把 Spring AOP 理解成一个“全局监听器”,它可以在不干扰业务逻辑的前提下,在方法执行的不同阶段插入一些操作。比如说,你想要在某些方法执行时自动检查用户是否有权限、并记录每次操作的日志——不用重复在每个方法里手写这些代码。相反,你通过给方法贴上一个“标签”(自定义注解),AOP 会自动在后台帮你处理这些操作。
比如说,你有一个门禁系统,每次有人要开门,系统自动检查这个人的权限(AOP 做的权限校验),如果权限通过,门就会打开(方法执行),同时系统会记录谁打开了门(日志记录)。
通过这种方式,你的代码不仅更简洁,而且维护起来也更方便,因为所有的权限检查和日志记录逻辑都集中在 AOP 切面里,方法本身只负责它的业务功能,不受其他逻辑的干扰。
总结:
使用 Spring AOP 和自定义注解,你可以高效地处理权限校验和日志管理。这种方式减少了重复代码,提升了系统的可维护性,同时还保证了灵活性。你只需在需要的地方打上注解,就能确保系统的统一性和一致性,而这些操作完全不需要修改业务代码。
使用 JWT(JSON Web Token) 替代传统的 Session 进行用户身份认证是一种现代化的方案,它解决了随着用户量增长而带来的服务器负载和扩展性问题。接下来我会详细解释这个方案,确保通俗易懂,逻辑清晰。
二
问题描述:
在传统的 Session 机制 下,服务器会为每个用户生成并维护一个会话信息(通常存储在服务器内存或数据库中)。随着用户数量的增加,服务器必须不断管理这些会话数据,导致资源消耗大,同时当服务器要扩展为多实例(如微服务架构)时,必须共享这些会话数据,增加了系统的复杂性。
思路:
使用 JWT(JSON Web Token) 可以避免服务器存储用户的会话数据。JWT 是一种无状态的认证机制,它将用户的身份信息封装在一个加密的令牌(token)里,交由客户端保存。每次客户端发起请求时,携带该令牌,服务器验证该令牌的合法性后即可确认用户身份。
实现步骤:
1. 用户登录时生成 JWT
当用户通过用户名和密码登录时,服务器不再生成传统的 session。相反,服务器会生成一个 JWT,其中包含用户的关键信息,比如 用户 ID、角色 等,使用 私钥对其进行签名并返回给客户端。
一个典型的 JWT 结构包括三部分:
- Header:描述令牌的类型和使用的加密算法(如
HS256)。 - Payload:包含用户信息(如用户 ID)以及其他声明(例如角色、过期时间)。
- Signature:对前两部分使用服务器的私钥进行签名,确保数据未被篡改。
JWT 示例(格式为 header.payload.signature):
1 | |
在服务器代码中,生成 JWT 的过程通常如下:
1 | |
2. 客户端存储 JWT
生成 JWT 后,服务器将该令牌返回给客户端。客户端(比如浏览器、移动应用)会将 JWT 保存下来,常见的存储方式有:
- 浏览器: 使用
localStorage或sessionStorage存储。 - 移动应用: 使用安全存储库(如 Android 的 Keystore 或 iOS 的 Keychain)。
1 | |
3. 客户端每次请求时携带 JWT
客户端每次向服务器发送请求时,必须将存储的 JWT 放入 HTTP 请求头的 Authorization 字段中。常见的格式是:
1 | |
在客户端,发起请求时通常会这样做:
1 | |
4. 服务器验证 JWT
服务器在收到客户端的请求后,会从请求头中获取 JWT,并使用事先约定的密钥对其进行解码和验证。如果验证成功,则允许访问,否则拒绝请求。服务器无需存储任何会话数据,所有信息都包含在 JWT 中。
JWT 验证的关键步骤包括:
- 解码:解析 JWT 并提取 Header、Payload、Signature。
- 验证签名:使用服务器的私钥验证签名是否正确。
- 检查有效期:确认 JWT 是否过期。
示例代码:
1 | |
如果 JWT 合法且未过期,服务器将提取出用户 ID 等信息,并继续处理请求。
关键技术:
JWT(JSON Web Token):
- JWT 是一种基于 JSON 的自包含令牌,可以携带用户身份信息和其他声明。它使用对称加密算法(如 HS256)进行签名,确保数据未被篡改。
- JWT 的无状态特性使得服务器无需维护会话信息,从而极大地提高了扩展性,适合分布式系统。
加密与解密:
- 服务器使用密钥对 JWT 进行签名,确保只有持有密钥的服务器才能生成和验证合法的 JWT。客户端不能修改 JWT,因为篡改后的 JWT 会导致签名验证失败。
HTTP Header 传输:
- JWT 通过 HTTP 请求头的
Authorization字段发送,通常遵循Bearer <token>格式,这是一种标准的传输机制,安全且简洁。
- JWT 通过 HTTP 请求头的
过期时间管理:
- JWT 的 Payload 中通常包含
iat(签发时间)和exp(过期时间)字段,服务器会检查令牌是否过期,避免使用过期的令牌来进行操作。
- JWT 的 Payload 中通常包含
通俗理解:
可以把 JWT 想象成“通行证”。每次你登录,服务器会给你一张通行证,上面写着你的身份信息和到期时间。你每次去某个地方(比如请求服务器的资源),只需要出示这张通行证,服务器一看,觉得你身份没问题,也没过期,就会让你通过。
而与传统的 Session 不同的是,这张“通行证”是你自己保管的(在客户端存储),服务器不需要一直记住你拿过通行证。所以,服务器的压力会小很多。而且,如果有多个服务器,它们都可以通过验证同一张通行证来确认你的身份,无需相互通信。
总结:
使用 JWT 替代传统的 Session,有以下几个好处:
- 无状态:服务器不需要保存用户的会话数据,降低了服务器的压力,特别适合高并发和分布式系统。
- 扩展性:在微服务架构中,JWT 可以轻松跨服务器验证,无需共享 Session 数据。
- 安全性:JWT 使用加密算法签名,防止令牌被篡改。并且可以设置过期时间,防止长期滥用。
通过这种方式,你的系统不仅可以减少服务器资源的消耗,还能提高系统的扩展性和灵活性,特别是在现代的微服务架构中非常适用。
三、
定时任务获取热榜并抓取博文数据的解决方案
问题背景:你需要定期从外部获取博文的 ID 和详细内容,并将这些信息存入你自己的数据库。手动完成这些步骤显然不现实,所以需要一个自动化的解决方案,来定期执行这些任务。
思路:
通过 Spring 的定时任务功能,你可以设定一个定时器,定期从指定的网站或 API 获取最新的博文 ID 列表。然后,通过 Jsoup 库自动爬取每篇博文的详细内容,并将这些数据解析并保存到数据库中。
整个过程可以分为三个主要步骤:
- 定时获取博文 ID。
- 抓取博文的详细数据。
- 解析并存储数据到数据库。
实现步骤:
1. 设置定时任务获取博文 ID
定时任务就像一个“闹钟”,到了设定的时间就会自动执行。你可以使用 Spring 的 @Scheduled 注解来定义定时任务,比如每隔 30 分钟抓取一次热榜数据。
示例代码:
1 | |
- @Scheduled 注解可以让方法按照设定的频率执行。这里我们使用
fixedRate,每隔 30 分钟触发一次。 - 这个方法会去某个外部网站(或者 API)抓取热榜的博文 ID 列表,比如返回一组热门博文的 ID。
2. 使用 Jsoup 爬取博文详细内容
抓取博文的详细内容可以使用 Jsoup 库。Jsoup 是一个 HTML 解析器,它可以像浏览器那样连接到网页,读取内容,并解析出你需要的部分。
示例代码:
1 | |
- **Jsoup.connect()**:用于连接到博文的 URL,并获取网页的 HTML 内容。
- **doc.select()**:使用 CSS Selector 选择器提取网页中的特定元素,比如博文的标题和正文。
- 假设博文的标题位于
<h1 class="post-title">,而正文位于<div class="post-content">标签中,Jsoup 可以通过类似 CSS 的方式精准提取这些信息。 - 解析完数据后,将其保存到数据库。
3. 将数据存入数据库
在获取到博文的标题和正文之后,你需要将这些数据存储到数据库中。可以使用 Spring Data JPA 或传统的 JDBC 来实现。
示例代码(基于 Spring Data JPA):
1 | |
- 通过调用
blogPostRepository.save(),可以将抓取到的博文数据保存到数据库中。 BlogPost是一个典型的实体类,包含字段title和content,对应数据库表中的字段。
关键技术:
Spring 定时任务(@Scheduled):
- Spring 提供的
@Scheduled注解可以方便地设置定时任务,自动触发数据抓取操作,确保系统定时运行任务。 - 它支持多种方式的调度,例如
fixedRate(固定频率执行)或cron表达式(精确到秒的复杂调度)。
- Spring 提供的
Jsoup:
- Jsoup 是一个非常强大的 HTML 解析库,可以像浏览器一样抓取和解析网页。
- 你可以使用 CSS Selector 来精确选择网页上的元素,比如获取博文的标题、正文、作者等信息。
- 与传统的网页抓取工具不同,Jsoup 可以在后台模拟浏览器的行为,自动处理 HTML 和 CSS,并抓取数据。
CSS Selector:
- CSS Selector 是用来选择 HTML 元素的语法,它非常类似于网页前端中的 CSS 选择器。例如,
h1选择所有<h1>标签,div.post-content选择具有post-content类名的<div>标签。 - 在数据爬取时,通过 CSS Selector 可以精准地定位网页中的数据,而不必手动解析 HTML。
- CSS Selector 是用来选择 HTML 元素的语法,它非常类似于网页前端中的 CSS 选择器。例如,
数据库存储:
- 可以使用 Spring Data JPA 轻松地将抓取到的数据存入数据库。通过定义实体类和 JPA repository,你可以使用简洁的代码实现数据库操作。
通俗理解:
可以把这个过程想象成一个自动化的“爬虫机器人”:
- 首先,它会定时醒来(比如每 30 分钟),去某个地方(外部网站或 API)检查是否有新的热门博文。
- 它找到这些博文的“入口”(博文 ID)后,依次走到每篇博文的具体页面,把里面的内容抓下来。
- 然后,它会按照事先设定好的“规则”(CSS Selector)来挑出有用的信息,比如博文的标题、正文等。
- 最后,它会把这些信息整理好,存到你的数据库里,就像你手动把信息复制到笔记本里一样。
通过这样的自动化流程,你不再需要手动去访问这些网页、复制内容,而是让程序自动帮你抓取并存储所有的数据。
总结:
- 定时任务调度:使用
@Scheduled设置定时任务,实现自动化获取博文数据。 - 网页数据抓取:通过 Jsoup 连接外部网页,使用 CSS Selector 精确提取你需要的博文信息。
- 数据存储:将抓取到的博文数据存入数据库,方便后续的展示或处理。
整个流程自动化程度高,系统稳定运行后,无需人工干预,大大提高了效率。
四
Elastic Stack 搜索特性(关键词高亮、搜索建议、热门话题分析)解决方案
问题背景:你希望在搜索系统中加入更高级的功能,如关键词高亮显示、根据用户输入实时提供搜索建议,以及分析用户最关注的热门话题。这不仅提高了用户体验,还能为后续的数据分析提供有价值的信息。
思路:
通过 Elasticsearch(ES)提供的强大搜索功能,你可以使用其内置的查询 DSL(领域特定语言)来实现这些高级搜索功能。ES 的优势在于它的速度和灵活性,能够处理海量数据并返回精确、丰富的结果。以下是对三个核心功能的实现思路:
- 关键词高亮:帮助用户快速定位搜索结果中的关键内容。
- 搜索建议:根据用户输入提供相关联的搜索建议,提升用户体验。
- 热门话题分析:对用户搜索进行分析,识别最受关注的话题。
实现步骤:
1. 关键词高亮
关键词高亮的作用是,当用户搜索某个关键词时,在搜索结果中,将该关键词用特定的样式(例如 HTML 标签)高亮显示,让用户更容易看到匹配的部分。
具体实现步骤:
- 用户输入查询关键词。
- Elasticsearch 搜索时返回高亮字段:
- 使用 Elasticsearch 中的 highlighting 功能,在查询时返回关键词匹配的内容。
- ES 会自动将匹配的关键词用预定义的 HTML 标签包裹起来(通常为
<em>标签),前端展示时可以将这些关键词突出显示。
示例查询 DSL:
1 | |
- 在这个查询中,ES 会在文档的
content字段中匹配 “Elasticsearch” 这个词,并返回高亮的结果。
通俗理解:当用户搜索“Elasticsearch”时,系统会把搜索结果中所有提到“Elasticsearch”的部分,用比如黄色背景或加粗字体来高亮显示,帮助用户更快找到内容。
2. 搜索建议
搜索建议功能类似于 Google 的联想搜索,当用户在搜索框输入关键词的开头时,系统会自动提供与之相关的建议,用户可以直接点击建议内容,而无需完整输入。
具体实现步骤:
- 配置 Elasticsearch 的 Completion Suggester:
Completion Suggester是 Elasticsearch 提供的一个高效的自动补全功能,它基于输入的前缀来返回匹配的建议结果。- 每当用户输入几个字符时,ES 会根据索引中已有的内容实时提供相关的建议。
示例查询 DSL:
1 | |
- 用户输入了 “Elas” 作为前缀,ES 将基于该前缀提供联想建议,如 “Elasticsearch”、”Elastomer” 等。
fuzzy: true表示支持模糊匹配,容错用户的拼写错误。
通俗理解:当你在搜索框里刚打出 “Elas” 时,系统会立刻提示出类似“Elasticsearch”、“Elastic”这样的词语,省去你继续打字的麻烦,并确保你可以快速找到想要的内容。
3. 热门话题分析
热门话题分析功能通过对用户的搜索行为进行统计,找出大家搜索最多的关键词或话题,帮助你了解哪些内容最受关注。这对数据分析和内容运营非常有用。
具体实现步骤:
- 使用 Elasticsearch 的聚合查询:
- Elasticsearch 提供了强大的 aggregation(聚合)功能,能够对数据进行统计、分组和排序。
- 通过对用户的搜索行为进行聚合查询,你可以统计某段时间内最常被搜索的关键词或主题。
示例查询 DSL:
1 | |
size: 0表示不需要返回具体文档内容,只需要聚合结果。terms聚合可以对search_keyword字段中的值进行分组和计数,size: 10意味着返回前 10 个搜索最多的关键词。
通俗理解:就像你在商店看到一张“最受欢迎产品”的排行榜一样,ES 可以统计出过去一段时间里,用户搜索最多的关键词,从而告诉你哪些话题最受欢迎。
关键技术:
Elasticsearch 的关键词高亮功能:
- 在搜索结果中,通过
highlight功能将用户搜索的关键词用 HTML 标签(如<em>)标记,前端可以将这些部分高亮显示出来。 - 这个功能帮助用户快速定位搜索结果中最相关的部分,提升用户体验。
- 在搜索结果中,通过
Completion Suggester(自动搜索建议):
Completion Suggester是 Elasticsearch 提供的一个高效补全工具,通过用户输入的前缀,返回可能的匹配建议。- 它支持模糊匹配(拼写错误纠正),并且在处理大量数据时,性能非常好。
Elasticsearch 的聚合功能:
Aggregation是 Elasticsearch 用来对大量数据进行分组、统计、排序的工具。- 使用
terms聚合可以轻松实现按关键词统计,找到用户搜索最多的话题。
通俗理解:
关键词高亮:当用户在搜索框中输入“猫”时,系统会显示出包含“猫”的文章或博文,并将其中的“猫”用黄色背景标出来,这样用户可以一眼看到内容的关键部分。
搜索建议:如果用户刚开始输入“猫”,系统会立即提示出“猫咪养护”、“猫咪品种”等相关搜索建议,用户可以直接选择,不必继续输入完整的搜索词。
热门话题分析:系统还会记录所有用户的搜索行为,定期生成一个“热门话题榜”,比如显示“猫”、“狗”、“宠物饲养”等词语搜索得最多,帮助你了解用户的关注点。
总结:
通过 Elasticsearch 提供的搜索功能,你可以实现多个高级特性,提升用户体验和系统分析能力:
- 关键词高亮:让用户能快速定位搜索结果中的关键内容。
- 搜索建议:实时联想用户输入的关键词,提供快速搜索建议。
- 热门话题分析:通过聚合查询分析用户的搜索习惯,找出最受关注的话题。
这些功能不仅提高了搜索体验,还可以为后续的内容优化和用户行为分析提供数据支撑。
五
适配器模式与门面模式实现聚合搜索的解决方案
问题背景:你的系统需要整合来自多个不同数据源的搜索结果。这些数据源可能包括:MySQL 数据库、Elasticsearch(ES)、第三方 API 等。不同的数据源有不同的搜索方式,但用户只需要看到一个统一的搜索结果,而不需要知道这些搜索是在不同的数据源上进行的。
思路:
- 适配器模式:通过适配器模式,你可以把不同的数据源(MySQL、Elasticsearch、第三方 API 等)的搜索接口封装成统一的格式。适配器的作用是隐藏不同数据源的实现细节,只提供统一的
search()方法供调用。 - 门面模式:使用门面模式提供一个统一的接口供前端调用。当用户发起搜索请求时,门面类会同时调用所有数据源的搜索方法,将结果整合后返回给用户。这样前端只需调用一个接口,而不需要处理多个不同数据源的逻辑。
实现步骤:
1. 适配器模式(Adapter Pattern)
适配器模式的核心思想是将不同的数据源封装成统一的接口,使得系统的调用方不需要关心每个数据源的内部实现。
具体实现步骤:
- 定义一个通用的搜索接口:
- 你需要为不同的数据源定义一个统一的接口,比如
SearchService,所有数据源都要实现这个接口。
- 你需要为不同的数据源定义一个统一的接口,比如
1 | |
- 为每个数据源实现具体的适配器:
- 比如你有 MySQL、Elasticsearch 和一个第三方 API 作为数据源,那么你需要为每个数据源创建适配器,实现
SearchService接口中的search()方法。
- 比如你有 MySQL、Elasticsearch 和一个第三方 API 作为数据源,那么你需要为每个数据源创建适配器,实现
示例:MySQL 适配器:
1 | |
示例:Elasticsearch 适配器:
1 | |
示例:第三方 API 适配器:
1 | |
通俗理解:适配器模式就像是在你有多种不同形状的插头时,使用适配器把它们都转换成统一的形状,这样你就可以用同一个插座(统一接口)来处理不同的插头(数据源)。
2. 门面模式(Facade Pattern)
门面模式的作用是为复杂的系统提供一个简化的接口。在聚合搜索中,门面模式负责调用不同数据源的适配器,将这些搜索结果合并后返回给前端。
具体实现步骤:
- 创建门面类:
- 创建一个门面类(比如
SearchFacade),这个类将作为系统的唯一入口,负责调用各个数据源的搜索方法。
- 创建一个门面类(比如
1 | |
整合搜索结果:
- 在
SearchFacade中,将来自不同数据源的搜索结果汇总成一个统一的结果集返回给前端。你可以按需求对结果进行去重、排序或其他处理。
- 在
前端调用门面类:
- 当前端发起搜索请求时,只需要调用
SearchFacade的search()方法,门面类会自动处理不同数据源的搜索并返回统一的结果。
- 当前端发起搜索请求时,只需要调用
通俗理解:门面模式就像是一个“总开关”,你只需要按下这个开关,它会帮你同时打开好几个不同的电器(即多个搜索源)。这样你只需要一次操作(一个接口调用),而不用分别去打开多个开关(分别调用每个数据源的搜索方法)。
技术关键点:
适配器模式的作用:
- 适配器模式将不同数据源的搜索功能封装成统一的接口,使得系统可以通过相同的方式调用这些不同的数据源,而无需了解它们的实现细节。
- 每个数据源适配器只需要实现统一的
search()方法,无论它是基于 MySQL、Elasticsearch 还是第三方 API,调用方只关心它能返回结果。
门面模式的作用:
- 门面模式提供了一个统一的接口,使得系统调用变得更加简单和清晰。前端调用
SearchFacade,无需处理每个数据源的细节,只需要接收聚合后的搜索结果。 - 门面类隐藏了复杂的逻辑,保证系统的模块化和可维护性。
- 门面模式提供了一个统一的接口,使得系统调用变得更加简单和清晰。前端调用
聚合搜索的处理:
- 当你从不同的数据源获取到搜索结果后,你可以对这些结果进行进一步处理,如去重、排序、分页等。这样可以确保用户得到一个整合后的搜索体验,而不是多个杂乱无章的搜索结果。
通俗理解与类比:
适配器模式:就像你买了很多电器,但它们的插头形状各不相同,而你家里只有一种形状的插座。你需要使用适配器来把每个电器的插头转换成相同的形状,这样你就可以统一使用这些电器了。在你的项目中,每个数据源(MySQL、Elasticsearch、API)就像一个不同的插头,而
search()方法是那个统一的插座。门面模式:好比你家里的电器很多,但你不想一个一个开关去开它们。所以你安装了一个总开关,按一下,它会自动打开所有电器。门面模式就是这个“总开关”,你只需调用一次
SearchFacade.search(),系统会自动在所有数据源中搜索并汇总结果,前端不用再去操心具体每个搜索源的细节。
总结:
适配器模式解决了不同数据源之间的接口不统一问题,通过封装,所有数据源的搜索接口看起来都是一致的。
门面模式提供了一个简化的接口,前端只需调用这个统一接口,系统会自动在多个数据源上进行搜索并返回聚合后的结果。
通过结合这两个设计模式,整个聚合搜索系统不仅易于扩展和维护,还能简化调用流程,提升用户体验。
六
Logstash 实现 MySQL 到 Elasticsearch 的数据同步
问题背景:为了保证搜索系统的数据是最新的,项目需要定期将 MySQL 数据库中的内容同步到 Elasticsearch 中。这可以让搜索功能基于最新的数据进行工作,避免因为数据不同步而导致搜索结果不准确。
思路:
通过使用 Logstash 配置数据同步管道,它可以从 MySQL 读取数据,并将其自动写入 Elasticsearch。Logstash 是一个强大的数据处理工具,允许你从各种数据源中读取数据、进行处理,然后将其输出到目标位置。它的 JDBC 插件负责与 MySQL 数据库进行通信,而 Elasticsearch 插件则负责把数据发送到 Elasticsearch 集群中。
实现步骤:
1. 设置 Logstash 数据同步管道
Logstash 管道由 输入(input)、过滤(filter) 和 输出(output) 三部分组成。我们将使用 MySQL 作为输入,Elasticsearch 作为输出。
- Logstash 配置文件:
创建一个 Logstash 配置文件,通常命名为logstash.conf,用于定义整个数据同步流程。
1 | |
input 部分:配置 JDBC 插件来读取 MySQL 数据源。
jdbc_connection_string:指向 MySQL 数据库的连接字符串。jdbc_user和jdbc_password:数据库的用户名和密码。statement:定义查询语句,这里通过查询updated_at字段来获取最新修改的数据。schedule:定义了定时任务的频率,每分钟运行一次。
output 部分:配置 Elasticsearch 插件来写入数据。
hosts:指向 Elasticsearch 集群的地址。index:目标索引,即 Elasticsearch 中存储数据的地方。document_id:指定每条数据在 Elasticsearch 中的唯一标识,避免重复数据插入。
2. 使用 JDBC 插件从 MySQL 读取数据
JDBC 插件允许 Logstash 从关系数据库中读取数据。
通过statement,可以灵活地定义查询语句,比如查询那些新插入或更新的记录。tracking_column:用于记录上次成功同步的时间戳,确保每次只同步新增或变更的数据,而不是重新同步所有数据。
通俗理解:可以将 JDBC 插件看作一个“工人”,它负责从 MySQL 数据库中提取最新的“货物”(数据),然后将这些货物传递给 Logstash 进行处理。
3. 使用 Elasticsearch 插件将数据写入 Elasticsearch
- Elasticsearch 插件负责将从 MySQL 获取的数据插入到 Elasticsearch 中。
index:指定将数据写入哪个索引。document_id:定义每条记录的唯一 ID,确保重复数据不会被重新插入。如果记录已经存在,则会进行更新。
这样,你的搜索引擎(Elasticsearch)就能实时获取到来自 MySQL 的最新数据。
通俗理解:Elasticsearch 插件就像一个“接收员”,它从 JDBC 插件(工人)那里接收到 MySQL 的数据,然后将这些数据分发到 Elasticsearch 的“仓库”(索引)中。
4. 运行 Logstash
配置文件写好后,启动 Logstash 以定期执行数据同步任务。可以通过以下命令启动:
1 | |
Logstash 将根据配置文件中的定时任务(schedule)按设定频率从 MySQL 中查询数据,并将其同步到 Elasticsearch。
技术关键点:
Logstash 的作用:
- Logstash 是一个数据处理工具,可以从多种数据源中提取数据,进行处理(如过滤、格式化等),然后将数据输出到目标系统。在这个场景中,Logstash 扮演着数据传输和处理的角色。
JDBC 插件:
- JDBC 插件专门用于从关系型数据库中提取数据。在这里,它连接 MySQL,并根据你设定的查询条件(如
updated_at字段),定期拉取最新数据。
- JDBC 插件专门用于从关系型数据库中提取数据。在这里,它连接 MySQL,并根据你设定的查询条件(如
Elasticsearch 插件:
- Elasticsearch 插件用于将处理后的数据写入到 Elasticsearch 中。Logstash 处理完从 MySQL 拉取的数据后,会通过这个插件将数据发送到 Elasticsearch 索引中。
实时性与定时任务:
- 通过
schedule设定,你可以控制数据同步的频率,比如每分钟、每小时或更长时间间隔。Logstash 会根据这个设定,自动进行数据同步,确保搜索引擎中的数据是最新的。
- 通过
通俗理解与类比:
Logstash 的流水线:你可以把 Logstash 看成是一条自动化的流水线。这个流水线的任务是从 MySQL 这个“仓库”中取货(数据),然后根据它的设定条件,把“货物”运送到 Elasticsearch 这个搜索引擎仓库中。每过一定时间,流水线就会自动运行一次,确保货物是最新的。
JDBC 插件与工人类比:JDBC 插件可以类比为“工人”,负责从 MySQL 仓库中挑选最新的货物。如果某些数据是之前已经挑选过的,工人就会跳过它们,确保每次只取新的或者变动的数据。
Elasticsearch 插件与接收员类比:Elasticsearch 插件则是“接收员”,它从工人那里接过货物,然后把它们存储到 Elasticsearch 仓库中。接收员的职责是确保每个货物都有唯一的标识,避免重复存储。
总结:
Logstash 是数据同步的核心工具:它像是一条自动化的流水线,能够从 MySQL 定期拉取变更数据,并同步到 Elasticsearch 中。通过 JDBC 插件,它从 MySQL 拉取数据;通过 Elasticsearch 插件,它把数据写入 Elasticsearch。
JDBC 插件 用于从 MySQL 拉取数据:它通过 SQL 查询语句获取最新的变更记录,并通过
tracking_column机制,确保每次只同步变动的数据,而不是所有数据。Elasticsearch 插件 用于写入数据:它会将从 MySQL 获取的数据插入到 Elasticsearch 的索引中,确保搜索数据的实时性。
定时任务控制同步频率:通过 Logstash 的
schedule设定,你可以控制同步的频率,确保你的搜索引擎中的数据始终是最新的。
通过这个方案,你可以自动、实时地将 MySQL 中的数据同步到 Elasticsearch,保持搜索引擎数据的更新和一致性。
七
使用 Jsoup 和 CompletableFuture 实现异步数据抓取与批量插入
问题背景:在项目中,需要从大量网页中抓取数据,并将这些数据存入数据库中。由于网页抓取速度较慢,单线程抓取和插入会导致性能瓶颈。因此,需要通过并行处理和批量插入数据库来提高效率。
思路:
- Jsoup 库用于连接并抓取网页内容,解析 HTML 页面,提取所需数据。
- CompletableFuture 提供了异步编程的能力,可以同时发起多个网页抓取任务,避免逐一处理的等待时间,最大限度地利用系统资源。
- 批量插入数据库 减少了每次单条插入时数据库连接和事务提交的开销,提高了数据库写入的效率。
实现步骤:
1. 使用 Jsoup 抓取网页数据
- Jsoup 是一个强大的 HTML 解析库,类似于浏览器访问网页,并提取其中的内容。
1 | |
- 解析 HTML 内容:Jsoup 提供了类似 CSS 选择器的功能,可以轻松从 HTML 页面中提取文本、图片、链接等各种元素。
2. 使用 CompletableFuture 实现异步数据抓取
- 异步处理:通过
CompletableFuture.runAsync()实现异步抓取。它允许多个任务并行执行,不用等待上一个任务完成再开始下一个,大大提高了处理速度。
1 | |
- 示例说明:
runAsync():在后台线程池中运行抓取任务,避免阻塞主线程。allOf():等待所有异步任务完成,确保所有网页抓取任务都执行完毕。
这样,每个网页抓取任务是独立的,并且多个任务可以同时进行,充分利用了 CPU 的多核性能,避免了单线程逐一抓取时的性能瓶颈。
3. 批量插入数据到数据库
- 批量插入:当抓取完成后,将多条记录一次性插入数据库,减少多次数据库连接开销和事务提交的消耗。
1 | |
- 批处理插入:
- 使用
addBatch()将多条 SQL 语句一次性提交。 executeBatch():批量执行所有插入语句。- 通过关闭
autoCommit并手动控制事务提交,减少每次插入的网络和 I/O 消耗,提升性能。
- 使用
技术关键点:
Jsoup 的作用:
- Jsoup 是一个轻量级的 HTML 解析库,适合用于抓取网页内容并解析其中的数据。通过 CSS Selector,可以快速提取出 HTML 中的关键信息。
- 在这种场景下,Jsoup 就像是一个“爬虫”,自动化地抓取网页并解析内容。
CompletableFuture 的作用:
- CompletableFuture 是 Java 异步编程的重要工具,可以用来并行处理多个抓取任务。它允许多个任务同时进行,而不是一个任务完成后再执行下一个。
- 通过
runAsync()提交异步任务,多个抓取任务并行执行,大大提升了抓取速度。
批量插入数据库:
- 数据库批量插入减少了每次插入时的连接开销,提高了插入效率。在数据抓取完成后,将多个记录一次性写入数据库,可以减少频繁连接数据库的成本。
通俗理解:
Jsoup 的工作原理:
- 可以把 Jsoup 想象成一只“抓取数据的手”,它就像你手动用浏览器访问网页,然后复制网页中的内容。它会自动从网页上获取标题、正文等内容,并将这些数据提取出来,供你使用。
CompletableFuture 异步任务:
- 如果说 Jsoup 是“抓取数据的手”,那么 CompletableFuture 就像是并行工作的“多只手”。它能让多只手同时工作——你可以同时抓取多个网页,而不是一个网页抓完再抓下一个,极大地提高了效率。
批量插入的好处:
- 想象你在做一项任务,每次只处理一条记录,会非常耗时。但是,如果你能一次处理多条记录,就像批量插入数据一样,你就能大大节省时间。批量插入可以减少每次连接数据库的时间消耗,因为它能一次性插入多条数据,而不是每插入一条数据都要重新连接数据库。
通俗类比:
- 抓取网页与批量处理的类比:
- Jsoup 抓取网页就像你用浏览器访问网页,手动复制你需要的信息。
- CompletableFuture 就像“并行的快递员”,多个快递员可以同时去抓取网页信息,而不是一个快递员来回跑,极大提高了效率。
- 批量插入数据库就像批量处理快递,而不是一个一个快递单独处理,可以一次性处理很多,减少了重复操作,提升了整体性能。
总结:
Jsoup 负责抓取网页内容:通过 Jsoup,可以像浏览器一样访问网页并解析 HTML 页面内容,提取出有用的数据。
CompletableFuture 异步并行处理:使用 CompletableFuture 进行异步处理,多个网页抓取任务可以同时进行,减少了逐一抓取带来的延迟,充分利用多核 CPU 资源,极大提升了数据抓取效率。
批量插入数据库:抓取完数据后,将多条记录一次性批量插入数据库,减少了多次数据库连接的开销,优化了插入操作的性能。
这个方案解决了抓取大量网页数据并高效处理的需求,利用异步编程和批量插入提升了系统整体性能,让数据处理变得更加高效。