 Elastic Stack 全家桶
Elastic Stack 全家桶
学习目标
在这里,你将系统学习了解Elastic Stack 全家桶的相关内容
我们将以最简单直接的方式为您呈现内容!
# ☕ Elasticsearch 下载安装
🍗 Elasticsearch 下载地址:Elasticsearch - Download (opens new window)
# 🍔 MySQL 与 ES 比较
# 🍣 查询 DSL
在此,我特地整理并记录了在学习 Elasticsearch 过程中所掌握的基础查询 DSL(领域特定语言)语法要点,以便日后回顾与深入应用。
🍗 推荐阅读:
# 复合查询
# 全文搜索
# term 查询
# 聚合查询
# 🍚 其他 DSL
# 新建索引
PUT /article_v2
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
}
}
}
}
这里简单分析下这条新建索引语句:
ES Mapping:
id(可以不放到字段设置里)
ES 中,尽量存放需要用户筛选(搜索)的数据
aliases:别名(为了后续方便数据迁移)
字段类型是 text,这个字段是可被分词的、可模糊查询的;而如果是 keyword,只能完全匹配、精确查询。
analyzer(存储时生效的分词器):用 ik_max_word,拆的更碎、索引更多,更有可能被搜出来
search_analyzer(查询时生效的分词器):用 ik_smart,更偏向于用户想搜的分词
如果想要让 text 类型的分词字段也支持精确查询,可以创建 keyword 类型的子字段:
# 插入文档
PUT /article_v2/_doc/1
{
"title": "明日之后",
"content": "拉扎罗夫,我带你回家!"
}
# 简单的布尔查询
GET article_v2/_search
{
"query": {
"match": { "title": "测试" }
}
}
# 修改索引结构
PUT /article_v3/_mapping
{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
},
"content": {
"type": "binary",
}
}
}
# ☕ Java 操作 ES
# Elasticsearch 官方 API
- 推荐跳转至
官网学习:Introduction | Elasticsearch Java API Client (opens new window),这里不再详述
# Spring Data Elasticsearch
Spring-data 是一个由 Spring 提供的操作数据的框架,包括
Spring-data-redis、Spring-data-mongodb和Spring-data-elasticsearch等模块,分别提供了操作Redis、MongoDB和Elasticsearch等数据存储的一套方法,简化了数据操作的过程。Spring Data Elasticsearch - Reference Documentation (opens new window)
# 实战
- 接下来,我们将深入探讨如何借助
Spring Data Elasticsearch框架简化与 Elasticsearch 的交互,轻松实现Java操作Elasticsearch
注意
在进行实际操作之前,请确保您的本地计算机已正确安装 Elasticsearch,以避免因环境问题导致操作失败。
# 导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
# 开启相关配置
elasticsearch:
uris: http://localhost:9200
username: root
password: 123456
# 索引结构映射
在 model/dto/post 目录下,我们创建了一个新的类
PostESDTO。通过使用@Document注解,我们启用了与post_v1 索引相对应的 Elasticsearch 文档的结构映射。这种映射方式类似于 MySQL 中的
表结构映射,使得该类能够清晰地定义 Elasticsearch 文档的结构:
/**
* 帖子 ES 包装类
*
**/
@Document(indexName = "post_v1")
@Data
public class PostEsDTO implements Serializable {
private static final String DATE_TIME_PATTERN = "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'";
/**
* id
*/
@Id
private Long id;
/**
* 标题
*/
private String title;
/**
* 内容
*/
private String content;
/**
* 标签列表
*/
private List<String> tags;
/**
* 点赞数
*/
private Integer thumbNum;
/**
* 收藏数
*/
private Integer favourNum;
/**
* 创建用户 id
*/
private Long userId;
/**
* 诗人/词人
*/
private String author;
/**
* 创建时间
*/
@Field(index = false, store = true, type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date createTime;
/**
* 更新时间
*/
@Field(index = false, store = true, type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN)
private Date updateTime;
/**
* 是否删除
*/
private Integer isDelete;
private static final long serialVersionUID = 1L;
}
这里的
@Field 注解需要进一步解释:index = false: 表示这个字段不会作为索引的一部分,也就是说它不会被搜索。store = true: 表示该字段的值会被存储,这样可以在搜索结果中获取到它的值。type = FieldType.Date: 指定该字段的类型为日期。format = {}: 通常用于指定日期时间的格式,但在这里它是空的,可能是因为日期时间格式已经在上面通过 pattern 指定了。pattern = DATE_TIME_PATTERN: 指定日期时间的格式,与上面定义的常量一致。
至此,我们已经完成了使用 Java 操作 Elasticsearch 的所有前期准备工作。接下来,我们将进入实际操作演示阶段。在 ES 的操作方式上,我们将其分为两种:接口方式和注解方式。这两种方式各有千秋,我们将分别进行演示,
# 接口方式
- 接口方式更简洁和声明式,提供了一套默认的查询方法,例如 findByXXX、deleteByXXX 等,更接近于传统的 JPA 或 MyBatis 的用法,适用于简单的 CRUD 操作。
# 编写 DAO 层
/**
* 帖子 ES 操作
*/
public interface PostEsDao extends ElasticsearchRepository<PostEsDTO, Long> {
List<PostEsDTO> findByUserId(Long userId);
}
# demo 测试
- 在
PostEsDaoTest类下,编写如下测试 demo 代码:
@Resource
private PostEsDao postEsDao;
// 新增一条文档
@Test
void testAdd() {
PostEsDTO postEsDTO = new PostEsDTO();
postEsDTO.setId(5L);
postEsDTO.setTitle("test");
postEsDTO.setContent("test");
postEsDTO.setTags(Arrays.asList("java", "python"));
postEsDTO.setThumbNum(1);
postEsDTO.setFavourNum(1);
postEsDTO.setUserId(1L);
postEsDTO.setCreateTime(new Date());
postEsDTO.setUpdateTime(new Date());
postEsDTO.setIsDelete(0);
postEsDao.save(postEsDTO);
System.out.println(postEsDTO.getId());
}
// 查找文档
@Test
void testFindById() {
Optional<PostEsDTO> postEsDTO = postEsDao.findById(1L);
System.out.println(postEsDTO);
}
// 查找所有文档
@Test
void testSelect() {
System.out.println(postEsDao.count());
Page<PostEsDTO> PostPage = postEsDao.findAll(
PageRequest.of(0, 5, Sort.by("createTime")));
List<PostEsDTO> postList = PostPage.getContent();
System.out.println(postList);
}
# 注解方式
- 注解方式注解方式需要手动编写与 Elasticsearch 的交互代码,直接控制与 Elasticsearch 的交互,适用于需要对 Elasticsearch 进行复杂操作的情况,例如聚合查询、高亮显示等。
# 注入 Bean
- 使用 @Resource 注解来自动注入一个 ElasticsearchRestTemplate 类型的 Bean:
@Resource
private ElasticsearchRestTemplate elasticsearchRestTemplate;
# 构建布尔查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
# 添加过滤条件
// 过滤 isDelete 字段
boolQueryBuilder.filter(QueryBuilders.termQuery("isDelete", 0));
// 过滤 id 字段
if (id != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("id", id));
}
// 过滤 notId 字段
if (notId != null) {
boolQueryBuilder.mustNot(QueryBuilders.termQuery("id", notId));
}
// 过滤 userId 字段
if (userId != null) {
boolQueryBuilder.filter(QueryBuilders.termQuery("userId", userId));
}
// 过滤 tag 字段
if (CollectionUtils.isNotEmpty(tagList)) {
for (String tag : tagList) {
boolQueryBuilder.filter(QueryBuilders.termQuery("tags", tag));
}
}
# 指定条件匹配
// 按关键词检索 满足其一√
if (StringUtils.isNotBlank(searchText)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("title", searchText));
boolQueryBuilder.should(QueryBuilders.matchQuery("content", searchText));
boolQueryBuilder.should(QueryBuilders.matchQuery("author", searchText));
boolQueryBuilder.minimumShouldMatch(1);
}
// 按标题检索
if (StringUtils.isNotBlank(title)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("title", title));
boolQueryBuilder.minimumShouldMatch(1);
}
// 按作者检索
if (StringUtils.isNotBlank(author)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("author", author));
boolQueryBuilder.minimumShouldMatch(1);
}
// 按内容检索
if (StringUtils.isNotBlank(content)) {
boolQueryBuilder.should(QueryBuilders.matchQuery("content", content));
boolQueryBuilder.minimumShouldMatch(1);
}
# 按指定字段排序
// 按指定字段排序
SortBuilder<?> sortBuilder = SortBuilders.scoreSort();
if (StringUtils.isNotBlank(sortField)) {
sortBuilder = SortBuilders.fieldSort(sortField);
sortBuilder.order(CommonConstant.SORT_ORDER_ASC.equals(sortOrder) ? SortOrder.ASC : SortOrder.DESC);
}
# 分页
// 分页
PageRequest pageRequest = PageRequest.of((int) current, (int) pageSize);
# 构造查询
// 分页
// 构造查询
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withPageable(pageRequest)
.withSorts(sortBuilder).build();
SearchHits<PostEsDTO> searchHits = elasticsearchRestTemplate.search(searchQuery, PostEsDTO.class);
- 使用
ElasticsearchRestTemplate实现复杂查询是一个广泛的主题,涉及到多个高级功能和概念。为了更好地理解这些功能并掌握最佳实践,建议您深入研究 Elasticsearch 的官方文档和相关教程。也可移步至关键词语高亮 (opens new window)、搜索词条建议 (opens new window)、热门搜索统计 (opens new window)和热门话题分析 (opens new window)中学习了解
# 插入数据记录
- 同步保存搜索词到 Elasticsearch 中:
// 同步保存搜索词到 Elasticsearch 中
MessageEsDTO messageEsDTO = new MessageEsDTO();
BeanUtils.copyProperties(messageDTO, messageEsDTO);
// 生成唯一 id
String uniqueId = getUniqueId(searchText);
messageEsDTO.setId(uniqueId);
MessageEsDTO save = elasticsearchRestTemplate.save(messageEsDTO);
ThrowUtils.throwIf(ObjectUtils.isEmpty(save), ErrorCode.OPERATION_ERROR);
# 🍜 分词器
# 内置分词器
空格分词器
- whitespace,按空格分词
POST _analyze
{
"analyzer": "whitespace",
"text": "The quick brown fox."
}
关键词分词器
- 就是不分词,整句话当作一个专业术语
标准分词规则
POST _analyze
{
"tokenizer": "standard",
"filter": [ "lowercase", "asciifolding" ],
"text": "Is this déja vu?"
}
分词器 analyze 和分词规则 tokenizer 有什么区别呢?
在搜索引擎和文本分析领域中,分词器(Analyzer)和分词规则器(Tokenizer)是两个不同的概念。
分词器(Analyzer)是一种将文本转换为单词(Term)序列的工具。它通常包含多个处理步骤,例如词法分析、去除停用词、小写转换、词干提取等。分词器的作用是将原始的文本输入转换为可供索引和搜索的标记流。例如,在 Elasticsearch 中,分词器被用于预处理文本数据并将其存储在倒排索引中,以支持全文搜索。
分词规则器(Tokenizer)是分词器的一个组成部分。它是文本分析的第一个处理步骤,将输入的文本按照指定的规则拆分为单词。常见的分词规则器有基于空格拆分的空格分词器、基于标点符号拆分的标点分词器等。分词规则器负责定义文本拆分的方式,决定了哪些字符会被视为词条的分隔。
总结来说,分词规则器(Tokenizer)是分词器(Analyzer)的组成部分,用于定义文本的拆分方式;而分词器(Analyzer)则包含多个处理步骤,用于将输入文本转换为标记流。
了解到这些分词器
对中文不友好,我们需要下载IK 分词器插件,对中文分词更加友好,内置两种分词器ik_smart
ik_max_word
# IK 分词器(ES 内置插件)
# 下载安装
🍖 安装链接: Releases · medcl/elasticsearch-analysis-ik (github.com) (opens new window)
- 下载完成后,将压缩包解压在本地 Elasticsearch 的
plugins / ik目录下即可
# 修改版本一致
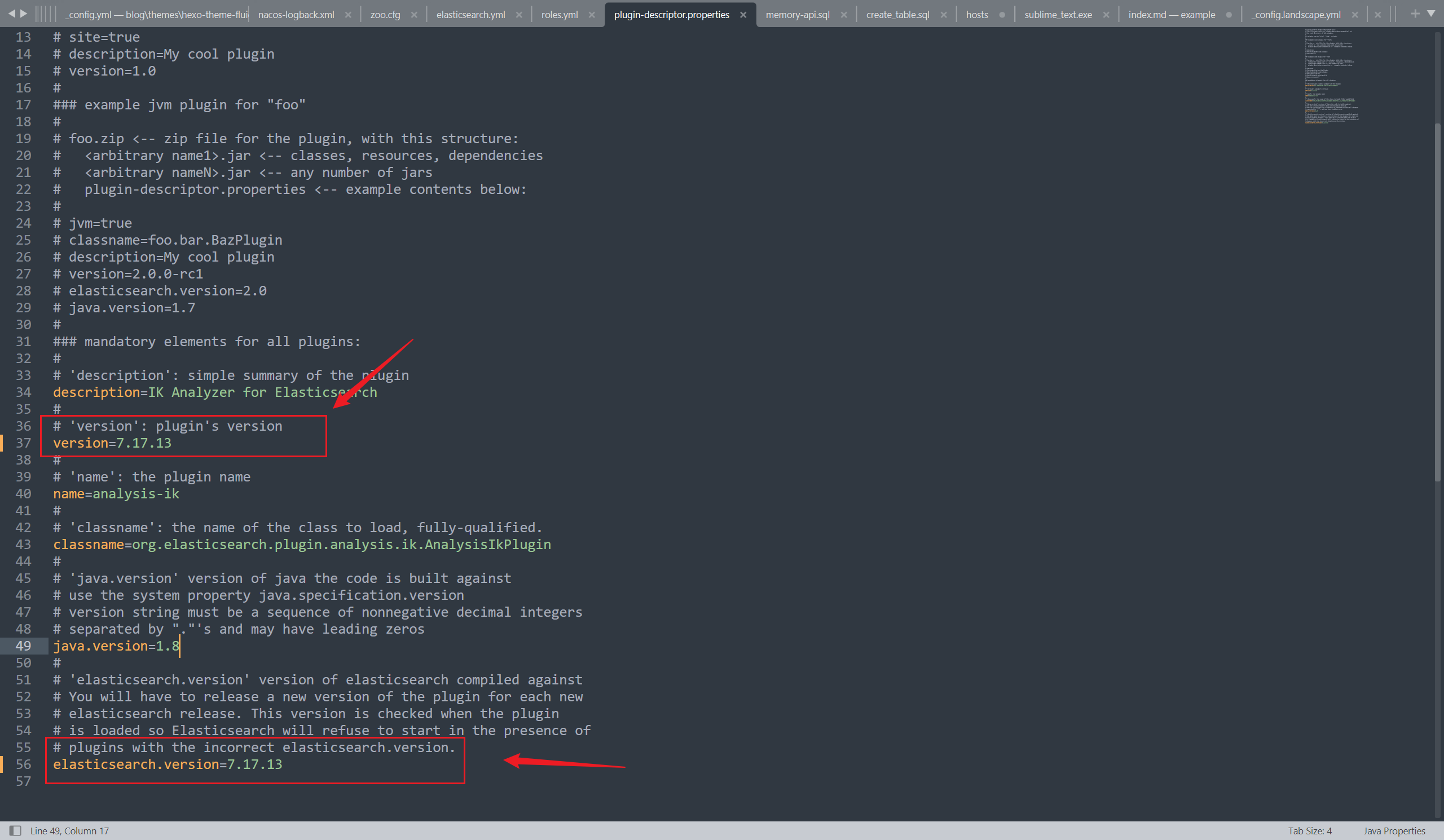
解压完成后,修改 plugins / ik 目录下的 plugin-descriptor.properties 文件,将 ik 版本修改为与 ES 版本一致
注意:我使用的 ES 版本为 7.17.13,而 ik 版本为 7.17.7(2023/09/20 午)
可能会由于版本不兼容,而造成 ES 启动失败,所以需要更改 ik 版本
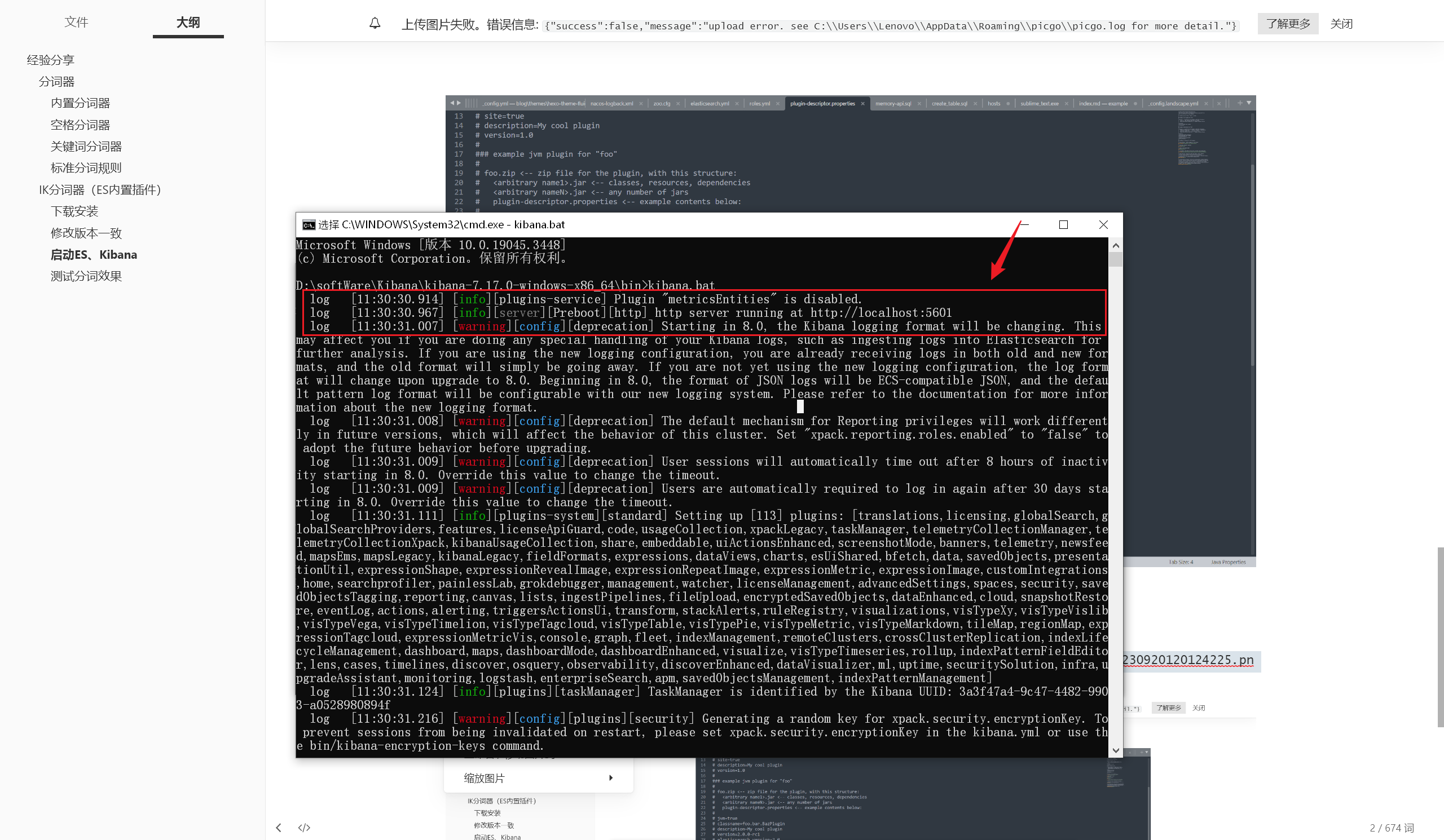
# 启动 ES、Kibana
- 启动成功:
# 测试分词效果
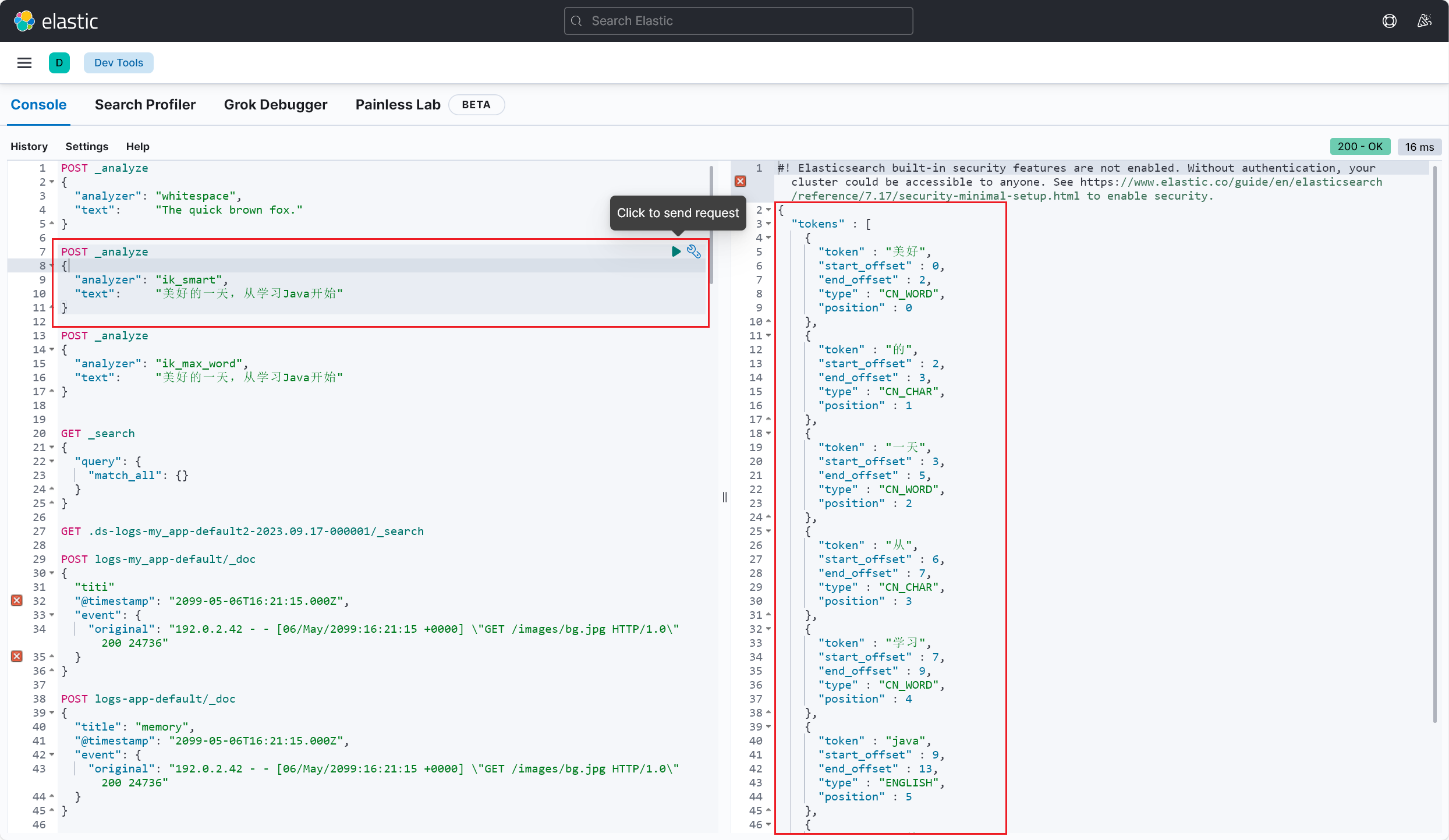
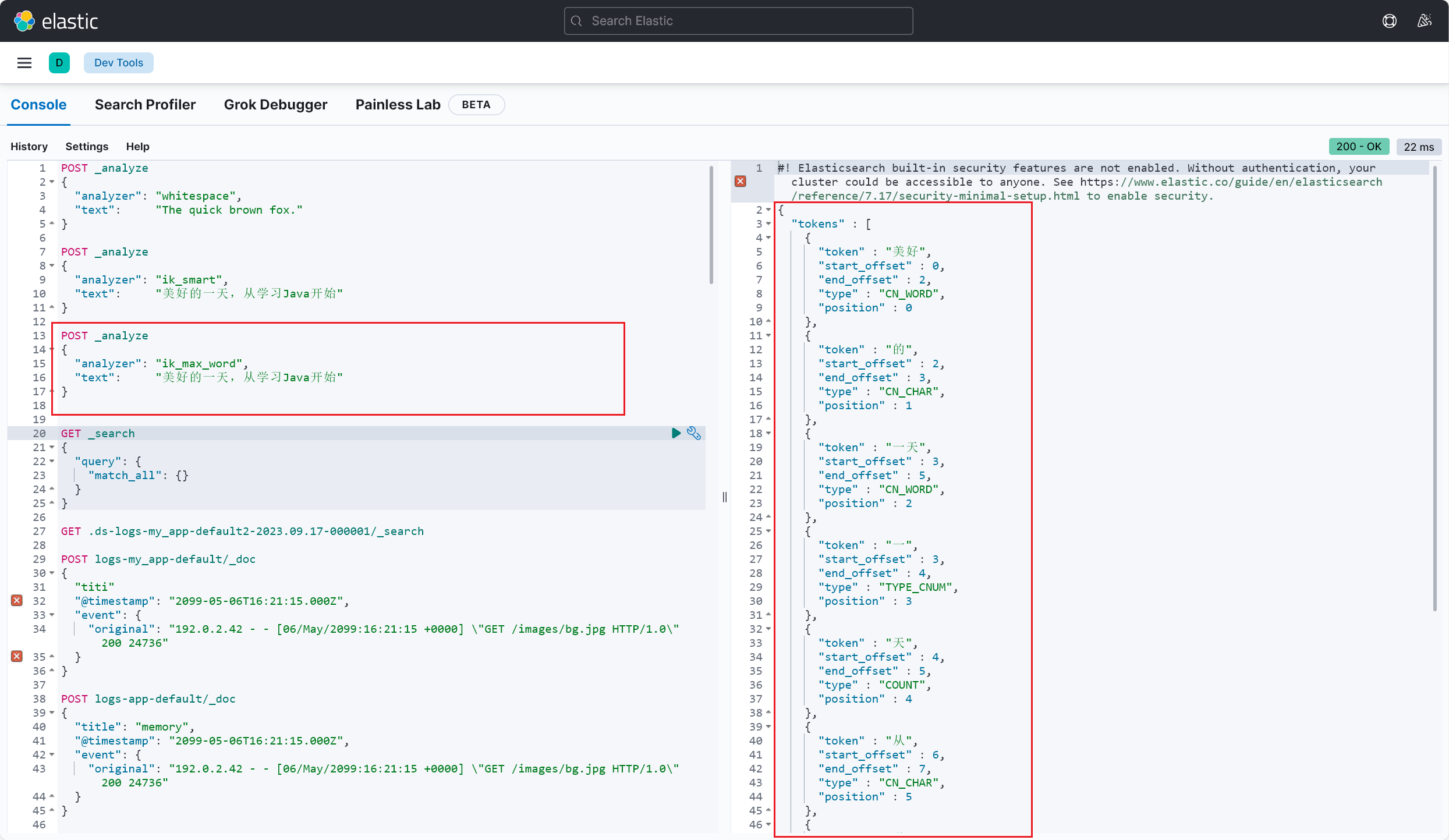
测试成功,这里也能看出来 ik_smart 和 ik_max_word 这两种不同分词模式的区别了(2023/09/20 午)
ik_smart模式是IK 分词器的简单模式,它会对文本进行较为粗粒度的切分,主要以将句子切分为一些较短的词语为目标,适用于快速搜索和一般文本处理场景。该模式下的分词结果倾向于保留短词ik_max_word模式是IK 分词器的细粒度模式,它会尽可能多地将文本切分为更小的词语,包括一些更细致的切分,如拆分复合词和词组等。该模式下的分词结果倾向于将文本切分为更多的词
# 🌮 关键词语高亮
# 🥃 搜索词条建议
# 🥡 热门搜索统计
# 🍱 热门话题分析
# 🍚 Kibana 数据监控看板
# 下载安装
🍖 Logstash 下载安装: 下载 - Kibana (opens new window)
# 本地启动 Kibana
在本地 Kibana 的 bin 目录下,执行以下命令,一键启动 Kibana:
kibana.bat
# 数据看板介绍
# 找到监控面板:
# 创建可视化看板
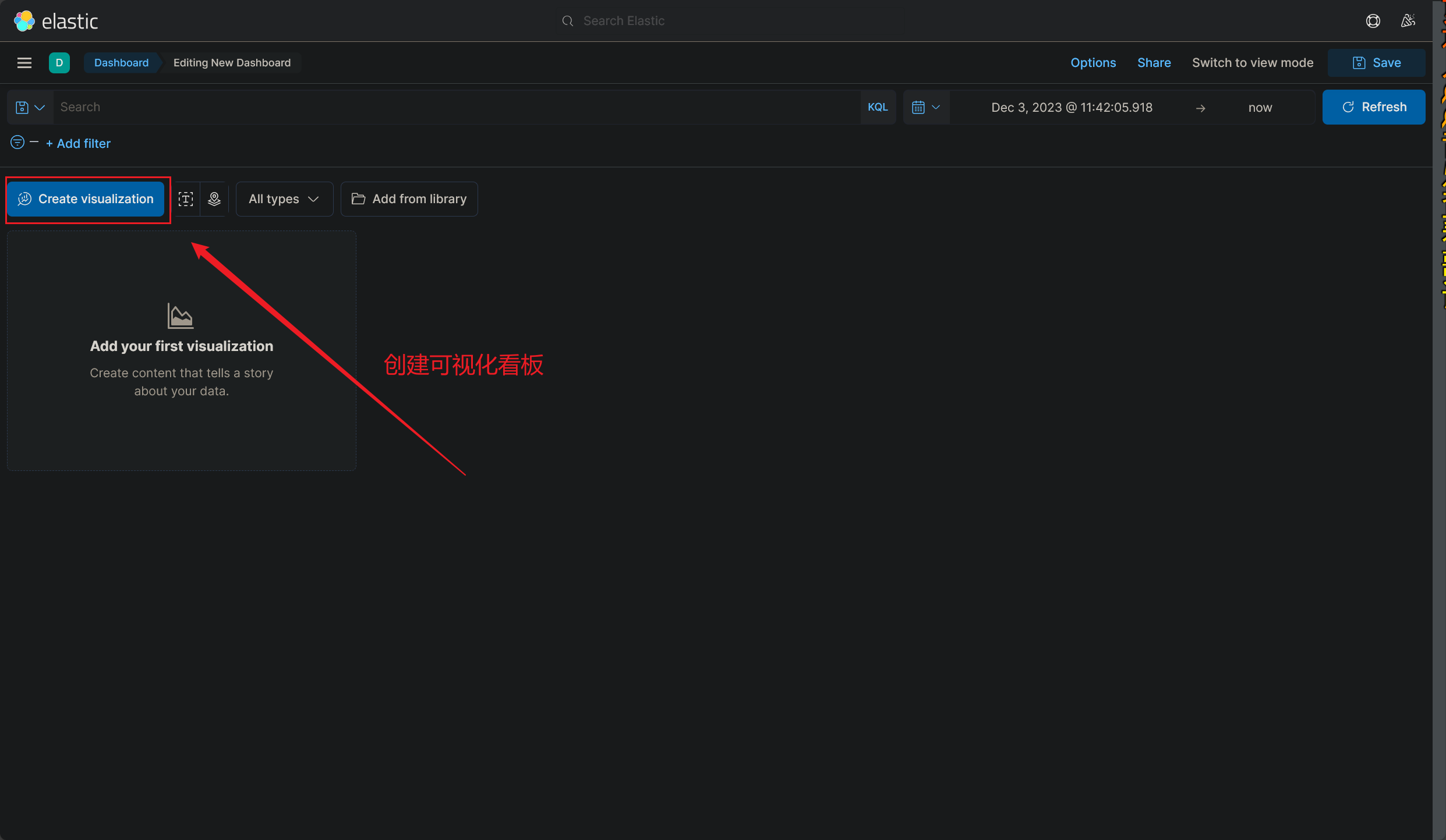
# 进入看板管理页面
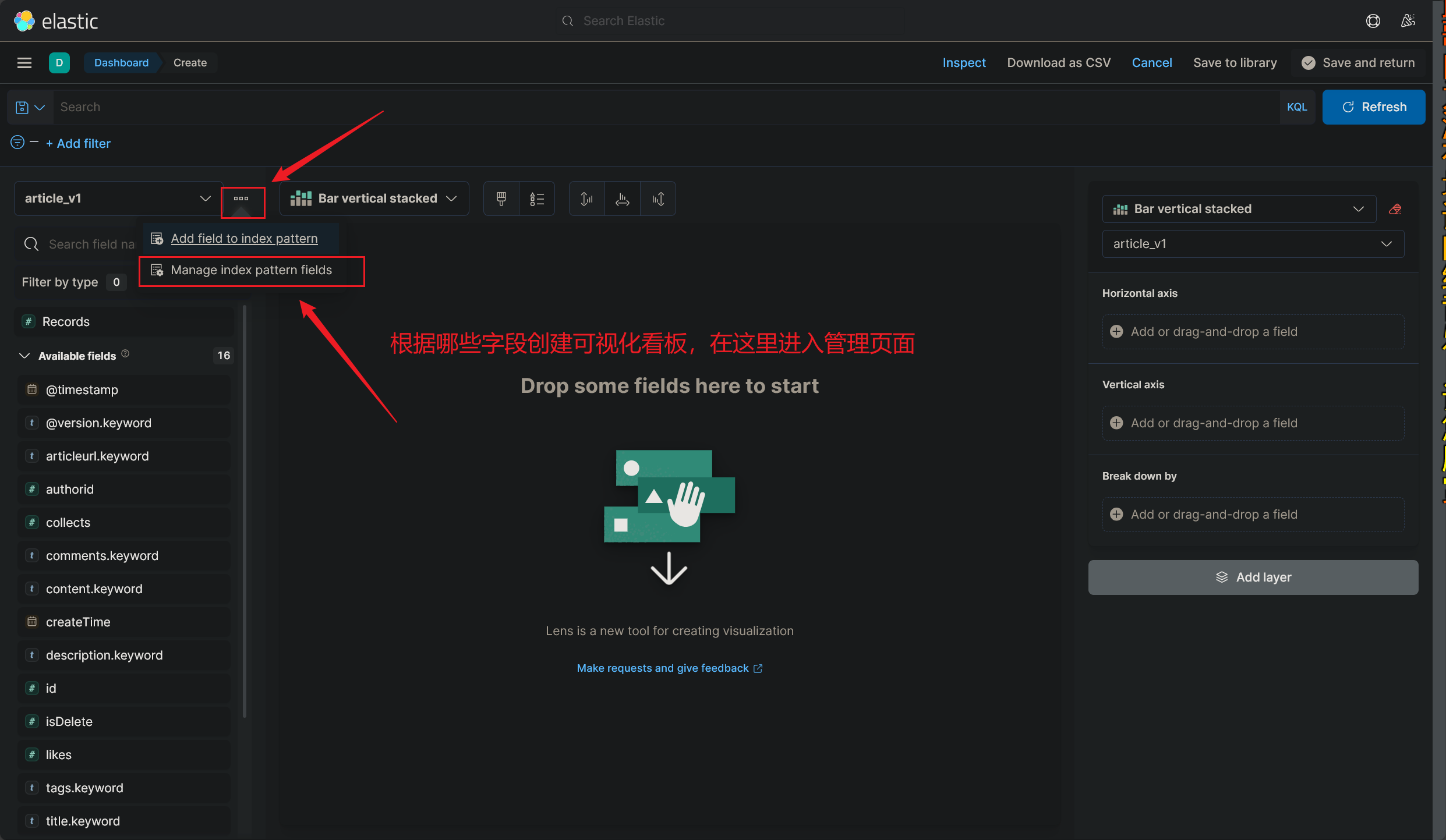
# 查看已创建的看板列表
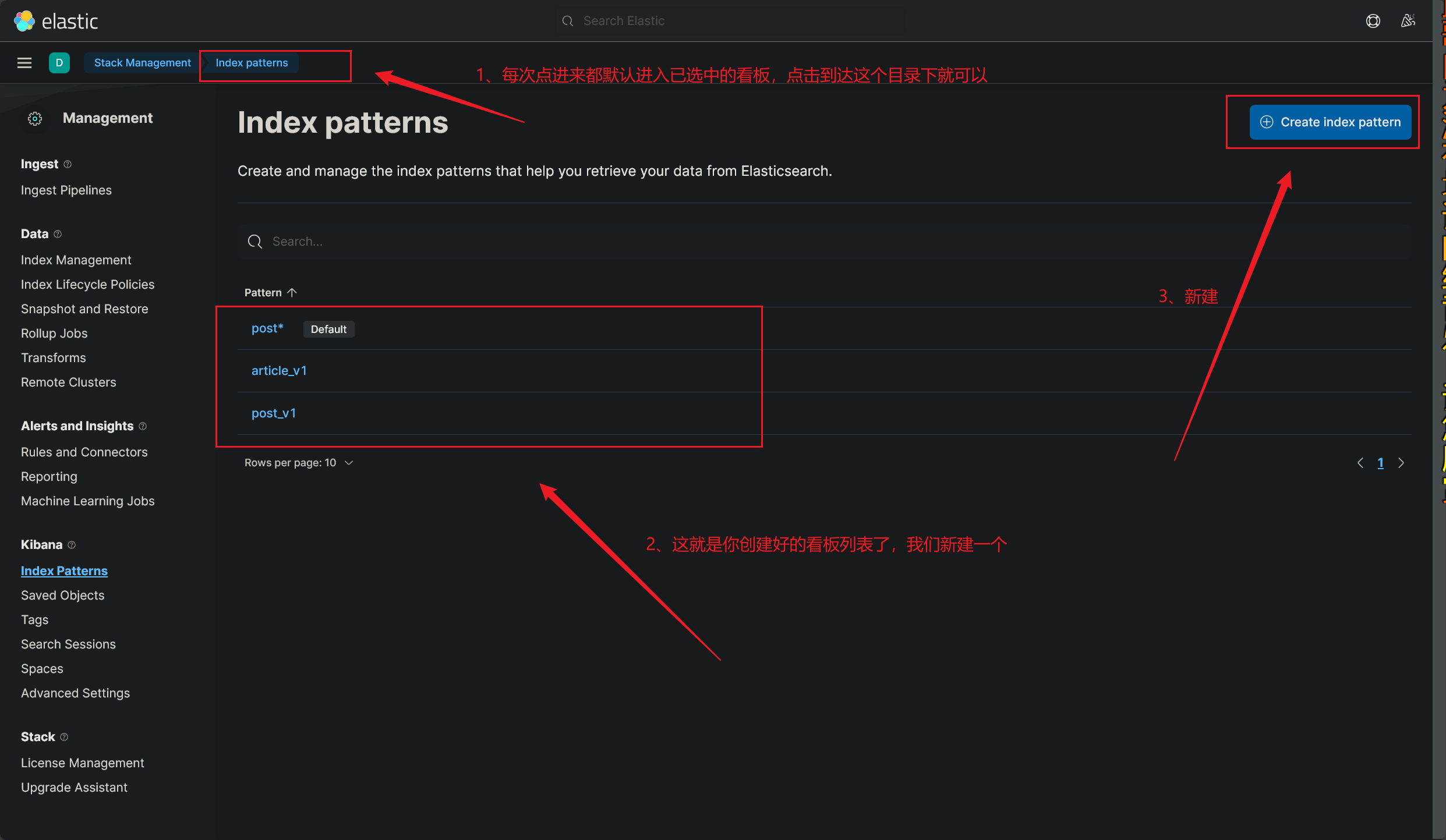
# 创建数据看板
- 成功创建新的数据看板,如下图所示:
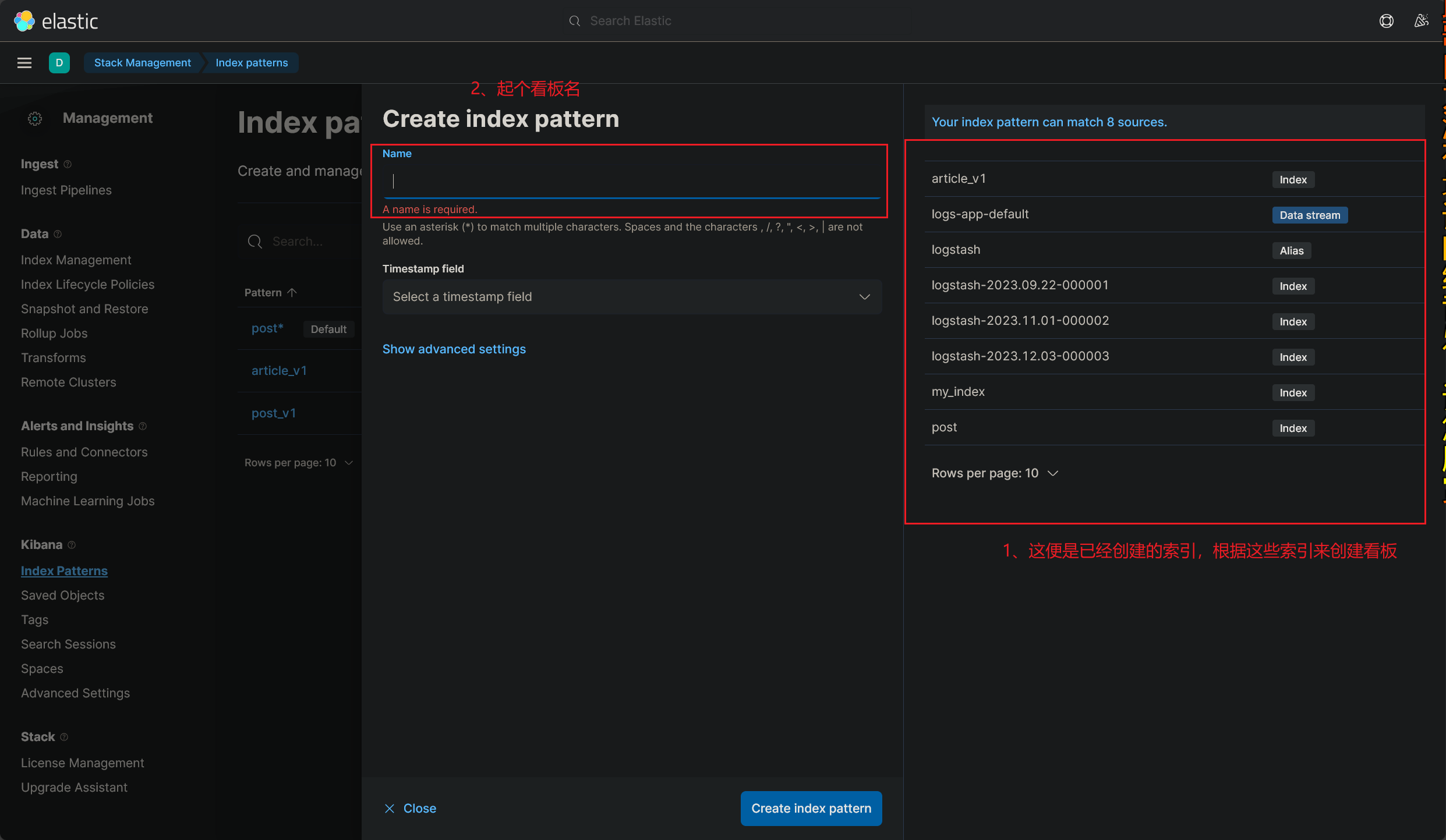
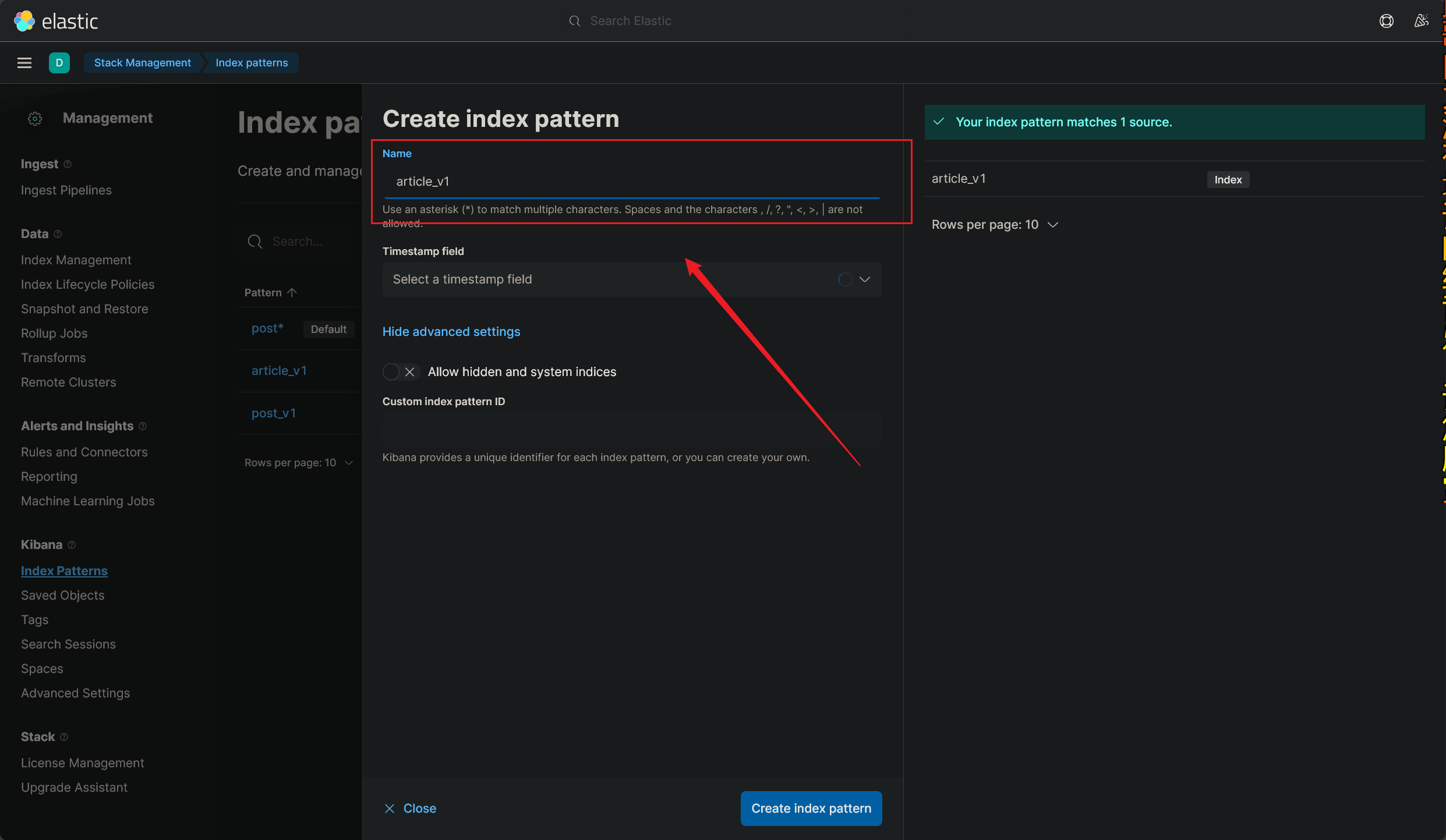
看板的命名很有意思,看板的命名必须要匹配到已经创建的索引名,还不能重复,也就是说:
每个索引只可以创建一个看板,至少以我目前的理解是这样的
创建好新的看板之后,就可以再次进入
DashBorad界面了,我们创建的可视化看板可以投入使用了
# 看板模块介绍
- 这里简单地介绍下各个板块的作用吧,其他没有什么好讲的,有时间玩玩就可以
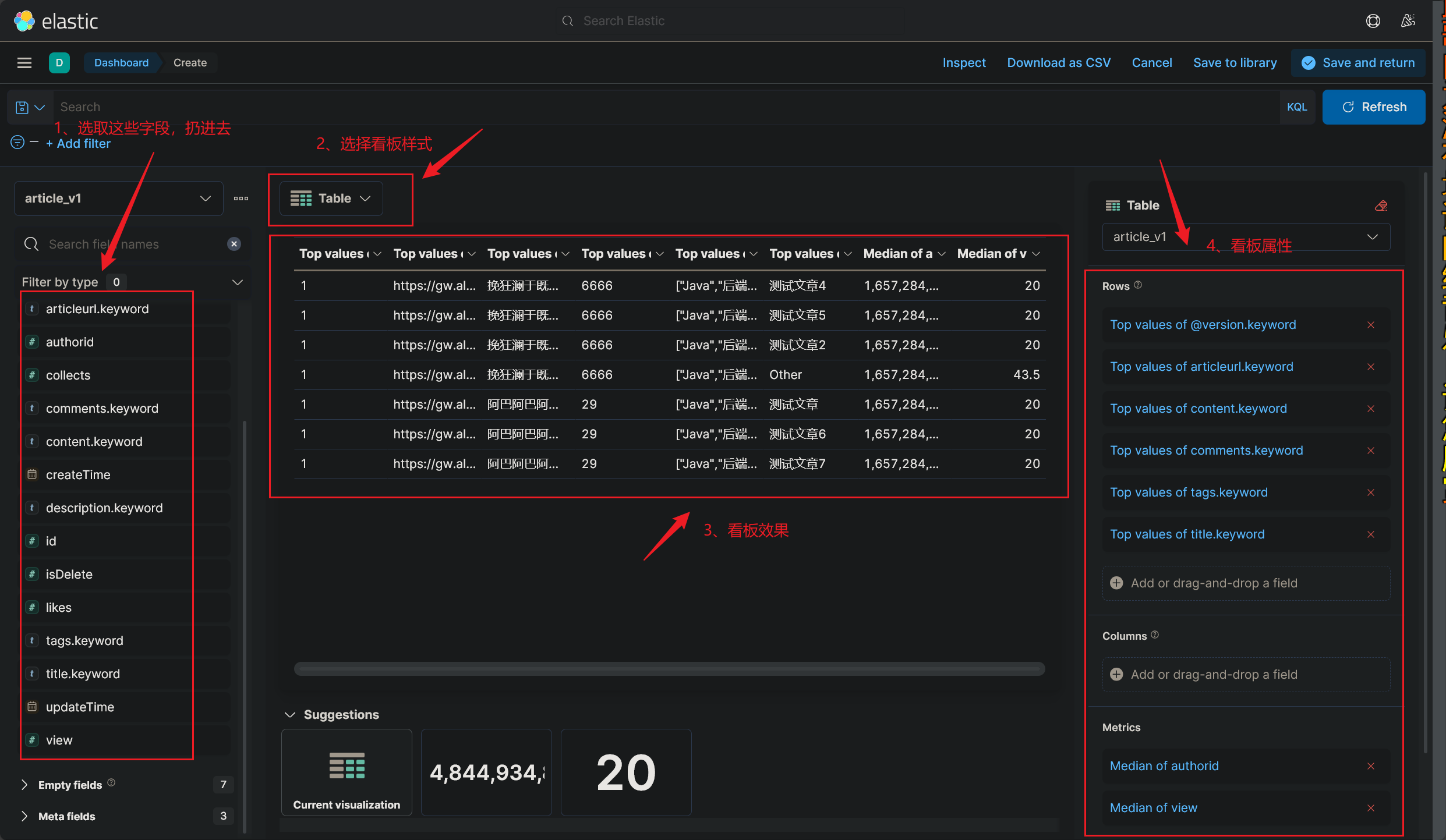
- 使用
Kibana可视化监控看板的教程到这里就结束了