 外源数据抓取
外源数据抓取
学习目标
在这里,你将系统学习了解 MemorySearch 忆搜阁中多种外源数据抓取实现方法
我们将以最简单直接的方式为您呈现内容!
# 🥣 数据抓取
# 常见方案
在项目开发过程中,我们经常需要从外部数据源获取数据。为了满足这一需求,可以采用以下几种常用的数据抓取方式:
利用 API 接口: 通过直接调用现有的 API 接口,我们可以方便地获取所需的数据。这种方式通常具有高效、稳定的特点,并且数据格式规范,便于后续处理。
使用 HttpClient 或 Hutool 等客户端: 这些工具可以帮助我们发送 HTTP 请求,并接收返回的 JSON 字符串。我们可以使用 Jackson 等库来解析这些字符串,提取出所需的数据。
使用 Jsoup 解析 HTML: 对于一些需要实时获取文章内容的场景,我们可以利用 Jsoup 来抓取网页内容。通过 Jsoup,我们可以方便地使用 CSS 选择器来解析 HTML,并将其存储到数据库中。
以上就是常用的几种数据抓取方式,它们各有特点,适用于不同的场景。在实际应用中,我们可以根据需求选择最适合的方式来进行数据抓取。接下来,我们将深入探讨这几种数据抓取方式,并通过 Java 代码演示其实践应用。
# 直接调用现成 API 接口
市面上有很多 API 接口可供开发者直接调用,这极大地简化和方便了我们的开发工作。比如说讯飞科技的讯飞星火 AI 大模型,几个月前开放了 API 接口调用。
作为开发者,只需要下载官方提供的 SDK ,领取到系统发放的唯一的 access_key 和 secret_key ,即可在代码中方便快捷地调用官方提供的 AI 对话接口服务,这样的接口服务是非常给力的。
其余内容不再详细赘述,如果对该内容感兴趣,推荐您点击此处,跳转至讯飞星火官网 (opens new window)了解详情
当然也可以跳转至我的个人博客:,教会你如何快速使用官网提供的 SDK ,体验讯飞星火 AI 对话接口服务
# 🥩 诗词抓取
提示
对于这部分内容中异步编程支持的深入了解,您可以跳转到 异步编程支持 (opens new window) 页面,其中详细阐述了该过程的原理、最佳实践以及应用场景
- 初始化一个
计时器StopWatch 来追踪整个过程的耗时。接着,定义了一个包含多位著名诗人名字的字符串数组,并将其转换为列表 authorList,以便后续按作者批量获取诗词数据。此时,计时器开始计时,为后续操作提供精确的耗时统计:
// new一个StopWatch对象
StopWatch stopWatch = new StopWatch();
// 计时开始
stopWatch.start();
// 按作者批量获取诗词
String[] stringArray = {"李白", "杜甫", "苏轼", "王维", "杜牧", "陆游", "李煜", "元稹", "韩愈", "岑参",
"齐己", "贾岛", "柳永", "曹操", "李贺", "曹植", "张籍", "孟郊", "屈原", "王勃", "高适",
"白居易", "辛弃疾"};
List<String> authorList = Arrays.asList(stringArray);
首先,设定了用于请求诗词数据的
URL 地址模板。接着,创建了一个固定大小为 10 的自定义线程池,用于执行并发任务。此外,初始化了一个列表来存储所有异步任务的 CompletableFuture 对象,以便后续管理和监控这些任务的状态。这一系列配置为后续的
异步爬取操作提供了必要的基础设施和资源管理。
String originUrl = "https://so.gushiwen.cn/shiwens/default.aspx?page=%d&tstr=&astr=%s&cstr=&xstr=";
// 创建自定义线程池
ExecutorService executorService = Executors.newFixedThreadPool(10);
// 存储所有的异步任务
List<CompletableFuture<Void>> futures = new ArrayList<>();
并发爬取与存储诗词信息:对于给定的作者列表,程序创建多个线程,每个线程异步地抓取指定 URL 的 HTML 文档。
使用 Jsoup 解析文档,提取诗词的
标题、作者和内容,并将这些信息封装为对象。随后,批量将对象列表存储至数据库。此过程利用异步编程提高爬虫效率,确保数据的快速获取与存储。
for (String authorStr : authorList) {
for (int i = 1; i < 5; i++) {
String url = String.format(originUrl, i, authorStr);
// 创建异步任务
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
try {
// 1. 获取数据
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81")
.get();
// 捕获 id = "leftZhankai"
Element leftZhankai = doc.getElementById("leftZhankai");
Elements heads = leftZhankai.select(".sons .cont div:nth-of-type(2)");
ArrayList<Post> postList = new ArrayList<>();
for (Element head : heads) {
Post post = new Post();
String title = head.select(">p:nth-of-type(1)").text();
String author = head.select(">p:nth-of-type(2)").text();
String content = head.select(".contson").text();
post.setTitle(title);
post.setAuthor(author);
post.setContent(content);
postList.add(post);
}
boolean saveBatch = postService.saveBatch(postList);
ThrowUtils.throwIf(!saveBatch, ErrorCode.OPERATION_ERROR, "批量插入诗词失败");
} catch (IOException e) {
throw new RuntimeException(e);
}
}, executorService);
// 将异步任务添加到列表中
futures.add(future);
}
}
在完成所有并发爬取任务后,程序会等待所有异步任务完成执行。随后,关闭用于执行这些任务的线程池,以确保资源的正确释放。接着,计时器停止计时,并输出整个爬取和存储过程的总耗时,以便进行
性能分析和优化。在按作者批量获取诗词的场景中,通过
异步编程方式处理,显著提高了批量插入数据库的效率。这里给出普通批量插入的代码实现:
// new一个StopWatch对象
StopWatch stopWatch = new StopWatch();
// 计时开始
stopWatch.start();
// 按作者批量获取诗词
String[] stringArray = {"李白", "杜甫", "苏轼", "王维", "杜牧", "陆游", "李煜", "元稹", "韩愈", "岑参",
"齐己", "贾岛", "柳永", "曹操", "李贺", "曹植", "张籍", "孟郊", "屈原", "王勃", "高适",
"白居易", "辛弃疾"};
List<String> authorList = Arrays.asList(stringArray);
String originUrl = "https://so.gushiwen.cn/shiwens/default.aspx?page=%d&tstr=&astr=%s&cstr=&xstr=";
for (String authorStr : authorList) {
for (int i = 1; i < 5; i++) {
String url = String.format(originUrl, i, authorStr);
// 1. 获取数据
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81")
.get();
// 捕获 id = "leftZhankai"
Element leftZhankai = doc.getElementById("leftZhankai");
Elements heads = leftZhankai.select(".sons .cont div:nth-of-type(2)");
ArrayList<Post> postList = new ArrayList<>();
for (Element head : heads) {
Post post = new Post();
String title = head.select(">p:nth-of-type(1)").text();
String author = head.select(">p:nth-of-type(2)").text();
String content = head.select(".contson").text();
post.setTitle(title);
post.setAuthor(author);
post.setContent(content);
postList.add(post);
}
boolean saveBatch = postService.saveBatch(postList);
ThrowUtils.throwIf(!saveBatch, ErrorCode.OPERATION_ERROR, "批量插入诗词失败");
}
}
// 计时结束
stopWatch.stop();
// 计算插入所用总时间
System.out.println(stopWatch.getTotalTimeMillis() + "ms");
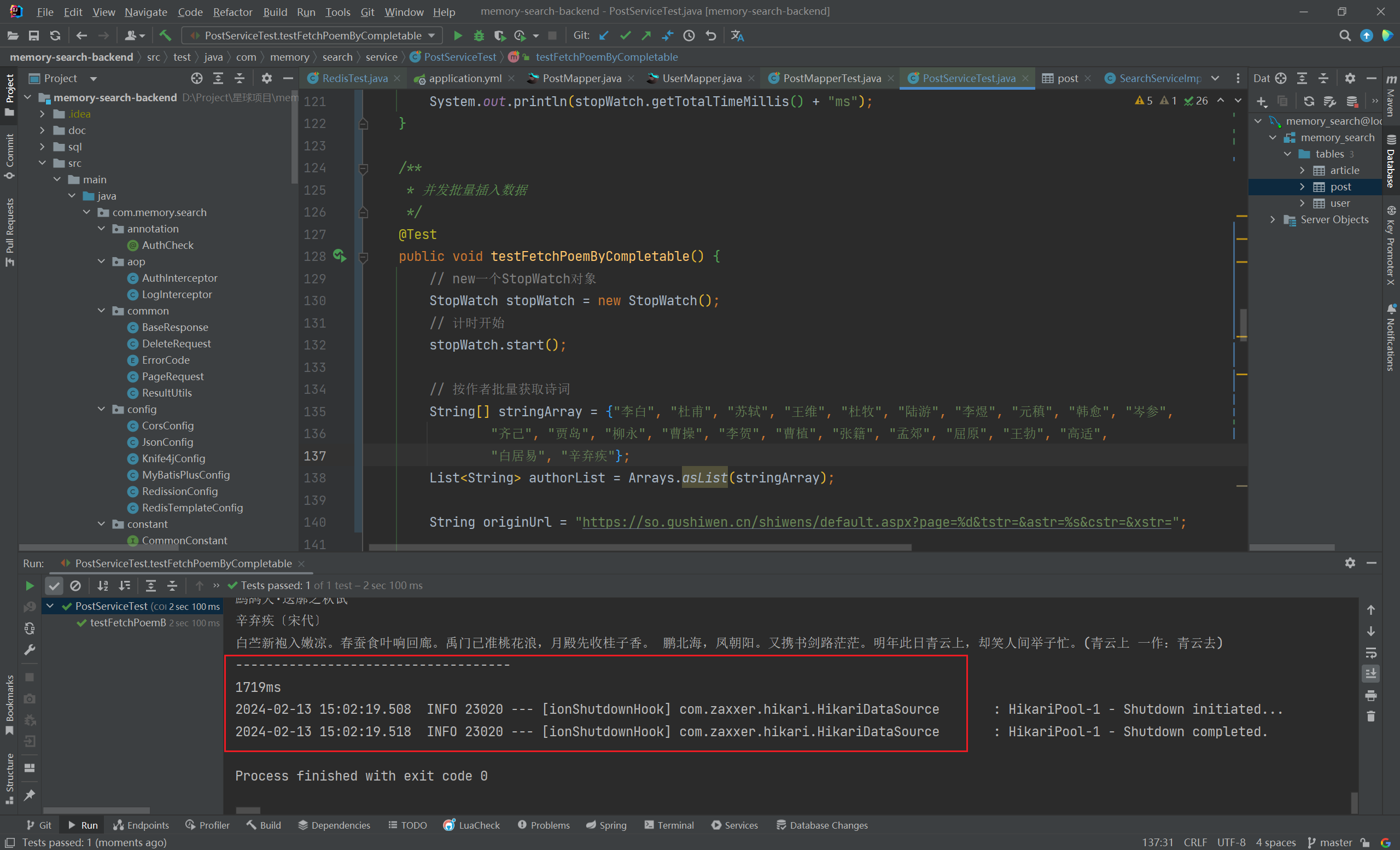
- 针对 24 位作者,每位作者 4 页诗词,每页 10 首,共计 960 首诗词的记录插入操作,普通批量插入耗时
4168 毫秒,而采用异步编程后,该过程仅用时1719 毫秒,性能提升近60%。这一优化表明,异步编程在处理大量数据插入时,能够大幅度减少等待时间,提升整体处理效率。
# 🍚 文章抓取
# Hutool 客户端发起 HTTP GET 请求
- 指定
请求 URL,使用Hutool 客户端发起请求:
// 定义 URL
String url = "https://api.juejin.cn/content_api/v1/content/article_rank?category_id=6809637769959178254&type=hot&aid=2608&uuid=7202969973525005828&spider=0";
// 发起 HTTP GET 请求
HttpRequest request = HttpRequest.get(url);
// 获取响应结果
HttpResponse response = request.execute();
String json = response.body();
# 解析 JSON 字符串
- 使用
Jackson的ObjectMapper解析获取的JSON字符串
/**
* 存储博文 id
*/
List<String> contentIdList = new ArrayList<>();
// 解析 JSON 字符串
ObjectMapper objectMapper = new ObjectMapper();
JsonNode rootNode = null;
try {
rootNode = objectMapper.readTree(json);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
JsonNode dataNode = rootNode.get("data");
// 保存博文 id
for (JsonNode jsonNode : dataNode) {
JsonNode contentNode = jsonNode.get("content");
String contentId = contentNode.get("content_id").asText();
contentIdList.add(contentId);
System.out.println("content_id: " + contentId);
}
# Jsoup 发起 HTTP GET 请求
- 指定
请求 URL,使用Jsoup 库抓取 HTML 文档
String url = "https://juejin.cn/post/7313418992310976549";
Document doc = Jsoup
.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81")
.get();
# 解析 HTML 文档
- 利用
CSS Selector准确、高效地解析 HTML 文档结构,获取title和content,并持久化至数据库
@Resource
private ArticleService articleService;
// 解析获取 title
Elements title = doc.select(".article-area .article-title");
// 解析获取 content
Elements content = doc.select(".article-viewer p");
// 转码,便于保存
byte[] contentBytes = content.toString().getBytes(StandardCharsets.UTF_8);
// 接收博文数据
Article article = new Article();
article.setId(Long.valueOf("7313418992310976777"));
article.setTitle(title.text());
article.setContent(contentBytes);
article.setAuthorId(0L);
article.setView(0);
article.setLikes(0);
article.setComments("");
article.setCollects(0);
article.setTags("");
//持久化到数据库
articleService.save(article);
- 至此,我们实现了使用
Hutool和Jackson从外部网站获取热榜博文 id,并使用jsoup实时获取文章内容,利用CSS Selector解析 HTML 并入库。
# 图片抓取
提示
对于这部分内容中Redis 缓存的深入了解,您可以跳转到 Redis 缓存 (opens new window) 页面,其中详细阐述了该过程的原理、最佳实践以及应用场景
执行图片搜索并获取分页结果:构造请求 url 地址,根据搜索词条和页码,获取外部图片资源:
/**
* 图片搜索
*
* @param searchText 搜索关键词
* @param pageSize 每页容量
* @param currentPage 当前页码
* @return 图片列表
*/
@Override
public Page<Picture> listPictureVOByPage(String searchText, long pageSize, long currentPage) {
long current = currentPage - 1;
if (searchText == null) {
return null;
}
// 非空条件,转码
if (StringUtils.isNotBlank(searchText)) {
try {
searchText = URLEncoder.encode(searchText, "UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
}
String url = String.format("https://cn.bing.com/images/search?q=%s&first=%s", searchText, current);
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
throw new RuntimeException(e);
}
Elements elements = doc.select(".iuscp.isv");
List<Picture> pictureList = new ArrayList<>();
Long currentId = BaseContext.getCurrentId();
int count = 0;
for (Element element : elements) {
String mUrl = getImageUrl(element);
String title = getTitle(element);
Picture picture = new Picture(title, mUrl);
// 图片列表
pictureList.add(picture);
count++;
if (count > CommonConstant.PICTURE_NUMS) {
break;
}
}
// Redis 保存搜索图片 两小时
redisTemplate.opsForValue()
.set(String.format(SEARCH_PICTURE_KEY, String.valueOf(currentId)),
GSON.toJson(pictureList), 2, TimeUnit.HOURS);
Page<Picture> picturePage = new Page<>(pageSize, currentPage);
picturePage.setRecords(pictureList);
return picturePage;
}
从爬取得到的文档中,解析出图片标题和地址:
private String getImageUrl(Element element) {
String m = element.select(".iusc").get(0).attr("m");
Map<String, Object> map = JSONUtil.toBean(m, Map.class);
return (String) map.get("murl");
}
private String getTitle(Element element) {
return element.select(".inflnk").get(0).attr("aria-label");
}
整个流程实现了高效的图片搜索、提取、缓存和分页处理,这里简单描述一下以上代码的执行流程:
该方法 listPictureVOByPage 旨在根据给定的
搜索关键词、每页容量和当前页码,从外部图片资源网站(如 Bing 图片搜索)检索相关图片。首先,它对搜索关键词进行非空检查与 URL 编码。然后,构造相应的
搜索 URL,并通过 Jsoup 库连接并获取页面文档。接着,从文档中提取特定元素(可能是图片容器)作为候选图片,并遍历这些元素,提取图片 URL 和标题信息,创建 Picture 对象,并将其添加到图片列表中。为确保不过度获取图片,该方法设置了一个
最大图片数量限制。之后,将图片列表存储到
Redis 缓存中,以便在两小时内快速访问。最后,创建一个分页对象,设置其每页容量和当前页码,并将图片列表作为记录集合,返回该分页对象。