 高效多元搜索
高效多元搜索
学习目标
在这里,你将系统学习了解高效多元搜索的相关内容
我们将以最简单直接的方式为您呈现内容!
# 🍜 关键词语高亮
- 在 Elasticsearch 中,
关键词语高亮是一种将查询中的特定关键词突出显示在结果中的功能。通过ElasticsearchRestTemplate,您可以轻松地实现这一功能,以改善用户的搜索体验。有关如何配置和使用关键词语高亮的详细指南,可以参考 Elasticsearch 的官方文档或相关教程。 S🍚 推荐阅读:Highlighting | Elasticsearch Guide 7.17] | Elastic (opens new window)
# DSL 实现
- 在 Kibana 面板中的
Dev Tools工具下,执行以下 DSL 语句:
# 搜索高亮语法
- 搜索高亮语法,就是查询词和指示高亮字段相配合的结果:
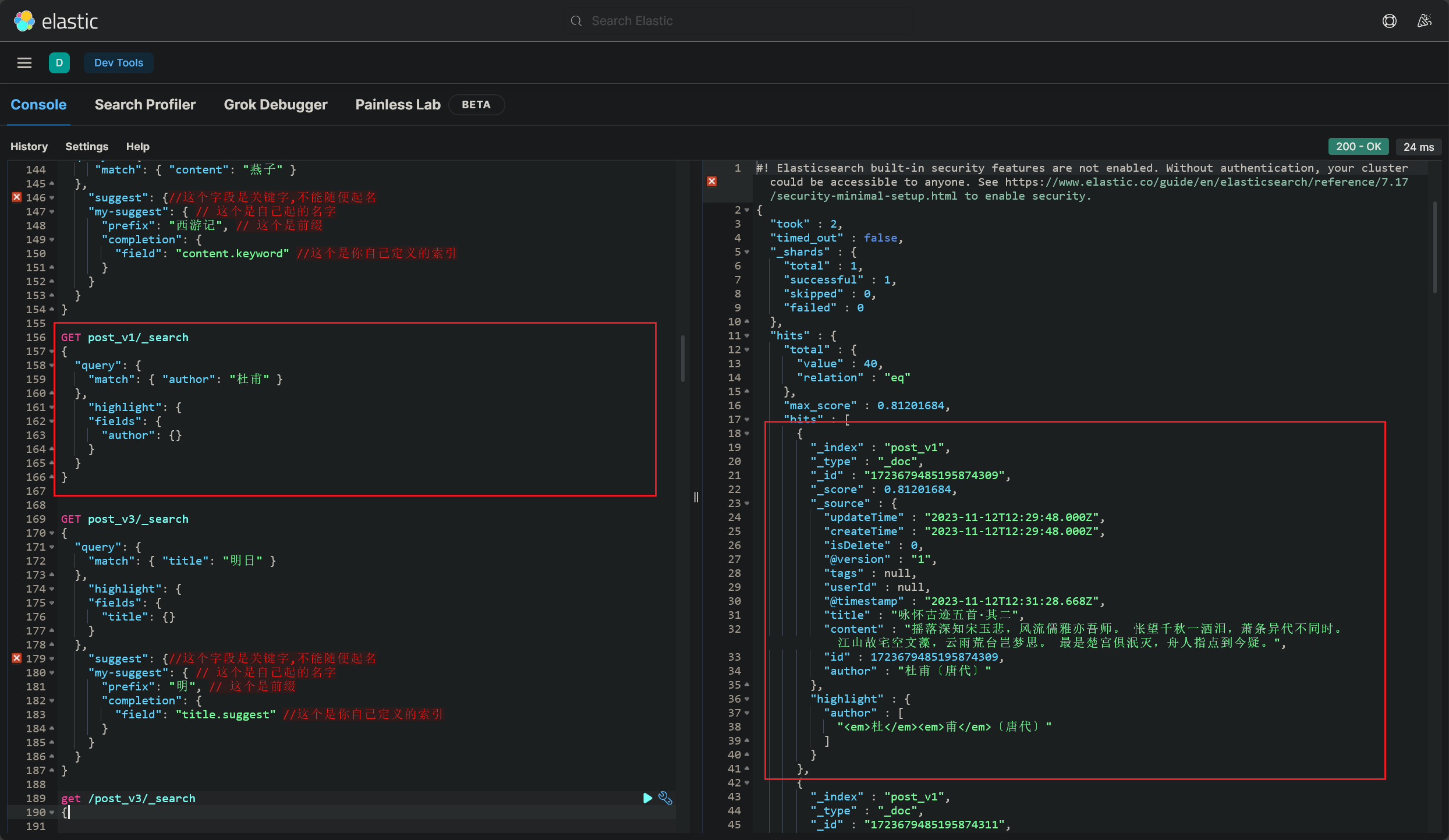
GET post_v1/_search
{
"query": {
"match": { "author": "杜甫" }
},
"highlight": {
"fields": {
"author": {}
}
}
}
- 查询结果如下:
# Java API 实现
# 后端
# 配置搜索高亮
// 配置支持搜索高亮的字段和高亮关键词样式
HighlightBuilder highlightBuilder = new HighlightBuilder()
.field("description")
.requireFieldMatch(false)
.preTags("<font color='#eea6b7'>")
.postTags("</font>");
highlightBuilder.field("title")
.requireFieldMatch(false)
.preTags("<font color='#eea6b7'>")
.postTags("</font>");
# 构造查询
// 构造查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withHighlightBuilder(highlightBuilder)
.withPageable(pageRequest)
.withSorts(sortBuilder)
.build();
# 执行搜索,获取搜索结果
@Resource
private ElasticsearchRestTemplate elasticsearchRestTemplate;
// 执行搜索,获取搜索结果
SearchHits<ArticleEsDTO> searchHits = elasticsearchRestTemplate.search(searchQuery, ArticleEsDTO.class);
- 这里对应的 DSL 语法查询语句为:
GET post_v1/_search
{
"query": {
"match": { "author": "杜甫" }
},
"highlight": {
"fields": {
"author": {}
}
}
}
# 解析高亮关键词
// 组织高亮关键词搜索结果
if (searchHits.hasSearchHits()) {
// 依次获取所有高亮关键词
Map<Long, ArticleEsHighlightData> highlightDataMap = new HashMap<>();
for (SearchHit hit : searchHits.getSearchHits()) {
// 保存高亮关键词
ArticleEsHighlightData data = new ArticleEsHighlightData();
data.setId(Long.valueOf(hit.getId()));
if (hit.getHighlightFields().get("title") != null) {
String highlightTitle = String.valueOf(hit.getHighlightFields().get("title"));
// 记录文档中 title 字段的高亮关键词
data.setTitle(highlightTitle.substring(1, highlightTitle.length() - 1));
System.out.println(data.getTitle());
}
if (hit.getHighlightFields().get("description") != null) {
String highlightContent = String.valueOf(hit.getHighlightFields().get("description"));
// 记录文档中 content 字段的高亮关键词
data.setDescription(highlightContent.substring(1, highlightContent.length() - 1));
System.out.println(data.getContent());
}
// 保存所有高亮关键词
highlightDataMap.put(data.getId(), data);
}
..............................
}
# 根据 id 获取完整记录
//保存搜索结果的 id 列表
List<SearchHit<ArticleEsDTO>> searchHitList = searchHits.getSearchHits();
List<Long> articleIdList = searchHitList.stream().map(searchHit -> searchHit.getContent().getId())
.collect(Collectors.toList());
// 根据 id 在 MySQL 数据库中查询完整记录
List<Article> articleList = baseMapper.selectBatchIds(articleIdList);
# 高亮关键词替换原文本
List<Article> resourceList = new ArrayList<>();
...................................
// 使用高亮关键词替换原文本
if (articleList != null) {
Map<Long, List<Article>> idArticleMap = articleList.stream().collect(Collectors.groupingBy(Article::getId));
articleIdList.forEach(articleId -> {
if (idArticleMap.containsKey(articleId)) {
// 拿到高亮关键词
Article article = idArticleMap.get(articleId).get(0);
String hl_title = highlightDataMap.get(articleId).getTitle();
String hl_des = highlightDataMap.get(articleId).getDescription();
// 高亮关键词替换原文本
if (hl_title != null && hl_title.trim() != "") {
article.setTitle(hl_title);
}
if (hl_des != null && hl_des.trim() != "") {
article.setDescription(hl_des);
}
resourceList.add(article);
} else {
// MySQL 已物理删除该 id 对应记录,同步从 ES 清空数据
String delete = elasticsearchRestTemplate.delete(String.valueOf(articleId), ArticleEsDTO.class);
log.info("delete post {}", delete);
}
});
}
# 返回结果到前端
// 组织搜索结果
Page<Article> page = new Page<>();
page.setTotal(searchHits.getTotalHits());
// 返回最终搜索结果到前端
page.setRecords(resourceList);
return page;
# 前端
# 获取搜索结果
// 执行搜索,获取搜索结果
myAxios.post("/search/all", query).then((res: any) => {
// 搜索到诗词记录
if (type === "post") {
postList.value = res.dataList;
// 搜索到图片记录
} else if (type === "picture") {
if (res.dataList !== null) {
pictureList.value = res.dataList.map((picture: any) => {
return {
...picture,
isVisitable: false,
};
});
}
// 搜索到博文记录
} else if (type === "article") {
articleList.value = res.dataList;
}
});
# 页面显示
<div>
..........................
<a-list
class="demo-loadmore-list"
item-layout="horizontal"
:data-source="articleList"
style="width: 400%"
>
<template #renderItem="{ item }">
<a-list-item>
<template #actions>
🔥
1554
<h2>热度</h2>
<a @click="goToRead(item.id)">查看</a>
</template>
.............................
</a-list-item>
</template>
</a-list>
</div>
- 最终效果如下:
# 🍻 搜索词条建议
- Elasticsearch 提供了
搜索建议功能,可以帮助用户更快地找到他们想要的结果。使用ElasticsearchRestTemplate,您可以轻松地为应用程序添加这一功能。您可以通过分析用户输入的前几个字符,为可能的完整查询或结果提供建议。有关如何设置和使用搜索建议的更详细信息,可以参考 Elasticsearch 的相关文档或教程。
🍚 推荐阅读:Highlighting | Elasticsearch Guide 7.17] | Elastic (opens new window)
# DSL 实现
- 在 Kibana 面板中的
Dev Tools工具下,执行以下 DSL 语句:
# 新增索引
PUT /article_v4
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"suggest": {
"type": "completion",
"analyzer": "ik_max_word"
}
}
}
}
}
}
# 插入文档数据
PUT /article_v2/_doc/1
{
"title": "明日之后",
"content": "拉扎罗夫,我带你回家!"
}
# 搜索测试
GET article_v4/_search
{
"query": {
"match": { "title": "测试" }
}
}
# 搜索词建议
GET article_v4/_search
{
"query": {
"match": { "title": "测试" }
},
"suggest": {//这个字段是关键字,不能随便起名
"my-suggest": { // 这个是自己起的名字
"prefix": "测试", // 这个是前缀
"completion": {
"field": "title.suggest" //这个是你自己定义的索引
}
}
}
}
- 执行结果如下:
# Java API 实现
# 后端
- 新增搜索词索引, 特别指定
searchText字段支持suggest搜索词建议:
PUT /search_text
{
"mappings" : {
"properties" : {
"id" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"searchText" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
},
"suggest" : {
"type" : "completion",
"analyzer" : "ik_max_word",
"preserve_separators" : true,
"preserve_position_increments" : true,
"max_input_length" : 50
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"userId" : {
"type" : "long"
}
}
}
}
# 配置搜索建议
@Resource
private ElasticsearchRestTemplate elasticsearchRestTemplate;
// 搜索建议
SuggestBuilder suggestBuilder = new SuggestBuilder()
.addSuggestion("suggestionTitle", new CompletionSuggestionBuilder("searchText.suggest").skipDuplicates(true).size(5).prefix(suggestText));
// 构造查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withSuggestBuilder(suggestBuilder)
.build();
// 执行搜索
SearchHits<MessageEsDTO> searchHits = elasticsearchRestTemplate.search(searchQuery, MessageEsDTO.class);
- 注意,这里的搜索建议配置跟这条 DSL 语句是对应的:
GET article_v4/_search
{
"query": {
"match_all": {}
},
"suggest": {//这个字段是关键字,不能随便起名
"suggestionTitle": { // 这个是自己起的名字
"prefix": "suggestText", // 这个是前缀
"completion": {
"field": "searchText.suggest" //这个是你自己定义的索引
}
}
}
}
构造了一个 SuggestBuilder 对象,用于构建搜索建议查询。该查询包括一个名为“suggestionTitle”的建议,使用了 CompletionSuggestionBuilder 来指定搜索建议的字段为“searchText.suggest”。设置了跳过重复项、返回建议的最大数量为 5,并为搜索建议提供了前缀文本。
使用 NativeSearchQueryBuilder 构建了包含建议查询的 Elasticsearch 查询对象。然后,通过 elasticsearchRestTemplate 执行了该查询,并得到了 SearchHits 结果。
搜索词 ES 包装类:
/**
* 搜索词 ES 包装类
*
* @author memory
**/
@Document(indexName = "search_text")
@Data
public class MessageEsDTO {
/**
* 文章id
*/
@Id
private String id;
/**
* 用户
*/
private Long userId;
/**
* 搜索词条
*/
private String searchText;
}
# 构造查询
// 搜索建议词列表
ArrayList<String> suggestionList = new ArrayList<>();
// 从 SearchResponse 中获取建议
Suggest suggest = searchHits.getSuggest();
if (suggest != null) {
// 获取特定的建议结果
Suggest.Suggestion<? extends Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option>> termSuggestion = suggest.getSuggestion("suggestionTitle");
// 遍历建议选项
for (Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option> entry : termSuggestion.getEntries()) {
// 处理每个建议选项,例如打印它们
for (Suggest.Suggestion.Entry.Option option : entry.getOptions()) {
if (option != null) {
String text = option.getText();
suggestionList.add(text);
}
}
}
}
提取并处理搜索建议:
首先,初始化了一个空的 suggestionList 列表,用于存储从搜索结果中提取的搜索建议。
接着,从 searchHits 中获取 Suggest 对象,该对象包含了搜索建议的信息。确保 Suggest 对象不为空后,通过 getSuggestion 方法获取了名为“suggestionTitle”的特定建议结果。
然后,遍历了建议结果中的每个条目(Entry),对于每个条目,进一步遍历了其下的选项(Option)。在遍历选项时,检查了选项是否不为空,并提取了选项的文本内容。
最后,将提取到的文本内容添加到 suggestionList 列表中,从而完成了对搜索建议的提取和处理。这个过程为用户提供了可能的搜索关键词建议,有助于改善搜索体验和效率。
注意看,这里可以选取的
建议选项跟这里是一一对应的:
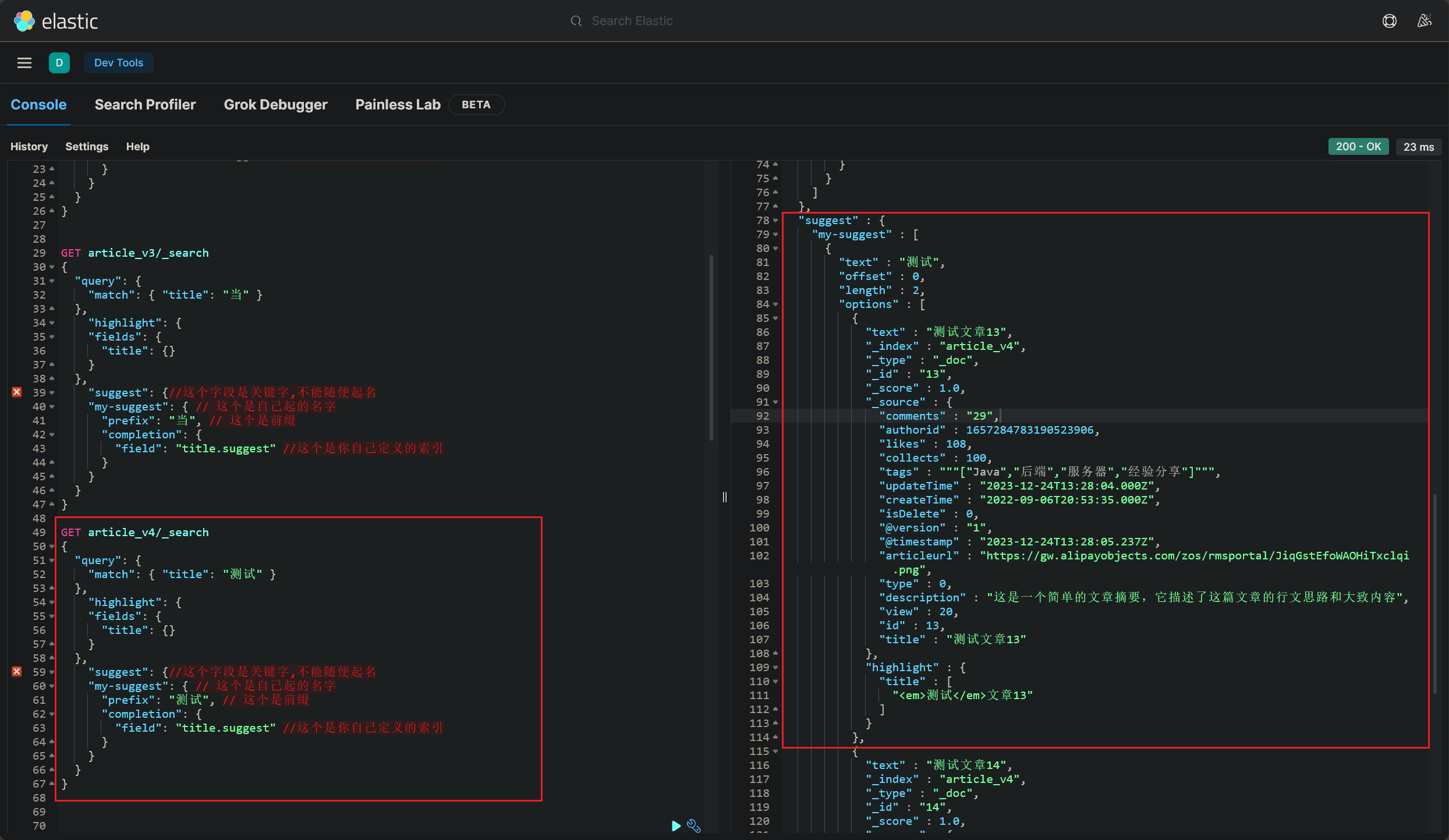
- 执行查询,成功获取到搜索关键词对应的查询建议:
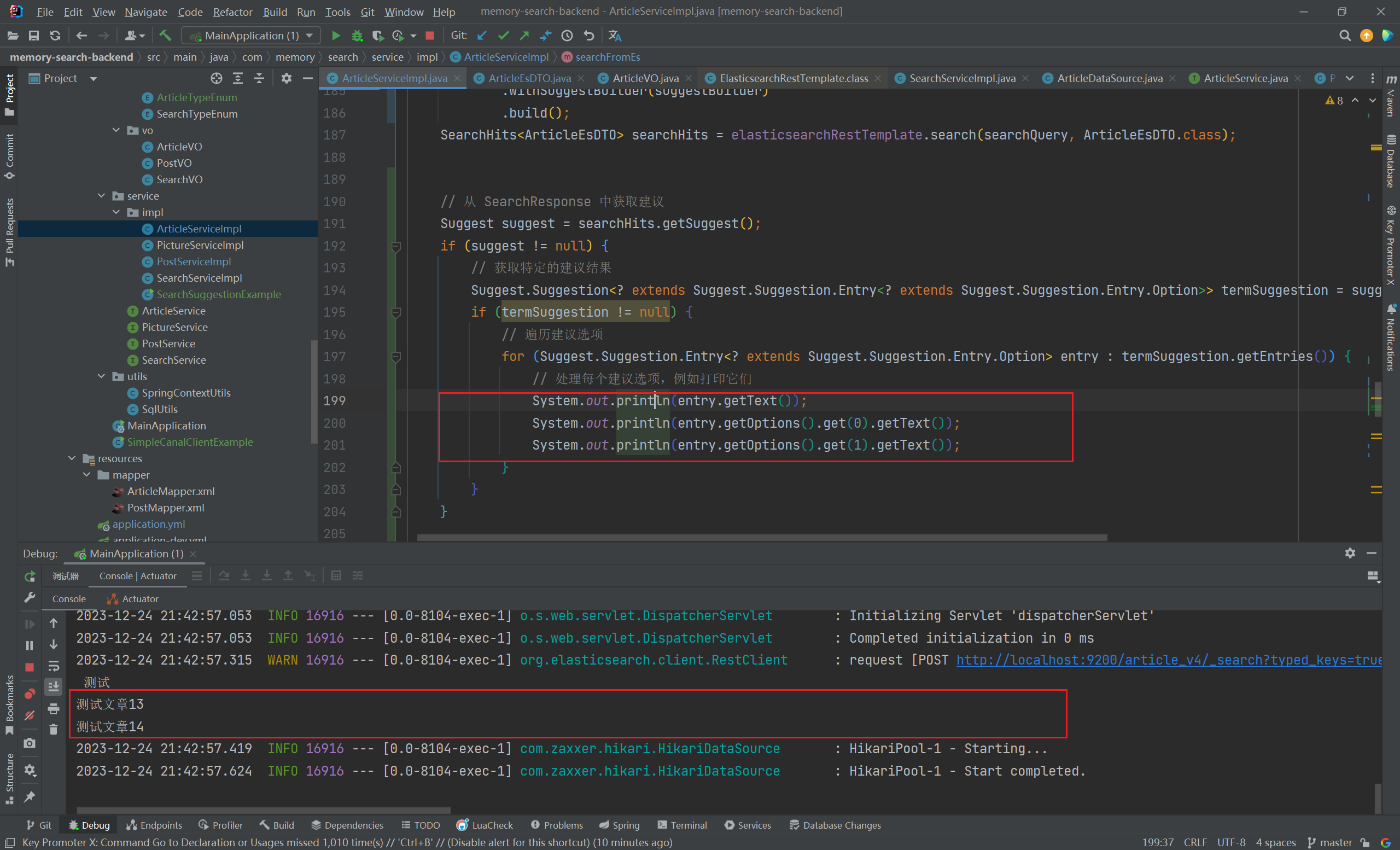
# 返回搜索结果
// 返回搜索建议词列表
return suggestionList;
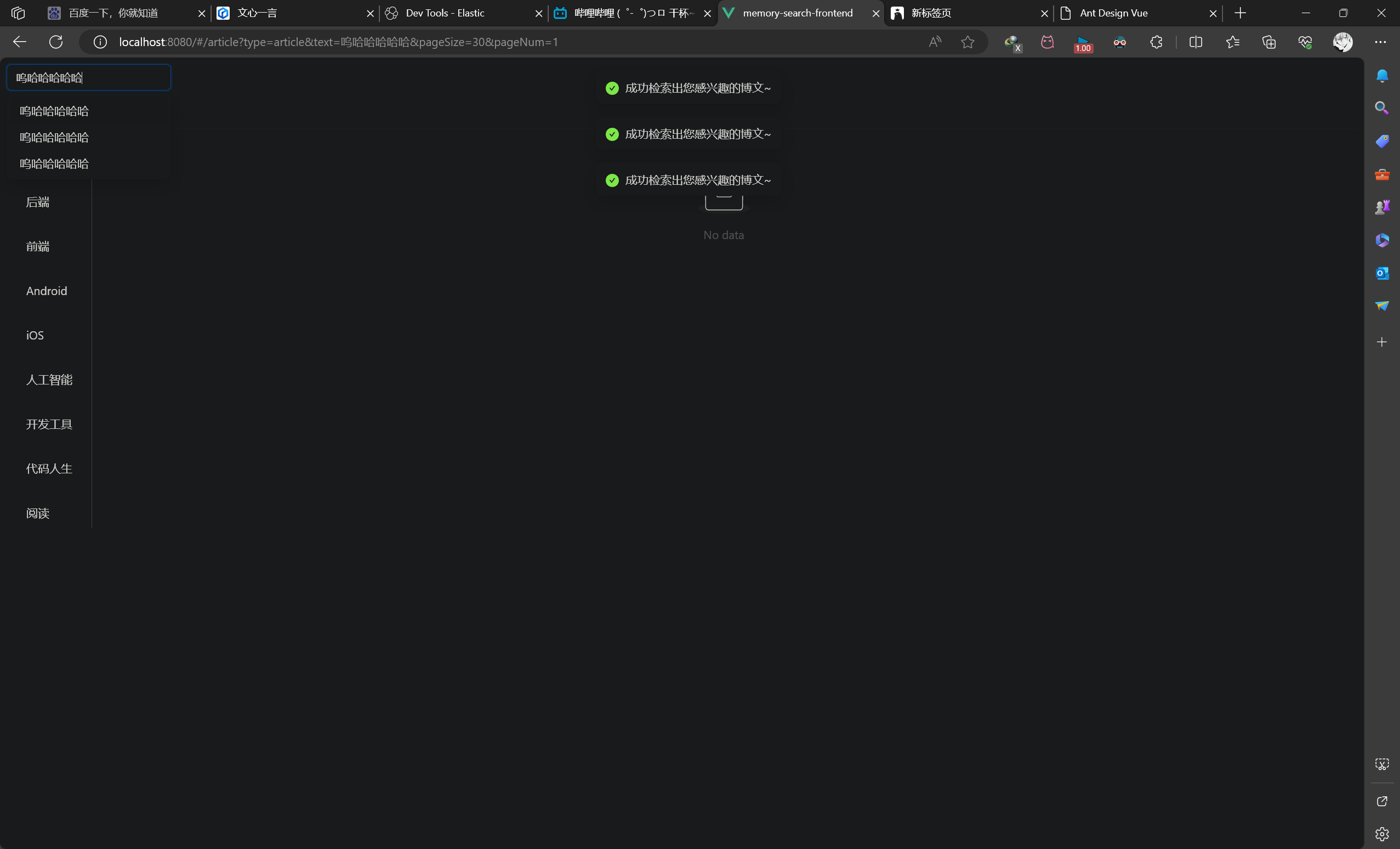
# 前端
# 🍛 热门话题分析
在热门话题分析功能中,Elasticsearch 的聚合搜索发挥了关键作用。聚合搜索允许用户对数据进行
分组、统计和分析,以发现数据中的趋势和模式。对于热门话题分析,Elasticsearch 可以按照特定字段(如消息内容或关键词)对文档进行聚合,统计每个话题的出现次数和频率。通过使用 Elasticsearch 的聚合功能,用户可以轻松地识别出最热门的话题,并对其进行进一步的分析。Elasticsearch 提供了多种聚合类型,如
术语聚合(Terms Aggregation),用于按字段值对文档进行分组;过滤器聚合(Filter Aggregation),用于对满足特定条件的文档进行分组;以及日期直方图聚合(Date Histogram Aggregation),用于按时间间隔对文档进行分组等。
🍚 推荐阅读:Aggregations | Elasticsearch Guide 7.17] | Elastic (opens new window)
# DSL 实现
# 新增索引映射
PUT /message_index
{
"mappings": {
"properties":{
"message": {
"analyzer": "ik_smart",
"term_vector": "with_positions_offsets",
"boost": 8,
"type": "text",
"fielddata":"true"
}
}
}
}
# 添加文档数据
POST message_index/_doc/1
{
"message":"美女"
}
POST message_index/_doc/2
{
"message":"沙滩上的美女"
}
POST message_index/_doc/3
{
"message":"女生 教室 阳光"
}
POST message_index/_doc/4
{
"message":"睡觉 夜晚"
}
POST message_index/_doc/5
{
"message":"戏水的女子"
}
# 查询索引数据
GET message_index/_search
{
"query":{
"match_all": {}
}
}
# 聚合查询
POST message_index/_search
{
"size": 0,
"aggs": {
"search_terms": {
"terms": {
"field": "message",
"size": 10
}
}
}
}
# 多字段聚合查询
POST article_v4/_search
{
"size" : 0,
"aggs" : {
"first-aggr" : {
"terms" : {
"size" : 10,
"field" : "description.keyword"
}
},
"scecond-aggr" : {
"terms" : {
"size" : 10,
"field" : "title.keyword"
}
}
}
}
这个过程是一个 Elasticsearch 的查询请求,用于在 article_v4 索引中执行聚合(aggregation)操作。以下是该过程的详细描述:
POST article_v4/_search:这是一个 HTTP POST 请求,发送到 article_v4 索引的_search 端点。Elasticsearch 会响应这个请求,返回与查询匹配的文档。
"size" : 0:在这个查询中,size 参数被设置为 0。这意味着 Elasticsearch 不需要返回任何与查询匹配的文档。通常,size 参数用于限制返回的文档数量,但在这里,它被设置为 0,因为请求者只对聚合结果感兴趣。
"aggs" : { ... }:这是聚合部分的开始。aggs 是 aggregations 的缩写,用于定义要在查询中执行的聚合操作。
"first-aggr" : { ... }:这是第一个聚合的名称,叫做 first-aggr。你可以给聚合命名,以便在结果中识别它们。
在这个聚合中,使用了 terms 聚合类型。terms 聚合用于返回在指定字段中出现的唯一值(或术语)及其文档计数。
"size" : 10:这个参数限制了返回的术语数量。在这个例子中,first-aggr 将只返回 description.keyword 字段中出现次数最多的前 10 个术语。
"field" : "description.keyword":这指定了要进行聚合的字段。在这个例子中,聚合是基于 description.keyword 字段的。
"scecond-aggr" : { ... }:这是第二个聚合的名称,但请注意,这里似乎有一个拼写错误。正确的名称应该是 second-aggr,而不是 scecond-aggr。 这个聚合与 first-aggr 类似,也是使用 terms 聚合类型,并限制了返回的术语数量为 10。 区别在于它是对 title.keyword 字段进行聚合,而不是 description.keyword 字段。 综上所述,这个 Elasticsearch 查询请求将在 article_v4 索引中执行两个聚合操作:一个基于 description.keyword 字段,另一个基于 title.keyword 字段。这两个聚合都会返回各自字段中出现次数最多的前 10 个术语及其文档计数。然而,请注意更正 scecond-aggr 的拼写错误,以确保查询能够正确执行。
聚合查询执行结果:
该查询是一个针对 Elasticsearch 的聚合查询,用于分析 message_index 索引中 message 字段的热门话题。查询中使用了 terms 聚合,该聚合能够按照 message 字段的不同值(即不同的话题)对文档进行分组,并统计每个话题的
出现频率。查询结果中,"size": 0 表示不返回具体的文档内容,仅返回
聚合结果。"aggs": {"search_terms": {...}} 部分定义了聚合操作,其中"search_terms"是聚合的名称,而内部的"terms"定义了具体的聚合类型和操作。执行该查询后,Elasticsearch 会返回一个聚合结果,其中包含按 message 字段值分组的话题及其对应的
文档数量(即热度)。由于设置了"size": 10,所以结果中只会包含热度最高的前 10 个话题。综上所述,该聚合查询成功统计出了 message_index 索引下的
热门话题,并按照热度进行了排序。这种分析结果可以帮助用户快速了解当前最热门、讨论最多的话题,从而做出相应的决策或采取进一步的行动。
# Java API 实现
# 添加聚合条件
// 添加聚合条件
TermsAggregationBuilder search_terms = AggregationBuilders.terms("search_terms")
.field("message").size(10);
// 创建查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withAggregations(search_terms) // 添加聚合条件
.build();
定义了一个名为 getPopularTopic 的方法,用于从 Elasticsearch 中检索并分析热门话题。该方法利用 Elasticsearch 的聚合功能,特别是 Terms 聚合,对 message 字段进行聚合,以识别出现频率最高的 10 个话题
通过 AggregationBuilders 创建了一个 Terms 聚合查询,该查询将按 message 字段对文档进行分组,并返回前 10 个最频繁出现的值(话题)。然后,使用 NativeSearchQueryBuilder 构建了一个包含此聚合的查询:
# 执行聚合搜索
// 执行搜索,获取搜索结果
SearchHits<MessageTest> searchHits = elasticsearchRestTemplate.search(searchQuery, MessageTest.class);
// 获取Spring Data Elasticsearch的聚合结果
ElasticsearchAggregations searchHitsAggregations = (ElasticsearchAggregations) searchHits.getAggregations();
Aggregations aggregations = Objects.requireNonNull(searchHitsAggregations).aggregations();
接着,通过 elasticsearchRestTemplate 执行此查询,并获取 SearchHits 结果。这些结果包含了与查询匹配的文档以及聚合结果。
代码进一步从 SearchHits 中提取了聚合信息,并遍历了所有的聚合结果。
# 获取聚合结果
// 聚合搜索结果
List<Aggregation> aggregationList = aggregations.asList();
// 存储热门话题
ArrayList<TopicEsDTO> popularTopicList = new ArrayList<>();
for (Aggregation aggregation : aggregationList) {
System.out.println(aggregation);
aggregation.getName();
// 检查聚合类型并转换为相应的聚合对象
if (aggregation instanceof Terms) {
Terms termsAggregation = (Terms) aggregation;
// 获取buckets
List<? extends Terms.Bucket> buckets = termsAggregation.getBuckets();
// 遍历buckets
for (Terms.Bucket bucket : buckets) {
TopicEsDTO topicEsDTO = new TopicEsDTO();
String keyAsString = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
topicEsDTO.setPopularTopic(keyAsString);
topicEsDTO.setDocCount(docCount);
boolean add = popularTopicList.add(topicEsDTO);
// 如果需要,还可以获取其他bucket信息,如聚合的子聚合等
}
}
}
对于每个聚合结果,它检查是否是 Terms 类型的聚合,如果是,则提取出聚合的桶(buckets),每个桶代表一个话题及其出现次数。
对于每个桶,代码创建了一个 TopicEsDTO 对象,并将桶的键(即话题)和文档计数(即话题的出现次数)设置到该对象中。然后,将这些对象添加到 popularTopicList 列表中。
# 返回聚合结果
// 获取聚合结果
return popularTopicList;
- 最后,该方法返回了包含热门话题及其出现次数的 popularTopicList 列表。通过这个过程,用户可以获得当前最热门的话题及其流行度。
# 🥣 热门搜索统计
- 利用 Redis 的 ZSet 数据结构实现
热门搜索统计,通过实时更新搜索词及其次数并保持自动排序,Redis 提供高性能内存存储和原子操作,确保快速处理大量搜索请求,并实时展示搜索热度趋势。
🍚 推荐阅读: RedisTemplate.opsForZSet()用法简介并举例-CSDN 博客 (opens new window)
# Redis 基本数据结构
Redis 的基本数据类型主要有五种,包括:
String(字符串):这是 Redis 最基本的数据类型,可以存储任何类型的数据,包括字符串、数字和二进制数据等。一个 Redis 中字符串 value 最多可以是 512M。
Hash(哈希):Redis 的 Hash 是一个键值对集合,是一个 String 类型的 field 和 value 的映射表,特别适合用于存储对象。可以理解为一个小的 key-value 存储,方便数据的存储和读取。
List(列表):Redis 的 List 是一种有序的字符串列表,可以在头部或尾部添加元素。它可以实现队列和栈的数据结构,常用于消息队列,并且可以避免消息丢失等问题。
Set(集合):Redis 的 Set 是一组无序、唯一的字符串集合,可以对集合进行并、交、差等集合运算。它还可以实现去重等功能。
Sorted Set(有序集合):Redis 的 Sorted Set 和 Set 一样都是 string 类型元素的集合,且不允许重复的成员。但 Sorted Set 中的每个元素都会关联一个 double 类型的分数,Redis 正是通过分数来为集合中的成员进行从小到大的排序。 这些数据类型为 Redis 提供了丰富的功能和应用场景,使得 Redis 能够作为数据库、缓存、消息中间件等多种角色存在于系统中。
# Redis 实现热门搜索统计
# value 使用 String 数据结构
- 首先,通过 setHotWords 方法,将用户输入的搜索词条存储到 Redis 中,并更新搜索次数。每个搜索词条作为 key 值,对应的 value 值为一个包含用户 id、搜索次数和搜索时间的字符串。这样可以方便地根据搜索词条查询相关信息:
@Override
public List<Message> setHotWords(String suggestTextStr, HttpServletRequest request) {
// 获取当前登录用户
User loginUser = (User) request.getSession().getAttribute(USER_LOGIN_STATE);
Long userId = loginUser.getId();
if (com.qcloud.cos.utils.StringUtils.isNullOrEmpty(suggestTextStr)) {
return null;
}
// 按空格,获取每个搜索词
String[] suggestTexts = suggestTextStr.split(" ");
ArrayList<Message> messageList = new ArrayList<>();
for (String suggestText : suggestTexts) {
// 从 Redis 中获取原始消息
String messageStr = redisTemplate.opsForValue().get(String.format(REDIS_KEY_TEMPLATE, suggestText));
Message message = null;
Gson gson = new Gson();
// 检查原始消息是否为空
if (ObjectUtils.isNotEmpty(messageStr)) {
// 获取原始消息中的 searchNum 字段并增加 1
Message mes = gson.fromJson(messageStr, Message.class);
Integer searchNum = mes.getSearchNum();
Integer newSearchNum = searchNum + 1;
// 创建新的 Message 对象
message = new Message(MESSAGE_ID, suggestText, newSearchNum);
} else {
// 创建新的 Message 对象
message = new Message(MESSAGE_ID, suggestText, SEARCH_NUM);
}
boolean add = messageList.add(message);
ThrowUtils.throwIf(!add, ErrorCode.OPERATION_ERROR, "记录热搜词失败");
// 将新的 Message 对象存回 Redis 中,设置过期时间为 30 天
redisTemplate.opsForValue()
.set(String.format(REDIS_KEY_TEMPLATE, suggestText), gson.toJson(message), 30, TimeUnit.DAYS);
}
return messageList;
}
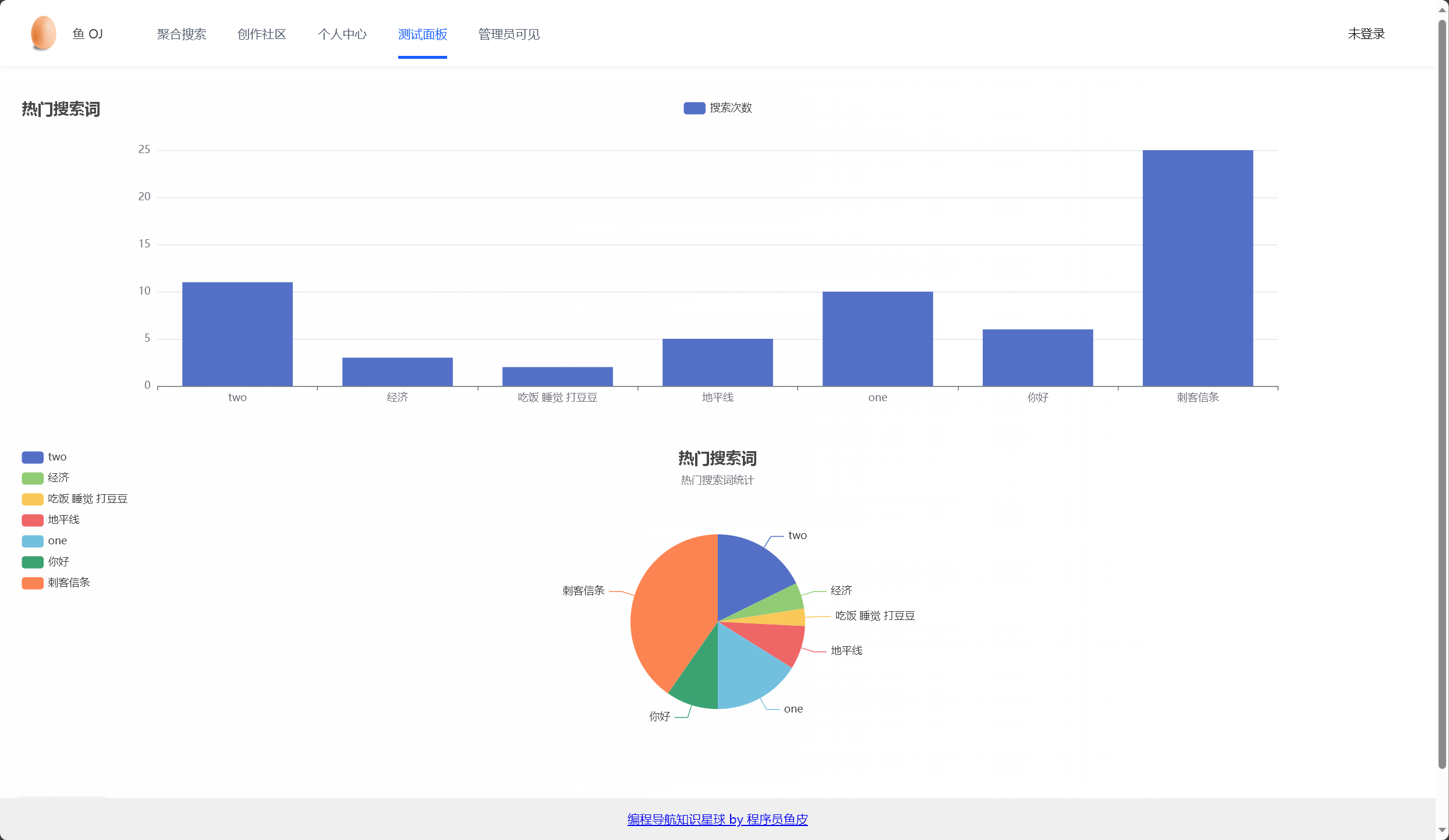
- 然后,通过 getHotWords 方法,获取所有搜索词条及其相关信息,并将它们添加到一个列表中返回。这个方法使用了 Redis 的 keys 命令来获取所有以"search:hot"开头的 key,然后遍历这些 key,从 Redis 中获取对应的 value 值,并将其转换为 Message 对象,最后将这些 Message 对象添加到列表中返回。
@Override
public List<Message> getHotWords() {
Set<String> keys = redisTemplate.keys("search:hot*");
ArrayList<Message> hotWordList = new ArrayList<>();
Gson gson = new Gson();
for (String key : Objects.requireNonNull(keys)) {
String messageStr = redisTemplate.opsForValue().get(key);
Message message = gson.fromJson(messageStr, Message.class);
hotWordList.add(message);
}
System.out.println(keys);
return hotWordList;
}
- 词条相关信息:
@Data
public class Message {
/**
* 搜索词条
*/
private Long userId;
/**
* 搜索词条
*/
private String searchText;
/**
* 搜索词条
*/
private Integer searchNum;
public Message(Long userId, String searchText, Integer searchNum) {
this.userId = userId;
this.searchText = searchText;
this.searchNum = searchNum;
}
public Message(Long userId, Integer searchNum) {
this.userId = userId;
this.searchNum = searchNum;
}
}
- 需要注意的是,由于 value 值中的 searchNum 字段用于按序查询前十条数据
较为困难,因此可以考虑使用其他数据结构或算法来实现这个需求。
# value 使用 ZSet 数据结构
# 保存搜索词
- 用户输入搜索词条,通过 setHotWords 方法将搜索词条存储到 Redis 中,并更新搜索次数。每个搜索词条作为 key 值,对应的 value 值为一个包含用户 id、搜索次数和搜索时间的字符串。这样可以方便地根据搜索词条查询相关信息。
// 获取当前登录用户
User loginUser = (User) request.getSession().getAttribute(USER_LOGIN_STATE);
Long userId = loginUser.getId();
if (com.qcloud.cos.utils.StringUtils.isNullOrEmpty(searchTextStr)) {
return null;
}
// 按空格,获取每个搜索词
String[] searchTexts = searchTextStr.split(" ");
- 在存储搜索词条时,首先获取当前登录用户的 ID,然后按空格分割搜索词条,得到每个搜索词。对于每个搜索词,从 Redis 中获取原始消息,如果原始消息不为空,则存入 Redis 并更新 score 分数;否则,将新的 Message 对象存回 Redis 中。
// 创建新的 Message 对象
MessageDTO messageDTO = new MessageDTO(userId, searchText);
Gson gson = new Gson();
// 原始消息不为空
if (size > 0) {
// 存入 Redis,更新 score
redisTemplate.opsForZSet()
.incrementScore(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), gson.toJson(messageDTO), 1);
} else {
// 将新的 Message 对象存回 Redis 中
redisTemplate.opsForZSet()
.add(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), gson.toJson(messageDTO), SEARCH_NUM);
}
boolean add = messageDTOList.add(messageDTO);
ThrowUtils.throwIf(!add, ErrorCode.OPERATION_ERROR, "记录热搜词失败");
- 同步保存搜索词到 Elasticsearch 中,生成唯一 ID,并将搜索词的信息保存到 Elasticsearch 中。
// 同步保存搜索词到 Elasticsearch 中
MessageEsDTO messageEsDTO = new MessageEsDTO();
BeanUtils.copyProperties(messageDTO, messageEsDTO);
// 生成唯一 id
String uniqueId = getUniqueId(searchText);
messageEsDTO.setId(uniqueId);
MessageEsDTO save = elasticsearchRestTemplate.save(messageEsDTO);
ThrowUtils.throwIf(ObjectUtils.isEmpty(save), ErrorCode.OPERATION_ERROR, "记录热搜词失败");
# 生成唯一 id
- 此业务流程的核心目的是为给定的搜索词生成一个唯一的 ID。此 ID 基于搜索词的 MD5 哈希值生成,确保每个不同的搜索词都会产生一个独特的 ID。
/**
* 生成唯一 id
*
* @param searchText 搜索词
* @return 唯一 id
*/
private String getUniqueId(String searchText) {
try {
// 获取MD5信息摘要实例
MessageDigest md = MessageDigest.getInstance("MD5");
// 计算搜索词的MD5哈希值
byte[] hashBytes = md.digest(searchText.getBytes());
StringBuilder hexString = new StringBuilder();
// 将字节数组转换为十六进制字符串
for (byte b : hashBytes) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) hexString.append('0');
hexString.append(hex);
}
// 生成最终的唯一ID,使用uniqueId作为文档的ID
return hexString.toString();
} catch (NoSuchAlgorithmException e) {
// 处理异常
throw new RuntimeException(e);
}
}
此业务流程通过 MD5 哈希算法为给定的搜索词生成一个唯一的 ID:
用户提供的搜索词经过 MD5 哈希计算后得到一个字节数组,再将该数组转换为十六进制字符串。由于 MD5 的特性,不同的搜索词会产生不同的哈希值,从而确保每个 ID 的唯一性。
如果在过程中遇到不支持 MD5 算法的情况,会抛出异常。这种方法为需要唯一标识符的场景(如文档、数据库记录等)提供了一种简便有效的解决方案。
# 查找热门搜索词
- 该方法的核心功能是从 Redis 的有序集合中检索前十条最热门的搜索词条,并将其转换为 MessageVO 对象的列表:
@Override
public List<MessageVO> getHotWords() {
// 根据 score 获取前十条搜索词条
Set<String> messageSet = redisTemplate.opsForZSet()
.reverseRange(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), 0, 9);
ArrayList<MessageVO> messageVOList = new ArrayList<>();
Gson gson = new Gson();
for (String messageStr : Objects.requireNonNull(messageSet)) {
MessageDTO messageDTO = gson.fromJson(messageStr, MessageDTO.class);
// 查询搜索词条对应 score
Double score = redisTemplate.opsForZSet()
.score(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), messageStr);
// 封装 messageVO
MessageVO messageVO = new MessageVO();
BeanUtils.copyProperties(messageDTO, messageVO);
messageVO.setSearchNum(score);
boolean add = messageVOList.add(messageVO);
ThrowUtils.throwIf(!add, ErrorCode.OPERATION_ERROR, "获取热搜词失败");
}
return messageVOList;
}
首先利用 reverseRange 方法从 Redis 中快速获取按分数降序排列的搜索词条字符串集合。接着,通过 Gson 库的反序列化功能,将这些字符串转换成 MessageDTO 对象。
然后,为每个 MessageDTO 对象获取其对应的分数(即搜索热度),并将该分数设置为 MessageVO 对象的 searchNum 属性。在将 MessageVO 对象添加到结果列表时,确保列表中的唯一性,以避免重复数据。
最后,返回包含转换后热门词条的 MessageVO 列表,为用户提供实时、高效的热门搜索词数据。
词条相关信息:
@Data
public class MessageDTO {
/**
* 用户
*/
private Long userId;
/**
* 搜索词条
*/
private String searchText;
public MessageDTO(Long userId, String searchText) {
this.userId = userId;
this.searchText = searchText;
}
}
/**
* 搜索词 ES 包装类
*
* @author memory
**/
@Document(indexName = "search_text")
@Data
public class MessageEsDTO {
/**
* 文章id
*/
@Id
private String id;
/**
* 用户
*/
private Long userId;
/**
* 搜索词条
*/
private String searchText;
}