 缓存性能调优
缓存性能调优
温馨提示
在这里,通过深入学习代码实现,您将系统地探索如何实现缓存性能调优功能的具体代码细节。
# 🥩 基本数据结构类型
Redis 的基本数据类型主要有五种,包括:
String(字符串):这是 Redis 最基本的数据类型,可以存储任何类型的数据,包括字符串、数字和二进制数据等。一个 Redis 中字符串 value 最多可以是 512M。
Hash(哈希):Redis 的 Hash 是一个键值对集合,是一个 String 类型的 field 和 value 的映射表,特别适合用于存储对象。可以理解为一个小的 key-value 存储,方便数据的存储和读取。
List(列表):Redis 的 List 是一种有序的字符串列表,可以在头部或尾部添加元素。它可以实现队列和栈的数据结构,常用于消息队列,并且可以避免消息丢失等问题。
Set(集合):Redis 的 Set 是一组无序、唯一的字符串集合,可以对集合进行并、交、差等集合运算。它还可以实现去重等功能。
Sorted Set(有序集合):Redis 的 Sorted Set 和 Set 一样都是 string 类型元素的集合,且不允许重复的成员。但 Sorted Set 中的每个元素都会关联一个 double 类型的分数,Redis 正是通过分数来为集合中的成员进行从小到大的排序。
这些数据类型为 Redis 提供了丰富的功能和应用场景,使得 Redis 能够作为数据库、缓存、消息中间件等多种角色存在于系统中。
# 🥣 使用 Zset 实现热门搜索统计(排行榜)
# value 使用 String 数据结构
- 首先,通过 setHotWords 方法,将用户输入的搜索词条存储到 Redis 中,并更新搜索次数。每个搜索词条作为 key 值,对应的 value 值为一个包含用户 id、搜索次数和搜索时间的字符串。这样可以方便地根据搜索词条查询相关信息:
@Override
public List<Message> setHotWords(String suggestTextStr, HttpServletRequest request) {
// 获取当前登录用户
User loginUser = (User) request.getSession().getAttribute(USER_LOGIN_STATE);
Long userId = loginUser.getId();
if (com.qcloud.cos.utils.StringUtils.isNullOrEmpty(suggestTextStr)) {
return null;
}
// 按空格,获取每个搜索词
String[] suggestTexts = suggestTextStr.split(" ");
ArrayList<Message> messageList = new ArrayList<>();
for (String suggestText : suggestTexts) {
// 从 Redis 中获取原始消息
String messageStr = redisTemplate.opsForValue().get(String.format(REDIS_KEY_TEMPLATE, suggestText));
Message message = null;
Gson gson = new Gson();
// 检查原始消息是否为空
if (ObjectUtils.isNotEmpty(messageStr)) {
// 获取原始消息中的 searchNum 字段并增加 1
Message mes = gson.fromJson(messageStr, Message.class);
Integer searchNum = mes.getSearchNum();
Integer newSearchNum = searchNum + 1;
// 创建新的 Message 对象
message = new Message(MESSAGE_ID, suggestText, newSearchNum);
} else {
// 创建新的 Message 对象
message = new Message(MESSAGE_ID, suggestText, SEARCH_NUM);
}
boolean add = messageList.add(message);
ThrowUtils.throwIf(!add, ErrorCode.OPERATION_ERROR, "记录热搜词失败");
// 将新的 Message 对象存回 Redis 中,设置过期时间为 30 天
redisTemplate.opsForValue()
.set(String.format(REDIS_KEY_TEMPLATE, suggestText), gson.toJson(message), 30, TimeUnit.DAYS);
}
return messageList;
}
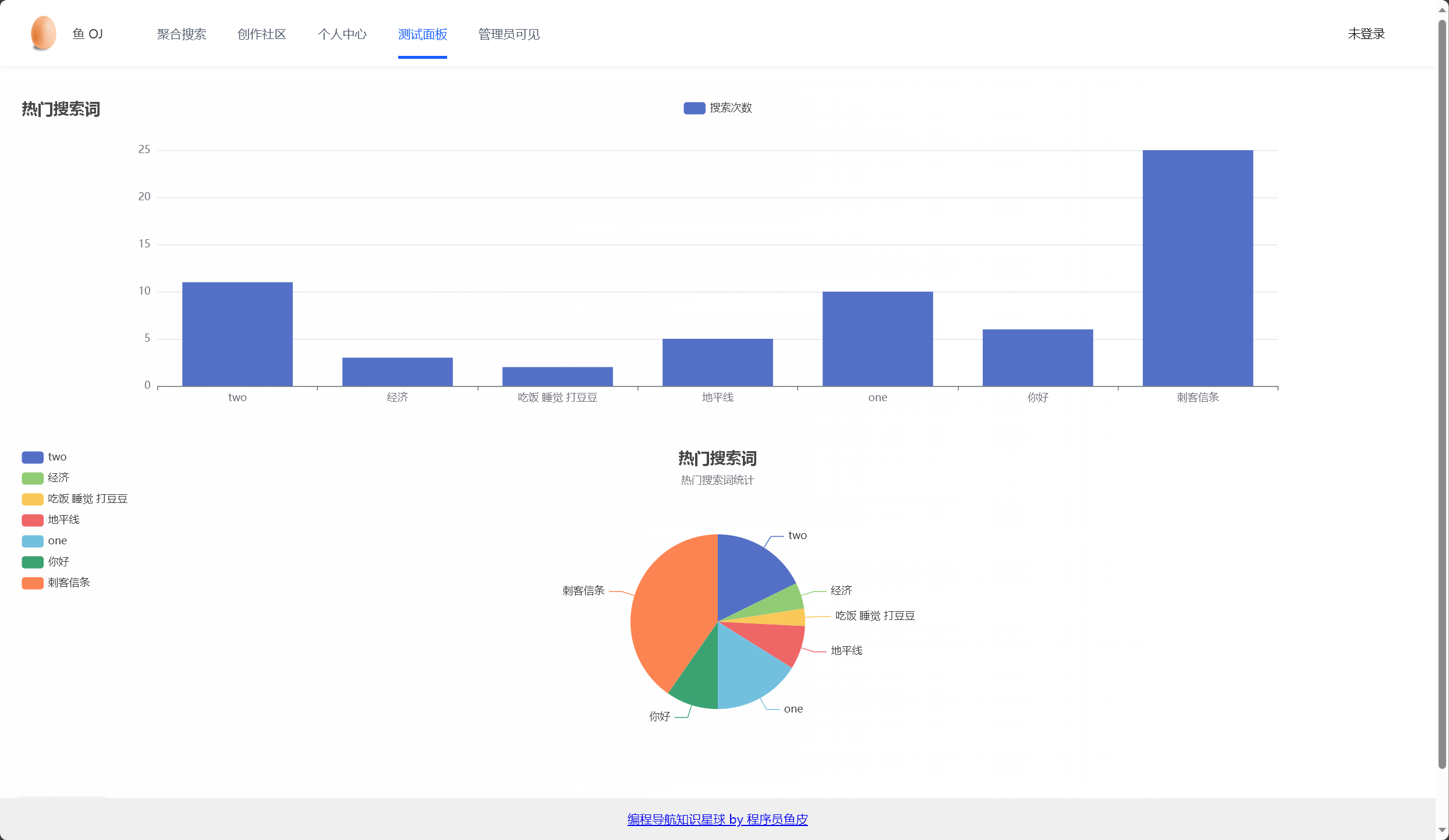
- 然后,通过 getHotWords 方法,获取所有搜索词条及其相关信息,并将它们添加到一个列表中返回。这个方法使用了 Redis 的 keys 命令来获取所有以"search:hot"开头的 key,然后遍历这些 key,从 Redis 中获取对应的 value 值,并将其转换为 Message 对象,最后将这些 Message 对象添加到列表中返回。
@Override
public List<Message> getHotWords() {
Set<String> keys = redisTemplate.keys("search:hot*");
ArrayList<Message> hotWordList = new ArrayList<>();
Gson gson = new Gson();
for (String key : Objects.requireNonNull(keys)) {
String messageStr = redisTemplate.opsForValue().get(key);
Message message = gson.fromJson(messageStr, Message.class);
hotWordList.add(message);
}
System.out.println(keys);
return hotWordList;
}
- 词条相关信息:
@Data
public class Message {
/**
* 搜索词条
*/
private Long userId;
/**
* 搜索词条
*/
private String searchText;
/**
* 搜索词条
*/
private Integer searchNum;
public Message(Long userId, String searchText, Integer searchNum) {
this.userId = userId;
this.searchText = searchText;
this.searchNum = searchNum;
}
public Message(Long userId, Integer searchNum) {
this.userId = userId;
this.searchNum = searchNum;
}
}
- 需要注意的是,由于 value 值中的 searchNum 字段用于按序查询前十条数据
较为困难,因此可以考虑使用其他数据结构或算法来实现这个需求。
# value 使用 ZSet 数据结构
# 保存搜索词
- 用户输入搜索词条,通过 setHotWords 方法将搜索词条存储到 Redis 中,并更新搜索次数。每个搜索词条作为 key 值,对应的 value 值为一个包含用户 id、搜索次数和搜索时间的字符串。这样可以方便地根据搜索词条查询相关信息。
// 获取当前登录用户
User loginUser = (User) request.getSession().getAttribute(USER_LOGIN_STATE);
Long userId = loginUser.getId();
if (com.qcloud.cos.utils.StringUtils.isNullOrEmpty(searchTextStr)) {
return null;
}
// 按空格,获取每个搜索词
String[] searchTexts = searchTextStr.split(" ");
- 在存储搜索词条时,首先获取当前登录用户的 ID,然后按空格分割搜索词条,得到每个搜索词。对于每个搜索词,从 Redis 中获取原始消息,如果原始消息不为空,则存入 Redis 并更新 score 分数;否则,将新的 Message 对象存回 Redis 中。
// 创建新的 Message 对象
MessageDTO messageDTO = new MessageDTO(userId, searchText);
Gson gson = new Gson();
// 原始消息不为空
if (size > 0) {
// 存入 Redis,更新 score
redisTemplate.opsForZSet()
.incrementScore(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), gson.toJson(messageDTO), 1);
} else {
// 将新的 Message 对象存回 Redis 中
redisTemplate.opsForZSet()
.add(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), gson.toJson(messageDTO), SEARCH_NUM);
}
boolean add = messageDTOList.add(messageDTO);
ThrowUtils.throwIf(!add, ErrorCode.OPERATION_ERROR, "记录热搜词失败");
- 同步保存搜索词到 Elasticsearch 中,生成唯一 ID,并将搜索词的信息保存到 Elasticsearch 中。
// 同步保存搜索词到 Elasticsearch 中
MessageEsDTO messageEsDTO = new MessageEsDTO();
BeanUtils.copyProperties(messageDTO, messageEsDTO);
// 生成唯一 id
String uniqueId = getUniqueId(searchText);
messageEsDTO.setId(uniqueId);
MessageEsDTO save = elasticsearchRestTemplate.save(messageEsDTO);
ThrowUtils.throwIf(ObjectUtils.isEmpty(save), ErrorCode.OPERATION_ERROR, "记录热搜词失败");
# 生成唯一 id
- 此业务流程的核心目的是为给定的搜索词生成一个唯一的 ID。此 ID 基于搜索词的 MD5 哈希值生成,确保每个不同的搜索词都会产生一个独特的 ID。
/**
* 生成唯一 id
*
* @param searchText 搜索词
* @return 唯一 id
*/
private String getUniqueId(String searchText) {
try {
// 获取MD5信息摘要实例
MessageDigest md = MessageDigest.getInstance("MD5");
// 计算搜索词的MD5哈希值
byte[] hashBytes = md.digest(searchText.getBytes());
StringBuilder hexString = new StringBuilder();
// 将字节数组转换为十六进制字符串
for (byte b : hashBytes) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) hexString.append('0');
hexString.append(hex);
}
// 生成最终的唯一ID,使用uniqueId作为文档的ID
return hexString.toString();
} catch (NoSuchAlgorithmException e) {
// 处理异常
throw new RuntimeException(e);
}
}
此业务流程通过 MD5 哈希算法为给定的搜索词生成一个唯一的 ID:
用户提供的搜索词经过 MD5 哈希计算后得到一个字节数组,再将该数组转换为十六进制字符串。由于 MD5 的特性,不同的搜索词会产生不同的哈希值,从而确保每个 ID 的唯一性。
如果在过程中遇到不支持 MD5 算法的情况,会抛出异常。这种方法为需要唯一标识符的场景(如文档、数据库记录等)提供了一种简便有效的解决方案。
# 查找热门搜索词
- 该方法的核心功能是从 Redis 的有序集合中检索前十条最热门的搜索词条,并将其转换为 MessageVO 对象的列表:
@Override
public List<MessageVO> getHotWords() {
// 根据 score 获取前十条搜索词条
Set<String> messageSet = redisTemplate.opsForZSet()
.reverseRange(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), 0, 9);
ArrayList<MessageVO> messageVOList = new ArrayList<>();
Gson gson = new Gson();
for (String messageStr : Objects.requireNonNull(messageSet)) {
MessageDTO messageDTO = gson.fromJson(messageStr, MessageDTO.class);
// 查询搜索词条对应 score
Double score = redisTemplate.opsForZSet()
.score(String.format(SEARCH_TEXT_KEY, SEARCH_TIME), messageStr);
// 封装 messageVO
MessageVO messageVO = new MessageVO();
BeanUtils.copyProperties(messageDTO, messageVO);
messageVO.setSearchNum(score);
boolean add = messageVOList.add(messageVO);
ThrowUtils.throwIf(!add, ErrorCode.OPERATION_ERROR, "获取热搜词失败");
}
return messageVOList;
}
首先利用 reverseRange 方法从 Redis 中快速获取按分数降序排列的搜索词条字符串集合。接着,通过 Gson 库的反序列化功能,将这些字符串转换成 MessageDTO 对象。
然后,为每个 MessageDTO 对象获取其对应的分数(即搜索热度),并将该分数设置为 MessageVO 对象的 searchNum 属性。在将 MessageVO 对象添加到结果列表时,确保列表中的唯一性,以避免重复数据。
最后,返回包含转换后热门词条的 MessageVO 列表,为用户提供实时、高效的热门搜索词数据。
词条相关信息:
@Data
public class MessageDTO {
/**
* 用户
*/
private Long userId;
/**
* 搜索词条
*/
private String searchText;
public MessageDTO(Long userId, String searchText) {
this.userId = userId;
this.searchText = searchText;
}
}
/**
* 搜索词 ES 包装类
*
* @author memory
**/
@Document(indexName = "search_text")
@Data
public class MessageEsDTO {
/**
* 文章id
*/
@Id
private String id;
/**
* 用户
*/
private Long userId;
/**
* 搜索词条
*/
private String searchText;
}
# 🥣 保留近期搜索的图片数据
- 使用给定的搜索文本构造 Bing 图片搜索的 URL,并对搜索文本进行 URL 编码,确保其在 URL 中的正确性,再使用 Jsoup 库发送 HTTP 请求到 Bing 服务器,获取搜索结果页面的 HTML 内:
long current = currentPage - 1;
if (searchText == null) {
return null;
}
// 非空条件,转码
if (StringUtils.isNotBlank(searchText)) {
try {
searchText = URLEncoder.encode(searchText, "UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
}
String url = String.format("https://cn.bing.com/images/search?q=%s&first=%s", searchText, current);
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
throw new RuntimeException(e);
}
用 Jsoup 解析 HTML,定位到包含图片信息的元素。这里假设图片信息包含在类名为.iuscp.isv 的元素中。遍历这些元素,提取每张图片的 URL 和标题,并创建 Picture 对象来保存这些信息
如果提取的图片数量达到预设的最大值 CommonConstant.PICTURE_NUMS,则停止提取
Elements elements = doc.select(".iuscp.isv");
List<Picture> pictureList = new ArrayList<>();
Long currentId = BaseContext.getCurrentId();
int count = 0;
for (Element element : elements) {
String mUrl = getImageUrl(element);
String title = getTitle(element);
Picture picture = new Picture(title, mUrl);
// 图片列表
pictureList.add(picture);
count++;
if (count > CommonConstant.PICTURE_NUMS) {
break;
}
}
- 使用 Redis 将提取到的图片信息以 JSON 形式存储起来,键由当前用户 ID 和搜索文本组成,值是图片列表的 JSON 字符串。设置有效期为两小时,以避免缓存数据过期
// Redis 保存搜索图片 两小时
redisTemplate.opsForValue()
.set(String.format(SEARCH_PICTURE_KEY, String.valueOf(currentId)),
GSON.toJson(pictureList), 2, TimeUnit.HOURS);
Page<Picture> picturePage = new Page<>(pageSize, currentPage);
picturePage.setRecords(pictureList);
return picturePage;
- 至此,我们使用 Redis 缓存,根据用户提供的搜索文本,实现了从 Bing 图片搜索 API 获取相关图片信息,将提取的图片信息保存到 Redis 缓存中,并以分页的形式返回给用户